Ukoliko ste savladali nekoliko programskih jezika, verovatno ste se susreli sa terminom „parsiranje teksta“. Ovaj proces se koristi za pojednostavljivanje kompleksnih vrednosti podataka iz datoteka. Ovaj članak će vam pomoći da razumete kako se parsira tekst koristeći različite jezike. Pored toga, ako naiđete na grešku prilikom parsiranja teksta, u ovom članku ćete saznati kako da je rešite.

Kako parsirati tekst
U ovom članku ćemo detaljno objasniti kako se tekst može parsirati na različite načine, pružajući uvod u samu tehniku parsiranja.
Šta je parsiranje teksta?
Pre nego što se upustite u detalje parsiranja teksta, važno je da imate osnovno razumevanje programiranja i kodiranja.
NLP ili obrada prirodnog jezika
Za parsiranje teksta koristi se obrada prirodnog jezika (NLP), poddisciplina veštačke inteligencije. Python, jedan od popularnih jezika u ovoj oblasti, često se koristi za parsiranje teksta.
NLP omogućava računarima da razumeju i obrađuju ljudske jezike, čineći ih pogodnim za različite primene. Da bi se tehnike mašinskog učenja primenile na jezik, nestrukturirani tekstualni podaci moraju se konvertovati u strukturirane, tabelarne podatke. Za ovu svrhu, Python se koristi za manipulaciju programskim kodom.
Šta podrazumeva parsiranje teksta?
Parsiranje teksta jednostavno znači prebacivanje podataka iz jednog formata u drugi. Format u kom je datoteka sačuvana se analizira i konvertuje u drugi format, omogućavajući korisniku da je koristi u raznim aplikacijama.
- Drugim rečima, to je proces analize teksta ili niza znakova i pretvaranje u logičke komponente promenom formata datoteke.
- Određena pravila Python jezika koriste se za obavljanje ovog uobičajenog programskog zadatka. Tokom parsiranja teksta, dati tekst se razlaže na manje delove.
Koji su razlozi za parsiranje teksta?
Razlozi zašto je potrebno parsirati tekst su navedeni u ovom odeljku, i oni su preduslov za razumevanje procesa parsiranja.
- Svi podaci na računaru nisu u istom formatu i mogu se razlikovati u zavisnosti od aplikacije.
- Formati podataka se razlikuju za različite aplikacije, a nekompatibilan kod bi doveo do grešaka.
- Ne postoji jedan univerzalni kompjuterski program koji može da bira podatke iz svih formata.
Metod 1: Kroz klasu DataFrame
Klasa DataFrame u Python-u ima sve potrebne funkcije za parsiranje teksta. Ova ugrađena biblioteka sadrži kodove za prebacivanje podataka iz bilo kog formata u drugi format.
Kratko objašnjenje klase DataFrame
DataFrame je struktura podataka sa mnogobrojnim funkcijama, koja se koristi kao alatka za analizu podataka. To je moćan alat za analizu koji se može koristiti sa minimalnim naporom.
- Kod se učitava u Pandas DataFrame radi analize u Python-u.
- Klasa dolazi sa mnogim paketima koje obezbeđuje Pandas, a koriste ih Python analitičari podataka.
- Karakteristika ove klase je apstrakcija, kod u kome je unutrašnja funkcionalnost funkcije sakrivena od korisnika, NumPy biblioteke. NumPy biblioteka je Python biblioteka koja uključuje komande i funkcije za rad sa nizovima.
- DataFrame klasa se može koristiti za prikaz dvodimenzionalnog niza sa više indeksa redova i kolona. Ovi indeksi pomažu u skladištenju višedimenzionalnih podataka i stoga se zovu MultiIndex. Oni se moraju izmeniti kako biste znali kako da popravite grešku parsiranja.
Pandas u Python-u pomaže pri izvođenju SQL operacija sa najvećom preciznošću kako bi se izbegla greška parsiranja. Takođe sadrži IO alate koji pomažu u analizi CSV, MS Excel, JSON, HDF5 i drugih formata podataka.
Proces parsiranja teksta pomoću DataFrame klase
Da biste razumeli kako da parsirate tekst, možete koristiti standardni proces koristeći DataFrame klasu, koji je opisan u ovom odeljku.
- Dešifrujte format ulaznih podataka.
- Odlučite o formatu izlaznih podataka, npr. CSV.
- Napišite u kodu primitivni tip podataka, kao što je lista ili rečnik.
Napomena: Pisanje koda na praznom DataFrame-u može biti naporno i komplikovano. Pandas omogućava kreiranje podataka u DataFrame klasi od ovih tipova podataka. Dakle, podaci u primitivnom tipu mogu se lako parsirati u željeni format.
- Analizirajte podatke pomoću alatke za analizu podataka, Pandas DataFrame, i prikažite rezultat.
Opcija I: Standardni format
Ovde je objašnjen standardni metod za formatiranje bilo koje datoteke sa određenim formatom podataka kao što je CSV.
- Sačuvajte datoteku sa podacima lokalno na računaru. Na primer, možete je nazvati data.txt.
- Uvezite datoteku u Pandas sa određenim imenom i prebacite podatke u drugu promenljivu. Na primer, Pandas se uvozi pod imenom pd u datom kodu.
- Uvoz treba da sadrži ceo kod sa detaljima imena ulazne datoteke, funkcije i formata datoteke.
Napomena: Ovde se promenljiva pod imenom res koristi za funkciju čitanja podataka iz datoteke data.txt pomoću Pandas koji je uvezen pod imenom pd. Format za ulazni tekst je naveden kao CSV.
- Pozovite datoteku i analizirajte parsirani tekst na štampanom rezultatu. Na primer, komanda res, nakon izvršavanja, će prikazati parsirani tekst.
Primer koda za proces koji je opisan gore je dat u nastavku i pomoći će vam da razumete kako da parsirate tekst.
import pandas as pd
res = pd.read_csv('data.txt')
res
U ovom slučaju, ako unesete podatke u datoteku data.txt, npr. [1,2,3], oni će biti parsirani i prikazani kao 1 2 3.
Opcija II: String metoda
Ako tekst sadrži samo nizove ili alfanumeričke karaktere, specijalni znaci u nizu kao što su zarezi, razmaci itd., mogu se koristiti za razdvajanje i parsiranje teksta. Proces je sličan uobičajenim string operacijama. Da biste razumeli kako da popravite grešku parsiranja, pratite proces parsiranja teksta opisan u nastavku.
- Podaci se izdvajaju iz niza i beleže se svi specijalni znaci koji razdvajaju tekst.
Na primer, u kodu ispod, identifikuju se specijalni znaci u nizu my_string, a to su ‘,’ i ‘:’. Ovaj proces mora biti pažljivo obavljen da bi se izbegla greška parsiranja.
- Tekst u nizu se deli pojedinačno na osnovu vrednosti i pozicije specijalnih znakova.
Na primer, niz se deli na vrednosti na osnovu specijalnih znakova identifikovanih pomoću split komande.
- Vrednosti podataka niza se prikazuju kao parsirani tekst. Komanda print() se koristi za prikaz parsiranih vrednosti teksta.
Primer koda za proces opisan gore je dat u nastavku.
my_string = 'Names: Tech, computer'
sfinal = [name.strip() for name in my_string.split(':')[1].split(',')]
print("Names: {}".format(sfinal))
U ovom slučaju, rezultat parsiranog niza biće prikazan kao što je prikazano ispod.
Names: ['Tech', 'computer']
Za bolju jasnoću i razumevanje procesa parsiranja teksta, koristi se for petlja i kod se menja na sledeći način.
my_string = 'Names: Tech, computer'
s1 = my_string.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print("Step {}: {}".format(idx, item))
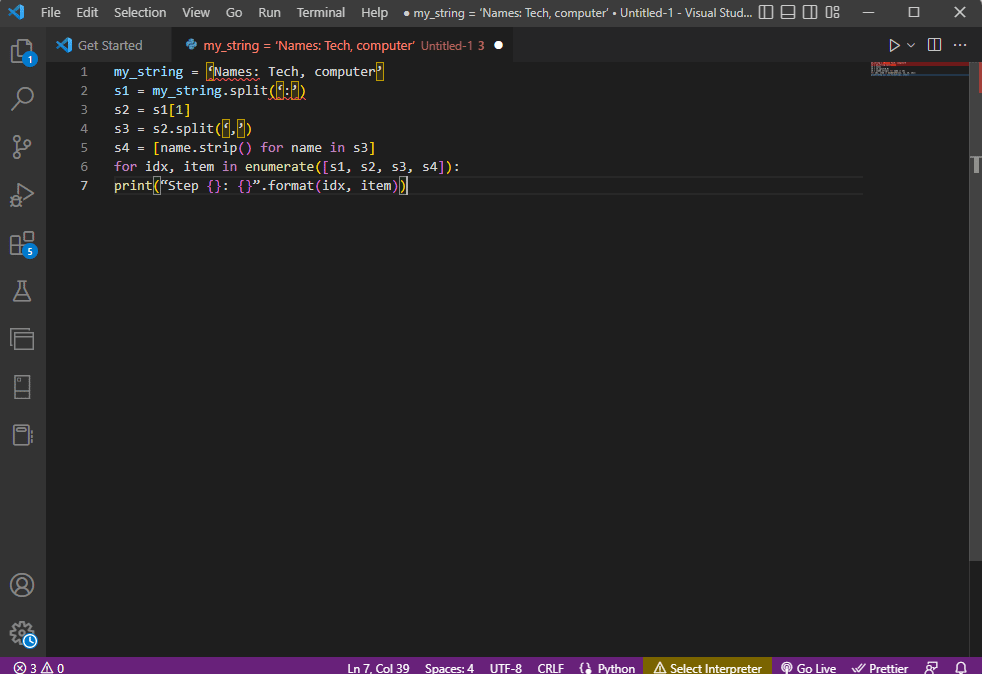
Rezultat parsiranog teksta za svaki korak je prikazan ispod. Možete primetiti da se u koraku 0 niz odvaja na osnovu specijalnog znaka :, a vrednosti se odvajaju na osnovu drugih znakova u kasnijim koracima.
Step 0: ['Names', 'Tech, computer'] Step 1: Tech, computer Step 2: [' Tech', ' computer'] Step 3: ['Tech', 'computer']
Opcija III: Parsiranje kompleksne datoteke
U mnogim slučajevima, podaci u datoteci koju treba parsirati sadrže različite tipove podataka i vrednosti. U ovom slučaju, može biti teško parsirati datoteku pomoću prethodno objašnjenih metoda.
Karakteristike parsiranja kompleksnih podataka u datoteci su da se vrednosti podataka prikazuju u tabelarnom formatu.
- Naslov ili metapodaci se prikazuju na vrhu datoteke.
- Promenljive i polja se prikazuju u izlazu u tabelarnom obliku.
- Vrednosti podataka formiraju kompleksni ključ.
Pre nego što naučite kako se parsira tekst ovom metodom, potrebno je da razumete nekoliko osnovnih koncepata. Parsiranje vrednosti se vrši na osnovu regularnih izraza.
Regex Patterns
Da biste znali kako da popravite grešku parsiranja, morate se uveriti da su obrasci regularnog izraza u izrazima ispravni. Kod za parsiranje nizova podataka uključivao bi uobičajene obrasce regularnog izraza koji su navedeni u nastavku.
- `\d`: odgovara decimalnoj cifri u nizu.
- `\s`: odgovara znaku razmaka.
- `\w`: odgovara alfanumeričkom karakteru.
- `+` ili `*`: izvodi pohlepno podudaranje uparivanjem jednog ili više znakova u nizovima.
- `a-z`: odgovara grupi malih slova u tekstualnim podacima.
- `A-Z` ili `a-z`: odgovara grupi velikih i malih slova u nizu.
- `0-9`: odgovara numeričkim vrednostima.
Regularni izrazi
Moduli regularnog izraza su važan deo Pandas paketa u Python-u, a netačan izraz može dovesti do greške pri parsiranju teksta. To je mali jezik ugrađen u Python za pronalaženje uzoraka nizova u izrazu. Regularni izrazi ili Regex su nizovi sa posebnom sintaksom. Omogućavaju korisniku da uporedi obrasce u drugim nizovima na osnovu vrednosti u njima.
Regularni izraz se kreira na osnovu tipa podataka i zahteva izraza, npr. `String = (.*)\n`. Regularni izraz se koristi pre šablona u svakom izrazu. Simboli koji se koriste u regularnim izrazima su navedeni ispod.
- `.`: za preuzimanje bilo kog znaka iz podataka.
- `*`: koristite nula ili više podataka iz prethodnog izraza.
- `(.*)`: za grupisanje dela regularnog izraza unutar zagrada.
- `\n`: kreira znak novog reda na kraju reda u kodu.
- `\d`: kreira kratku celobrojnu vrednost u opsegu od 0 do 9.
- `+`: koristite jedan ili više podataka iz prethodnog izraza.
- `|`: kreirati logički iskaz; koristi se za „ili“ izraze.
RegexObjects
RegexObject je povratna vrednost za funkciju kompiliranja i koristi se za vraćanje MatchObject ako izraz odgovara vrednosti podudaranja.
1. MatchObject
Pošto je Boolean vrednost MatchObject-a uvek Tačna, možete koristiti if naredbu da identifikujete pozitivna podudaranja u objektu. Ako se koristi if naredba, grupa na koju se odnosi indeks se koristi za otkrivanje podudaranja objekta u izrazu.
- `group()`: vraća jednu ili više podgrupa podudaranja.
- `group(0)`: vraća celo podudaranje.
- `group(1)`: vraća prvu podgrupu u zagradi.
- Dok se odnosi na više grupa, treba koristiti Python ekstenziju. Ova ekstenzija se koristi za određivanje imena grupe u kojoj se mora pronaći podudaranje. Specifična ekstenzija se nalazi unutar grupe u zagradi. Na primer, izraz, `(?P<group1>regex1)` bi se odnosio na određenu grupu sa imenom group1 i proveravao podudaranje u regularnom izrazu, regex1. Da biste naučili kako da popravite grešku parsiranja, morate da proverite da li je grupa ispravno usmerena.
2. Metode MatchObject-a
Dok učite kako da parsirate tekst, važno je znati da MatchObject ima dve osnovne metode. Ako se MatchObject pronađe u datom izrazu, vraća svoju instancu, u suprotnom vraća None.
- Metoda `match(string)` se koristi za pronalaženje podudaranja niza na početku regularnog izraza.
- Metoda `search(string)` se koristi za skeniranje niza kako bi se pronašla lokacija podudaranja u regularnom izrazu.
Funkcije regularnog izraza
Regex funkcije su linije koda koje se koriste za obavljanje određene funkcije koju je definisao korisnik iz skupa podataka.
Napomena: Za pisanje funkcija, sirovi nizovi se koriste za regularne izraze kako bi se izbegla greška parsiranja. Ovo se postiže dodavanjem indeksa r ispred svakog obrasca u izrazu.
Uobičajene funkcije koje se koriste u izrazima su objašnjene u nastavku.
1. `re.findall()`
Ova funkcija vraća sve obrasce u nizu ako se pronađe podudaranje i vraća praznu listu ako nije pronađeno. Na primer, funkcija, `string = re.findall(‘[aeiou]’, regex_filename)` se koristi za pronalaženje samoglasnika u imenu datoteke.
2. `re.split()`
Ova funkcija se koristi za razdvajanje niza u slučaju podudaranja sa određenim karakterom kao što je razmak. U slučaju da nije pronađeno podudaranje, vraća prazan niz.
3. `re.sub()`
Funkcija zamenjuje odgovarajući tekst sadržajem promenljive zamene. Ako se ne pronađe obrazac, vraća se originalni niz.
4. `re.search()`
Jedna od osnovnih funkcija koja pomaže u učenju parsiranja teksta je funkcija pretrage. Pomaže u pretraživanju šablona u nizu i vraćanju objekta podudaranja. Ako pretraga ne uspe da identifikuje podudaranje, vrednost se ne vraća.
5. `re.compile(pattern)`
Ova funkcija se koristi za kompilaciju regularnih izraza u RegexObject, o čemu je već bilo reči.
Drugi zahtevi
Navedeni zahtevi su dodatna karakteristika koju koriste napredni programeri u analizi podataka.
- Za vizualizaciju regularnog izraza koristi se regexper.
- Za testiranje regularnog izraza koristi se regex101.
Proces parsiranja teksta
Metoda za parsiranje teksta u ovoj kompleksnoj opciji je opisana na sledeći način.
- Najvažniji korak je razumevanje formata ulaza čitanjem sadržaja datoteke. Na primer, funkcije `with open` i `read()` se koriste za otvaranje i čitanje sadržaja datoteke pod imenom sample. Datoteka sample sadrži sadržaj datoteke file.txt. Da bi ste znali kako da popravite grešku parsiranja, datoteka mora biti pročitana u celosti.
- Sadržaj datoteke se štampa da bi se ručno analizirali podaci kako bi se saznali metapodaci vrednosti. Ovde se funkcija `print()` koristi za štampanje sadržaja sample datoteke.
- Potrebni paketi za parsiranje teksta se uvoze u kod i klasi se daje ime za dalje kodiranje. Ovde se uvoze regularni izrazi i Pandas.
- Regularni izrazi potrebni za kod se definišu u datoteci uključivanjem šablona regularnog izraza i funkcije regularnog izraza. Ovo omogućava tekstualnom objektu da uzme kod za analizu podataka.
- Da biste znali kako da parsirate tekst, možete pogledati primer koda koji je ovde dat. Funkcija `compile()` se koristi za kompilaciju niza iz grupe stringname1 imena datoteke. Funkciju za proveru podudaranja koristi komanda `ief_parse_line(line)`.
- Parser linije za kod je napisan pomoću `def parse_file(filepath)`, u kome definisana funkcija proverava sva podudaranja regularnog izraza u navedenoj funkciji. Metoda `regex search()` traži ključ rk u imenu datoteke i vraća ključ i podudaranje prvog odgovarajućeg regularnog izraza. Bilo kakav problem sa korakom može dovesti do greške parsiranja.
- Sledeći korak je da napišete parser datoteka koristeći funkciju parsiranja datoteka, a to je `def parse_file(filepath)`. Kreira se prazna lista za prikupljanje podataka koda, `data = []`, a podudaranje se proverava u svakoj liniji pomoću `match = _parse_line(line)`, i podaci o tačnoj vrednosti se vraćaju na osnovu tipa podataka.
- Da biste izdvojili broj i vrednost za tabelu, koristi se `line.strip().split(‘,’)`. Komanda `row{}` se koristi za kreiranje rečnika sa redom podataka. Komanda `data.append(row)` se koristi za razumevanje podataka i parsiranje u tabelarni format.
Komanda `data = pd.DataFrame(data)` se koristi za kreiranje Pandas DataFrame od vrednosti dictionary. Alternativno, možete koristiti sledeće komande:
- `data.set_index([‘string’, ‘integer’] inplace=True)` za postavljanje indeksa tabele.
- `data = data.groupby(level=data.index.names).first()` za konsolidaciju i uklanjanje NaN vrednosti.
- `data = data.apply(pd.to_numeric, errors=’ignore’)` za nadogradnju rezultata sa float na celobrojnu vrednost.
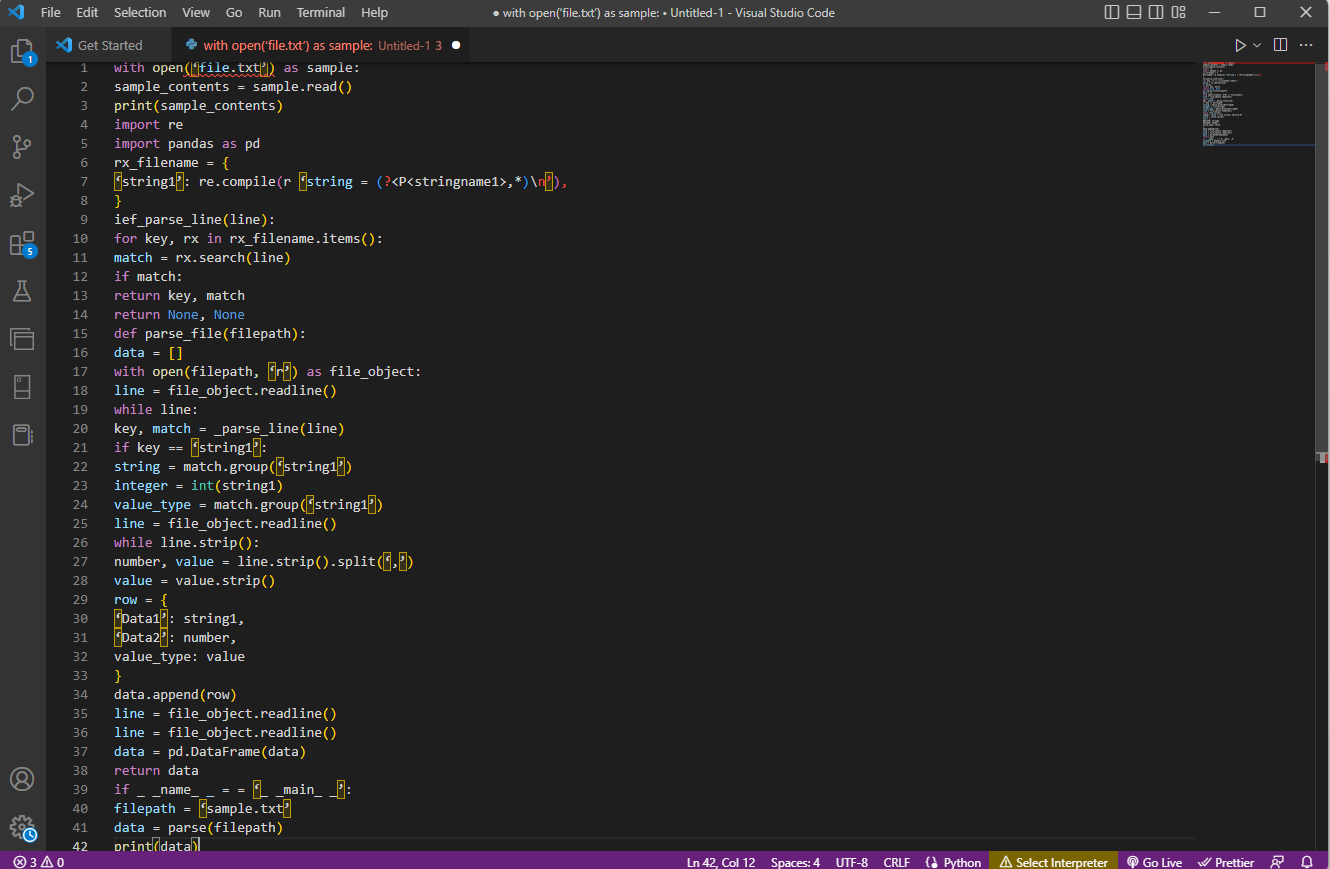
Poslednji korak da znate kako da parsirate tekst je da testirate parser koristeći if naredbu dodeljivanjem vrednosti promenljivim podacima i štampanjem pomoću komande `print(data)`. Primer koda za objašnjenje iznad je dat ovde:
with open('file.txt') as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
'string1': re.compile(r'string = (?P<stringname1>.*)\n'),
}
def _parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, 'r') as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == 'string1':
string1 = match.group('string1')
integer = int(string1)
value_type = match.group('string1')
line = file_object.readline()
while line.strip():
number, value = line.strip().split(',')
value = value.strip()
row = {
'Data1': string1,
'Data2': number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if __name__ == '__main__':
filepath = 'sample.txt'
data = parse_file(filepath)
print(data)
Metod 2: Tokenizacijom reči
Proces pretvaranja teksta u tokene ili manje delove na osnovu određenih pravila naziva se tokenizacija. Da biste naučili kako da popravite grešku parsiranja, važno je analizirati komande za tokenizaciju reči u kodu. Slično regularnom izrazu, u ovom metodu se mogu kreirati sopstvena pravila, i pomaže u zadacima predobrade teksta kao što je mapiranje delova govora. Takođe, aktivnosti kao što su pronalaženje i upoređivanje uobičajenih reči, čišćenje teksta i priprema podataka za napredne tehnike analize teksta kao što je analiza sentimenta se izvode u ovoj metodi. Ako je tokenizacija neispravna, može doći do greške pri parsiranju.
Nltk biblioteka
Proces zahteva pomoć popularne biblioteke jezičkih alata pod nazivom nltk, koja ima bogat skup funkcija za obavljanje mnogih NLP poslova. Oni se mogu preuzeti putem Pip paketa. Da biste znali kako da parsirate tekst, možete koristiti osnovni paket Anaconda, koji podrazumevano uključuje ovu biblioteku.
Oblici tokenizacije
Uobičajeni oblici ove metode su tokenizacija reči i tokenizacija rečenica. Zahvaljujući leksemi na nivou reči, prvi štampa jednu reč samo jednom, dok drugi štampa reč na nivou rečenice.
Proces parsiranja teksta
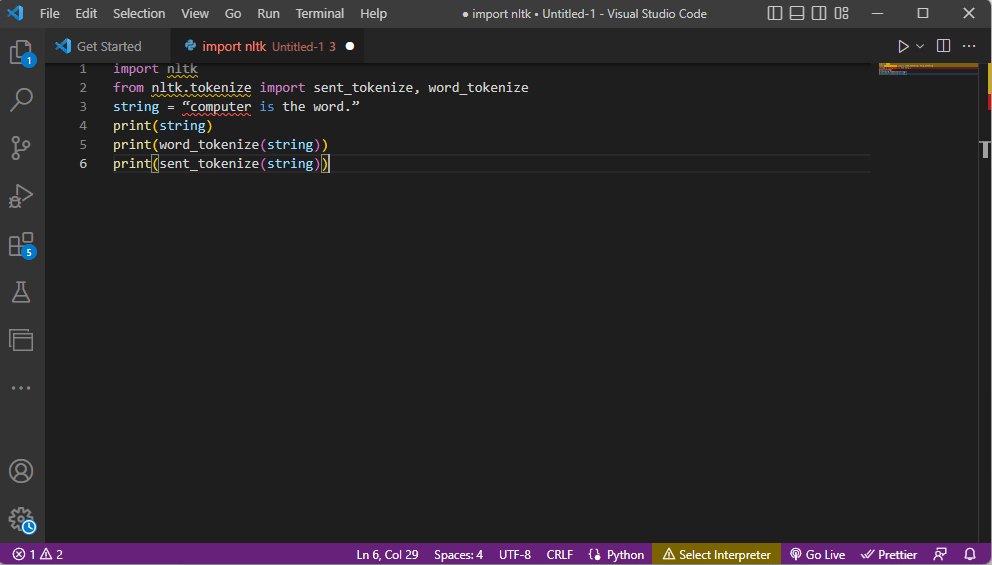
- Nltk biblioteka se uvozi, a obrasci za tokenizaciju se uvoze iz biblioteke.
- Dat je niz, i date su komande za obavljanje tokenizacije.
- Dok se niz štampa, izlaz bi bio kompjuterska reč.
- U slučaju tokenizacije reči ili `word_tokenize()`, svaka reč u rečenici se štampa pojedinačno unutar navodnika i odvojena je zarezom. Izlaz za komandu bi bio `’računar’, ‘je’, ‘reč’, ‘.’`
- U slučaju tokenizacije rečenice ili `sent_tokenize()`, pojedinačne rečenice se stavljaju unutar navodnika i ponavljanje reči je dozvoljeno. Izlaz za komandu bi bio „računar je reč“.
Kod koji objašnjava gore navedene korake za tokenizaciju je dat ovde.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = "computer is the word." print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metod 3: Kroz klasu DocParser
Slično klasi DataFrame, klasa DocParser se može koristiti za parsiranje teksta u kodu. Ova klasa omogućava vam da pozovete funkciju parsiranja pomoću putanje datoteke.
Proces parsiranja teksta
Da biste znali kako da parsirate tekst pomoću klase DocParser, pratite uputstva data u nastavku.
- Funkcija `get_format(filename)` se koristi za izdvajanje ekstenzije datoteke, vraćanje u postavljenu promenljivu i prosleđivanje sledećoj funkciji. Na primer, `p1 = get_format(filename)` bi izdvojio ekstenziju datoteke, postavio je na promenljivu p1 i prosledio sledećoj funkciji.
- Logička struktura sa drugim funkcijama se konstruiše pomoću if-elif-else iskaza i funkcija.
- Ako je ekstenzija datoteke važeća i struktura je logična, funkcija `get_parser` se koristi za parsiranje podataka u putanji datoteke i vraćanje string objekta korisniku.
Napomena: Da biste znali kako da popravite grešku parsiranja, ova funkcija mora biti ispravno implementirana.
- Parsiranje se vrši na osnovu ekstenzije datoteke. Specifična implementacija klase, npr. `parse_txt` ili `parse_docx`, se koristi za generisanje string objekata iz delova datog tipa datoteke.
- Parsiranje se može obaviti za datoteke drugih čitljivih ekstenzija kao što su `parse_pdf`, `parse_html` i `parse_pptx`.
- Vrednosti i interfejs se mogu uvesti u aplikaciju naredbama za uvoz i instanciranjem DocParser objekta. Ovo se može uraditi parsiranjem datoteka u Python-u, kao što je `parse_file.py`. Ova operacija se mora obaviti pažljivo kako bi se izbegla greška parsiranja.
Metod 4: Kroz alatku za parsiranje teksta
Alatka za parsiranje teksta se koristi za izdvajanje određenih podataka iz promenljivih i mapiranje u druge promenljive. Ovo je nezavisno od drugih alatki koje se koriste u zadatku, a alatka BPA platforme se koristi za konzumiranje i izlaz promenljivih. Koristite link koji je dat ovde da biste pristupili alatki za parsiranje teksta na mreži i koristite odgovore koji su dati ranije o tome kako da parsirate tekst.
Metod 5: Kroz TextFieldParser (Visual Basic)
TextFieldParser koristi objekte za parsiranje i obradu veoma velikih, struktuiranih i razgraničenih datoteka. Širina i kolona teksta, kao što su datoteke evidencije ili informacije iz zastarelih baza podataka, mogu se koristiti u ovoj metodi. Metoda parsiranja je slična ponavljanju koda preko tekstualne datoteke i uglavnom se koristi za izdvajanje polja teksta, slično metodama manipulacije nizovima. Ovo se radi da bi se tokenizirali razgraničeni nizovi i polja različitih širina pomoću definisanog graničnika kao što je zarez ili tabulator.
Funkcije za parsiranje teksta
Sledeće funkcije se mogu koristiti za parsiranje teksta u ovoj metodi.
- Za definisanje graničnika se koristi `SetDelimiters`. Na primer, komanda `testReader.SetDelimiters(vbTab)` se koristi za postavljanje tabulatora kao graničnika.
- Da biste postavili širinu polja na vrednost pozitivnog celog broja na fiksnu širinu polja tekstualnih datoteka, možete koristiti komandu `testReader.SetFieldWidths(integer)`.
- Da biste testirali tip polja teksta, možete koristiti sledeću komandu: `testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth`.
Metode za pronalaženje MatchObject
Postoje dve osnovne metode za pronalaženje MatchObject u kodu ili parsiranom tekstu.
- Prva metoda je da definišete format i prođete kroz datoteku koristeći metodu ReadFields. Ova metoda bi pomogla u obradi svake linije koda.
- Metoda PeekChars se koristi za proveru svakog polja pojedinačno pre čitanja, definisanje više formata i reagovanje.
U oba slučaja, ako polje ne odgovara navedenom formatu tokom parsiranja ili pronalaženja načina da se parsira tekst, vraća se izuzetak MalformedLineException.
Profesionalni savet: Kako parsirati tekst pomoću MS Excel-a
Kao poslednji i jednostavan metod za parsiranje teksta, možete koristiti MS Excel kao parser za kreiranje datoteka razdvojenih tabulatorima i zarezima. Ovo bi pomoglo u unakrsnoj proveri sa vašim rezultatima parsiranja i pronalaženju načina da popravite grešku parsiranja.
1. Izaberite vrednosti podataka u izvornoj datoteci i pritisnite tastere Ctrl + C da biste kopirali datoteku.
2. Otvorite MS Excel pomoću Windows trake za pretragu.
<img class=“alignnone wp-image-136836″ width=“600″ height=“480″ src=“https://wilku.top/wp-content/uploads/2022/10/1665808210_114_How-to-Parse-Text.png“ src