Можда се чини необично, али Линук команда `sed` представља едитор текста који не користи графички интерфејс. Његова употреба се одвија преко командне линије и омогућава манипулацију текстом унутар фајлова и стримова. У наставку ћемо показати како да искористите пун потенцијал ове команде.
Моћ команде `sed`
Команда `sed` се може упоредити са шахом: основе се науче за сат времена, али је потребно целог живота за савладавање (или барем доста вежбе). У овом тексту ћемо приказати селекцију основних техника из сваке од главних функционалних категорија команде `sed`.
Команда `sed` је ток едитор који обрађује улазни текст преко цевовода или из текстуалних фајлова. Међутим, нема интерактивни интерфејс, већ прима инструкције које се извршавају приликом обраде текста. Све се ово извршава у Басх-у и другим командним линијама.
Уз помоћ команде `sed`, можете обављати следеће радње:
- Селектовати текст
- Заменити текст
- Уметати редове у текст
- Брисати редове из текста
- Изменити оригинални фајл (или га сачувати)
Примери у овом тексту су структурирани тако да објасне концепте, а не да прикажу најкомплексније команде. Функције за проналажење шаблона и селекцију текста у команди `sed` се у великој мери ослањају на регуларне изразе (регуларни изрази). За ефикасну употребу команде `sed` је потребно основно разумевање ових израза.
Једноставан пример
Прво ћемо користити команду `echo` за прослеђивање текста команди `sed` преко цеви, како би `sed` заменио део текста. За то, укуцавамо следећу команду:
echo howtogonk | sed 's/gonk/geek/'
Команда `echo` прослеђује текст „howtogonk“ команди `sed`, која примењује једноставно правило замене (ознака „s“ представља замену). `sed` претражује улазни текст и замењује сва подударања првог стринга другим.
Реч „gonk“ се замењује са „geek“, а нови низ се приказује у прозору терминала.

Замене су најчешћа употреба команде `sed`. Пре него што се упустимо у детаље, потребно је да разумемо како селектовати и упаривати текст.
Селекција текста
За наше примере је потребан текстуални фајл. Користићемо фајл који садржи део стихова из епске поеме Семјуела Тејлора Колриџа „The Rime of the Ancient Mariner“.
Уносимо следећу команду да бисмо видели садржај фајла са командом `less`:
less coleridge.txt
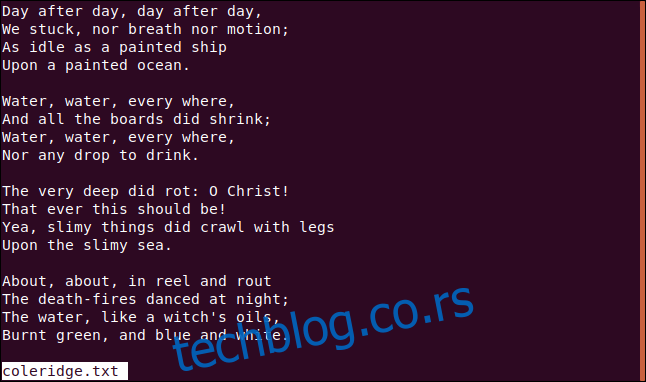
Да бисмо изабрали одређене линије из фајла, одређујемо почетни и крајњи ред жељеног опсега. Један број бира само тај један ред.
За издвајање редова од један до четири, уносимо ову команду:
sed -n '1,4p' coleridge.txt
Обратите пажњу на зарез између 1 и 4. Слово „p“ значи „прикажи упарене линије“. По подразумеваној вредности, `sed` штампа све редове. Видели бисмо сав текст из фајла, са упареним редовима који се штампају два пута. Да бисмо то спречили, користићемо опцију „-n“ (тихо) да уклонимо нежељен текст.
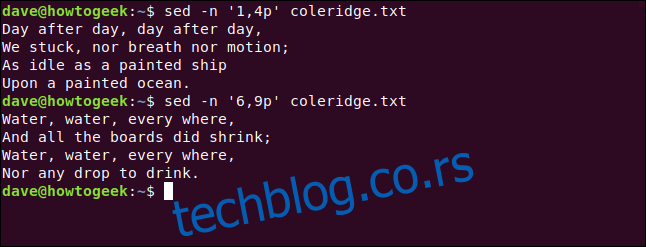
Мењамо бројеве редова да бисмо одабрали други стих, као што је приказано у наставку:
sed -n '6,9p' coleridge.txt
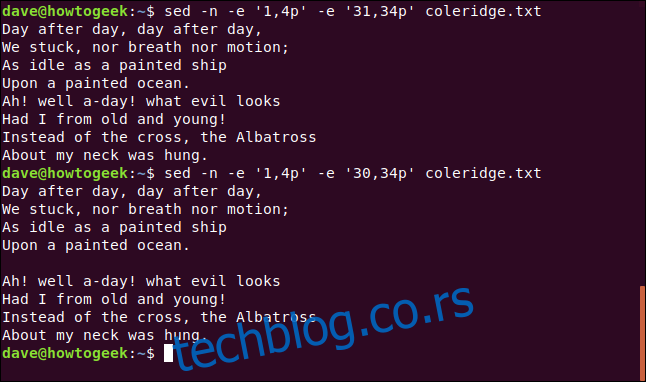
Опцију „-e“ (израз) можемо користити да извршимо више селекција. Са два израза можемо одабрати два стиха, на следећи начин:
sed -n -e '1,4p' -e '31,34p' coleridge.txt
Ако у другом изразу смањимо први број, можемо убацити празан простор између два стиха. Укуцавамо следећу команду:
sed -n -e '1,4p' -e '30,34p' coleridge.txt
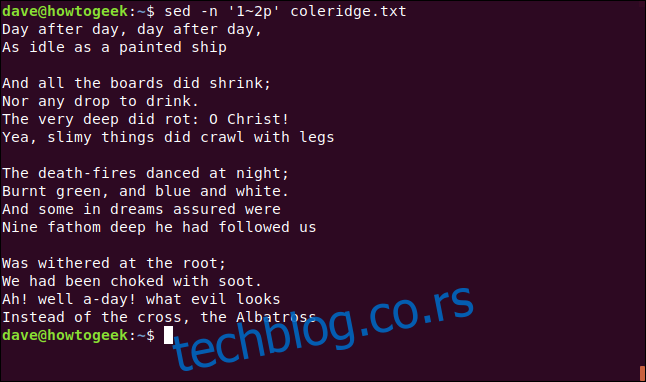
Такође можемо одабрати почетни ред и наложити команди `sed` да прође кроз фајл и штампа алтернативне редове, сваки пети ред, или прескочити било који број редова. Команда је слична оним које смо користили за одабир опсега. Овога пута ћемо користити тилду (~) уместо зареза да одвојимо бројеве.
Први број означава почетни ред. Други број говори команди `sed` које редове желимо да видимо након почетног. Број 2 означава сваки други ред, 3 сваки трећи ред, итд.
Уносимо следећу команду:
sed -n '1~2p' coleridge.txt
Нећемо увек знати где се у фајлу налази текст који тражимо, па бројеви редова неће увек бити од користи. Можемо користити команду `sed` да одаберемо редове који садрже одговарајуће текстуалне шаблоне. На пример, да издвојимо све редове који почињу са „И“.
Симбол (^) представља почетак реда. Наш термин претраге ћемо приложити косим цртама (/). Такође укључујемо размак иза „И“ како речи попут „Андроид“ не би биле укључене у резултат.
Читање `sed` скрипти може у почетку бити изазовно. „/p“ значи „штампање“, као у претходним командама. У следећој команди, међутим, му претходи коса црта:
sed -n '/^And /p' coleridge.txt
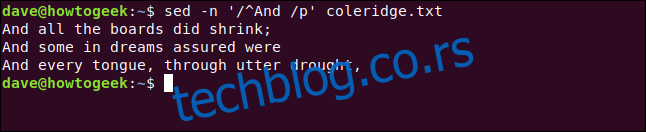
Три реда која почињу са „И“ се издвајају из фајла и приказују.
Замене
У нашем првом примеру, приказан је следећи основни формат за `sed` замену:
echo howtogonk | sed 's/gonk/geek/'
Слово „s“ говори команди `sed` да је у питању замена. Први низ је шаблон за претрагу, а други је текст којим замењујемо пронађени текст. Наравно, као и код свих Линукс ствари, детаљи су кључни.
Уносимо следећу команду да променимо сва појављивања речи „day“ у „week“, дајући тако морнару и албатросу више времена за повезивање:
sed -n 's/day/week/p' coleridge.txt
У првом реду се мења само друго појављивање речи „day“. То је зато што `sed` прекида рад након првог проналаска у реду. Потребно је додати „g“ на крај израза, као што је приказано у наставку, да извршимо глобалну претрагу, како би се обрадила сва подударања у сваком реду:
sed -n 's/day/week/gp' coleridge.txt
Ово проналази три од четири речи „day“ у првом реду. Пошто је прва реч „Day“, а `sed` прави разлику између великих и малих слова, не сматра ту инстанцу истом као „day“.
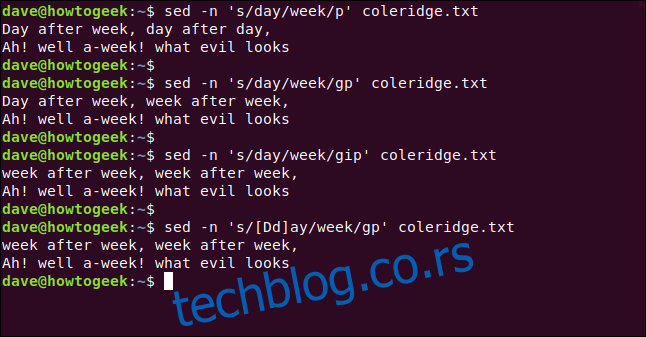
Уносимо следећу команду, додајући „i“ на крају израза да укажемо на неосетљивост на велика и мала слова:
sed -n 's/day/week/gip' coleridge.txt
Ово функционише, али можда нећемо увек желети да укључимо неосетљивост на велика и мала слова за све. У таквим случајевима можемо користити групу регуларних израза да додамо неосетљивост на мала и велика слова која је специфична за шаблон.
На пример, ако ставимо знакове у угласте заграде ([]), тумачиће се као „било који знак са ове листе знакова“.
Укуцавамо следећу команду и укључујемо „D“ и „d“ у групу, како бисмо били сигурни да се подудара и са „Day“ и са „day“:
sed -n 's/[Dd]ay/week/gp' coleridge.txt
Такође можемо ограничити замене на делове фајла. Рецимо да наш фајл садржи чудне размаке у првом стиху. Можемо користити следећу команду да видимо први стих:
sed -n '1,4p' coleridge.txt
Потражићемо два размака и заменити их једним. То ћемо урадити глобално како би се радња понављала кроз цео ред. Да будемо јасни, шаблон за претрагу је „размак, размак, звездица“, а низ за замену је један размак. „1,4“ ограничава замену на прва четири реда фајла.
sed -n '1,4 s/ */ /gp' coleridge.txt
Све то састављамо у следећу команду:
Ово добро функционише! Шаблон за претрагу је овде важан. Звездица (*) представља нула или више претходних знакова, што је размак. Дакле, шаблон за претрагу тражи низове од једног или више размака.
sed -n '1,4 s/ */ /gp' coleridge.txt
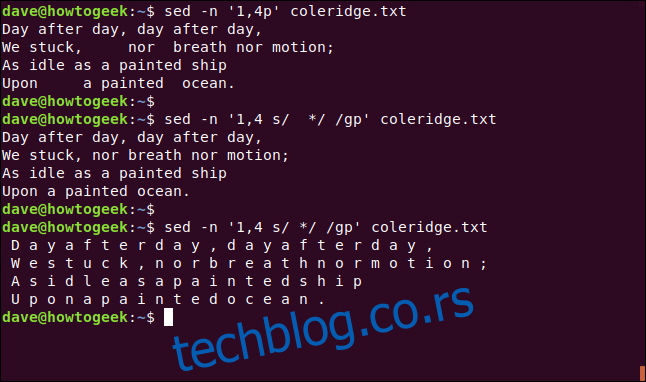
Ако заменимо један размак за било коју секвенцу од више размака, вратићемо фајл у уобичајено стање, са једним размаком између сваке речи. Ово ће такође заменити један размак једним размаком у неким случајевима, али то неће негативно утицати на резултат. Добићемо жељени исход.
Ако унесемо следећу команду и смањимо шаблон за претрагу на један размак, видећете зашто је потребно укључити два размака:
Пошто звездица (*) одговара нули или више претходних знакова, сваки знак који није размак види као „нулти размак“ и примењује замену на њега.
sed -n -e 's/motion/flutter/gip' -e 's/ocean/gutter/gip' coleridge.txt
Међутим, ако укључимо два размака у шаблон претраге, `sed` мора пронаћи бар један знак размака пре него што примени замену. Ово осигурава да ће знакови без размака остати нетакнути.
sed -n 's/motion/flutter/gip;s/ocean/gutter/gip' coleridge.txt
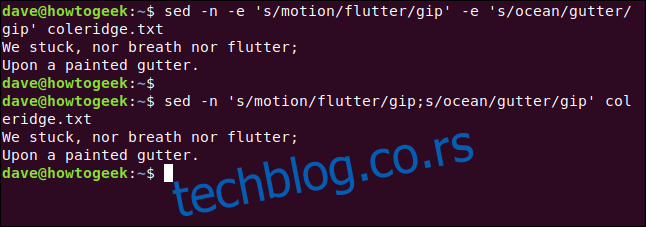
Уносимо следећу команду, користећи „-e“ (израз), који смо раније користили, и који нам омогућава да извршимо две или више замена истовремено:
sed -n 's/[Dd]ay/week/gp' coleridge.txt
Исти резултат можемо постићи ако користимо тачку и зарез (;) да одвојимо два израза, на следећи начин:
Када смо заменили „day“ са „week“ у следећој команди, инстанца „day“ у изразу „good day“ је такође замењена:
sed -n '/after/ s/[Dd]ay/week/gp' coleridge.txt
Да бисмо то спречили, можемо покушати замене само на линијама које одговарају другом шаблону. Ако модификујемо команду тако да има шаблон претраге на почетку, радићемо само на линијама које одговарају том шаблону.
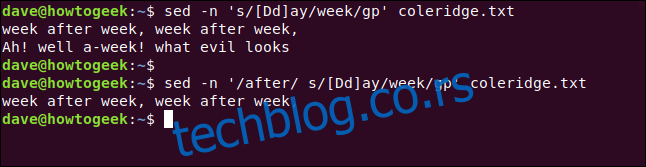
Уносимо следећу команду да би наш шаблон био реч „after“:
Тиме добијамо жељени одговор.
Комплексније замене
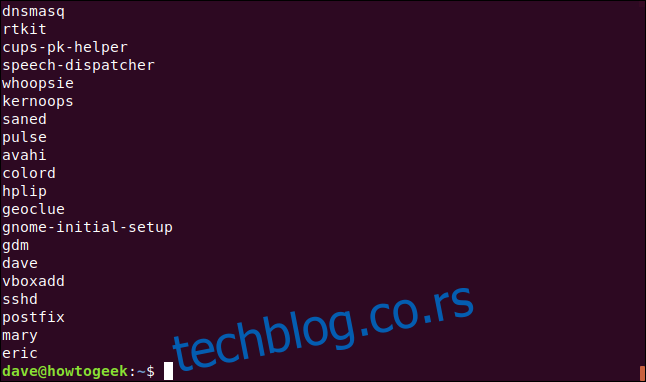
Прекинимо са Колриџом и користимо `sed` за издвајање имена из фајла `etc/passwd`. [()] Постоје краћи начини да се ово уради (о томе касније), али ћемо овде користити дужи пут да демонстрирамо још један концепт. Сваки пронађени део шаблона претраге (који се називају под-изрази) може бити нумерисан (највише до девет делова). Ове бројеве можете користити у `sed` командама за референцирање одређених под-израза.
Под-израз мора бити у заградама `()`:
sed 's/([^:]*).*/1/' /etc/passwd

Заградама мора претходити коса црта `\` да се не би третирале као обичан карактер.
За то, укуцајте следеће:
Рашчланимо команду: `sed ‘s/`: команда `sed` и почетак израза замене.
`([^:]*)`: почетна заграда `(` која обухвата под-израз, којој претходи обрнута коса црта `\`. Први под-израз термина за претрагу садржи групу у угластим заградама. Карет (`^`) значи „не“ када се користи у групи. Група значи да ће се сваки карактер који није двотачка (:) прихватити као подударање.
`(.*)`: Завршна заграда `)` са претходном косом цртом `\`.
`.*`: Овај други под-израз претраге значи „било који карактер и било који број њега“.
`/1`: Део израза за замену садржи `\1`. Ово представља текст који одговара првом под-изразу.
`/’`: Завршна коса црта `/` и једноструки наводник `’` завршавају `sed` команду.
Све ово значи да ћемо тражити било који низ знакова који не садржи двотачку (:), што ће бити прва инстанца пронађеног текста. Затим тражимо било шта друго у том реду, што ће бити друга инстанца пронађеног текста. Цео ред ћемо заменити текстом који одговара првом под-изразу. [()] Сваки ред у фајлу `/etc/passwd` почиње корисничким именом које се завршава двотачком. Поклапамо све до прве двотачке, а затим ту вредност замењујемо целим редом. Дакле, изоловали смо корисничка имена.
Затим ћемо други под-израз ставити у заграде:
sed 's/([^:]*)(.*)/2/' /etc/passwd

како бисмо га могли референцирати бројем. Такође ћемо заменити `\1` са `\2`. Наша команда ће сада заменити цео ред са свиме од прве двотачке (:) до краја реда.
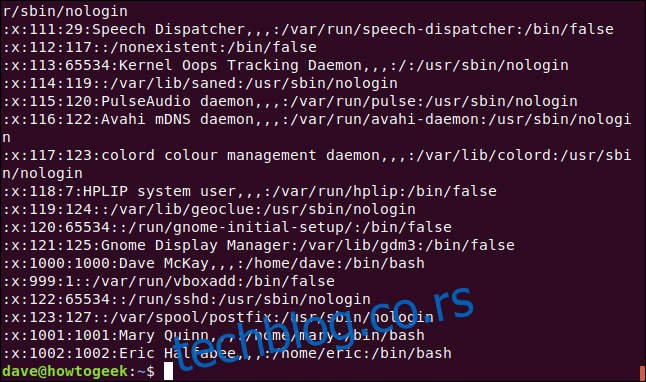
Укуцавамо следећу команду:
Ове мале промене инвертују значење команде и добијамо све осим корисничких имена.
Сада, погледајмо брз и једноставан начин да се то уради.
sed 's/:.*//" /etc/passwd

Наш шаблон за претрагу иде од прве двотачке (:) до краја реда. Пошто је наш израз за замену празан (`//`), нећемо заменити текст ничим.
Дакле, укуцавамо следећу команду, одсецајући све од прве две тачке (:) до краја реда, остављајући само корисничка имена:
cat geeks.txt
Погледајмо пример у којем референцирамо прво и друго пронађено подударање у истој команди.
sed 's/^(.*),(.*)$/2,1 /g' geeks.txt
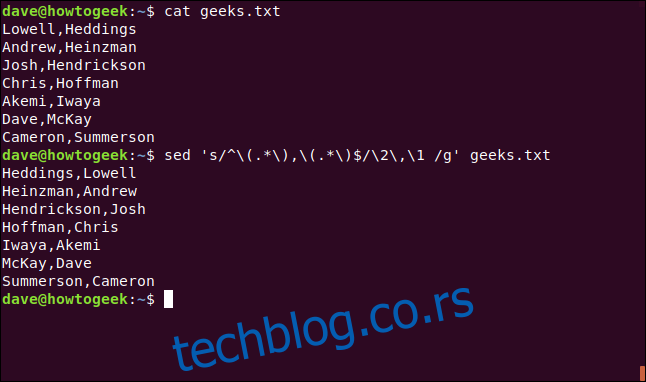
Имамо фајл са зарезима (,) који раздвајају имена и презимена. Желимо да их наведемо као „презиме, име“. Можемо користити команду `cat`, као што је приказано у наставку, да видимо шта се налази у фајлу:
Као и многе `sed` команде, следећа може изгледати непробојно:
Ово је команда за замену попут осталих које смо користили, а шаблон претраге је прилично једноставан. Раставићемо га:
`sed ‘s/`: нормална команда замене.
`^`: Пошто карет није у групи, то значи „почетак линије“.
`(.*),`: Први под-израз је било који број било ког карактера. У загради је `()`, којој претходи обрнута коса црта `\` како бисмо могли да је референцирамо бројем. Наш цео шаблон за претрагу до сада се преводи као претрага од почетка реда до првог зареза (,) за било који број било ког карактера.
`(.*)`: Следећи под-израз је (опет) било који број било ког знака. Такође је затворен у заградама `()`, којима претходи обрнута коса црта `\` како бисмо могли да референцирамо текст по броју.
`$/`: Знак долара ($) представља крај реда и омогућава да се наша претрага настави до краја реда. Користили смо ово једноставно да уведемо знак долара. Овде нам баш и не треба, јер би звездица `*` ишла до краја реда у овом случају. Коса црта (/) завршава одељак шаблона за претрагу.
`\2,\1 /g`: Пошто смо наша два под-израза ставили у заграде, можемо се позвати на оба по бројевима. Пошто желимо да обрнемо редослед, куцамо их као друго подударање, па прво. Бројевима мора претходити обрнута коса црта `\`.
`/g`: Ово омогућава команди да ради глобално на свакој линији.
sed '/neck/c Around my wrist was strung' coleridge.txt

`geeks.txt`: Фајл на којем радимо.
Такође можете користити команду `c` (заменити) да замените читаве редове који одговарају вашем шаблону претраге. Укуцавамо следећу команду да бисмо потражили ред са речју „neck“ и заменили га новим текстом:
Наша нова линија се сада појављује на дну нашег издвајања.
Уметање редова и текста
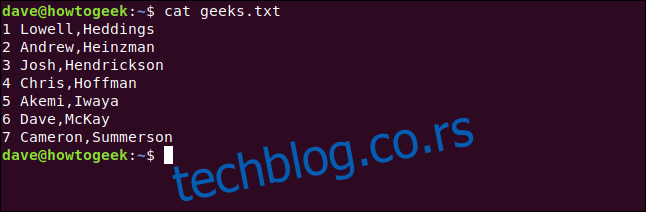
Ево фајла са којим ћемо радити:
`cat geeks.txt`
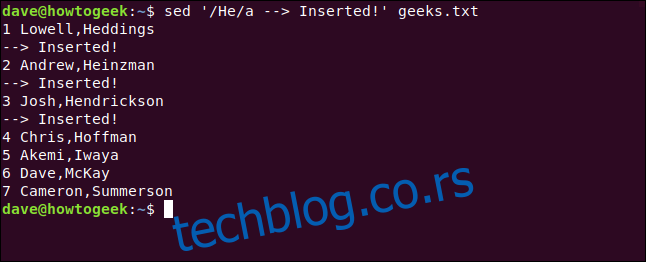
sed '/He/a --> Inserted!' geeks.txt
Нумерисали смо редове да бисмо их лакше пратили.
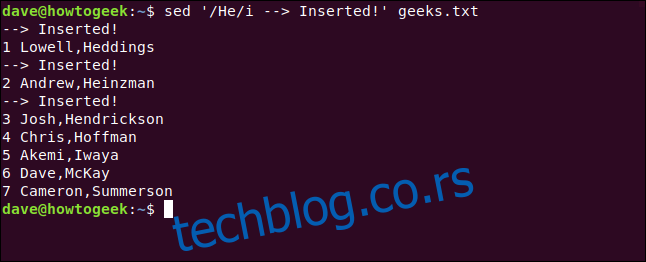
sed '/He/i --> Inserted!' geeks.txt
Укуцавамо следећу команду да бисмо потражили редове који садрже реч „He“ и убацили нови ред испод њих:
Откуцавамо следећу команду и укључујемо команду `i` (insert) да бисмо уметнули нови ред изнад оних који садрже одговарајући текст:
sed 's/.*/--> Inserted &/' geeks.txt
<img decoding=“async“ class=“alignnone wp-image-666741 size-full“ src=“https://techblog.co.rs/wp-content/uploads/2022/01/1641681967_842_Како-користити-команду-сед-на-Линуку.png“ alt=“Приказ команде