Prema statističkim podacima koje iznosi Forbes, čak 90% globalnih organizacija koristi analitiku velikih podataka pri izradi svojih investicionih izveštaja.
Sa sve većom zastupljenošću velikih podataka, prirodno dolazi do značajnog porasta prilika za zapošljavanje u oblasti Hadoop-a, više nego ikada pre.
Stoga, u cilju da vam pomognemo da ostvarite željenu poziciju stručnjaka za Hadoop, pripremili smo ovaj članak sa pitanjima i odgovorima za intervju. Neka vam ovaj materijal posluži kao pomoć u pripremi za razgovor za posao.
Možda će vas saznanje o rasponu plata u području Hadoop-a i Big Data, koji ove uloge čine izuzetno unosnim, dodatno motivisati da zablistate na intervjuu? 🤔
- Prema podacima sa indeed.com, programer Big Data Hadoop-a u Sjedinjenim Američkim Državama ostvaruje prosečnu godišnju platu u iznosu od 144.000 dolara.
- Prema itjobswatch.co.uk, prosečna plata programera Big Data Hadoop-a iznosi 66.750 funti.
- U Indiji, izvori sa indeed.com navode da bi oni zarađivali prosečnu platu od 1.600.000 INR.
Izgleda prilično unosno, zar ne? Sada, krenimo u otkrivanje tajni Hadoop-a.
Šta je Hadoop?
Hadoop je popularan okvir razvijen u Java programskom jeziku. Koristi programske modele za obradu, skladištenje i analizu obimnih skupova podataka.
Njegov dizajn omogućava skaliranje od jednog servera na više računara, pružajući mogućnost lokalnog računanja i skladištenja. Pored toga, sposobnost detekcije i obrade grešaka na nivou aplikacije, rezultirajući visoko dostupnim uslugama, čini Hadoop izuzetno pouzdanim.
Sada pređimo na najčešća pitanja sa intervjua za posao u vezi sa Hadoop-om i ponudimo precizne odgovore.
Pitanja i odgovori za intervju vezana za Hadoop
Šta predstavlja jedinicu za skladištenje u Hadoop-u?
Odgovor: Jedinica za skladištenje u Hadoop-u poznata je kao Hadoop Distributed File System (HDFS), odnosno Hadoop distribuirani sistem datoteka.
Koja je razlika između mrežne memorije (NAS) i Hadoop distribuiranog sistema datoteka (HDFS)?
Odgovor: HDFS, koji čini primarni prostor za skladištenje podataka u Hadoop-u, predstavlja distribuirani sistem datoteka dizajniran za čuvanje velikih fajlova, koristeći standardni hardver. Sa druge strane, NAS je server za skladištenje računarskih podataka na nivou datoteke, koji omogućava pristup podacima heterogenim grupama klijenata.
Dok NAS čuva podatke na specijalizovanom hardveru, HDFS distribuira blokove podataka na sve mašine unutar Hadoop klastera.
NAS koristi vrhunske uređaje za skladištenje, što ga čini prilično skupim, dok je standardni hardver koji se koristi u HDFS-u isplativiji.
NAS skladišti podatke odvojeno od računanja, što ga čini nepogodnim za MapReduce. Suprotno tome, dizajn HDFS-a omogućava mu da efikasno radi sa MapReduce okvirom. U MapReduce-u, proračuni se premeštaju ka podacima, umesto obrnuto.
Objasnite MapReduce u Hadoop-u i proces „shuffling“ (premeštanje)
Odgovor: MapReduce se odnosi na dva distinktivna zadatka koja Hadoop programi obavljaju kako bi omogućili visoku skalabilnost na stotinama ili čak hiljadama servera unutar Hadoop klastera. „Shuffling“, sa druge strane, podrazumeva proces prenosa izlaza mapiranja od „Mapper“-a ka željenom „Reducer“-u u okviru MapReduce-a.
Približite arhitekturu Apache Pig-a
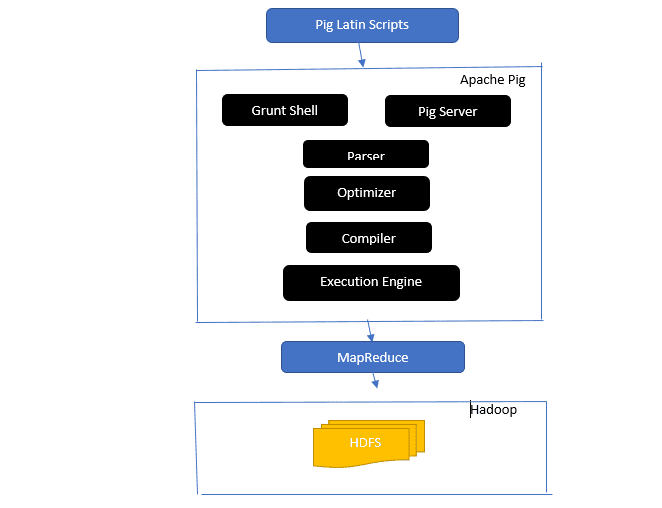 Arhitektura Apache Pig-a
Arhitektura Apache Pig-a
Odgovor: Arhitektura Apache Pig-a obuhvata Pig Latin interpreter koji obrađuje i analizira velike skupove podataka koristeći Pig Latin skripte.
Apache Pig se takođe sastoji od skupova podataka nad kojima se sprovode operacije kao što su spajanje, učitavanje, filtriranje, sortiranje i grupisanje.
Pig Latin jezik koristi izvršne mehanizme poput Grant shell-a, UDF-ova i ugrađenih funkcija za pisanje Pig skripti koje izvršavaju tražene zadatke.
Pig olakšava rad programerima tako što prevodi napisane skripte u niz Map-Reduce zadataka.
Komponente arhitekture Apache Pig uključuju:
- Parser – analizira Pig skripte, proveravajući sintaksu i vršeći proveru tipa. Izlaz parser-a predstavlja izjave i logičke operatore Pig Latina i poznat je kao DAG (Directed Acyclic Graph – usmereni aciklični graf).
- Optimizator – implementira logičke optimizacije kao što su projekcija i potiskivanje na DAG.
- Kompajler – prevodi optimizovani logički plan iz optimizatora u niz MapReduce zadataka.
- Execution Engine – predstavlja mesto gde se konačno izvršavaju MapReduce zadaci, generišući željeni izlaz.
- Način izvršavanja – režimi izvršavanja u Apache Pig-u uglavnom uključuju lokalni i Map Reduce.
Odgovor: Metastore usluga u lokalnom Metastore-u radi u istom JVM-u kao Hive, ali se povezuje sa bazom podataka koja radi u zasebnom procesu, na istoj ili udaljenoj mašini. S druge strane, Metastore u Remote Metastore-u radi u svom JVM-u, odvojenom od JVM servisa Hive.
Šta je pet V velikih podataka?
Odgovor: Ovih pet V predstavljaju ključne karakteristike velikih podataka. To uključuje:
- Vrednost: Veliki podaci nastoje da pruže značajne benefite i visok povrat ulaganja (ROI) za organizacije koje koriste velike podatke u svojim operacijama. Veliki podaci donose ovu vrednost kroz otkrivanje uvida i prepoznavanje obrazaca, što rezultira snažnijim odnosima sa klijentima i efikasnijim operacijama, između ostalih prednosti.
- Raznovrsnost: ovo predstavlja heterogenost tipova prikupljenih podataka. Različiti formati uključuju CSV, video zapise, audio itd.
- Obim: definiše značajnu količinu i veličinu podataka kojima organizacija upravlja i analizira. Ovi podaci pokazuju eksponencijalni rast.
- Brzina: predstavlja eksponencijalnu brzinu rasta podataka.
- Verodostojnost: odnosi se na to koliko su dostupni podaci „neizvesni“ ili „netačni“, usled toga što su podaci nepotpuni ili nedosledni.
Objasnite različite tipove podataka Pig Latin-a.
Odgovor: Tipovi podataka u Pig Latin-u se dele na atomske i kompleksne tipove podataka.
Atomski tipovi podataka su osnovni tipovi podataka, slični onima koji se koriste u drugim jezicima. Oni uključuju sledeće:
- Int – Ovaj tip podataka predstavlja potpisani 32-bitni ceo broj. Primer: 13
- Long – Long predstavlja 64-bitni ceo broj. Primer: 10L
- Float – predstavlja potpisani 32-bitni broj sa pokretnim zarezom. Primer: 2.5F
- Double – predstavlja potpisani 64-bitni broj sa pokretnim zarezom. Primer: 23.4
- Boolean – predstavlja logičku vrednost. Uključuje: True/False
- Datum i vreme – predstavlja vrednost datuma i vremena. Primer: 1980-01-01T00:00.00.000+00:00
Kompleksni tipovi podataka uključuju:
- Mapa – mapa predstavlja skup parova ključ/vrednost. Primer: [‘color’#’yellow’, ‘number’#3]
- Torba – kolekcija je skupa torki i koristi simbol ‘{ }’. Primer: {(Henry, 32), (Kitty, 47)}
- Torka – torka definiše uređeni skup polja. Primer: (starost, 33)
Šta su Apache Oozie i Apache ZooKeeper?
Odgovor: Apache Oozie je Hadoop planer zadužen za zakazivanje i povezivanje Hadoop poslova u jedinstveni logički posao.
Apache ZooKeeper, s druge strane, koordinira sa različitim servisima u distribuiranom okruženju. Programerima štedi vreme jednostavnim izlaganjem jednostavnih usluga kao što su sinhronizacija, grupisanje, održavanje konfiguracije i imenovanje. Apache ZooKeeper takođe pruža gotovu podršku za čekanje u redu i izbor lidera.
Koja je uloga „Combiner“, „RecordReader“ i „Partitioner“ u MapReduce operaciji?
Odgovor: „Combiner“ deluje kao mini reduktor. On prihvata i obrađuje podatke iz zadataka mapiranja, a zatim prosleđuje izlaz podataka u fazu redukovanja.
„RecordReader“ komunicira sa „InputSplit“-om i konvertuje podatke u parove ključ-vrednost, kako bi ih „mapper“ mogao adekvatno pročitati.
„Partitioner“ je odgovoran za određivanje broja potrebnih „reducer“ zadataka za sumiranje podataka i utvrđivanje načina na koji se izlazi kombinatora šalju ka reduktoru. „Partitioner“ takođe kontroliše ključno particionisanje izlaza srednjeg mapiranja.
Navedite različite distribucije Hadoop-a specifične za vendore.
Odgovor: Različiti vendori koji proširuju mogućnosti Hadoop-a uključuju:
- IBM Open platformu.
- Cloudera CDH Hadoop distribuciju
- MapR Hadoop distribuciju
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Key package velikih podataka
- Datastax Enterprise Analytics
- HDInsight kompanije Microsoft Azure – Hadoop distribuciju zasnovanu na oblaku.
Zašto je HDFS otporan na greške?
Odgovor: HDFS replicira podatke na različitim čvorovima podataka, što ga čini otpornim na greške. Čuvanje podataka na više čvorova omogućava preuzimanje sa drugih čvorova ukoliko se jedan čvor sruši.
Napravite razliku između federacije i visoke dostupnosti.
Odgovor: HDFS Federacija nudi toleranciju na greške koja omogućava neprekidan protok podataka na jednom čvoru u slučaju da se drugi čvor sruši. Sa druge strane, visoka dostupnost zahteva dve odvojene mašine koje zasebno konfigurišu aktivni „NameNode“ i sekundarni „NameNode“ na prvoj i drugoj mašini.
Federacija može imati neograničen broj nepovezanih „NameNode“-a, dok su u visokoj dostupnosti dostupna samo dva povezana „NameNode“-a, aktivni i pripravni, koji rade neprekidno.
„NameNode“-ovi u federaciji dele skup metapodataka, pri čemu svaki „NameNode“ ima svoj namenski skup. U visokoj dostupnosti, međutim, aktivni nazivni čvorovi pokreću svaki po jedan, dok rezervni čvorovi imena ostaju neaktivni i samo povremeno ažuriraju svoje metapodatke.
Kako se može pronaći status blokova i zdravlje sistema datoteka?
Odgovor: Koristite komandu `hdfs fsck /`, na nivou root korisnika, ili unutar pojedinačnog direktorijuma, kako biste proverili zdravstveno stanje HDFS sistema datoteka.
Primer komande `hdfs fsck` u upotrebi:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Opis komande:
- -files: Štampa datoteke koje se proveravaju.
- –locations: Štampa lokacije svih blokova tokom provere.
Komanda za proveru statusa blokova:
hdfs fsck <path> -files -blocks
- <putanja>: Započinje provere sa putanje koja je ovde prosleđena.
- –blocks: Štampa blokove datoteka tokom provere
Kada se koriste komande `rmadmin-refreshNodes` i `dfsadmin-refreshNodes`?
Odgovor: Ove dve komande su korisne za osvežavanje informacija o čvoru, bilo tokom puštanja u rad, ili kada je puštanje čvora u rad završeno.
Komanda `dfsadmin-refreshNodes` pokreće HDFS klijenta i osvežava konfiguraciju čvora „NameNode“. Komanda `rmadmin-refreshNodes`, sa druge strane, izvršava administrativne zadatke „ResourceManager“-a.
Šta je „checkpoint“ (kontrolna tačka)?
Odgovor: „Checkpoint“ je operacija koja spaja poslednje izmene sistema datoteka sa najnovijom FSImage, kako bi datoteke dnevnika izmena ostale dovoljno male da ubrzaju proces pokretanja „NameNode“-a. „Checkpoint“ se javlja u sekundarnom imenom čvoru.
Zašto se HDFS koristi za aplikacije koje imaju velike skupove podataka?
Odgovor: HDFS obezbeđuje „DataNode“ i „NameNode“ arhitekturu koja implementira distribuirani sistem datoteka.
Ove dve arhitekture obezbeđuju pristup podacima visokih performansi preko visoko skalabilnih Hadoop klastera. Njegov „NameNode“ skladišti metapodatke sistema datoteka u RAM-u, što rezultira količinom memorije koja ograničava broj datoteka HDFS sistema datoteka.
Šta radi komanda `jps`?
Odgovor: Komanda „Java Virtual Machine Process Status“ (JPS) proverava da li su određeni Hadoop demoni, uključujući „NodeManager“, „DataNode“, „NameNode“ i „ResourceManager“ pokrenuti ili ne. Ova komanda je neophodna za pokretanje sa root-a, kako bi se proverili operativni čvorovi u hostu.
Šta je „spekulativno izvršenje“ u Hadoop-u?
Odgovor: Ovo je proces u kojem glavni čvor u Hadoop-u, umesto da popravi otkrivene spore zadatke, pokreće drugu instancu istog zadatka kao rezervni zadatak (spekulativni zadatak) na drugom čvoru. Spekulativno izvršenje štedi mnogo vremena, posebno u okruženju intenzivnog radnog opterećenja.
Navedite tri režima u kojima Hadoop može da radi.
Odgovor: Tri osnovna režima u kojima Hadoop radi uključuju:
- Samostalni čvor je podrazumevani režim koji pokreće Hadoop usluge koristeći lokalni sistem datoteka i jedan Java proces.
- Pseudo-distribuirani čvor izvršava sve Hadoop usluge koristeći jednu instancu Hadoop implementacije.
- Potpuno distribuirani čvor pokreće Hadoop master i slave usluge koristeći zasebne čvorove.
Šta je UDF?
Odgovor: UDF (User-Defined Functions), odnosno korisnički definisane funkcije, vam omogućavaju da kodirate sopstvene prilagođene funkcije koje možete koristiti za obradu vrednosti kolona tokom Impala upita.
Šta je DistCp?
Odgovor: DistCp, ili Distributed Copy, skraćeno, je koristan alat za veliko kopiranje podataka, bilo između ili unutar klastera. Koristeći MapReduce, DistCp efikasno implementira distribuirano kopiranje velike količine podataka, između ostalih zadataka kao što su rukovanje greškama, oporavak i izveštavanje.
Odgovor: Hive metastore je usluga koja čuva metapodatke Apache Hive za Hive tabele u relacionoj bazi podataka, kao što je MySQL. Pruža API usluge metastore, omogućavajući centralni pristup metapodacima.
Definišite RDD.
Odgovor: RDD, skraćeno od Resilient Distributed Datasets, je Spark-ova struktura podataka i nepromenljiva distribuirana kolekcija vaših elemenata podataka koja se obrađuje na različitim čvorovima klastera.
Kako se izvorne biblioteke mogu uključiti u YARN poslove?
Odgovor: Ovo možete implementirati bilo korišćenjem `-Djava.library.path` opcije u komandi ili postavljanjem `LD_LIBRARY_PATH` u `.bashrc` datoteci, koristeći sledeći format:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Objasnite WAL u HBase-u.
Odgovor: „Write Ahead Log“ (WAL), odnosno dnevnik pisanja unapred, je protokol za oporavak koji beleži promene podataka u „MemStore“-u u HBase-u u skladištu zasnovanom na datotekama. WAL obnavlja ove podatke ako se „RegionServer“ sruši pre nego što se „MemStore“ ispere.
Da li je YARN zamena za Hadoop MapReduce?
Odgovor: Ne, YARN nije zamena za Hadoop MapReduce. Umesto toga, moćna tehnologija poznata kao Hadoop 2.0 ili MapReduce 2 podržava MapReduce.
Koja je razlika između `ORDER BY` i `SORT BY` u Hive-u?
Odgovor: Dok obe komande preuzimaju podatke na sortiran način u Hive-u, rezultati korišćenja `SORT BY` mogu biti samo delimično uređeni.
Pored toga, `SORT BY` zahteva reduktor da bi se redovi poređali. Ovi reduktori potrebni za konačni izlaz mogu takođe biti višestruki. U ovom slučaju, konačni rezultat može biti delimično uređen.
Sa druge strane, `ORDER BY` zahteva samo jedan reduktor za ukupan red izlaza. Takođe možete koristiti ključnu reč `LIMIT` koja smanjuje ukupno vreme sortiranja.
Koja je razlika između Spark-a i Hadoop-a?
Odgovor: Iako su i Hadoop i Spark okviri za distribuiranu obradu, njihova ključna razlika je u načinu obrade. Dok je Hadoop efikasan za grupnu obradu, Spark je efikasan za obradu podataka u realnom vremenu.
Pored toga, Hadoop uglavnom čita i upisuje datoteke u HDFS, dok Spark koristi koncept „Resilient Distributed Dataset“ za obradu podataka u RAM-u.
Na osnovu njihovog kašnjenja, Hadoop je računarski okvir sa visokim kašnjenjem bez interaktivnog režima za obradu podataka, dok je Spark računarski okvir sa niskim kašnjenjem koji podatke obrađuje interaktivno.
Uporedite Sqoop i Flume.
Odgovor: Sqoop i Flume su Hadoop alati koji prikupljaju podatke iz različitih izvora i učitavaju podatke u HDFS.
- Sqoop (SQL-to-Hadoop) izdvaja strukturirane podatke iz baza podataka, uključujući Teradata, MySQL, Oracle, itd., dok je Flume koristan za izdvajanje nestrukturiranih podataka iz različitih izvora i njihovo učitavanje u HDFS.
- Kada je reč o događajima, Flume je vođen događajima, dok Sqoop nije.
- Sqoop koristi arhitekturu zasnovanu na konektorima, gde konektori znaju kako da se povežu sa drugim izvorima podataka. Flume koristi arhitekturu zasnovanu na agentima, pri čemu je kod napisan kao agent zadužen za preuzimanje podataka.
- Zahvaljujući Flume-ovoj distribuiranoj prirodi, on može lako da prikuplja i agregira podatke. Sqoop je koristan za paralelni prenos podataka, što rezultira izlazom u više fajlova.
Objasnite BloomMapFile.
Odgovor: BloomMapFile je klasa koja proširuje klasu MapFile i koristi dinamičke filtere koji pružaju brzi test članstva za ključeve.
Navedite razliku između HiveQL-a i PigLatina.
Odgovor: Dok je HiveQL deklarativni jezik sličan SQL-u, PigLatin je proceduralni jezik toka podataka visokog nivoa.
Šta je čišćenje podataka?
Odgovor: Čišćenje podataka je ključan proces uklanjanja ili ispravljanja identifikovanih grešaka u podacima, koje uključuju netačne, nepotpune, oštećene, duplirane i pogrešno formatirane podatke unutar skupa podataka.
Cilj ovog procesa je da se poboljša kvalitet podataka i obezbede tačnije, doslednije i pouzdanije informacije, neophodne za efikasno donošenje odluka unutar organizacije.
Zaključak💃
Sa trenutnim porastom prilika za zapošljavanje u oblasti velikih podataka i Hadoop-a, možda biste želeli da povećate svoje šanse da se zaposlite. Pitanja i odgovori za Hadoop intervju u ovom članku će vam pomoći da budete uspešni na predstojećem intervjuu.
Nakon toga, možete istražiti dobre resurse za učenje velikih podataka i Hadoop-a.
Srećno! 👍