Web scraping, odnosno struganje veba, predstavlja tehniku izdvajanja informacija sa web stranica i njihovu upotrebu za različite svrhe.
Zamislite da želite da preuzmete tabelu sa neke web stranice, konvertujete je u JSON format i koristite je za razvoj internih alata. Korišćenjem web scraping-a, možete precizno izvući željene podatke ciljanjem specifičnih elemenata na stranici. Python se često koristi za web scraping jer nudi brojne biblioteke, kao što su BeautifulSoup i Scrapy, koje omogućavaju efikasno izdvajanje podataka.
Veština efikasnog izdvajanja podataka je izuzetno važna za programere i naučnike podataka. Ovaj članak će vam pomoći da shvatite kako da efikasno „ostružete“ web lokaciju i dođete do potrebnog sadržaja kako biste ga mogli manipulisati u skladu sa vašim zahtevima. U ovom vodiču koristićemo paket BeautifulSoup, moderan alat za scraping podataka u Pythonu.
Zašto koristiti Python za Web Scraping?
Python je prvi izbor mnogih programera kada je u pitanju kreiranje web scraper-a. Postoji više razloga za to, a u ovom članku ćemo se fokusirati na tri ključna razloga zašto je Python popularan za ovu svrhu.
Podrška biblioteka i zajednice: Postoji mnogo sjajnih biblioteka, kao što su BeautifulSoup, Scrapy, Selenium i druge, koje nude odlične funkcionalnosti za efikasno struganje web stranica. Izgrađen je sjajan ekosistem za web scraping, a zahvaljujući tome što veliki broj programera koristi Python, lako možete dobiti pomoć kada naiđete na problem.
Automatizacija: Python je poznat po svojim mogućnostima automatizacije. Web scraping je samo jedan deo procesa ako želite da napravite složen alat koji se oslanja na preuzimanje podataka. Na primer, ako želite da razvijete alat koji prati cene proizvoda na online prodavnicama, biće vam potrebne i funkcije automatizacije, tako da on svakodnevno može da prati cene i unosi ih u vašu bazu podataka. Python vam omogućava da lako automatizujete ove procese.
Vizualizacija podataka: Web scraping se intenzivno koristi u nauci o podacima. Naučnici podataka često moraju da preuzimaju podatke sa različitih web stranica. Uz biblioteke kao što je Pandas, Python olakšava vizualizaciju podataka čak i kada su u sirovom obliku.
Biblioteke za Web Scraping u Pythonu
U Pythonu postoji više biblioteka koje pojednostavljuju proces web scraping-a. Hajde da razmotrimo tri najpopularnije.
#1. BeautifulSoup
Jedna od najpopularnijih biblioteka za web scraping. BeautifulSoup pomaže programerima da stružu web stranice još od 2004. godine. Nudi jednostavne metode za navigaciju, pretragu i modifikaciju parsiranog stabla. BeautifulSoup takođe rešava kodiranje ulaznih i izlaznih podataka. Dobro je održavan i ima veliku zajednicu.
#2. Scrapy
Još jedan popularan okvir za ekstrakciju podataka. Scrapy ima više od 43.000 zvezdica na GitHub-u. Takođe se može koristiti za struganje podataka iz API-ja. Ima i nekoliko korisnih ugrađenih funkcionalnosti, poput slanja e-pošte.
#3. Selenium
Selenium nije primarno biblioteka za web scraping. U osnovi, to je alat za automatizaciju web pretraživača. Ali, lako možemo proširiti njegove funkcionalnosti da bismo njime „ostrugali“ web stranice. Koristi Webdriver protokol za kontrolu različitih pretraživača. Selenium je na tržištu već skoro 20 godina. Korišćenjem Selenium-a, možete lako da automatizujete i preuzimate podatke sa web stranica.
Izazovi sa Python Web Scraping-om
Mogu se javiti brojni izazovi prilikom pokušaja izvlačenja podataka sa web lokacija. Tu su problemi kao što su spora mreža, alati za sprečavanje scraping-a, blokiranje IP adresa, captcha blokade itd. Ovi problemi mogu stvoriti velike poteškoće prilikom pokušaja struganja web stranice.
Međutim, izazove možete efikasno prevazići prateći određene postupke. Na primer, u većini slučajeva, web adresa je blokirana od strane web lokacije ukoliko se pošalje veliki broj zahteva u kratkom vremenskom periodu. Da biste izbegli blokiranje IP adrese, potrebno je da vaš scraper kodirate tako da napravi pauzu nakon slanja zahteva.

Programeri često postavljaju zamke za „scraper-e“. Te zamke su obično nevidljive ljudskom oku, ali ih može „uhvatiti“ scraper. Ukoliko stružete web lokaciju koja postavlja zamke, moraćete da podesite svoj scraper u skladu sa tim.
Captcha je još jedan ozbiljan problem za scraper-e. Većina web lokacija danas koristi captcha zaštitu kako bi sprečila pristup botovima. U takvim slučajevima, možda ćete morati da koristite rešavač captcha.
Struganje web stranice pomoću Pythona
Kao što smo rekli, koristićemo BeautifulSoup za struganje web lokacije. U ovom vodiču ćemo „ostrugati“ istorijske podatke Ethereuma sa CoinGecko i sačuvati podatke iz tabele kao JSON datoteku. Započnimo sa izradom scraper-a.
Prvi korak je instaliranje BeautifulSoup-a i Requests. Za ovaj vodič koristiću Pipenv, menadžer virtuelnog okruženja za Python. Možete koristiti i venv ako želite, ali ja preferiram Pipenv. Diskusija o Pipenv-u je van okvira ovog uputstva. Ukoliko želite da naučite kako se koristi Pipenv, pogledajte ovaj vodič. Ili, ukoliko želite da razumete Python virtuelna okruženja, pogledajte ovaj vodič.
Pokrenite Pipenv shell u svom projektnom direktorijumu pokretanjem komande `pipenv shell`. Time ćete pokrenuti podproces u vašem virtuelnom okruženju. Sada, da biste instalirali BeautifulSoup, pokrenite sledeću komandu:
pipenv install beautifulsoup4
I, za instaliranje Requests-a, pokrenite sličnu komandu kao i gore:
pipenv install requests
Kada se instalacija završi, importujte potrebne pakete u glavnu datoteku. Napravite datoteku pod nazivom `main.py` i importujte pakete kao što je dole prikazano:
from bs4 import BeautifulSoup import requests import json
Sledeći korak je da dobijete sadržaj stranice sa istorijskim podacima i parsirate ga pomoću HTML parsera iz BeautifulSoup-a.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
U gornjem kodu, stranici se pristupa korišćenjem metode `get` iz biblioteke `requests`. Parsirani sadržaj se zatim čuva u varijabli koja se zove `soup`.
Sada počinje stvarni deo scraping-a. Prvo, morate precizno da identifikujete tabelu u DOM-u. Ukoliko otvorite ovu stranicu i pregledate je pomoću alata za razvojne programere u pretraživaču, videćete da tabela ima klase `table table-striped text-sm text-lg-normal`.
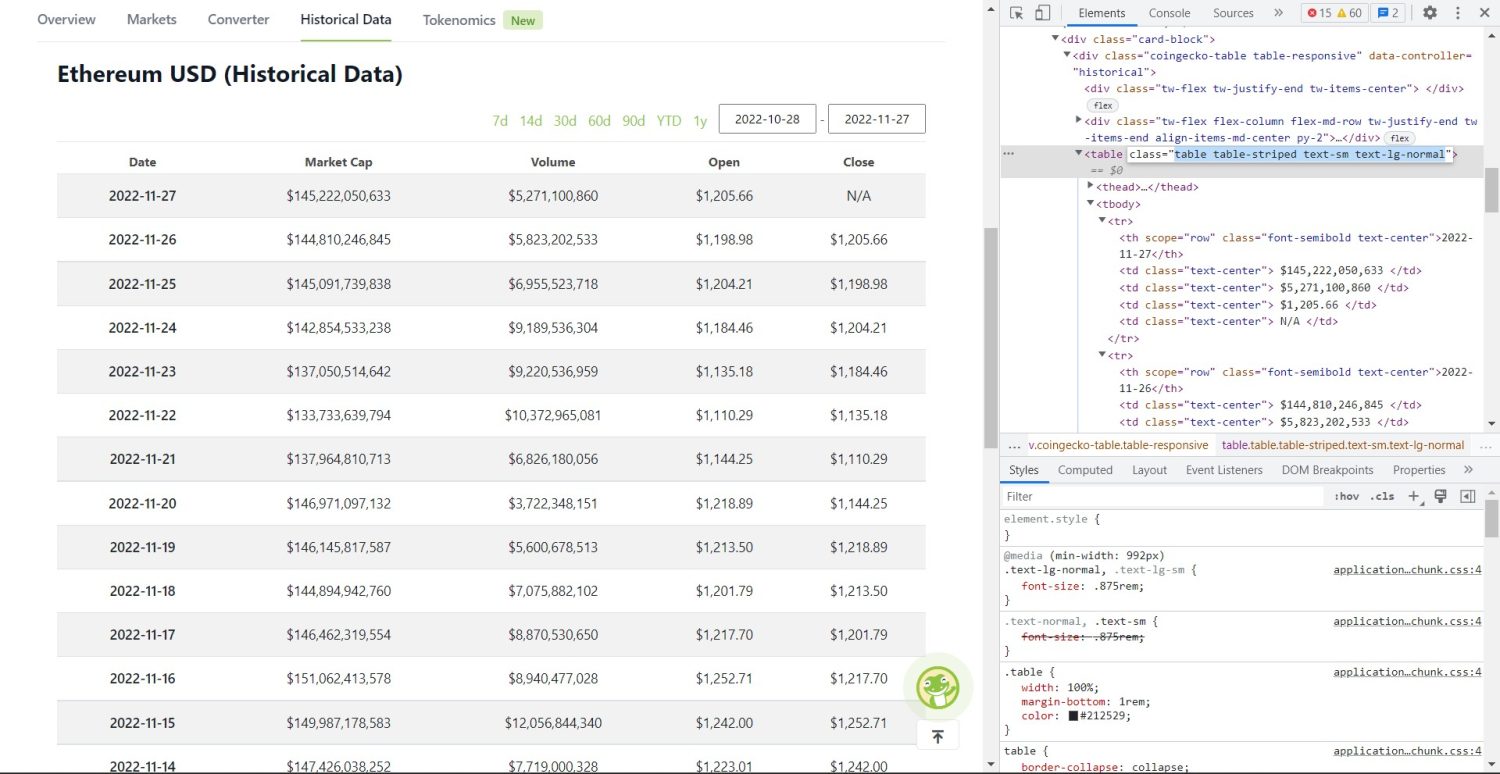 Tabela istorijskih podataka CoinGecko Ethereum
Tabela istorijskih podataka CoinGecko Ethereum
Da biste tačno ciljali ovu tabelu, možete koristiti metodu `find`.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
U gornjem kodu, prvo se tabela pronalazi korišćenjem metode `soup.find`, a zatim se metodom `find_all` pretražuju svi `tr` elementi unutar tabele. Ovi `tr` elementi se čuvaju u varijabli pod nazivom `table_data`. Tabela ima nekoliko elemenata zaglavlja. Nova varijabla pod nazivom `table_headings` se inicijalizuje da bi sačuvala zaglavlja u listi.
Zatim se pokreće `for` petlja za prvi red tabele. U ovom redu se traže svi elementi sa oznakom `th`, a njihova tekstualna vrednost se dodaje u listu `table_headings`. Tekst se izvlači pomoću metode `text`. Ukoliko sada ispišete varijablu `table_headings`, videćete sledeći izlaz:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Sledeći korak je da izvučemo ostatak elemenata, generišemo rečnik za svaki red i dodamo redove u listu.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Ovo je suštinski deo koda. Za svaki `tr` u varijabli `table_data`, prvo se pretražuju elementi `th`. `th` elementi su datum prikazan u tabeli. Ovi elementi se čuvaju unutar varijable `th`. Slično tome, svi `td` elementi se čuvaju u varijabli `td`.
Inicijalizuju se prazni podaci rečnika. Nakon inicijalizacije, prolazimo kroz opseg `td` elemenata. Za svaki red, prvo ažuriramo prvo polje rečnika sa prvom stavkom iz `th`. Kod `table_headings[0]: th[0].text` dodeljuje par ključ-vrednost datuma i prvog elementa.
Nakon inicijalizacije prvog elementa, ostali elementi se dodeljuju pomoću `data.update({table_headings[i+1]: td[i].text.replace(‘n’, “)})`. Ovde se tekst `td` elemenata prvo izvlači metodom `text`, a zatim se svi `n` zamenjuju metodom `replace`. Vrednost se zatim dodeljuje i+1. elementu liste `table_headings` jer je i-ti element već dodeljen.
Zatim, ako dužina rečnika `data` prelazi nulu, rečnik dodajemo na listu `table_details`. Možete da ispišete listu `table_details` da biste je proverili. Ali mi ćemo vrednosti zapisati u JSON datoteku. Pogledajmo kod za to,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Ovde koristimo metodu `json.dump` da zapišemo vrednosti u JSON datoteku pod nazivom `table.json`. Kada se upisivanje završi, ispisujemo „Data saved to json file…“ u konzolu.
Sada pokrenite datoteku koristeći sledeću komandu,
python run main.py
Nakon nekog vremena, videćete tekst „Data saved to json file…“ u konzoli. Takođe, videćete novu datoteku pod nazivom `table.json` u radnom direktorijumu. Datoteka će izgledati slično sledećoj JSON datoteci:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Uspešno ste implementirali web scraper koristeći Python. Ukoliko želite da pogledate kompletan kod, možete posetiti ovaj GitHub repozitorijum.
Zaključak
U ovom članku je objašnjeno kako možete implementirati jednostavan Python scraper. Razgovarali smo o tome kako se BeautifulSoup može koristiti za brzo struganje podataka sa web stranice. Takođe smo razgovarali o drugim dostupnim bibliotekama i zašto je Python prvi izbor mnogih programera za scraping web stranica.
Takođe, možete pogledati ove okvire za struganje veba.