Веб стругање представља моћну технику за издвајање информација са интернет страница и њихову аутоматску анализу. Иако је могуће ручно обавити овај процес, он често постаје заморан и одузима много времена. Зато алати за веб стругање омогућавају брже, ефикасније и јефтиније прикупљање података.
Занимљиво је да Гоогле табеле, захваљујући функцији ИМПОРТКСМЛ, могу послужити као ваш свеобухватни алат за веб стругање. Помоћу ИМПОРТКСМЛ функције, можете једноставно преузимати податке са веб страница и користити их за анализу, извештавање или било које друге задатке који се ослањају на податке.
Функција ИМПОРТКСМЛ у Гоогле табелама
Гоогле табеле имају уграђену функцију ИМПОРТКСМЛ, која омогућава увоз података из веб формата као што су КСМЛ, ХТМЛ, РСС и ЦСВ. Ова функција је посебно корисна ако желите да прикупљате податке са веб локација без потребе за сложеним програмирањем.
Основна синтакса ИМПОРТКСМЛ функције је следећа:
=IMPORTXML(url, xpath_query)
- url: УРЛ адреса веб странице са које желите да преузмете податке.
- xpath_query: КСПатх упит који дефинише које податке желите да издвојите.
КСПатх (КСМЛ Патх Лангуаге) је језик који се користи за кретање кроз КСМЛ документе, укључујући и ХТМЛ. Он вам омогућава да прецизирате локацију података у оквиру ХТМЛ структуре. Разумевање КСПатх упита је кључно за ефикасну употребу ИМПОРТКСМЛ функције.
Разумевање КСПатх-а
КСПатх пружа различите функције и изразе за кретање и филтрирање података унутар ХТМЛ документа. Комплетан водич за КСМЛ и КСПатх превазилази обим овог чланка, па ћемо се фокусирати на основне КСПатх концепте:
- Избор елемената: Елементе можете бирати користећи
/и//за означавање путања. На пример,/html/body/divбира све див елементе унутар тела документа. - Избор атрибута: Атрибуте бирате користећи
@. На пример,//@hrefбира све хреф атрибуте на страници. - Филтери предиката: Елементе можете филтрирати користећи предикате унутар угластих заграда (
[ ]). На пример,/div[@class="container"]бира све див елементе са класом „container“. - Функције: КСПатх нуди различите функције као што су
contains(),starts-with()иtext()за извођење специфичних радњи, као што је провера садржаја текста или вредности атрибута.
Сада знате синтаксу ИМПОРТКСМЛ функције, имате УРЛ веб странице и знате који елемент желите да издвојите. Али како доћи до КСПатх-а елемента?
Не морате детаљно познавати структуру веб странице да бисте преузели њене податке помоћу ИМПОРТКСМЛ-а. Сваки прегледач има алат који вам омогућава да брзо копирате КСПатх било ког елемента.
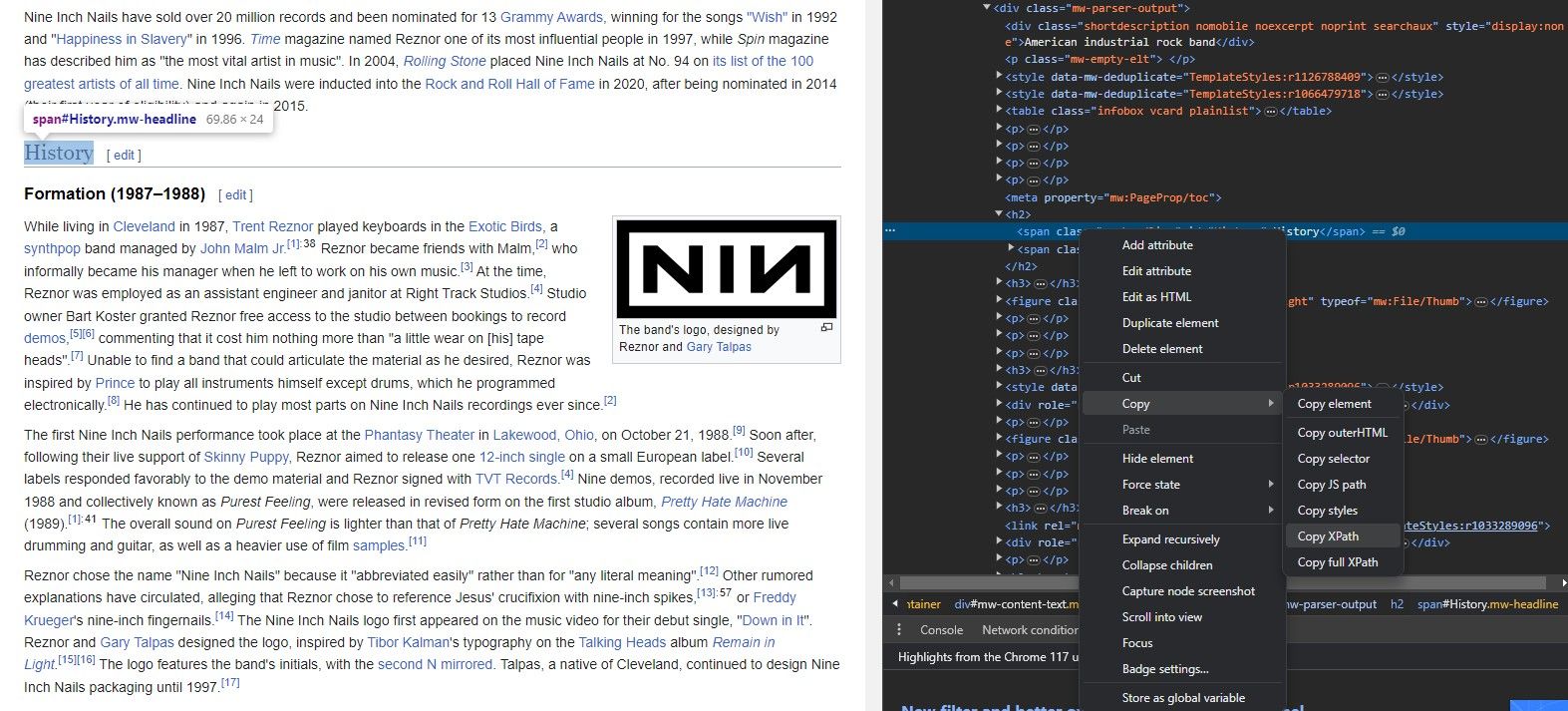
Алат „Инспецт Елемент“ вам омогућава да преузмете КСПатх са веб елемената. Ево како:
- Посетите веб страницу коју желите да стружете у свом прегледачу.
- Пронађите елемент који желите да преузмете.
- Десним кликом миша кликните на елемент.
- Изаберите „Инспецт Елемент“ из контекстног менија. Прегледач ће отворити панел са ХТМЛ кодом веб странице, а релевантни елемент ће бити истакнут.
- У панелу „Инспецт Елемент“, десним кликом миша кликните на истакнути елемент у ХТМЛ коду.
- Кликните на „Копирај КСПатх“ да бисте копирали КСПатх адресу елемента у међуспремник.
Сада када имате све што вам је потребно, време је да видите ИМПОРТКСМЛ на делу и преузмете неке везе.
Како преузети везе са веб странице помоћу ИМПОРТКСМЛ-а
ИМПОРТКСМЛ омогућава извлачење различитих типова података са веб страница, укључујући везе, видео записе, слике и готово све елементе странице. Везе су посебно важан елемент у веб анализи и могу открити много тога о сајту само анализом страница ка којима воде.
ИМПОРТКСМЛ омогућава брзо преузимање веза у Гоогле табелама, које се касније могу анализирати користећи друге функције које Гоогле табеле нуде.
1. Преузимање свих веза
За преузимање свих веза са веб странице, користите следећу формулу:
=IMPORTXML(url, "//a/@href")
Овај КСПатх упит бира све хреф атрибуте елемента, што резултира издвајањем свих веза на страници.
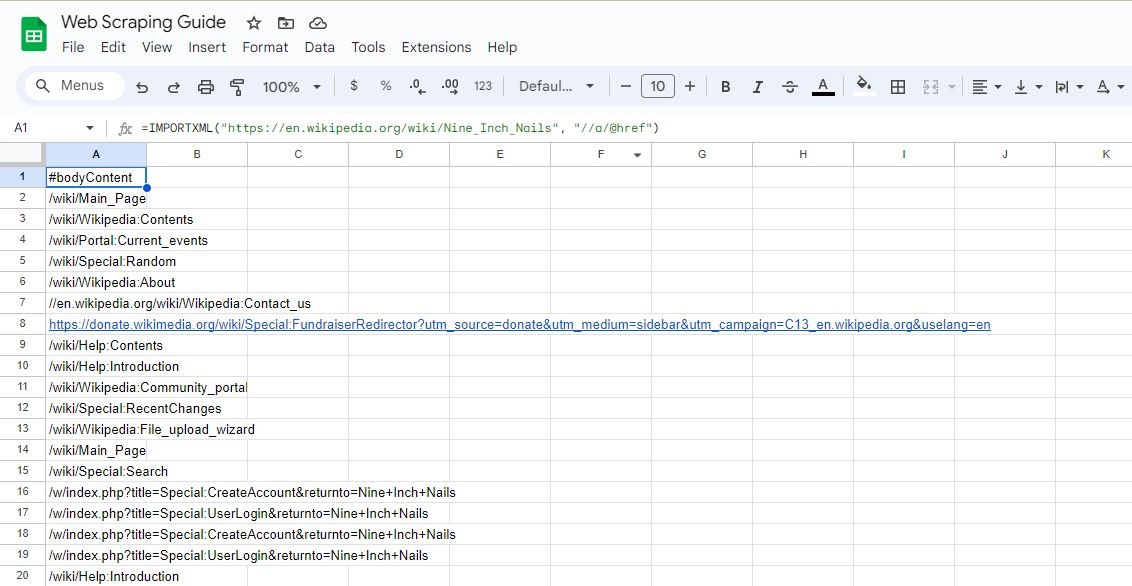
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Горе наведена формула преузима све везе из чланка на Википедији.
Препоручљиво је да УРЛ веб странице ставите у посебну ћелију и онда се позивате на њу. Ово ће спречити да формула постане превише дуга и компликована. Исто важи и за КСПатх упит.
2. Преузимање текста свих веза
Да бисте издвојили текст веза заједно са њиховим УРЛ адресама, користите:
=IMPORTXML(url, "//a")
Овај упит бира све елементе , а из добијених резултата можете издвојити и текст везе и њену УРЛ адресу.
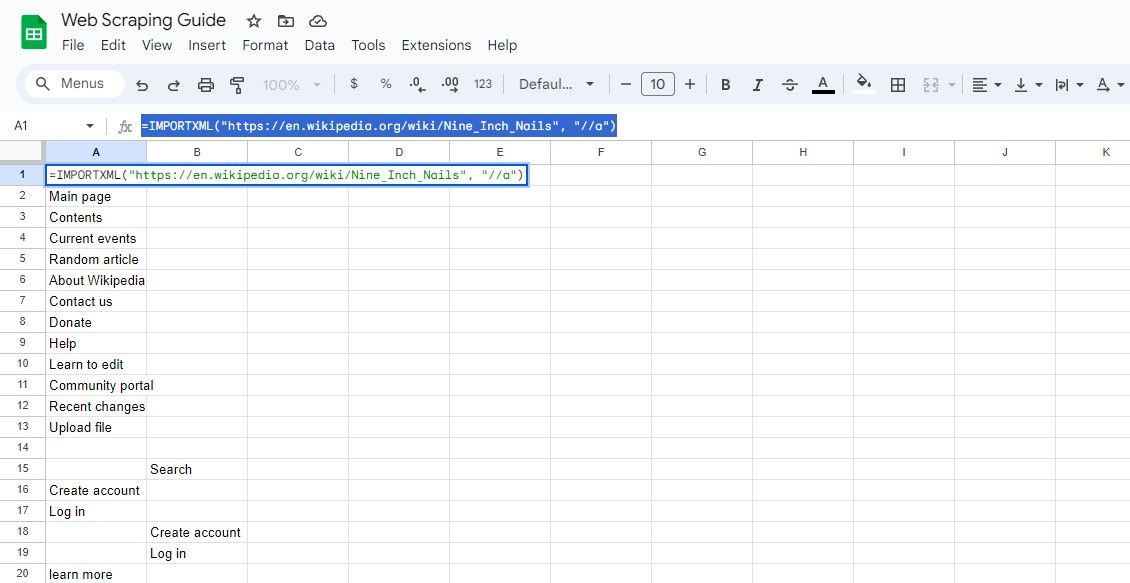
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Горе наведена формула преузима текстове веза из истог чланка на Википедији.
Како преузети специфичне везе са веб странице помоћу ИМПОРТКСМЛ-а
Понекад је потребно преузети одређене везе на основу критеријума. На пример, можда вас интересују везе које садрже одређену кључну реч или се налазе у специфичном делу странице.
Уз добро познавање КСПатх-а, можете прецизно циљати било који елемент који вам је потребан.
1. Преузимање веза које садрже кључну реч
Да бисте преузели везе које садрже одређену кључну реч, користите функцију contains() у КСПатх-у:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
Овај упит бира хреф атрибуте оних елемената где хреф атрибут садржи наведену кључну реч.
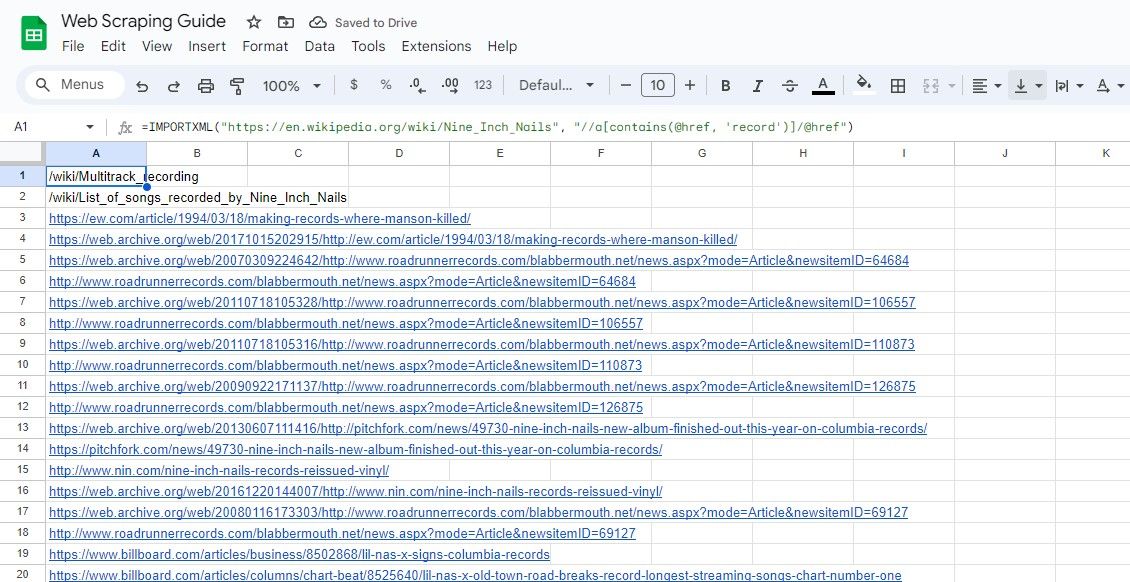
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Горе наведена формула преузима све везе које садрже реч „record“ у свом тексту, у оквиру примера са чланком на Википедији.
2. Преузимање веза из одређеног одељка
За преузимање веза из одређеног одељка странице, потребно је навести КСПатх за тај одељак. На пример:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Овај упит бира хреф атрибуте елемената унутар див елемената са класом „section“.
Слично, доња формула бира све везе унутар див елемента који има класу „mw-content-container“:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Треба напоменути да ИМПОРТКСМЛ можете користити за више од веб стругања. Функције ИМПОРТ породице можете користити за увоз табела са подацима са веб страница у Гоогле табеле.
Иако Гоогле табеле и Екцел деле већину функција, ИМПОРТ функције су специфичне за Гоогле табеле. За увоз података са веб локација у Екцел, мораћете да користите друге методе.
Поједноставите Веб Стругање помоћу Гоогле табела
Веб стругање помоћу Гоогле табела и функције ИМПОРТКСМЛ је прилагодљив и приступачан начин за прикупљање података са веб страница.
Савладавањем КСПатх-а и разумевањем како креирати ефикасне упите, можете откључати пуни потенцијал ИМПОРТКСМЛ-а и добити вредне увиде из веб ресурса. Зато почните да експериментишете и подигните своју веб анализу на виши ниво!