Појам и значај Data Lakehouse архитектуре
Data Lakehouse представља нову парадигму у управљању подацима, која обједињује најбоље карактеристике језера података и складишта података. Ова архитектура омогућава складиштење различитих типова података на једној платформи, уз могућност извођења упита и аналитике са АЦИД својствима.
Зашто користити Data Lakehouse? Као искусни софтверски инжењер, разумем изазове у управљању и одржавању два одвојена система, посебно када је у питању пренос великих количина података између њих.
Ако желите да анализирате податке за пословну аналитику и креирање извештаја, потребно је да структуриране податке чувате у складишту података. С друге стране, за чување свих података из различитих извора у оригиналном формату, потребна вам је језеро података. Data Lakehouse елиминише потребу за одржавањем различитих система, спајајући предности оба приступа.
Значај Data Lakehouse-а

За напредак ваше организације и пословања, неопходно је складиштити и анализирати податке, без обзира на њихов формат или структуру. Data Lakehouse је кључан за савремено управљање подацима, решавајући ограничења језера и складишта података.
Језера података често могу постати „мочваре података“, где се подаци складиште без структуре и управљања, што отежава њихово проналажење и коришћење, уз могућност проблема са квалитетом. С друге стране, складишта података могу бити превише крута и скупа.
Data Lakehouse поседује специфичне карактеристике. Хајде да их погледамо.
Карактеристике Data Lakehouse-а
Пре него што детаљније анализирамо архитектуру Data Lakehouse-а, погледајмо њене кључне карактеристике:
- Подршка за трансакције: Када се Data Lakehouse користи у великим размерама, дешава се истовремено читање и писање података. АЦИД усклађеност гарантује да истовремене операције неће ометати интегритет података.
- Подршка за пословну интелигенцију: БИ алати се могу директно повезати са индексираним подацима, елиминишући потребу за копирањем података. Ово омогућава приступ најновијим подацима брже и по нижој цени.
- Одвојен слој за складиштење и рачунање: Одвојени слојеви омогућавају скалирање сваког од њих независно, без утицаја на други. На пример, потребе за већим складиштем не морају да утичу на рачунарске ресурсе.
- Подршка за различите типове података: Пошто је база података изграђена на језеру података, подржава различите типове и формате, као што су аудио, видео, слике и текст.
- Отворени формати за складиштење: Data Lakehouse користи отворене и стандардизоване формате, као што је Apache Parquet, што омогућава коришћење различитих алата и библиотека за приступ подацима.
- Подршка за различита оптерећења: На основу података у језеру података, можете изводити различите типове радних оптерећења, укључујући SQL упите, БИ, аналитику и машинско учење.
- Подршка за стримовање у реалном времену: Нема потребе за креирањем посебног складишта података и цевовода за аналитику у реалном времену.
- Управљање шемом: Data Lakehouse промовише робусно управљање подацима и ревизију.
Архитектура Data Lakehouse-а
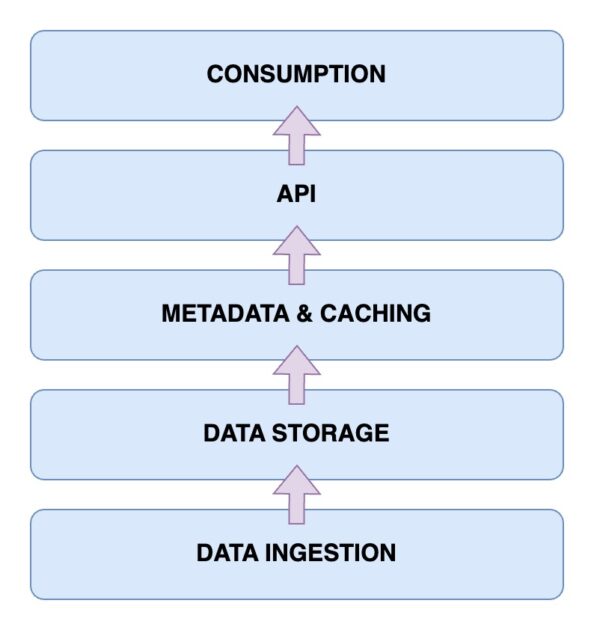
Сада ћемо размотрити архитектуру Data Lakehouse-а. Разумевање архитектуре је кључно за разумевање његовог функционисања. Архитектура се састоји од пет главних компоненти:
Слој за унос података
Ово је слој где се прикупљају сви различити подаци у различитим форматима. То могу бити промене у примарној бази података, подаци са IoT сензора или кориснички подаци у реалном времену.
Слој за складиштење података
Након уноса података из различитих извора, они се складиште у одговарајућим форматима. Овај слој представља ваше језеро података, које се може складиштити у различитим медијима као што је AWS S3.
Слој метаподатака и кеширање
Поред слоја за складиштење, потребан је слој метаподатака и управљања подацима. Он пружа јединствен поглед на све податке у језеру и додаје АЦИД трансакције, трансформишући језеро података у базу података.
API слој
Приступ индексираним подацима из слоја метаподатака је омогућен кроз API слој, било путем драјвера базе података или преко крајњих тачака доступних клијентима.
Слој за потрошњу података
Овај слој садржи аналитичке и БИ алате, који су главни корисници података из базе података. Овде се могу покренути програми машинског учења за добијање корисних увида.
Сада када имате јасну слику о архитектури, постави се питање: како изградити Data Lakehouse?
Кораци за изградњу Data Lakehouse-а
Погледајмо како можете направити сопствени Data Lakehouse, без обзира да ли имате постојеће језеро података или складиште, или градите од нуле:
- Идентификујте захтеве: Одредите типове података које ћете складиштити и које случајеве употребе желите да циљате, као што су машинско учење, пословни извештаји или аналитика.
- Креирајте цевовод за унос података: Овај цевовод је задужен за пренос података у систем, користећи магистрале за размену порука попут Apache Kafka или API крајње тачке.
- Направите слој за складиштење: Ако већ имате језеро података, користите га као слој за складиштење. У супротном, можете бирати између опција као што су AWS S3, HDFS или Delta Lake.
- Примена обраде података: Издвојите и трансформишите податке на основу пословних захтева, користећи алате отвореног кода попут Apache Spark за покретање периодичних послова.
- Креирајте управљање метаподацима: Пратите и складиштите различите врсте података и њихова својства за лаку каталогизацију и претраживање, уз могућност креирања слоја за кеширање.
- Обезбедите опције интеграције: Омогућите интеграцијске тачке за спољне алате који се повезују и приступају подацима, као што су SQL упити, алати за машинско учење или БИ решења.
- Имплементирајте управљање подацима: Успоставите политике управљања подацима, укључујући контролу приступа, шифровање и ревизију, за одржавање квалитета података, доследности и усклађености са прописима.
Даље, размотрићемо како мигрирати на Data Lakehouse ако већ имате постојеће решење за управљање подацима.
Кораци за миграцију на Data Lakehouse
Приликом миграције на Data Lakehouse, потребно је следити одређене кораке како би се избегли проблеми у последњем тренутку:
Корак 1: Анализа података
Први и кључни корак је анализа података за дефинисање обима миграције, идентификовање зависности и постављање приоритета. Ово вам омогућава бољи увид у окружење које мигрирате.
Корак 2: Припрема података за миграцију
Припремите податке које ћете мигрирати, као и потребне пратеће оквире. Одређивање који скупови података и колоне су вам заиста потребни може уштедети време и ресурсе.
Корак 3: Конверзија података у потребан формат
Користите алате за аутоматску конверзију података колико год је то могуће. Већина алата нуди једноставан SQL код или решења са ниским кодом, као што је Alchemist.
Корак 4: Валидација података након миграције
Аутоматизујте процес валидације података након миграције колико год је то могуће. Ручна валидација је заморна и успорава процес. Потврдите да пословни процеси и послови са подацима остају непромењени након миграције.
Кључне карактеристике Data Lakehouse-а
🔷 Комплетно управљање подацима: Data Lakehouse вам пружа функције управљања подацима, укључујући чишћење података, ETL процесе и спровођење шеме. Ово омогућава једноставну припрему података за аналитику и БИ алате.
🔷 Отворени формати за складиштење: Формат складиштења података је отворен и стандардизован, омогућавајући јединствен начин чувања података из различитих извора, са подршком за формате као што су AVRO, ORC или Parquet.
🔷 Одвајање складишта: Складиште се може одвојити од рачунарских ресурса коришћењем одвојених кластера, што омогућава засебно повећање складишта без непотребних промена у рачунарским ресурсима.
🔷 Подршка за стримовање података: Data Lakehouse омогућава доношење одлука на основу токова података у реалном времену, за разлику од стандардног складишта података.
🔷 Управљање подацима: Data Lakehouse подржава снажно управљање и ревизију података, што је кључно за одржавање интегритета.
🔷 Смањени трошкови података: Оперативни трошкови Data Lakehouse-а су мањи од складишта података. Можете користити складиште објеката у облаку по нижој цени, уз хибридну архитектуру која елиминише потребу за одржавањем више система за складиштење података.
Data Lake vs. Data Warehouse vs. Data Lakehouse
| Функција | Data Lake | Data Warehouse | Data Lakehouse |
| Складиште података | Складишти необрађене или неструктуриране податке | Складишти обрађене и структуриране податке | Складишти и сирове и структуриране податке |
| Шема података | Нема фиксну шему | Има фиксну шему | Користи шему отвореног кода за интеграције |
| Трансформација података | ELT | ETL, потребна трансформација података | ELT није потребна |
| Перформансе | Типично спорије због неструктурираних података | Веома брзо због структурираних података | Брзо због полуструктурираних података |
| Трошкови | Складиштење је исплативо | Већи трошкови складиштења и упита | Трошкови складиштења и упита су уравнотежени |
| Аналитика у реалном времену | Подржава аналитику у реалном времену | Ограничена подршка за аналитику у реалном времену | Подржава аналитику у реалном времену |
| Случајеви употребе | Складиштење података, истраживање, МЛ и AI | Извештавање и анализа помоћу БИ | И машинско учење и аналитика |
Закључак
Data Lakehouse ефикасно комбинује предности језера и складишта података, решавајући важне изазове у управљању и анализи података.
Сада сте упознати са карактеристикама и архитектуром Data Lakehouse-а. Значај ове базе података је очигледан у њеној способности да ради са структурираним и неструктурираним подацима, нудећи јединствену платформу за складиштење, упите и аналитику, уз АЦИД усаглашеност.
Користећи кораке из овог чланка за изградњу и миграцију на Data Lakehouse, можете откључати предности обједињене и исплативе платформе за управљање подацима. Будите у току са савременим пејзажом управљања подацима и покрените доношење одлука засновано на подацима, аналитику и пословни раст.
Погледајте наш детаљан чланак о репликацији података.