Obrada obimnih podataka predstavlja jedan od najzahtevnijih zadataka s kojima se organizacije suočavaju. Ovaj proces postaje još složeniji kada je u pitanju velika količina podataka koja se generiše u realnom vremenu.
U ovom tekstu ćemo istražiti pojam obrade velikih podataka, načine na koje se ona sprovodi, te ćemo se detaljnije upoznati sa Apache Kafkom i Sparkom – dva ključna alata u svetu obrade podataka!
Šta je obrada podataka? Kako se to radi?
Obrada podataka se može definisati kao bilo koja operacija ili niz operacija, bez obzira da li se obavljaju automatski ili ne. To uključuje prikupljanje, sređivanje i organizovanje informacija prema logičkom planu radi lakše interpretacije.

Kada korisnik pristupi bazi podataka i dobije rezultate svoje pretrage, obrada podataka je ta koja mu omogućava da dobije relevantne informacije. Informacije dobijene kao odgovor na upit su proizvod procesa obrade podataka. Stoga, informacione tehnologije su usmerene na efikasnu obradu podataka.
Tradicionalno, obrada podataka je obavljana uz pomoć jednostavnog softvera. Međutim, sa pojavom velikih podataka, situacija se promenila. Veliki podaci se odnose na obim informacija koje mogu doseći i preko sto terabajta ili čak petabajta.
Osim toga, ove informacije se neprekidno ažuriraju. Primeri uključuju podatke iz kontaktnih centara, društvenih mreža, berzanskih transakcija i slično. Ovakve vrste podataka se ponekad nazivaju i tokom podataka – kontinuiranim, neprekidnim protokom informacija. Ključna karakteristika je odsustvo definisanih granica, što otežava određivanje početka ili kraja toka podataka.
Podaci se obrađuju odmah po dolasku na odredište. Neki stručnjaci to nazivaju obradom u realnom vremenu ili onlajn obradom. Alternativno, postoji i obrada u blokovima, grupna ili oflajn obrada, gde se podaci obrađuju u intervalima od nekoliko sati ili dana. Često se ovaj proces obavlja noću radi konsolidacije podataka sakupljenih tokom dana. U nekim slučajevima, izveštaji generisani na nedeljnom ili mesečnom nivou mogu biti zastareli.
Najpopularnije platforme za obradu velikih podataka putem striminga su open-source rešenja poput Kafke i Sparka. Ove platforme omogućavaju korišćenje različitih, komplementarnih alata. Budući da su open-source, brzo se razvijaju i integrišu sve više alata. Na ovaj način, protok podataka se prihvata s različitih izvora, promenljivom brzinom i bez prekida.
Sada ćemo se fokusirati na dva najpoznatija alata za obradu podataka i izvršiti njihovo poređenje:
Apache Kafka
Apache Kafka je sistem za razmenu poruka koji omogućava kreiranje aplikacija za striming s neprekidnim protokom podataka. Prvobitno razvijen od strane LinkedIn-a, Kafka se temelji na evidencijama (logovima); dnevnik je osnovni oblik skladištenja jer se svaka nova informacija dodaje na kraj datoteke.

Kafka je jedno od najboljih rešenja za obradu velikih podataka zbog svoje visoke propusne moći. Uz Apache Kafku, moguće je čak i transformisati grupnu obradu u obradu u realnom vremenu.
Apache Kafka je sistem za razmenu poruka koji funkcioniše po principu objavljivanja i pretplate, gde aplikacija objavljuje poruke, a pretplaćena aplikacija ih prima. Vreme između objavljivanja i primanja poruke može biti svega nekoliko milisekundi, što ukazuje na nisku latenciju Kafka sistema.
Kako funkcioniše Kafka
Arhitektura Apache Kafke obuhvata proizvođače (producers), potrošače (consumers) i sam klaster. Proizvođač je bilo koja aplikacija koja objavljuje poruke klasteru. Potrošač je svaka aplikacija koja prima poruke od Kafke. Kafka klaster predstavlja skup čvorova koji funkcionišu kao jedna instanca servisa za razmenu poruka.
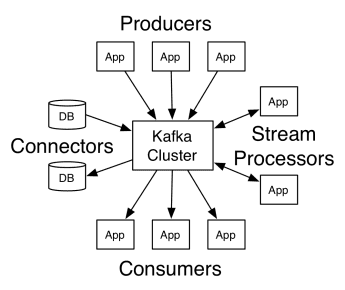 Kako funkcioniše Kafka
Kako funkcioniše Kafka
Kafka klaster se sastoji od nekoliko brokera. Broker je Kafka server koji prima poruke od proizvođača i upisuje ih na disk. Svaki broker upravlja listom tema (topics), a svaka tema je podeljena na nekoliko particija.
Nakon što primi poruke, broker ih šalje registrovanim potrošačima za svaku temu.
Podešavanjima Apache Kafke upravlja Apache ZooKeeper, koji čuva metapodatke klastera, poput lokacija particija, liste imena, liste tema i dostupnih čvorova. Dakle, ZooKeeper održava sinhronizaciju između različitih elemenata klastera.
ZooKeeper je od presudnog značaja, jer je Kafka distribuiran sistem; odnosno, pisanje i čitanje obavlja više klijenata istovremeno. U slučaju kvara, ZooKeeper bira zamenu i obnavlja operaciju.
Slučajevi upotrebe
Kafka je postala popularna, posebno kao alat za razmenu poruka, ali njena svestranost prevazilazi tu primenu i može se koristiti u različitim scenarijima, kao što je prikazano u primerima ispod.
Razmena poruka
Asinhroni oblik komunikacije koji razdvaja strane koje komuniciraju. U ovom modelu, jedna strana šalje podatke kao poruku Kafki, dok ih druga aplikacija kasnije koristi.
Praćenje aktivnosti
Omogućava čuvanje i obradu podataka koji prate interakciju korisnika sa web stranicom, kao što su pregledi stranica, klikovi, unos podataka itd. Ova vrsta aktivnosti obično generiše veliki obim podataka.
Metrike
Uključuje prikupljanje podataka i statistike s više izvora radi generisanja centralizovanog izveštaja.
Agregacija logova
Centralno agregira i skladišti datoteke logova koje potiču iz drugih sistema.
Obrada tokova podataka
Obrada tokova podataka se sastoji od više faza, gde se sirovi podaci koriste iz tema i agregiraju, obogaćuju ili transformišu u druge teme.
Kako bi podržala ove funkcije, platforma u suštini nudi tri API-ja:
- Streams API: Funkcioniše kao procesor toka koji koristi podatke iz jedne teme, transformiše ih i upisuje u drugu.
- Connectors API: Omogućava povezivanje tema s postojećim sistemima, kao što su relacione baze podataka.
- API-ji za proizvođače i potrošače: Omogućavaju aplikacijama da objavljuju i koriste Kafka podatke.
Prednosti
Replikovano, particionisano i uređeno
Poruke u Kafki se repliciraju preko particija na čvorovima klastera, redosledom kojim stižu, čime se osigurava sigurnost i brzina isporuke.
Transformacija podataka
Uz Apache Kafku, moguće je transformisati grupnu obradu u obradu u realnom vremenu koristeći API za batch ETL tokove.
Sekvencijalni pristup disku
Apache Kafka zadržava poruku na disku, a ne u memoriji, jer je tako brže. U većini situacija, pristup memoriji je brži, posebno kada se radi o nasumičnim lokacijama u memoriji. Međutim, Kafka obavlja sekvencijalni pristup i u ovom slučaju je disk efikasniji.
Apache Spark
Apache Spark je alat za obradu velikih podataka i skup biblioteka za paralelnu obradu podataka u klasterima. Spark predstavlja evoluciju Hadoop-a i programske paradigme Map-Reduce. Može biti do 100 puta brži zahvaljujući efikasnom korišćenju memorije koja ne zadržava podatke na diskovima tokom obrade.
Spark je organizovan na tri nivoa:
- API-ji niskog nivoa: Ovaj nivo sadrži osnovnu funkcionalnost za pokretanje poslova i ostale funkcije koje zahtevaju druge komponente. Važne su funkcije upravljanja bezbednošću, mrežom, planiranjem i logičkim pristupom sistemima datoteka kao što su HDFS, GlusterFS, Amazon S3 i drugi.
- Strukturirani API-ji: Nivo strukturiranih API-ja se bavi manipulacijom podacima preko skupova podataka ili okvira podataka, koji se mogu čitati u formatima kao što su Hive, Parquet, JSON i drugi. Uz pomoć SparkSQL (API koji omogućava pisanje upita u SQL-u), možemo manipulisati podacima kako želimo.
- Visok nivo: Na najvišem nivou imamo Spark ekosistem s različitim bibliotekama, uključujući Spark Streaming, Spark MLlib i Spark GraphX. One su odgovorne za upravljanje strimingom i pratećim procesima, poput oporavka od pada sistema, kreiranja i validacije klasičnih modela mašinskog učenja, kao i rad s grafovima i algoritmima.
Kako funkcioniše Spark
Arhitektura Spark aplikacije se sastoji od tri glavna dela:
Program drajvera: On je odgovoran za orkestriranje izvršavanja obrade podataka.
Cluster Manager: To je komponenta zadužena za upravljanje različitim mašinama u klasteru. Neophodna je samo ako Spark radi distribuirano.
Radnički čvorovi: Ovo su mašine koje obavljaju zadatke programa. Ako se Spark pokreće lokalno na vašoj mašini, ona će preuzeti ulogu programa drajvera i radnika. Ovaj način pokretanja Sparka se naziva samostalni (standalone).
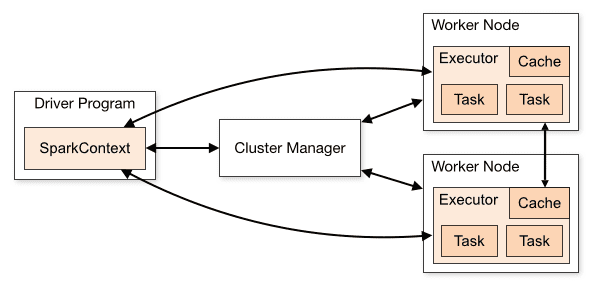 Pregled klastera
Pregled klastera
Spark kod se može pisati na nekoliko različitih jezika. Spark konzola, pod nazivom Spark Shell, je interaktivna i koristi se za učenje i istraživanje podataka.
Takozvana Spark aplikacija se sastoji od jednog ili više poslova, što omogućava podršku obradi podataka velikih razmera.
Kada govorimo o izvršenju, Spark ima dva režima:
- Klijent: Drajver radi direktno na klijentu, ne prolazeći kroz Resource Manager.
- Klaster: Drajver se pokreće na glavnoj aplikaciji preko menadžera resursa (u režimu klastera, ako se klijent prekine, aplikacija će nastaviti s radom).
Neophodno je pravilno koristiti Spark kako bi povezani servisi, poput Resource Manager-a, mogli da identifikuju potrebu za svakim izvršavanjem, obezbeđujući najbolje performanse. Dakle, na programeru je da odredi koji je najbolji način pokretanja svojih Spark poslova, strukturira pozive i konfiguriše Spark izvršioce kako mu odgovara.
Spark poslovi prvenstveno koriste memoriju, pa je uobičajeno prilagođavanje vrednosti Spark konfiguracije za izvršioce na radnom čvoru. U zavisnosti od Spark radnog opterećenja, moguće je utvrditi da određena nestandardna Spark konfiguracija obezbeđuje optimalnije izvršavanje. U tu svrhu, mogu se izvršiti uporedni testovi između različitih dostupnih opcija konfiguracije i same podrazumevane Spark konfiguracije.
Slučajevi upotrebe
Apache Spark pomaže u obradi ogromnih količina podataka, bilo u realnom vremenu ili arhiviranih, strukturiranih ili nestrukturiranih. Sledi nekoliko popularnih primera njegove upotrebe:
Obogaćivanje podataka
Kompanije često koriste kombinaciju istorijskih podataka o klijentima sa podacima o ponašanju u realnom vremenu. Spark može pomoći u izgradnji kontinuiranog ETL procesa za pretvaranje nestrukturiranih podataka o događajima u strukturirane podatke.
Detekcija pokretača događaja
Spark Streaming omogućava brzo otkrivanje i reagovanje na neuobičajeno ili sumnjivo ponašanje koje bi moglo ukazivati na potencijalni problem ili prevaru.
Složena analiza podataka sesije
Koristeći Spark Streaming, događaji povezani sa korisničkom sesijom, poput aktivnosti nakon prijave u aplikaciju, mogu se grupisati i analizirati. Ove informacije se mogu kontinuirano koristiti za ažuriranje modela mašinskog učenja.
Prednosti
Iterativna obrada
Ako je potrebno više puta obraditi podatke, Spark-ovi otporni distribuirani skupovi podataka (RDD) omogućavaju višestruke operacije mape u memoriji bez potrebe za upisivanjem privremenih rezultata na disk.
Grafička obrada
Spark-ov računarski model sa GraphX API-jem je odličan za iterativne proračune koji su tipični za grafičku obradu.
Mašinsko učenje
Spark ima MLlib — ugrađenu biblioteku za mašinsko učenje koja sadrži gotove algoritme koji se takođe pokreću u memoriji.
Kafka protiv Sparka
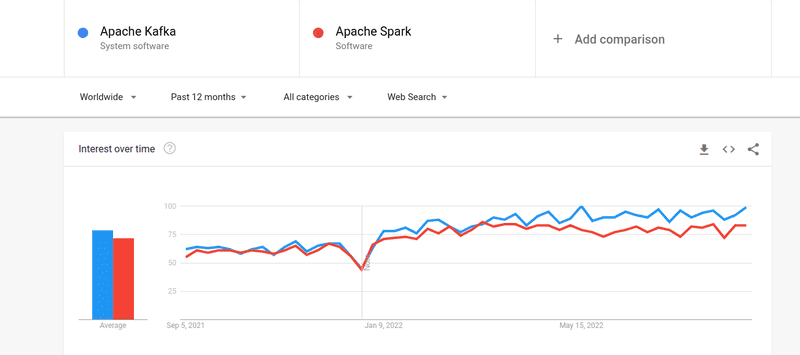
Iako je interesovanje za Kafku i Spark gotovo jednako, postoje značajne razlike između ova dva alata. Hajde da ih detaljnije pogledamo.
#1. Obrada podataka
Kafka je alat za strimovanje i skladištenje podataka u realnom vremenu koji je zadužen za prenos podataka između aplikacija, ali nije dovoljan za izgradnju kompletnog rešenja. Stoga su potrebni drugi alati za zadatke koje Kafka ne obavlja, kao što je Spark. Spark je, s druge strane, platforma za obradu podataka koja prvenstveno radi u paketima, izdvaja podatke iz Kafka tema i transformiše ih u kombinovane šeme.
#2. Upravljanje memorijom
Spark koristi Robust Distributed Datasets (RDD) za upravljanje memorijom. Umesto da pokušava da obradi ogromne skupove podataka, distribuira ih na više čvorova u klasteru. Nasuprot tome, Kafka koristi sekvencijalni pristup sličan HDFS-u i čuva podatke u bafer memoriji.
#3. ETL Transformacija
I Spark i Kafka podržavaju proces ETL transformacije, koji kopira zapise iz jedne baze podataka u drugu, obično s transakcione (OLTP) na analitičku (OLAP). Međutim, za razliku od Sparka, koji dolazi s ugrađenom mogućnošću ETL procesa, Kafka se oslanja na Streams API da bi ga podržala.
#4. Postojanost podataka

Spark-ova upotreba RRD-a omogućava skladištenje podataka na više lokacija za kasniju upotrebu, dok u Kafki morate definisati objekte skupova podataka u konfiguraciji da biste sačuvali podatke.
#5. Složenost
Spark je sveobuhvatno rešenje i lakši za učenje zahvaljujući podršci za različite programske jezike visokog nivoa. Kafka zavisi od brojnih različitih API-ja i modula nezavisnih proizvođača, što može otežati rad s njom.
#6. Oporavak
I Spark i Kafka nude opcije oporavka. Spark koristi RRD, koji mu omogućava neprekidno čuvanje podataka, a ako dođe do kvara klastera, on se može oporaviti.

Kafka kontinuirano replicira podatke unutar klastera i replikaciju među brokerima, što vam omogućava da pređete na različite brokere ako dođe do kvara.
Sličnosti između Sparka i Kafke
| Apache Spark | Apache Kafka | |
| Open Source | Open Source | Open Source |
| Build Streaming Data Application | Build Streaming Data Application | Build Streaming Data Application |
| Supports Stateful Processing | Supports Stateful Processing | Supports Stateful Processing |
| Supports SQL | Supports SQL | Supports SQL |
Sličnosti između Sparka i Kafke
Zaključne reči
Kafka i Spark su alati otvorenog koda, pisani u Scali i Javi, koji vam omogućavaju da kreirate aplikacije za striming podataka u realnom vremenu. Imaju nekoliko zajedničkih osobina, uključujući obradu stanja, podršku za SQL i ETL. Kafka i Spark se takođe mogu koristiti kao komplementarni alati koji pomažu u rešavanju problema složenosti prenosa podataka između aplikacija.