Šta je to Mašina sa Vektorima Podrške (SVM)?
Mašina sa vektorima podrške, ili SVM, predstavlja jedan od najčešće upotrebljavanih algoritama u domenu mašinskog učenja. Njena efikasnost i sposobnost treniranja na ograničenim skupovima podataka čine je izuzetno popularnom. Ali, šta je zapravo SVM?
Razumevanje Suštine SVM-a
SVM je algoritam mašinskog učenja koji koristi nadgledano učenje za izgradnju modela namenjenih binarnoj klasifikaciji. Ovaj koncept može zvučati složeno, pa ćemo u ovom tekstu detaljnije objasniti SVM i njegovu primenu u obradi prirodnog jezika. Pre nego što pređemo na primere, analiziraćemo princip rada SVM-a.
Kako Radi SVM?
Zamislimo jednostavan problem klasifikacije gde imamo podatke sa dve karakteristike, označene kao x i y, i jedan izlaz – klasifikaciju koja može biti ili crvena ili plava. Grafički, ovi podaci se mogu predstaviti na sledeći način:
Zadatak je da, na osnovu ovakvih podataka, kreiramo granicu odlučivanja. Ta granica je linija koja odvaja crvene i plave tačke. Evo istog skupa podataka sa dodatom granicom odlučivanja:
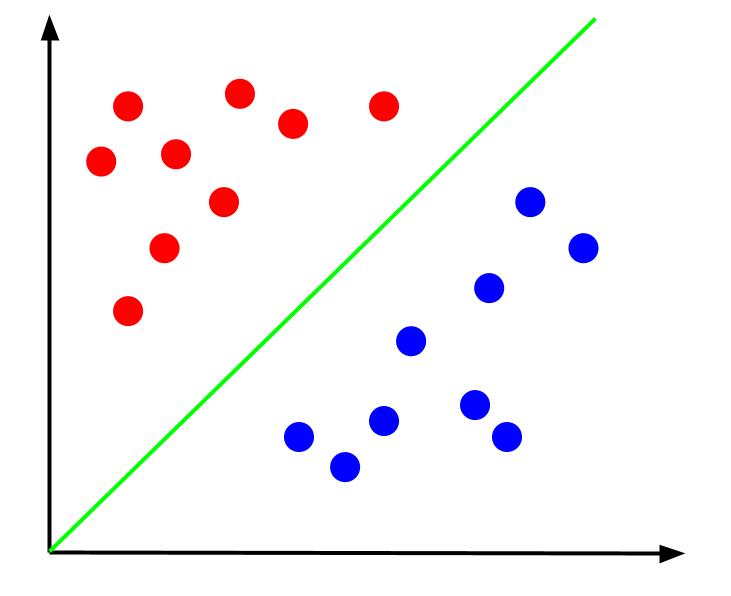
Kada imamo definisanu granicu odlučivanja, možemo da predvidimo kojoj klasi pripada neka tačka na osnovu njene pozicije u odnosu na tu granicu. Algoritam SVM-a pronalazi optimalnu granicu odlučivanja za klasifikaciju.
Ali, šta podrazumevamo pod „optimalnom granicom odlučivanja“?
Najbolja granica odlučivanja je ona koja maksimizira udaljenost od takozvanih vektora podrške. Vektori podrške su one tačke podataka, iz bilo koje klase, koje su najbliže tačkama suprotne klase. Ove tačke su najrizičnije za pogrešnu klasifikaciju zbog njihove blizine drugoj klasi.
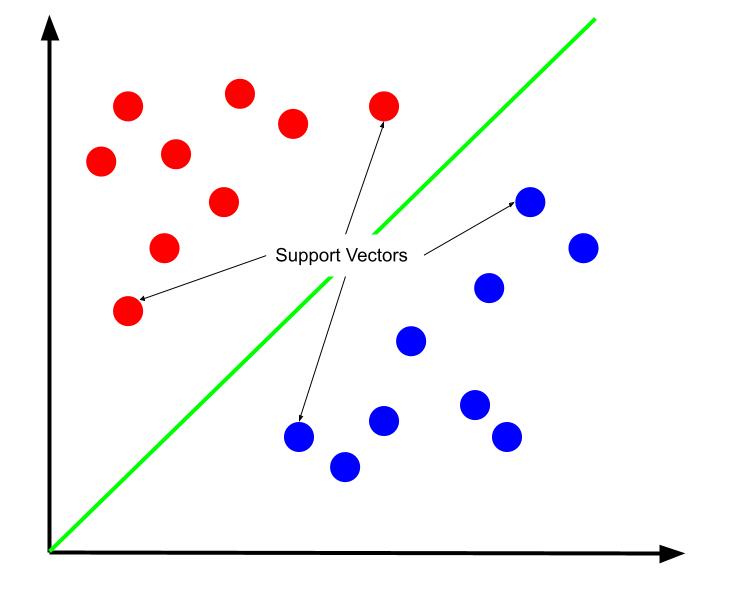
Obučavanje SVM-a, stoga, podrazumeva traženje linije koja povećava razmak između vektora podrške.
Važno je naglasiti da su pozicija granice odlučivanja određena samo vektorima podrške. Ostale tačke podataka su suvišne. Dakle, treniranje zahteva samo vektore podrške.
U ovom primeru, granica odlučivanja je prikazana kao prava linija, jer skup podataka ima samo dve karakteristike. Ako skup podataka ima tri karakteristike, granica odlučivanja bi bila ravan, a ne linija. Ako pak postoji četiri ili više karakteristika, granica odlučivanja se naziva hiperravan.
Nelinearno Razdvojivi Podaci
U prethodnom primeru, koristili smo jednostavne podatke koji se mogu razdvojiti linearnom granicom odlučivanja. Međutim, razmotrimo slučaj gde podaci izgledaju ovako:
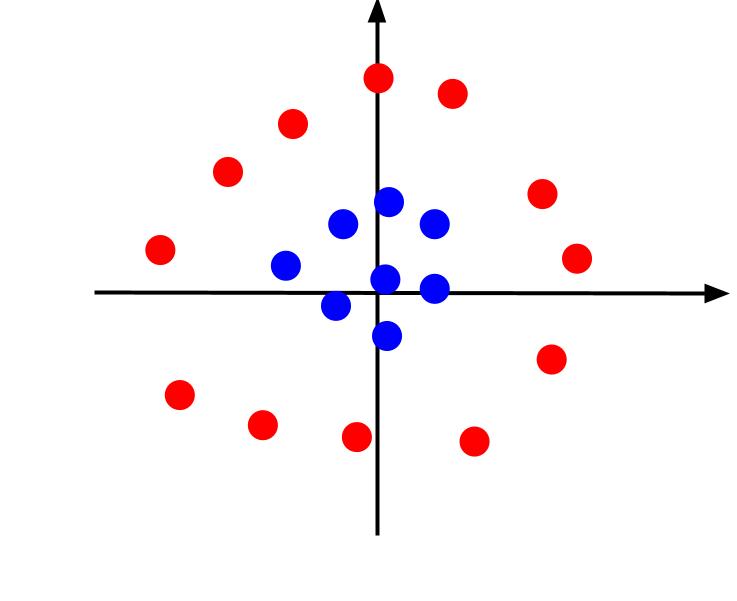
U ovom slučaju, podaci se ne mogu razdvojiti linijom. Međutim, možemo uvesti novu karakteristiku, z, koja se definiše kao z = x^2 + y^2. Dodavanjem z-ose, dobijamo trodimenzionalni prostor.
Kada pogledamo 3D prikaz iz ugla gde je x-osa horizontalna, a z-osa vertikalna, dobijamo sliku koja izgleda otprilike ovako:
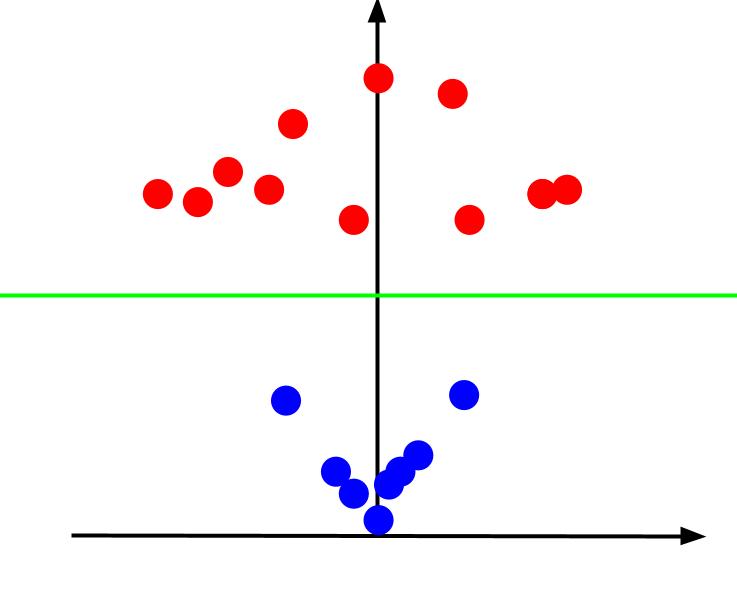
Z-vrednost pokazuje koliko je tačka udaljena od centra u odnosu na ostale tačke u staroj XY ravni. Plave tačke, koje su bliže centru, imaju niske z-vrednosti, dok crvene tačke, koje su dalje od centra, imaju veće z-vrednosti. Kada se iste tačke prikažu u odnosu na njihove z-vrednosti, dobijamo jasnu klasifikaciju koja se može odvojiti linearnom granicom odlučivanja.
Ova tehnika mapiranja dimenzija u veći broj dimenzija je ključna za SVM. Funkcije koje to omogućavaju su funkcije kernela. Postoji više vrsta funkcija kernela, kao što su sigmoidna, linearna, nelinearna i RBF.
Za efikasnije mapiranje ovih karakteristika, SVM koristi trik kernela.
Primena SVM-a u Mašinskom Učenju
Pored stabala odlučivanja i neuronskih mreža, SVM je jedan od najznačajnijih algoritama u mašinskom učenju. Njegova prednost leži u tome što efikasno radi sa manje podataka u poređenju sa drugim algoritmima. SVM se najčešće koristi u sledećim oblastima:
- Klasifikacija teksta: Kategorizacija tekstualnih podataka poput komentara i recenzija u jednu ili više kategorija.
- Prepoznavanje lica: Analiza slika u cilju prepoznavanja lica za različite namene, kao što je dodavanje filtera za proširenu stvarnost.
- Klasifikacija slika: SVM uspešno klasifikuje slike efikasnije od drugih pristupa.
Problem Klasifikacije Teksta
Internet je preplavljen velikom količinom tekstualnih podataka. Međutim, većina ovih podataka je nestrukturirana i neoznačena. Za bolju upotrebu i razumevanje ovih tekstualnih podataka, potrebna je njihova klasifikacija. Evo nekoliko primera kada se tekst klasifikuje:
- Kategorizacija tvitova u teme kako bi korisnici mogli da prate željene oblasti interesovanja.
- Razvrstavanje email poruka u kategorije kao što su društvene, promotivne ili neželjene.
- Klasifikacija komentara na javnim forumima kao govor mržnje ili nepristojan sadržaj.
Kako SVM Funkcioniše u Klasifikaciji Prirodnog Jezika?
SVM se koristi za klasifikaciju teksta u tekst koji pripada određenoj temi i tekst koji joj ne pripada. To se postiže prvo pretvaranjem tekstualnih podataka u skup podataka sa određenim karakteristikama.
Jedan od načina je da se kreiraju karakteristike za svaku reč u skupu podataka. Zatim se beleži koliko puta se svaka reč pojavljuje u svakoj tački tekstualnih podataka. Ako se u skupu podataka pojave jedinstvene reči, tada ćete imati karakteristike u skupu podataka.
Pored toga, potrebno je obezbediti klasifikacije za ove tačke podataka. Iako su ove klasifikacije označene tekstom, većina SVM implementacija očekuje numeričke oznake.
Stoga je neophodno da konvertujete ove oznake u brojeve pre treniranja. Kada je skup podataka pripremljen, možete koristiti SVM model da klasifikuje tekst, koristeći ove karakteristike kao koordinate.
Kreiranje SVM Modela u Python-u
Za kreiranje modela mašine sa vektorima podrške (SVM) u programskom jeziku Python, možete koristiti klasu SVC koja se nalazi u biblioteci scikit-learn (sklearn). Evo primera kako da koristite klasu SVC za kreiranje SVM modela u Python-u:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# Učitavanje skupa podataka
X = ...
y = ...
# Podela podataka na skupove za trening i testiranje
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Kreiranje SVM modela
model = SVC(kernel="linear")
# Treniranje modela na trening podacima
model.fit(X_train, y_train)
# Evaluacija modela na test podacima
accuracy = model.score(X_test, y_test)
print("Tačnost: ", accuracy)
U ovom primeru, prvo se uvozi klasa SVC iz biblioteke sklearn.svm. Zatim se učitava skup podataka i deli na skupove za trening i testiranje.
Zatim se kreira SVM model instanciranjem objekta SVC i navođenjem parametra „kernel“ kao ‘linear’. Nakon toga, model se trenira na trening podacima koristeći metodu fit(), a njegova tačnost se procenjuje na test podacima koristeći metodu score(). Metoda score() vraća tačnost modela, koja se ispisuje na konzoli.
Moguće je definisati i druge parametre za objekat SVC, poput parametra C koji kontroliše jačinu regularizacije i parametra gama, koji kontroliše koeficijent kernela za određene jezgre.
Prednosti SVM-a
Lista nekih prednosti korišćenja mašine sa vektorima podrške (SVM):
- Efikasnost: SVM modeli su uglavnom efikasni u procesu treniranja, posebno kada je veliki broj uzoraka.
- Otpornost na šum: SVM je relativno otporan na šum u podacima za obuku, jer pokušava da pronađe klasifikator sa najvećom marginom, koji je manje osetljiv na šum od ostalih klasifikatora.
- Efikasnost memorije: SVM zahteva samo podskup podataka za trening u memoriji u svakom trenutku, što ga čini efikasnijim u pogledu memorije u poređenju sa drugim algoritmima.
- Efikasan u visokodimenzionalnim prostorima: SVM nastavlja da pruža dobre rezultate čak i kada broj karakteristika prevazilazi broj uzoraka.
- Svestranost: SVM se može koristiti za zadatke klasifikacije i regresije i može da obrađuje različite tipove podataka, uključujući linearne i nelinearne.
Sada, pogledajmo neke od najboljih resursa za učenje o SVM-u.
Resursi za Učenje
Uvod u Mašine sa Vektorima Podrške
Knjiga „Uvod u mašine sa vektorima podrške“ daje sveobuhvatan i postepen uvid u metode učenja zasnovane na kernelu.
Ova knjiga vam pruža čvrstu osnovu u teoriji mašina sa vektorima podrške.
Primena Mašina sa Vektorima Podrške
Za razliku od prve knjige koja je fokusirana na teoriju, ova knjiga o primenama SVM-a usmerena je na praktične primene.
Ona istražuje kako se SVM koristi u obradi slika, detekciji obrazaca i kompjuterskoj viziji.
Mašine sa Vektorima Podrške (Informatika i Statistika)
Cilj ove knjige, „Mašine sa vektorima podrške (Informatika i Statistika)”, je da pruži uvid u principe koji stoje iza efikasnosti SVM-a u različitim primenama.
Autori naglašavaju nekoliko faktora koji doprinose uspehu SVM-a, uključujući njihovu sposobnost da dobro funkcionišu sa ograničenim brojem podesivih parametara, njihovu otpornost na različite vrste grešaka i anomalija, kao i njihove efikasne računske performanse u poređenju sa drugim metodama.
Učenje sa Kernelima
„Učenje sa kernelima“ je knjiga koja čitaoce upoznaje sa mašinama sa vektorima podrške (SVM) i sličnim tehnikama kernela.
Dizajnirana je tako da čitaocima pruži osnovno razumevanje matematike i znanja potrebnog za korišćenje algoritama kernela u mašinskom učenju. Knjiga ima za cilj da pruži temeljno, ali pristupačno razumevanje SVM-a i metoda kernela.
Mašine sa Vektorima Podrške uz Sci-kit Learn
Ovaj online kurs o SVM uz Sci-kit Learn, sa platforme Coursera, vas uči kako da implementirate SVM model koristeći popularnu biblioteku za mašinsko učenje – Sci-Kit Learn.

Pored toga, naučićete teoriju koja stoji iza SVM-a i njihove prednosti i ograničenja. Kurs je namenjen početnicima i traje oko 2,5 sata.
Mašine sa Vektorima Podrške u Python-u: Koncepti i Kod
Ovaj plaćeni online kurs o SVM u Python-u, sa platforme Udemy, obuhvata do 6 sati video instrukcija i dolazi sa sertifikatom.

Kurs objašnjava SVM i kako ih implementirati u Pythonu. Osim toga, obrađuje poslovne primene SVM-a.
Mašinsko Učenje i Veštačka Inteligencija: Mašine sa Vektorima Podrške u Python-u
U ovom kursu o mašinskom učenju i veštačkoj inteligenciji, naučićete kako da koristite SVM za različite praktične primene, uključujući prepoznavanje slika, detekciju neželjene pošte, medicinsku dijagnozu i regresionu analizu.

Koristićete programski jezik Python za implementaciju ML modela za ove aplikacije.
Završne Reči
U ovom članku smo kratko upoznali teoriju koja stoji iza mašina sa vektorima podrške. Naučili smo o njihovoj primeni u mašinskom učenju i obradi prirodnog jezika.
Takođe smo videli kako izgleda njegova implementacija pomoću scikit-learn biblioteke. Pored toga, razmatrali smo praktične primene i prednosti SVM-a.
Iako je ovaj članak bio samo uvod, preporučuju se dodatni resursi za detaljnije istraživanje. S obzirom na svestranost i efikasnost, SVM modeli su vredni razumevanja za svakog ko želi da se razvije kao naučnik podataka ili ML inženjer.
Zatim, možete pogledati najbolje modele mašinskog učenja.