U ovom članku ćemo istražiti koncept vektorizacije, ključne tehnike u obradi prirodnog jezika (NLP), i razmotriti njenu važnost kroz sveobuhvatan pregled različitih tipova vektorizacije.
Prethodno smo obradili osnovne principe NLP preprocesiranja i čišćenja teksta. Razmotrili smo osnove NLP-a, njegove raznolike primene i tehnike kao što su tokenizacija, normalizacija, standardizacija i čišćenje teksta.

Pre nego što detaljnije analiziramo vektorizaciju, osvrnimo se na definiciju tokenizacije i kako se ona razlikuje od vektorizacije.
Šta je tokenizacija?
Tokenizacija je proces razdvajanja rečenica na manje jedinice, koje nazivamo tokenima. Tokeni omogućavaju računarima da lakše razumeju i rade sa tekstom.
Primer: „Ovaj članak je dobar“
Tokeni: [‘Ovaj’, ‘članak’, ‘je’, ‘dobar’].
Šta je vektorizacija?
Kao što je poznato, modeli i algoritmi mašinskog učenja operišu sa numeričkim podacima. Vektorizacija predstavlja proces transformacije tekstualnih ili kategoričkih podataka u numeričke vektore. Konverzijom podataka u numerički format, omogućavamo precizniju obuku modela.
Zašto je vektorizacija neophodna?
❇ Tokenizacija i vektorizacija imaju različite, ali komplementarne uloge u obradi prirodnog jezika (NLP). Tokenizacija deli rečenice na manje jedinice, dok ih vektorizacija pretvara u numerički format, čime omogućava razumevanje teksta od strane računara ili modela mašinskog učenja.
❇ Vektorizacija nije korisna samo za pretvaranje teksta u numerički oblik, već je ključna i za hvatanje semantičkog značenja teksta.
❇ Vektorizacija može smanjiti dimenzionalnost podataka, čineći ih efikasnijim, što je naročito korisno pri radu sa velikim skupovima podataka.
❇ Mnogi algoritmi mašinskog učenja, uključujući neuronske mreže, zahtevaju numerički unos, pa je vektorizacija neophodna u tim slučajevima.
Postoji nekoliko različitih tehnika vektorizacije, koje ćemo detaljno analizirati u nastavku ovog članka.
Model „Vreća reči“
Kada radimo sa velikom količinom dokumenata ili rečenica, model „Vreća reči“ (Bag of Words) pojednostavljuje proces analize tretirajući svaki dokument kao „vreću“ ispunjenu rečima.
Ovaj pristup se može primeniti u klasifikaciji teksta, analizi sentimenta i pronalaženju dokumenata.
Pretpostavimo da analizirate veliku količinu teksta. Model „Vreća reči“ vam pomaže da predstavite tekstualne podatke kreiranjem rečnika jedinstvenih reči. Nakon kreiranja rečnika, svaka reč se kodira kao vektor na osnovu učestalosti pojavljivanja svake reči u tekstu.
Ovi vektori se sastoje od nenegativnih brojeva (0, 1, 2…) koji predstavljaju broj pojavljivanja reči u datom dokumentu.
Model „Vreća reči“ uključuje tri koraka:
Korak 1: Tokenizacija
Razdvajanje dokumenata na tokene.
Na primer – (Rečenica: „Volim picu i volim hamburgere“)
Korak 2: Izdvajanje jedinstvenih reči / Kreiranje rečnika
Napravite listu svih jedinstvenih reči koje se pojavljuju u vašim rečenicama.
[„Ja“, „volim“, „pica“, „i“, „hamburger“]
Korak 3: Brojanje pojavljivanja reči / Kreiranje vektora
Ovaj korak broji koliko puta se svaka reč ponavlja iz rečnika i pohranjuje te podatke u retku matricu. U retkoj matrici, svaki red vektora rečenice ima dužinu (broj kolona u matrici) koja je jednaka veličini rečnika.
Uvoz CountVectorizer-a
Uvozimo CountVectorizer kako bismo obučili naš model „Vreća reči“.
from sklearn.feature_extraction.text import CountVectorizer
Kreiranje vektorizatora
U ovom koraku, kreiramo model koristeći CountVectorizer i obučavamo ga na osnovu našeg uzorka tekstualnih dokumenata.
# Primer tekstualnih dokumenata
documents = [
"Ovo je prvi dokument.",
"Ovaj dokument je drugi dokument.",
"I ovo je treći.",
"Da li je ovo prvi dokument?",
]
# Kreiranje CountVectorizer modela
cv = CountVectorizer()
# Obuka i transformacija X = cv.fit_transform(documents)
Konverzija u gusti niz
U ovom koraku pretvaramo reprezentacije u gusti niz i dobijamo imena funkcija, odnosno reči.
# Dobijanje imena funkcija/reči feature_names = vectorizer.get_feature_names_out() # Konverzija u gusti niz X_dense = X.toarray()
Štampanje matrice termina dokumenta i reči karakteristika
# Štampanje matrice termina dokumenta (DTM) i reči karakteristika
print("Matrica termina dokumenta (DTM):")
print(X_dense)
print("\nReči karakteristika:")
print(feature_names)
Matrica termina dokumenta (DTM):

Reči karakteristika:

Kao što vidimo, vektori se sastoje od nenegativnih brojeva (0, 1, 2…) koji predstavljaju frekvenciju pojavljivanja reči u dokumentu.
Imamo četiri primera tekstualnih dokumenata i identifikovali smo devet jedinstvenih reči iz ovih dokumenata. Jedinstvene reči čuvamo u rečniku, dodeljujući im „imena funkcija“.
Zatim, naš model „Vreća reči“ proverava da li je prva jedinstvena reč prisutna u prvom dokumentu. Ako je prisutna, dodeljuje joj vrednost 1, u suprotnom dodeljuje 0.
Ako se reč pojavi više puta, na primer, dva puta, dodeljuje joj se odgovarajuća vrednost, u ovom slučaju 2.
Ukoliko želimo jednu reč kao karakteristiku u ključu rečnika, to je unigramska reprezentacija.
n-grami = unigrami, bigrami itd.
Postoji mnogo biblioteka za implementaciju modela „Vreća reči“, kao što su scikit-learn, Keras, Gensim i druge. Ovaj model je jednostavan i koristan u različitim scenarijima.
Međutim, model „Vreća reči“ je brz, ali ima određena ograničenja:
Za rešavanje ovog problema, možemo koristiti bolje pristupe, kao što je TF-IDF. Razmotrimo ovaj model detaljnije.
TF-IDF
TF-IDF, ili frekvencija termina – inverzna frekvencija dokumenta, predstavlja numeričku reprezentaciju koja služi za utvrđivanje važnosti reči u dokumentu.
Zašto nam je potreban TF-IDF umesto modela „Vreća reči“?
Model „Vreća reči“ tretira sve reči jednako i fokusira se samo na učestalost jedinstvenih reči u rečenicama. TF-IDF daje važnost rečima u dokumentu, uzimajući u obzir i učestalost i jedinstvenost.
Reči koje se previše često ponavljaju ne nadjačavaju ređe, ali važnije reči.
TF: Frekvencija termina meri koliko je reč važna u jednoj rečenici.
IDF: Inverzna frekvencija dokumenta meri koliko je reč važna u celoj kolekciji dokumenata.
TF = Učestalost reči u dokumentu / Ukupan broj reči u tom dokumentu
DF = Dokument koji sadrži reč v / Ukupan broj dokumenata
IDF = log (ukupan broj dokumenata / dokumenti koji sadrže reč v)
IDF je recipročan DF-u. Razlog za to je što je reč češća u svim dokumentima, to je manji njen značaj u trenutnom dokumentu.
Konačni TF-IDF rezultat: TF-IDF = TF * IDF
Ovo je način da se utvrdi koje su reči česte u jednom dokumentu, ali i jedinstvene među svim dokumentima. Takve reči su korisne za identifikovanje glavne teme dokumenta.
Na primer:
Doc1 = „Volim mašinsko učenje“
Doc2 = „Volim Geekflare“
Potrebno je pronaći TF-IDF matricu za ove dokumente.
Prvo kreiramo rečnik jedinstvenih reči.
Rečnik = [„Ja“, „volim“, „mašinsko“, „učenje“, „Geekflare“]
Dakle, imamo 5 reči. Izračunajmo TF i IDF za svaku od njih.
TF = Učestalost reči u dokumentu / Ukupan broj reči u tom dokumentu
TF:
- Za „Ja“ = TF za Doc1: 1/4 = 0.25 i za Doc2: 1/3 ≈ 0.33
- Za „volim“: TF za Doc1: 1/4 = 0.25 i za Doc2: 1/3 ≈ 0.33
- Za „mašinsko“: TF za Doc1: 1/4 = 0.25 i za Doc2: 0/3 ≈ 0
- Za „učenje“: TF za Doc1: 1/4 = 0.25 i za Doc2: 0/3 ≈ 0
- Za „Geekflare“: TF za Doc1: 0/4 = 0 i za Doc2: 1/3 ≈ 0.33
Sada izračunajmo IDF.
IDF = log (ukupan broj dokumenata / dokumenti koji sadrže reč v)
IDF:
- Za „Ja“: IDF je log(2/2) = 0
- Za „volim“: IDF je log(2/2) = 0
- Za „mašinsko“: IDF je log(2/1) = log(2) ≈ 0.69
- Za „učenje“: IDF je log(2/1) = log(2) ≈ 0.69
- Za „Geekflare“: IDF je log(2/1) = log(2) ≈ 0.69
Sada izračunajmo konačni TF-IDF rezultat:
- Za „Ja“: TF-IDF za Doc1: 0.25 * 0 = 0 i TF-IDF za Doc2: 0.33 * 0 = 0
- Za „volim“: TF-IDF za Doc1: 0.25 * 0 = 0 i TF-IDF za Doc2: 0.33 * 0 = 0
- Za „mašinsko“: TF-IDF za Doc1: 0.25 * 0.69 ≈ 0.17 i TF-IDF za Doc2: 0 * 0.69 = 0
- Za „učenje“: TF-IDF za Doc1: 0.25 * 0.69 ≈ 0.17 i TF-IDF za Doc2: 0 * 0.69 = 0
- Za „Geekflare“: TF-IDF za Doc1: 0 * 0.69 = 0 i TF-IDF za Doc2: 0.33 * 0.69 ≈ 0.23
TF-IDF matrica izgleda ovako:
Ja volim mašinsko učenje Geekflare Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Vrednosti u TF-IDF matrici pokazuju koliko je svaki termin važan u svakom dokumentu. Visoke vrednosti ukazuju na to da je termin važan u određenom dokumentu, dok niske vrednosti sugerišu da je termin manje važan ili uobičajen u tom kontekstu.
TF-IDF se uglavnom koristi u klasifikaciji teksta, pronalaženju informacija za četbotove i sumiranju teksta.
Uvoz TfidfVectorizer-a
Uvozimo TfidfVectorizer iz scikit-learn biblioteke.
from sklearn.feature_extraction.text import TfidfVectorizer
Kreiranje vektorizatora
Kreiramo naš TF-IDF model koristeći TfidfVectorizer.
# Primer tekstualnih dokumenata
text = [
"Ovo je prvi dokument.",
"Ovaj dokument je drugi dokument.",
"I ovo je treći.",
"Da li je ovo prvi dokument?",
]
# Kreiranje TfidfVectorizer modela
cv = TfidfVectorizer()
Kreiranje TF-IDF matrice
Obučavamo model na osnovu tekstualnih podataka, a zatim pretvaramo reprezentativnu matricu u gusti niz.
# Obuka i transformacija za kreiranje TF-IDF matrice X = cv.fit_transform(text)
# Dobijanje imena funkcija/reči feature_names = vectorizer.get_feature_names_out() # Konverzija TF-IDF matrice u gusti niz radi lakše manipulacije (opcionalno) X_dense = X.toarray()
Štampanje TF-IDF matrice i reči karakteristika
# Štampanje TF-IDF matrice i reči karakteristika
print("TF-IDF Matrica:")
print(X_dense)
print("\nReči karakteristika:")
print(feature_names)
TF-IDF Matrica:
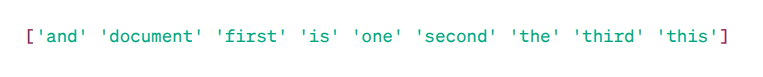
Kao što vidimo, ovi brojevi sa decimalnim zarezom pokazuju važnost reči u određenim dokumentima.
Takođe, možemo kombinovati reči u grupe od 2, 3, 4 itd. koristeći n-grame.
Postoje i drugi parametri koje možemo uključiti: min_df, max_feature, sublinear_tf itd.
Do sada smo istraživali osnovne tehnike zasnovane na frekvenciji.
Međutim, TF-IDF nije u mogućnosti da pruži semantičko značenje i kontekstualno razumevanje teksta.
U nastavku ćemo se upoznati sa naprednijim tehnikama koje su promenile svet ugrađivanja reči i koje su bolje za razumevanje semantičkog značenja i konteksta.
Word2Vec
Word2Vec je popularna tehnika ugrađivanja reči (tip vektora reči koji je koristan za hvatanje semantičkih i sintaksičkih sličnosti) u NLP-u. Razvili su je Tomas Mikolov i njegov tim u Google-u 2013. godine. Word2Vec predstavlja reči kao kontinuirane vektore u višedimenzionalnom prostoru.
Word2Vec ima za cilj da predstavi reči na način koji obuhvata njihovo semantičko značenje. Vektori reči koje generiše Word2Vec pozicionirani su u kontinuiranom vektorskom prostoru.
Na primer, vektori reči „mačka“ i „pas“ bili bi bliži jedni drugima nego vektori reči „mačka“ i „devojka“.
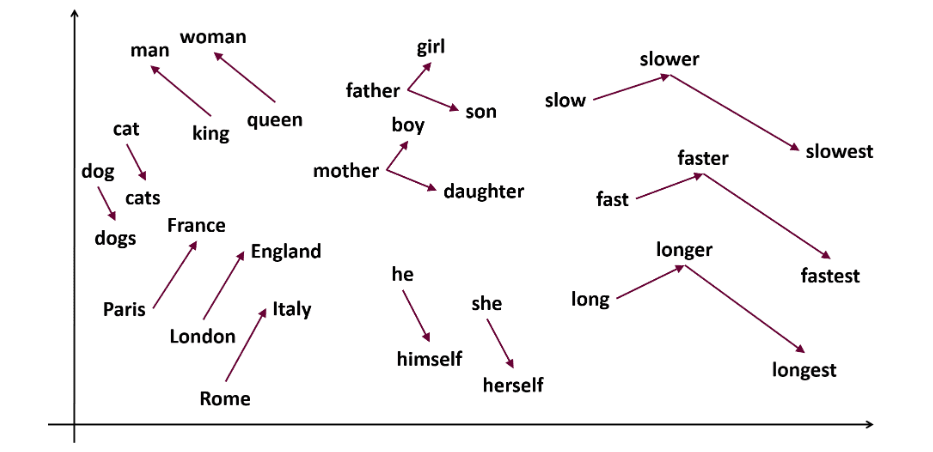
Izvor: usna.edu
Word2Vec može koristiti dve arhitekture modela za kreiranje ugrađivanja reči.
CBOW: Kontinuirana vreća reči (CBOW) pokušava da predvidi reč usrednjavanjem značenja okolnih reči. Koristi se fiksni prozor reči oko ciljne reči, zatim se reči konvertuju u numerički oblik (ugrađivanje), sve se usrednjava i koristi prosek za predviđanje ciljne reči pomoću neuronske mreže.
Primer: predviđanje reči „Lisica“.
Rečenica: „Brza braon lisica skače preko lenjeg psa.“
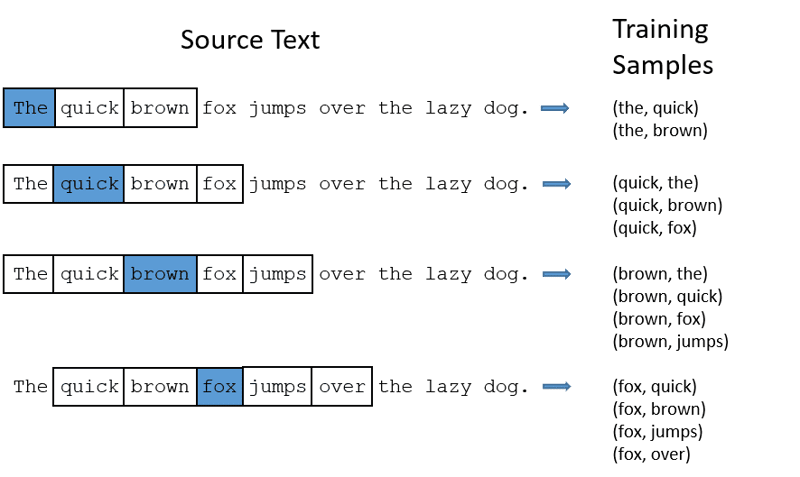
Word2Vec
- CBOW uzima prozor fiksne veličine (broj) reči, na primer, 2 (2 levo i 2 desno).
- Konvertuje se u ugrađivanje reči.
- CBOW usrednjava ugrađivanje reči.
- CBOW usredsređuje ugrađivanje reči na kontekstualne reči.
- Prosečni vektor pokušava da predvidi ciljnu reč koristeći neuronsku mrežu.
Sada razumemo kako se skip-gram razlikuje od CBOW-a.
Skip-gram: To je model ugrađivanja reči, ali funkcioniše drugačije. Umesto predviđanja ciljne reči, skip-gram predviđa kontekstualne reči na osnovu date ciljne reči.
Skip-gram je bolji u hvatanju semantičkih odnosa između reči.
Primer: Kralj – muškarac + žena = kraljica.
Ako želite da radite sa Word2Vec-om, imate dve opcije: možete obučiti sopstveni model ili koristiti već obučen model. Mi ćemo koristiti već obučen model.
Uvoz Gensim-a
Možete instalirati Gensim koristeći pip install:
pip install gensim
Tokenizacija rečenice pomoću word_tokenize:
Prvo pretvaramo rečenice u mala slova, a zatim ih tokenizujemo pomoću word_tokenize.
# Uvoz neophodnih biblioteka
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Primer rečenica
sentences = [
"Volim tora",
"Hulk je važan član Osvetnika",
"Ironman pomaže Spajdermenu",
"Spajdermen je jedan od popularnih članova Osvetnika",
]
# Tokenizacija rečenica
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Obučimo model:
Model obučavamo pružanjem tokenizovanih rečenica. Koristimo prozor od 5 za ovaj model obuke, a vi ga možete prilagoditi prema svojim zahtevima.
# Obuka Word2Vec modela
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Pronalaženje sličnih reči
similar_words = model.wv.most_similar("osvetnici")
# Štampanje sličnih reči
print("Slične reči za 'osvetnici':")
for word, score in similar_words:
print(f"{word}: {score}")
Slične reči kao „osvetnici“:

Ovo su neke od reči koje su slične reči „osvetnici“ prema Word2Vec modelu, zajedno sa njihovim ocenama sličnosti.
Model izračunava ocenu sličnosti (uglavnom kosinusnu sličnost) između vektora reči „osvetnici“ i drugih reči u rečniku. Ocena sličnosti pokazuje koliko su dve reči blisko povezane u vektorskom prostoru.
Na primer, reč „pomaže“ ima kosinusnu sličnost od -0.005911458611011982 sa reči „osvetnici“. Negativna vrednost sugeriše da se one mogu razlikovati jedna od druge.
Vrednosti kosinusne sličnosti se kreću od -1 do 1, gde je:
- 1 pokazuje da su dva vektora identična i imaju pozitivnu sličnost.
- Vrednosti blizu 1 ukazuju na visoku pozitivnu sličnost.
- Vrednosti blizu 0 ukazuju na to da vektori nisu mnogo povezani.
- Vrednosti blizu -1 ukazuju na veliku različitost.
- -1 ukazuje da su dva vektora potpuno suprotna i imaju savršenu negativnu sličnost.
Posetite ovaj link ukoliko želite bolje da razumete Word2Vec model i da vizuelno prikažete kako oni funkcionišu. To je zaista sjajan alat za gledanje CBOW i skip-gram modela u akciji.
Slično Word2Vec-u, postoji i GloVe model. GloVe može generisati ugrađivanja koja zahtevaju manje memorije u poređenju sa Word2Vec-om. Razmotrimo više o GloVe-u.
GloVe
Globalni vektori za predstavljanje reči (GloVe) su tehnika slična Word2Vec-u. Koristi se za predstavljanje reči kao vektora u kontinuiranom prostoru. Koncept koji stoji iza GloVe-a je isti kao kod Word2Vec-a: proizvodi kontekstualna ugrađivanja reči, ali u obzir uzima i superiorne performanse Word2Vec-a.
Zašto nam je potreban GloVe?
Word2Vec je metoda zasnovana na prozorima i koristi reči u okruženju za razumevanje reči. To znači da na semantičko značenje ciljne reči utiču samo okolne reči u rečenicama, što je neefikasno korišćenje statistike.
GloVe, s druge strane, beleži i globalnu i lokalnu statistiku koja dolazi sa ugrađivanjem reči.
Kada koristiti GloVe?
Koristite GloVe kada želite ugrađivanje reči koje obuhvata šire semantičke odnose i globalne asocijacije reči.
GloVe je bolji od drugih modela u zadacima prepoznavanja imenovanih entiteta, analogije reči i sličnosti reči.
Prvo moramo da instaliramo Gensim:
pip install gensim
Korak 1: Instalacija potrebnih biblioteka
# Uvoz potrebnih biblioteka import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Korak 2: Uvoz GloVe modela
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Korak 3: Preuzimanje vektorske reprezentacije reči za reč „slatka“
glove_model["cute"]
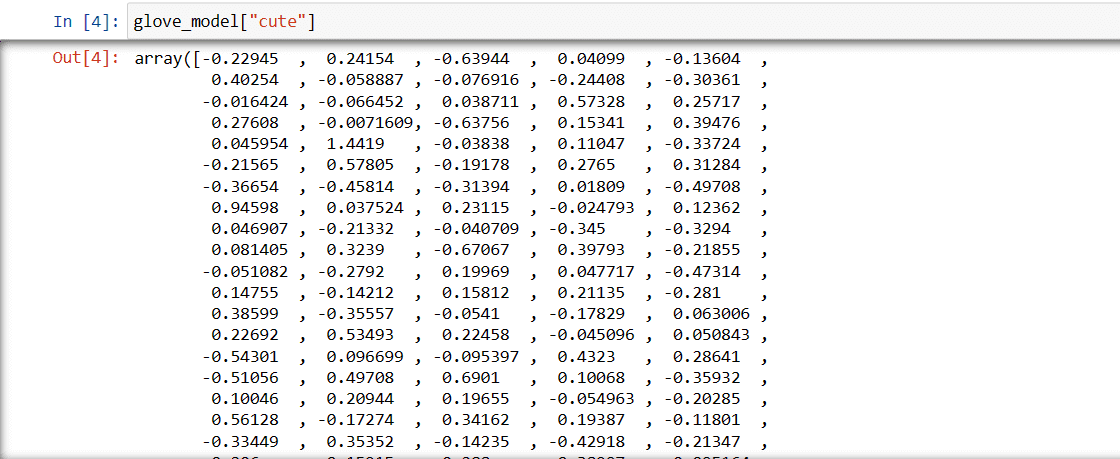
Vektor za reč „slatka“
Ove vrednosti obuhvataju značenje reči i odnose sa drugim rečima. Pozitivne vrednosti ukazuju na pozitivne asocijacije na određene pojmove, dok negativne vrednosti ukazuju na negativne asocijacije na druge koncepte.
U GloVe modelu, svaka dimenzija u vektoru reči predstavlja određeni aspekt značenja ili konteksta reči.
Negativne i pozitivne vrednosti u ovim dimenzijama doprinose tome koliko je „slatka“ semantički povezana sa drugim rečima u rečniku modela.
Vrednosti mogu biti različite za različite modele. Pronađimo neke slične reči reči „dečak“.
Top 10 sličnih reči za koje model smatra da su najsličnije reči „dečak“.
# Pronalaženje sličnih reči
glove_model.most_similar("boy")
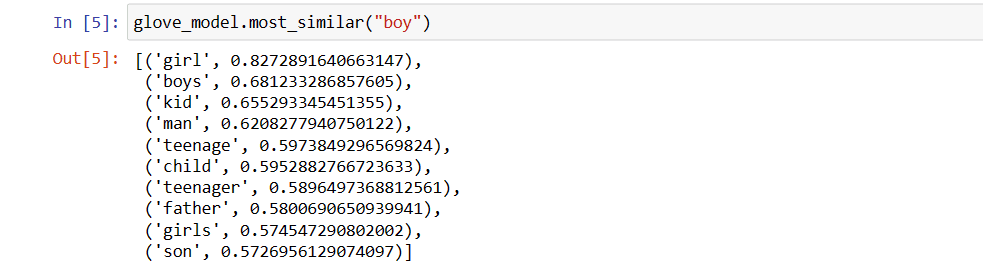
10 najboljih reči sličnih reči „dečak“
Kao što vidimo, najsličnija reč reči „dečak“ je „devojka“.
Sada ćemo pokušati da utvrdimo koliko dobro model razume semantičko značenje iz navedenih reči.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)

Najrelevantnija reč za reč „kraljica“
Naš model je u stanju da pronađe savršen odnos između reči.
Definisanje liste rečnika:
Sada pokušajmo da razumemo semantičko značenje ili odnos između reči koristeći grafički prikaz. Definišemo listu reči koje želimo da vizuelizujemo.
# Definišite listu reči koje želite da vizualizujete vocab = ["dečak", "devojka", "muškarac", "žena", "kralj", "kraljica", "banana", "jabuka", "mango", "krava", "kokos", "narandža", "mačka", "pas"]
Kreiranje matrice ugrađivanja:
Napišimo kod za