Dugogodišnja praksa u izgradnji automatizovanih softverskih sistema podrazumevala je postavljanje brojnih servera sa specifičnim konfiguracijama procesora, memorije, skladišnog prostora i drugih resursa. Nakon toga, formirao bi se tim administratora koji bi se starali o tim sistemima. Razvojni tim bi potom preuzimao infrastrukturu i započinjao procese koji su povezivali servere.
Ovaj proces može biti kompleksan, jer uključuje brojne različite grupe koje sarađuju na zajedničkom cilju. Takvi sukobi interesa mogu predstavljati izazov.
Ovakav pristup može biti i prilično skup. Zahteva angažovanje administratora i njihovo prisustvo na platnom spisku. Serveri, čak i kada nisu aktivno korišćeni, troše resurse radeći neprekidno.
Da bi se tokom vremena održale optimalne performanse, neophodno je imati rešenje za automatsko skaliranje koje dinamički prilagođava resurse servera potrebama.
Platforma u oblaku donosi značajnu prednost: omogućava kreiranje celokupne arhitekture bez potrebe za uspostavljanjem klastera servera. Sa stanovišta administracije, nema potrebe za održavanjem.
Ovo je ekonomična opcija za startape i projekte u fazi razvoja minimalno održivog proizvoda (MVP). Predstavlja dobru polaznu tačku ukoliko je teško predvideti buduće opterećenje produkcije i aktivnosti korisnika. U ovakvim situacijama može biti teško odrediti optimalnu konfiguraciju klastera servera.
Automatizacija procesa putem cloud usluga bez servera je ono što definiše arhitekturu bez servera. Povezuje različite servise i daje rezultate koji su slični onima koje pružaju tradicionalni klasteri servera.
U nastavku sledi primer izgradnje takve arhitekture korišćenjem isključivo izvornih AWS servisa.
Usvajanje toka usluga bez servera
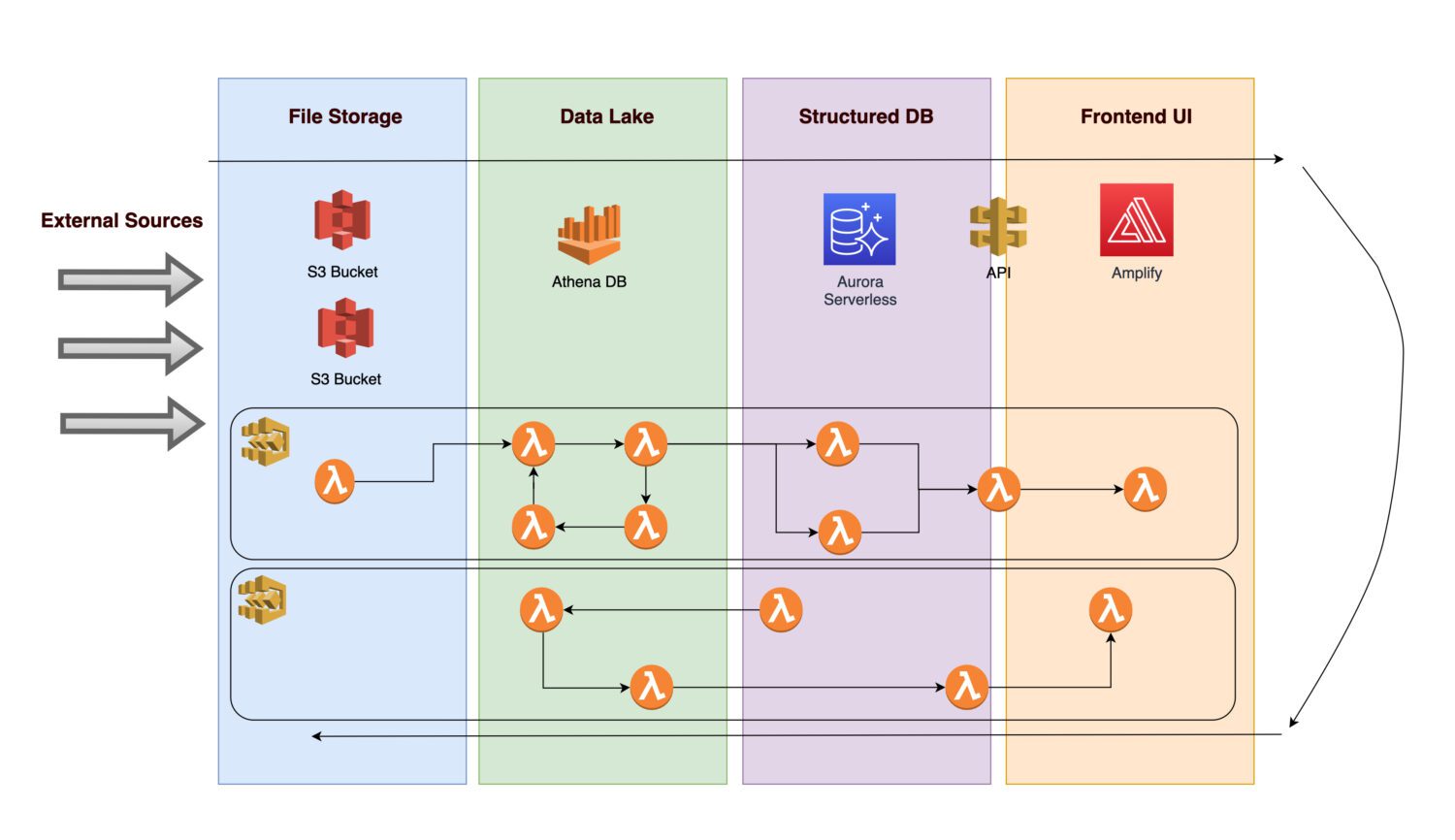
Zamislite da želite da kreirate platformu za prikupljanje raznovrsnih podataka i slika (ili fotografija) infrastrukture specifičnih resursa (ovo može biti bilo koja proizvodna ili komunalna imovina).
- U cilju omogućavanja buduće analitike, ulazne podatke je najpre potrebno prikupiti i uneti u sistem.
- Nakon primene definisanih poslovnih pravila, pozadinski proces čuva izračunate izlaze kao normirane informacije u relacijskoj bazi podataka.
- Aplikacije na prednjoj strani prikazuju normirane podatke, omogućavajući korisnicima uvid u rezultate.
Pogledajmo komponente koje ovakva arhitektura može da obuhvati.
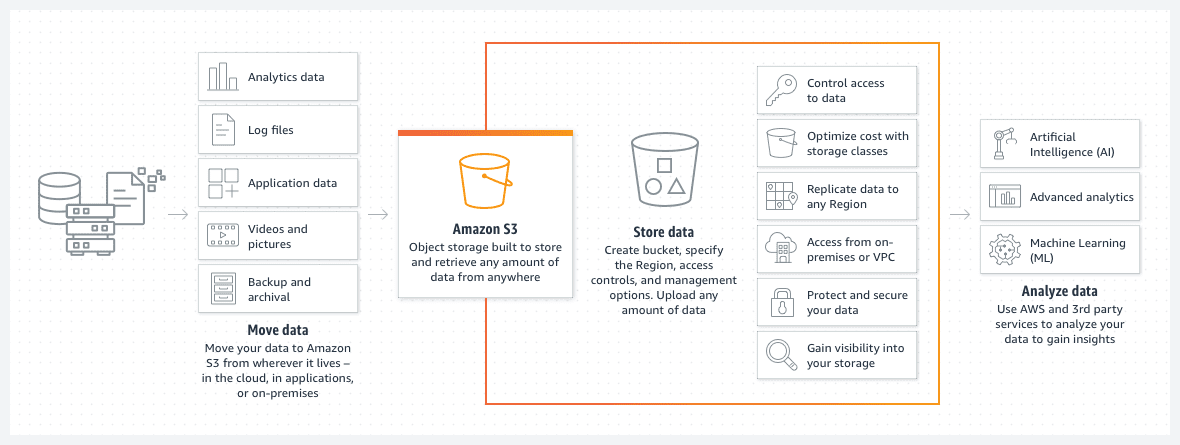
AWS S3 segmenti
 Izvor: aws.amazon.com
Izvor: aws.amazon.com
Amazon S3 segmenti predstavljaju idealno rešenje za skladištenje datoteka ili slika u AWS oblaku. Cena skladištenja podataka u S3 segmentu je izuzetno povoljna. Dodatno, uvođenje S3 politike životnog ciklusa segmenta dodatno smanjuje ove troškove.
Ovakva politika automatski premešta starije datoteke u različite klase S3 segmenata, kao što su arhivski ili duboko arhivski pristup. Klase se razlikuju i po brzini pristupa, ali za stare podatke to je manje važno. Prvenstvena svrha je pristup arhiviranim podacima u hitnim slučajevima, a ne za standardne operacije.
- Podatke možete organizovati u poddirektorijume.
- Neophodno je postaviti odgovarajuća ograničenja dozvola.
- Dodajte oznake segmentima radi lakše identifikacije i moguće primene u okviru dinamičkih S3 politika segmenta.
- Segment je dizajniran da bude bez servera, predstavljajući jednostavno mesto za skladištenje vaših podataka.
S3 segment je po svojoj strukturi bez servera. To je jednostavno skladišni prostor za vaše informacije.
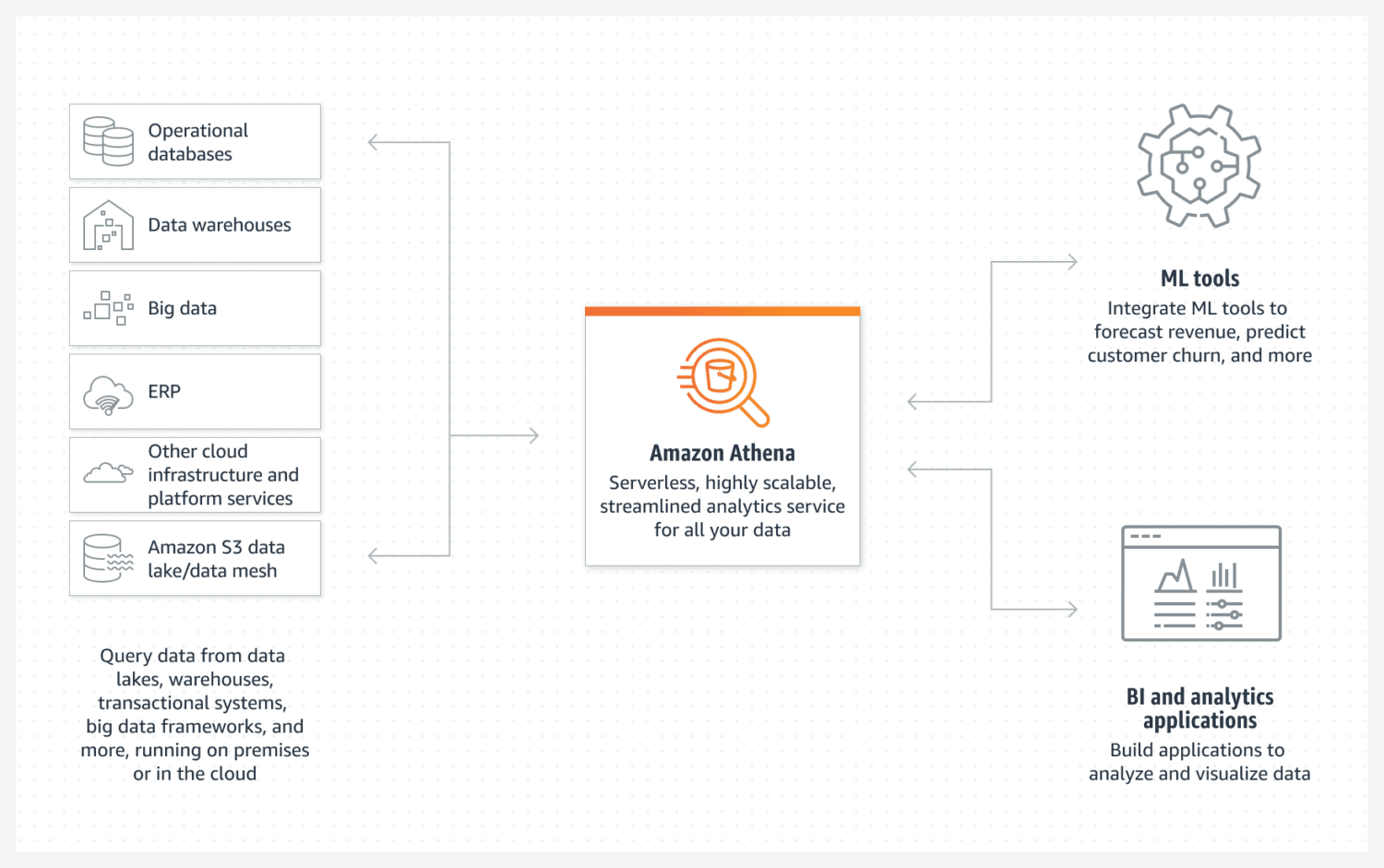
AWS Athena baza podataka
 Izvor: aws.amazon.com
Izvor: aws.amazon.com
Athena olakšava kreiranje osnovnog jezera podataka u AWS-u. To je baza podataka bez servera koja koristi S3 segment za skladištenje svojih podataka. Organizacija podataka se održava kroz struktuirane formate datoteka kao što su parket ili datoteke sa vrednostima odvojenim zarezima (CSV). S3 segment sadrži datoteke, a Athena ih referencira kad god procesi izaberu podatke iz baze podataka.
Važno je imati na umu da Athena ne podržava različite funkcije koje se inače smatraju standardnim, na primer, SQL izjave za ažuriranje podataka. Stoga, na Athenu treba gledati kao na vrlo jednostavnu opciju.
Ipak, podržava indeksiranje i particionisanje. Takođe, vrlo se lako horizontalno skalira, jer je to jednostavno kao dodavanje novih segmenata u infrastrukturu. Za kreiranje jednostavnog, ali funkcionalnog jezera podataka, ovo može biti sasvim dovoljno u većini slučajeva.
Za postizanje dobrih performansi, od suštinskog značaja je izbor najpogodnijeg dizajna podataka, sa fokusom na buduću upotrebu. Morate biti vrlo jasni u pogledu načina na koji želite da preuzimate podatke. Naknadno rekonstruisanje tabela, nakon što su već kreirane i popunjene podacima, može biti komplikovano.
Athena DB je odličan izbor i dobro se uklapa u vaš cilj ako želite da kreirate jednostavan i nepromenljiv skup podataka koji se lako horizontalno skalira tokom vremena.
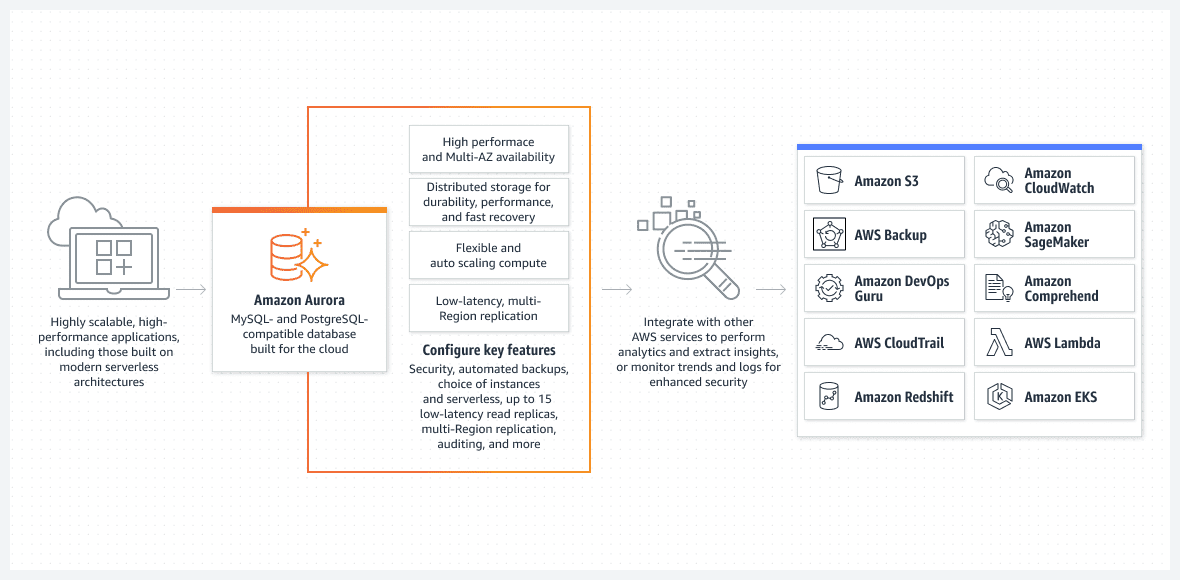
AWS Aurora baza podataka
 Izvor: aws.amazon.com
Izvor: aws.amazon.com
Athena DB se ističe u skladištenju nekategorizovanih podataka. Na kraju krajeva, to je i način na koji treba da čuvate svoj originalni sadržaj da biste maksimalno iskoristili njegovu buduću upotrebu. Međutim, spor je način pružanja odabranih rezultata aplikaciji na prednjoj strani.
Jedna od najboljih opcija, pre svega sa aspekta jednostavnog podešavanja, je Aurora baza podataka koja radi u režimu bez servera.
Aurora je mnogo više od osnovne baze podataka. To je jedno od najnaprednijih rešenja izvorne relacijske baze podataka u AWS-u, i predstavlja složeno rešenje koje se konstantno usavršava sa svakim novim izdanjem.
Aurora je jedinstvena po tome što može da radi u režimu bez servera, što je izdvaja od drugih relacijskih servisa. Režim rada je sledeći:
- Za konfiguraciju Aurora klastera, koristi se AWS konzola. Neophodno je navesti standardne nivoe procesora i RAM-a, kao i maksimalni interval automatskog skaliranja. Ovo utiče na performanse koje Aurora klaster može dinamički da dodaje ili uklanja. Na osnovu trenutnog korišćenja baze podataka, AWS odlučuje da li će povećati ili smanjiti kapacitet.
- Aurora klaster neće se pokrenuti ukoliko korisnik ili neki proces ne pošalje zahtev. Na primer, kada započne planirana grupna obrada ili ako aplikacija izvrši API poziv za preuzimanje podataka iz baze podataka. Baza podataka će se automatski otvoriti i ostati aktivna određeno vreme nakon završetka procesa zahteva.
- Aurora klaster će se automatski isključiti ukoliko nema više zahteva za obradu podataka u bazi podataka.
Još jednom, Aurora DB bez servera radi samo kada je potrebno da obavi određeni zadatak. Automatski pokrenuti klaster će se ponovo isključiti ako ne obrađuje nikakav posao. Plaćate samo stvarni rad, a ne vreme mirovanja.
Aurorom bez servera u potpunosti upravlja AWS, bez potrebe za angažovanjem administratora.
AWS Amplify
Amplify nudi platformu bez servera za brzu implementaciju aplikacija na prednjoj strani, izgrađenih pomoću JavaScript i React biblioteka. Nema potrebe za podešavanjem klastera servera. Koristite AWS konzolu za direktnu primenu koda ili automatizovani DevOps proces.
Možete pozvati pozadinske API-je kako biste pristupili podacima uskladištenim u bazama podataka. Ovi pozivi omogućavaju pristup stvarnim podacima u prednjoj aplikaciji. Optimizaciju performansi na pozadini treba da izvrši tim. Mogućnost sporog odgovora u korisničkom interfejsu može se dodatno smanjiti ukoliko se dizajniraju efikasne naredbe za izbor podataka direktno u okviru API poziva.
AWS Step Functions
 Izvor: aws.amazon.com
Izvor: aws.amazon.com
Iako su sve glavne komponente sistema bez servera, to ne garantuje arhitekturu bez servera. Ovo je moguće samo ukoliko su svi batch procesi između komponenti bez servera.
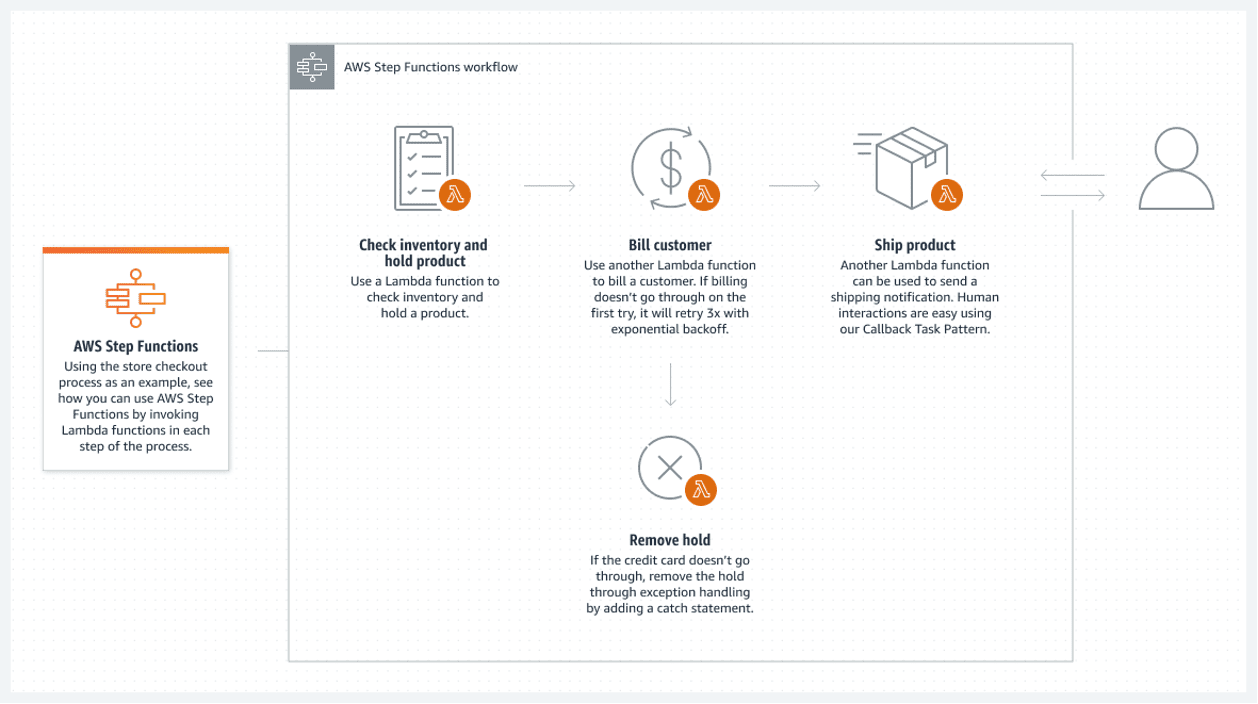
AWS Step Functions pružaju najbolje rešenje u AWS oblaku. Povezana lista AWS Lambda funkcija čini korak funkcije. Ove funkcije kreiraju dijagram toka sa jasnim početnim i krajnjim stanjima. Lambda funkcija, obično napisana u Python ili Node JS jezicima, predstavlja izvršni deo koda koji obrađuje sve neophodno.
Sledi primer kako se može izvršiti funkcija koraka:
Ovaj tok bez servera ima jedan veliki nedostatak: svaka Lambda funkcija može da radi najviše 15 minuta. Zato, podela toka na manje Lambda funkcije može ovo učiniti manje problematičnim.
Moguće je pozvati više Lambda funkcija istovremeno u jednom koraku, što u osnovi znači paralelizaciju koraka sa više Lambda funkcija koje se izvršavaju istovremeno. Samo sačekajte da se završi sva paralelna obrada pre nego što nastavite. Zatim pređite na sledeću Lambda obradu.
Završne reči
Arhitektura bez servera nudi jedinstvenu priliku za kreiranje platforme u oblaku koja pokriva ceo sistemski pejzaž. Ovakva platforma je horizontalno skalabilna i ima niske operativne troškove.
Predstavlja savršeno rešenje za projekte sa ograničenim budžetom. To je odlična opcija za istraživanje, posebno kada ne postoje jasne informacije o produkcijskom opterećenju. Ovo je posebno važno nakon uspešnog uključivanja svih korisnika. Projektni timovi mogu da steknu uvid u način na koji sistem funkcioniše. Sve ove prednosti možete ostvariti bez kompromisa.
Ovaj pristup neće biti adekvatan za sve situacije, naročito one koje uključuju veliku upotrebu procesora. Međutim, AWS oblak se konstantno razvija u pogledu slučajeva korišćenja bez servera. Preporučljivo je sprovesti temeljno istraživanje pre nego što se odlučite za opciju bez servera za vaš sledeći AWS projekat u oblaku.
Zatim pogledajte najbolje baze podataka bez servera za moderne aplikacije.