Linuks komanda `uniq` analizira vaše tekstualne datoteke, tražeći redove koji su jedinstveni ili se ponavljaju. U ovom vodiču istražićemo njenu fleksibilnost i funkcionalnosti, pokazujući kako da maksimalno iskoristite ovaj koristan alat.
Otkrivanje identičnih redova teksta u Linuksu
Komanda `uniq` je brza, prilagodljiva i veoma efikasna u onome što radi. Međutim, kao i mnoge Linuks komande, ima svoje specifičnosti na koje treba obratiti pažnju. Bez potrebnog razumevanja, rezultati mogu biti zbunjujući. Zato ćemo razjasniti te posebnosti.
Komanda `uniq` je idealna za one koji cene jednostavnost i fokusiranost na jedan zadatak. Zbog toga je posebno pogodna za upotrebu u cevovodima komandi. Jedan od njenih najčešćih saradnika je komanda `sort`, jer `uniq` zahteva sortiran ulaz za obradu.
Započnimo!
Pokretanje `uniq` bez opcija
Imamo tekstualnu datoteku koja sadrži stihove pesme Roberta Džonsona pod nazivom „I Believe I’ll Dust My Broom“. Pogledajmo kako će se `uniq` snaći sa njom.
Unesite sledeću komandu da izlaz prikažemo pomoću `less`:
uniq dust-my-broom.txt | less

Dobijamo celu pesmu, uključujući duplirane redove, prikazanu u `less`:
Čini se da se ne izdvajaju ni jedinstveni, ni duplirani redovi.
To je tačno, jer ovo je prva neobičnost. Kada se `uniq` koristi bez opcija, ponaša se kao da je upotrebljena opcija `-u` (jedinstveni redovi). Ovo nalaže `uniq`-u da prikaže samo jedinstvene redove iz datoteke. Razlog zašto vidite duplikate je taj što, da bi `uniq` prepoznao red kao duplikat, on mora biti direktno pored svog duplikata, a tu na scenu stupa sortiranje.
Kada sortiramo datoteku, duplikati redova se grupišu, a `uniq` ih tada tretira kao duplikate. Koristićemo `sort` na datoteci, proslediti sortirani izlaz `uniq`-u, i zatim prikazati konačni izlaz pomoću `less`.
Da bismo to uradili, unesite sledeće:
sort dust-my-broom.txt | uniq | less

Sortirana lista redova se prikazuje u `less`.
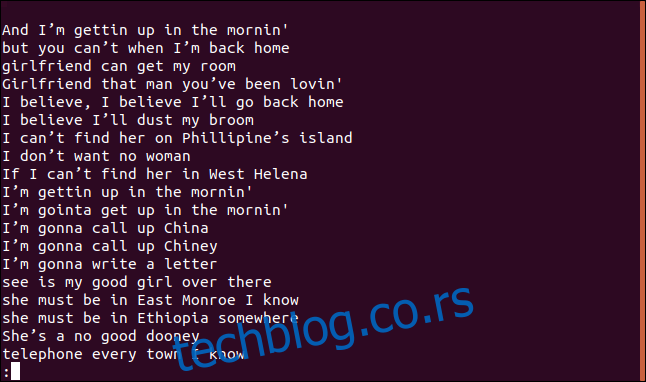
Stih „I believe I’ll dust my broom“ se definitivno pojavljuje više puta u pesmi. Zapravo, ponavlja se dva puta u prva četiri reda.
Dakle, zašto se pojavljuje na listi jedinstvenih redova? Zato što je prvo pojavljivanje reda u datoteci jedinstveno. Samo sledeći unosi se smatraju duplikatima. Zamislite to kao prikazivanje prvog pojavljivanja svakog jedinstvenog reda.
Ponovo ćemo koristiti `sort` i preusmeriti izlaz u novu datoteku. Na ovaj način, ne moramo koristiti `sort` u svakoj komandi.
Unesite sledeću komandu:
sort dust-my-broom.txt > sorted.txt

Sada imamo prethodno sortiranu datoteku za rad.
Brojanje duplikata
Možete koristiti opciju `-c` (broj) da prikažete koliko puta se svaki red pojavljuje u datoteci.
Unesite sledeću komandu:
uniq -c sorted.txt | less

Svaki red počinje brojem pojavljivanja tog reda u datoteci. Međutim, primetićete da je prvi red prazan. To znači da u datoteci postoji pet praznih redova.
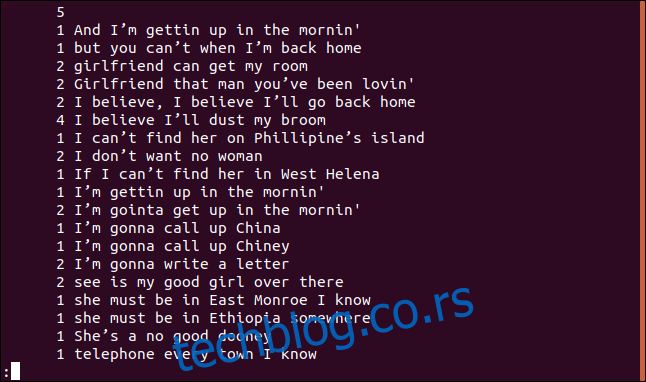
Ako želite da izlaz bude sortiran po numeričkom redosledu, možete proslediti izlaz `uniq`-a komandi `sort`. U našem primeru, koristićemo opcije `-r` (obrnuto) i `-n` (numeričko sortiranje) i prikazati rezultate u `less`.
Unesite sledeće:
uniq -c sorted.txt | sort -rn | less

Lista je sortirana u opadajućem redosledu na osnovu učestalosti pojavljivanja svakog reda.
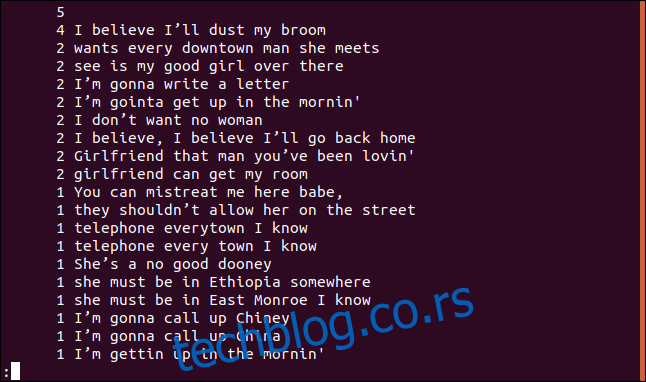
Prikazivanje samo dupliranih redova
Ako želite da vidite samo redove koji se ponavljaju u datoteci, možete koristiti opciju `-d` (duplirano). Bez obzira koliko puta se red duplira u datoteci, biće prikazan samo jednom.
Da biste koristili ovu opciju, unesite sledeće:
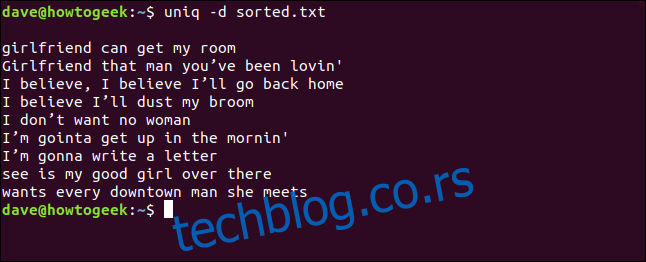
uniq -d sorted.txt

Duplirani redovi su prikazani. Primetite prazan red na vrhu, što znači da datoteka sadrži duple prazne redove. To nije prazan prostor koji je `uniq` ostavio radi izgleda.
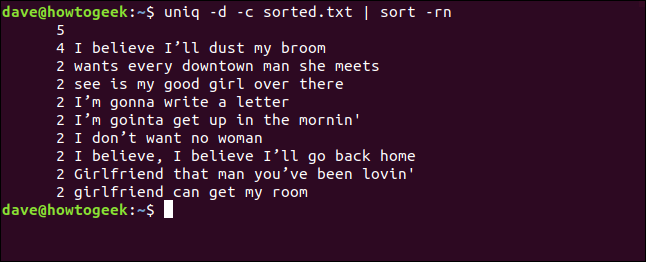
Takođe možemo kombinovati opcije `-d` (duplirano) i `-c` (broj) i proslediti izlaz kroz `sort`. Ovo nam daje sortiranu listu redova koji se pojavljuju najmanje dva puta.
Unesite sledeće da koristite ovu opciju:
uniq -d -c sorted.txt | sort -rn
Prikazivanje svih dupliranih linija
Ako želite da vidite listu svake duplirane linije, kao i unos za svaki put kada se linija pojavi u datoteci, možete koristiti opciju `-D` (sve duplirane linije).
Da biste koristili ovu opciju, unesite sledeće:
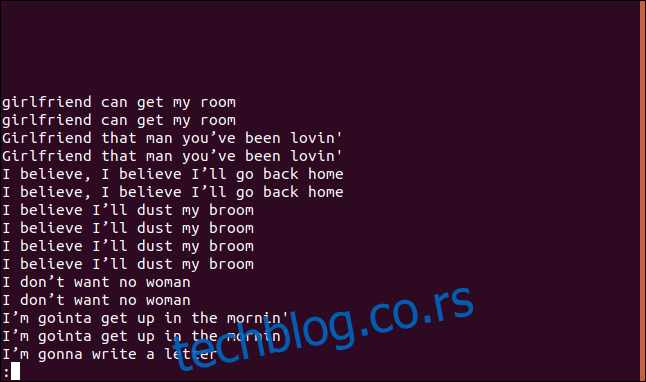
uniq -D sorted.txt | less

Lista sadrži unos za svaki duplirani red.
Ako koristite opciju `–group`, ona prikazuje svaki duplirani red sa praznim redom ili pre (prethodno), ili posle svake grupe (dodavanje), ili i pre i posle (obe) svake grupe.
Koristićemo `append` kao naš modifikator, pa unesite sledeće:
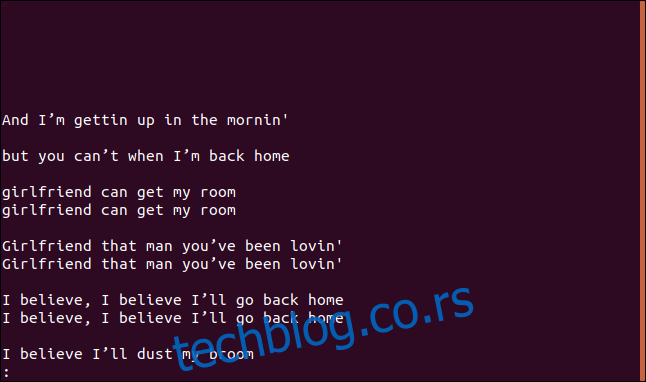
uniq --group=append sorted.txt | less

Grupe su odvojene praznim redovima radi lakšeg čitanja.
Provera određenog broja znakova
Podrazumevano, `uniq` proverava celu dužinu svakog reda. Međutim, ako želite da ograničite proveru na određeni broj znakova, možete koristiti opciju `-w` (provera znakova).
U ovom primeru, ponovićemo poslednju komandu, ali ćemo ograničiti poređenja na prva tri znaka. Da biste to uradili, unesite sledeću komandu:
uniq -w 3 --group=append sorted.txt | less

Rezultati i grupisanja koje dobijamo su prilično drugačiji.
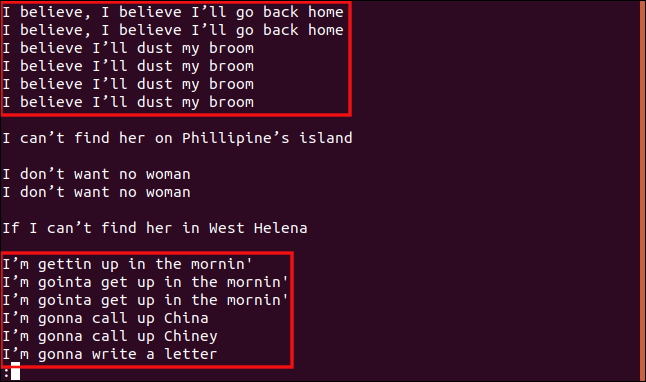
Svi redovi koji počinju sa „I b“ su grupisani zajedno, jer su ti delovi redova identični, pa se smatraju duplikatima.
Isto tako, svi redovi koji počinju sa „I am“ se tretiraju kao duplikati, čak i ako je ostatak teksta drugačiji.
Ignorisanje određenog broja znakova
Postoje slučajevi u kojima bi moglo biti korisno preskočiti određeni broj znakova na početku svakog reda, na primer kada su redovi u datoteci numerisani. Ili, recimo da želite da `uniq` preskoči vremensku oznaku i počne da proverava redove od šestog znaka umesto od prvog.
Ispod je verzija naše sortirane datoteke sa numerisanim linijama.
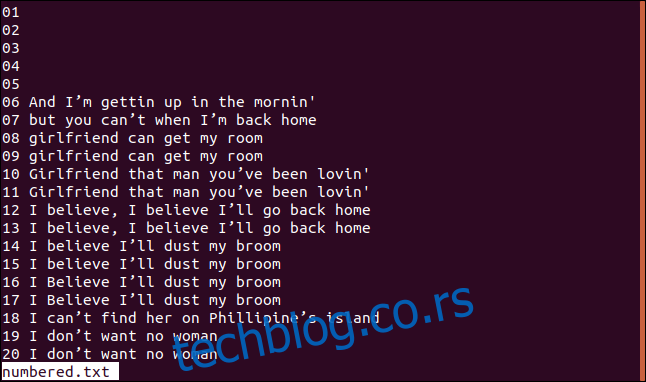
Ako želimo da `uniq` započne proveru poređenja na trećem znaku, možemo koristiti opciju `-s` (preskakanje znakova) tako što ćemo uneti sledeće:
uniq -s 3 -d -c numbered.txt
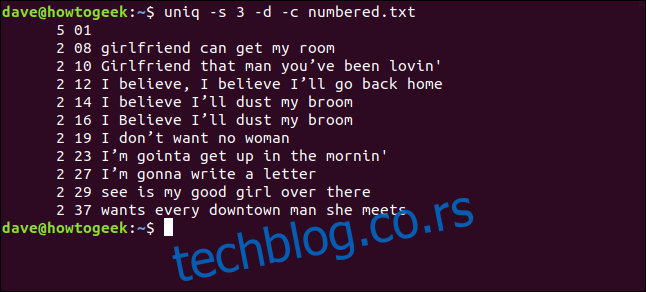
Linije se detektuju kao duplikati i pravilno se broje. Obratite pažnju da su prikazani brojevi redova oni prvog pojavljivanja svakog duplikata.
Takođe možete preskočiti polja (niz znakova i malo razmaka) umesto znakova. Koristićemo opciju `-f` (polja) da kažemo `uniq`-u koja polja da ignoriše.
Unesite sledeće da kažemo `uniq`-u da ignoriše prvo polje:
uniq -f 1 -d -c numbered.txt
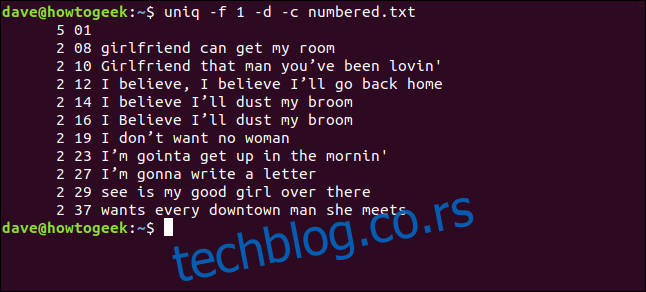
Dobijamo iste rezultate kao kada smo rekli `uniq`-u da preskoči tri znaka na početku svakog reda.
Ignorisanje velikih i malih slova
Podrazumevano, `uniq` je osetljiv na velika i mala slova. Ako se isto slovo pojavljuje napisano velikim i malim slovima, `uniq` smatra da su redovi različiti.
Na primer, pogledajte izlaz iz sledeće komande:
uniq -d -c sorted.txt | sort -rn
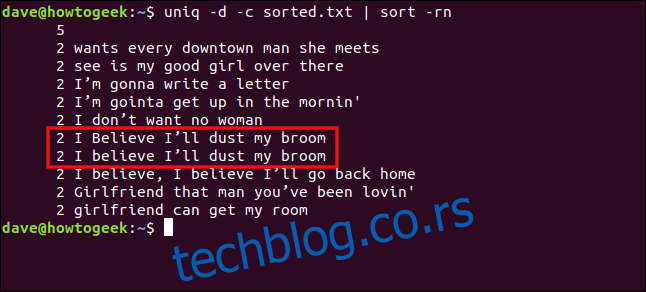
Redovi „I believe I’ll dust my broom“ i „i believe i’ll dust my broom“ se ne tretiraju kao duplikati zbog razlike u slovu na „B“ u „believe“.
Međutim, ako uključimo opciju `-i` (ignoriši velika i mala slova), ove linije će se tretirati kao duplikati. Unesite sledeće:
uniq -d -c -i sorted.txt | sort -rn
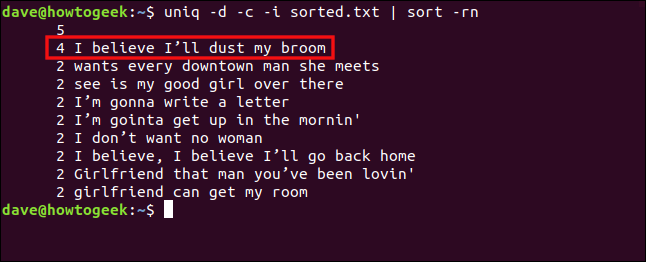
Linije se sada tretiraju kao duplikati i grupišu zajedno.
Linuks vam stavlja na raspolaganje mnoge specijalizovane alate. Kao i mnogi od njih, `uniq` nije alatku koju ćete koristiti svakodnevno.
Zato je veliki deo učenja u Linuksu zapamtiti koji alat će rešiti vaš trenutni problem i gde ga možete ponovo pronaći. Međutim, uz vežbu, bićete na pravom putu.
Ili, uvek možete pretražiti How-To Geek, verovatno imamo članak o tome.