Технологија „deepfake“ видеа је већ учинила да сумњамо у све што видимо. Сада, појава аудио „deepfake“-а може нас навести да сумњамо и у оно што чујемо. Можемо ли заиста бити сигурни да је председник објавио рат Канади или да нам се отац обраћа са захтевом за лозинком електронске поште?
Списак егзистенцијалних страхова се шири, а могућност да нас сопствена ароганција уништи делује све реалније. У време Регана, главне технолошке претње су били нуклеарни, хемијски и биолошки ратови.
Касније, бринули смо о сивој нанотехнолошкој слузи и глобалним пандемијама. Сада се суочавамо са “deepfake” технологијом – људима који губе контролу над својим ликом и гласом.
Шта су то аудио „deepfake“-ови?
Већина нас је упозната са видео „deepfake“-овима, где се користе алгоритми дубоког учења да би се лице једне особе заменило другим. Најбољи међу њима су застрашујуће реалистични, а сада је иста технологија доступна и за аудио. Аудио „deepfake“ је синтетички звук, креиран клонирањем гласа, који је готово немогуће разликовати од правог гласа.
Зохаиб Ахмед, извршни директор компаније Resemble AI, пореди технологију клонирања гласа са “Photoshop”-ом за глас.
Међутим, лоше уређене “Photoshop” фотографије је лако препознати. Стручњаци за безбедност наводе да људи погоде да ли је аудио лажан са тачношћу од око 57%, што је исто као да бацате новчић.
Поред тога, многи аудио снимци телефонских позива су лошег квалитета или су снимљени у бучним окружењима, што додатно отежава разликовање лажног од правог. Лошији квалитет звука отежава уочавање знакова да глас није аутентичан.
Зашто би неко уопште користио “Photoshop” за гласове?
Уверљива примена синтетичког звука
Потражња за синтетичким звуком је заправо огромна. Ахмед тврди да је „повраћај инвестиције веома брз“.
Ово се посебно односи на индустрију игара. У прошлости, говор је био једина компонента у игри коју је било немогуће креирати на захтев. Чак и у интерактивним играма са биоскопским сценама, вербалне интеракције са ликовима су углавном биле статичне.
Сада је технологија коначно достигла ту тачку. Студији имају могућност да клонирају глас глумца и користе механизме претварања текста у говор, омогућавајући ликовима да изговарају било шта у реалном времену.
Постоје и традиционалније примене у маркетингу, техничкој подршци и корисничким сервисима. Овде је битно да глас звучи аутентично људски, а да је истовремено персонализован и контекстуално релевантан, без људске интервенције.
Компаније које се баве клонирањем гласа су такође узбуђене због медицинских апликација. Наравно, замена гласа није ништа ново у медицини – Стивен Хокинг је користио роботски синтетизован глас након што је изгубио свој 1985. године. Међутим, савремено клонирање гласа нуди још више.
2008. године, компанија за синтетички говор CereProc, дала је покојном филмском критичару Роџеру Еберту његов глас након његове смрти од рака. CereProc је направио и веб страницу где су људи могли да куцају поруке, које би се затим изговарале гласом бившег председника Џорџа Буша.
Метју Ејлет, главни научник у CereProc-у, каже да је Еберт видео то и помислио: “Ако могу да копирају Бушов глас, требало би да могу да копирају и мој”. Еберт је затим замолио компанију да направи заменски глас, што су и учинили, обрађујући велику библиотеку његових гласовних снимака.
“Био је то један од првих примера такве примене и био је веома успешан,” рекао је Ејлет.
У последњих неколико година, многе компаније (укључујући CereProc) су радиле са ALS Association на Project Revoice како би обезбедиле синтетичке гласове онима који пате од ALS-а.

Како функционише синтетички аудио?
Клонирање гласа је у експанзији, а многе компаније развијају сопствене алате. Resemble AI и Descript имају бесплатне демо верзије на мрежи које свако може испробати. Само снимите фразе приказане на екрану и за неколико минута ће бити креиран модел вашег гласа.
Можемо захвалити вештачкој интелигенцији, посебно алгоритмима дубоког учења, који могу да повежу снимљени говор са текстом како би разумели фонеме које чине ваш глас. Резултујуће лингвистичке јединице се затим користе да се приближно репродукују речи које нисте изговорили.
Основна технологија постоји већ неко време, али, како је Ајлет нагласио, потребна је помоћ.
„Копирање гласа је било као прављење колача,“ рекао је. “Било је тешко и захтевало је ручно подешавање да би функционисало.”
Програмери су морали да користе велике количине снимљеног гласа да би добили задовољавајуће резултате. Међутим, пре неколико година је дошло до напретка. Истраживање у области компјутерског вида је било кључно. Научници су развили генеративне противничке мреже (GAN), које су, по први пут, могле да екстраполирају и дају предвиђања на основу постојећих података.
„Уместо да рачунар види слику коња и каже: ‘Ово је коњ’, мој модел би сада могао од коња да направи зебру,“ рекао је Ајлет. „Дакле, развој синтезе говора је захвалан академским истраживањима у области компјутерског вида.“
Једна од највећих иновација у клонирању гласа је смањење количине необрађених података потребних за креирање гласа. Раније, системима су биле потребне десетине или чак стотине сати аудио материјала. Сада је довољно само неколико минута за генерисање компетентног гласа.
Егзистенцијални страх од неповерења
Ова технологија, заједно са нуклеарном енергијом, нанотехнологијом, 3D штампањем и CRISPR-ом, је истовремено узбудљива и застрашујућа. Већ је било случајева у вестима о људима који су били преварени помоћу клонираних гласова. 2019. године, једна компанија у Великој Британији је тврдила да је била жртва аудио преваре, где су телефонским позивом наведени да пошаљу новац криминалцима.
Није потребно много тражити да би се пронашли застрашујуће убедљиви аудио фалсификати. YouTube канал Vocal Synthesis приказује познате личности како говоре ствари које никада нису изговорили. На пример, Џорџ В. Буш чита песму „In Da Club“ од 50 Cent-a.
На другим YouTube каналима можете чути бивше председнике, попут Обаме, Клинтона и Регана како репују NWA. Музика и позадински звуци прикривају неке од роботских грешака, али потенцијал је ипак очигледан.
Испробали смо алате Resemble AI и Descript и креирали смо клон гласа. Descript користи механизам за клонирање гласа, који се првобитно звао Lyrebird, и био је изузетно импресиван. Били смо шокирани квалитетом. Узнемирујуће је чути сопствени глас како говори ствари које никада нисте изговорили.
Глас има одређену роботску ноту, али, уз опуштено слушање, већина људи не би посумњала да је лажан.
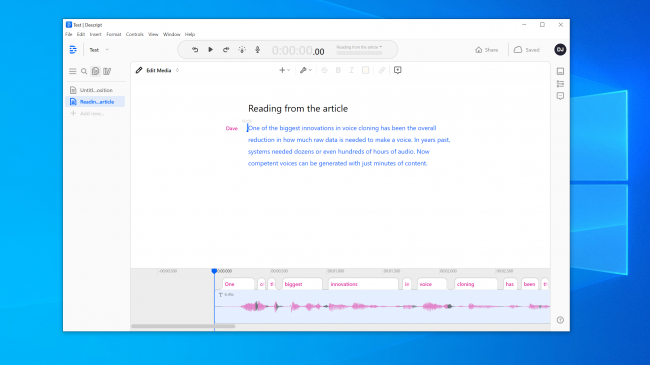
Имали смо већа очекивања од Resemble AI. Он вам даје алате за креирање разговора са више гласова, као и за варирање изражајности, емоција и темпа дијалога. Међутим, нисмо сматрали да модел гласа обухвата основне карактеристике гласа који смо користили. Вероватно не би никога преварио.
Представник Resemble AI нам је рекао да је „већина људи одушевљена резултатима ако се уради како треба“. Два пута смо направили модел гласа са сличним резултатима. Дакле, није увек лако направити клон гласа који можете користити за дигиталну пљачку.
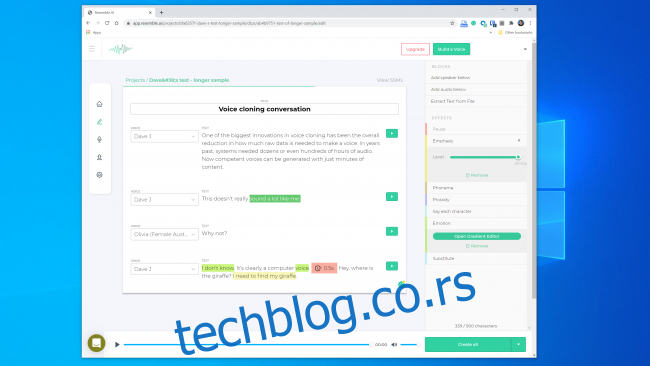
Упркос томе, оснивач Lyrebird-a (сада део Descript-a), Кундан Кумар, сматра да смо већ прешли ту границу.
„У малом проценту случајева, већ је ту,“ рекао је Кумар. „Ако користим синтетички звук да променим неколико речи у говору, то је већ толико добро да ћете тешко приметити промену.“
Можемо претпоставити да ће технологија бити све боља. Системима ће бити потребно мање звука за креирање модела, а бржи процесори ће моћи да креирају модел у реалном времену. Паметнија вештачка интелигенција ће научити како да дода убедљивију људску каденцу и акценат у говору, чак и без примера за рад.
То значи да се можда приближавамо ситуацији где ће клонирање гласа бити једноставно и доступно свима.
Етика Пандорине кутије
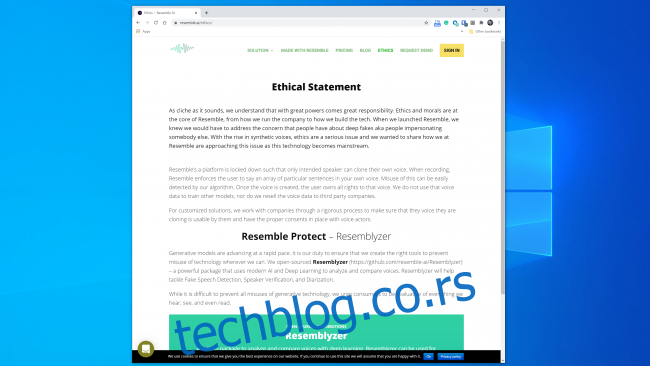
Чини се да је већина компанија које раде у овој области спремна да рукује технологијом на безбедан и одговоран начин. Resemble AI, на пример, има посебан одељак „Етика“ на својој веб страници, где наводи следеће:
„Радимо са компанијама кроз ригорозан процес како бисмо се уверили да могу да користе клонирани глас и да имају сагласност гласовних актера.“
Слично томе, Кумар је рекао да је Lyrebird од почетка био забринут због могуће злоупотребе. Зато, сада, као део Descript-a, дозвољавају људима да клонирају само свој глас. И Resemble и Descript захтевају да људи снимају своје узорке уживо како би спречили клонирање гласова без сагласности.
Охрабрујуће је што су главни комерцијални актери успоставили неке етичке смернице. Међутим, важно је запамтити да ове компаније нису једини власници технологије. Постоји велики број алата отвореног кода који су већ доступни, за које не постоје правила. Према Хенрију Ајдеру, шефу обавештајне службе у Deeptrace, није вам потребно ни напредно знање кодирања да бисте га злоупотребили.
„Велики део напретка у овој области је постигнут кроз заједнички рад на платформама као што је GitHub, користећи имплементације претходно објављених академских радова отвореног кода“, рекао је Ајдер. „Може га користити свако ко има основно знање кодирања.“
Стручњаци за безбедност су све ово већ видели
Криминалци су покушавали да украду новац телефоном давно пре него што је клонирање гласа било могуће, а стручњаци за безбедност су увек тражили начине да их открију и спрече. Компанија за безбедност Pindrop покушава да заустави банкарске преваре тако што проверава да ли је позивалац особа за коју се представља. Само у 2019. години, Pindrop тврди да је анализирао 1,2 милијарде гласовних интеракција и спречио око 470 милиона долара у покушајима преваре.
Пре клонирања гласа, преваранти су користили разне друге технике. Најједноставнији је био позив са друге локације, са личним информацијама о жртви.
„Наш акустични потпис нам омогућава да утврдимо да позив долази са Skype телефона у Нигерији, због карактеристика звука“, рекао је извршни директор Pindrop-a, Виџеј Баласубраманијан. „Онда то можемо упоредити са информацијом да купац користи АТ&Т телефон у Атланти.“
Неки криминалци су каријеру градили користећи позадинске звукове како би обманули службенике у банкама.
„Постојао је преварант кога смо звали ‘Chicken Man’, који је увек имао петлове у позадини“, рекао је Баласубраманијан. „А ту је и жена која је користила бебу која плаче у позадини, како би убедила агенте кол центра да пролази кроз тежак период и добила симпатије.“
Постоје и мушки криминалци који се представљају као жене како би дошли до банкарских рачуна жена.
„Користе технологију да подигну фреквенцију свог гласа, како би звучали женственије,“ објаснио је Баласубраманијан. Ово може бити успешно, али „повремено, софтвер забагује и звуче као Алвин и веверице“.
Наравно, клонирање гласа је само најновији развој у овом ескалирајућем рату. Безбедносне фирме су већ ухватиле преваранте који користе синтетички звук у бар једном случају “phishing” напада.
„Ако је мета права, потенцијална зарада је огромна,“ рекао је Баласубраманијан. „Зато има смисла уложити време у креирање синтетизованог гласа одређене особе.“
Може ли се препознати лажан глас?

Када је у питању препознавање лажног гласа, има и добрих и лоших вести. Лоша вест је да су клонирани гласови сваким даном све бољи. Системи дубоког учења постају све паметнији и креирају аутентичније гласове за које је потребно све мање аудио материјала.
Као што се може видети у овом клипу, где председник Обама говори МЦ Рен-у да заузме став, дошли смо до тачке где високо верни, пажљиво креирани модел гласа може звучати прилично убедљиво људском уху.
Што је звучни снимак дужи, већа је вероватноћа да ћете приметити да нешто није у реду. За краће клипове, међутим, можда нећете приметити да је глас синтетички, посебно ако немате разлога да сумњате у његову легитимност.
Што је квалитет звука бољи, лакше је препознати знакове аудио фалсификата. Ако неко говори директно у микрофон студијског квалитета, моћи ћете пажљиво да слушате. Међутим, аудио снимак телефонског позива лошег квалитета, или разговор снимљен на ручном уређају у бучној гаражи, ће бити много теже проценити.
Добра вест је да, чак и ако људи имају проблема да разликују право од лажног, рачунари немају иста ограничења. На срећу, алати за проверу гласа већ постоје. Pindrop има један који супротставља системе дубоког учења један против другог. Користи оба да утврди да ли је аудио узорак од особе за коју се представља. Међутим, такође проверава да ли човек уопште може да произведе све звукове у узорку.
У зависности од квалитета звука, свака секунда говора садржи између 8.000 и 50.000 узорака података који се могу анализирати.
„Ствари које обично тражимо су границе говора због људске еволуције,“ објаснио је Баласубраманијан.
На пример, између два вокална звука постоји минимална разлика. То је због тога што их је физички немогуће изговорити брже, због брзине којом се мишићи у устима и гласним жицама могу реконфигурисати.
„Када посматрамо синтетизовани звук,“ рекао је Баласубраманијан, „понекад видимо ствари и кажемо: ‘ово никада није могао да произведе човек, јер је једина особа која је то могла генерисати морала да има врат дуг седам стопа.“
Постоји и класа звукова који се називају „фрикативи“. Они настају када ваздух пролази кроз уско сужење у грлу, када изговарате слова као што су ф, с, в и з. Системима дубоког учења је посебно тешко да савладају фрикативе, јер софтвер има проблема да их разликује од буке.
Дакле, барем за сада, софтвер за клонирање гласа има проблеме јер су људи тела од меса, кроз чије рупе струји ваздух.