
Екстракција података је процес прикупљања специфичних података са веб страница. Корисници могу издвојити текст, слике, видео записе, рецензије, производе итд. Можете издвојити податке да бисте извршили истраживање тржишта, анализу расположења, анализу конкуренције и збирне податке.
Ако имате посла са малом количином података, податке можете извући ручно тако што ћете копирати и залепити одређене информације са веб страница у табелу или формат документа по вашем укусу. На пример, ако, као купац, тражите рецензије на мрежи које ће вам помоћи да донесете одлуку о куповини, можете ручно да одбаците податке.
С друге стране, ако имате посла са великим скуповима података, потребна вам је аутоматска техника издвајања података. Можете креирати интерно решење за екстракцију података или користити Проки АПИ или Сцрапинг АПИ за такве задатке.
Међутим, ове технике могу бити мање ефикасне јер неке од локација на које циљате могу бити заштићене цаптцха. Можда ћете такође морати да управљате ботовима и проксијима. Такви задаци вам могу одузети много времена и ограничити природу садржаја који можете издвојити.
Преглед садржаја
Сцрапинг претраживач: решење
Све ове изазове можете да превазиђете помоћу претраживача за гребање помоћу Бригхт Дата. Овај све-у-једном прегледач помаже у прикупљању података са веб локација које је тешко оборити. То је претраживач који користи графички кориснички интерфејс (ГУИ) и контролише га Пуппетеер или Плаивригхт АПИ, што га чини невидљивим за ботове.
Сцрапинг Бровсер има уграђене функције за откључавање које аутоматски управљају свим блоковима у ваше име. Прегледач се отвара на серверима компаније Бригхт Дата, што значи да вам није потребна скупа интерна инфраструктура да бисте уклонили податке за своје велике пројекте.
Карактеристике Бригхт Дата Сцрапинг Бровсер-а
- Аутоматско откључавање веб локације: Не морате стално да освежавате прегледач јер се овај прегледач аутоматски прилагођава решавању ЦАПТЦХА, новим блоковима, отисцима прстију и поновним покушајима. Сцрапинг Бровсер имитира правог корисника.
- Велика мрежа проксија: Можете циљати било коју земљу коју желите, јер Сцрапинг Бровсер има преко 72 милиона ИП адреса. Можете циљати градове или чак оператере и имати користи од најбоље технологије у класи.
- Скалабилност: Можете отворити хиљаде сесија истовремено јер овај претраживач користи Бригхт Дата инфраструктуру за руковање свим захтевима.
- Компатибилан са Пуппетеер-ом и Плаивригхт-ом: Овај прегледач вам омогућава да упућујете АПИ позиве и преузимате било који број сесија претраживача користећи Пуппетеер (Питхон) или Плаивригхт (Ноде.јс).
- Штеди време и ресурсе: Уместо постављања проксија, Сцрапинг претраживач се брине о свему у позадини. Такође не морате да постављате интерну инфраструктуру, јер овај алат брине о свему у позадини.
Како подесити претраживач за гребање
- Идите на веб локацију Бригхт Дата и кликните на претраживач за стругање на картици „Решења за стругање“.
- Направи налог. Видећете две опције; „Започните бесплатну пробну верзију“ и „Почните бесплатно са Гоогле-ом“. Хајде да за сада изаберемо „Започни бесплатну пробну верзију“ и пређимо на следећи корак. Можете да креирате налог ручно или да користите свој Гоогле налог.
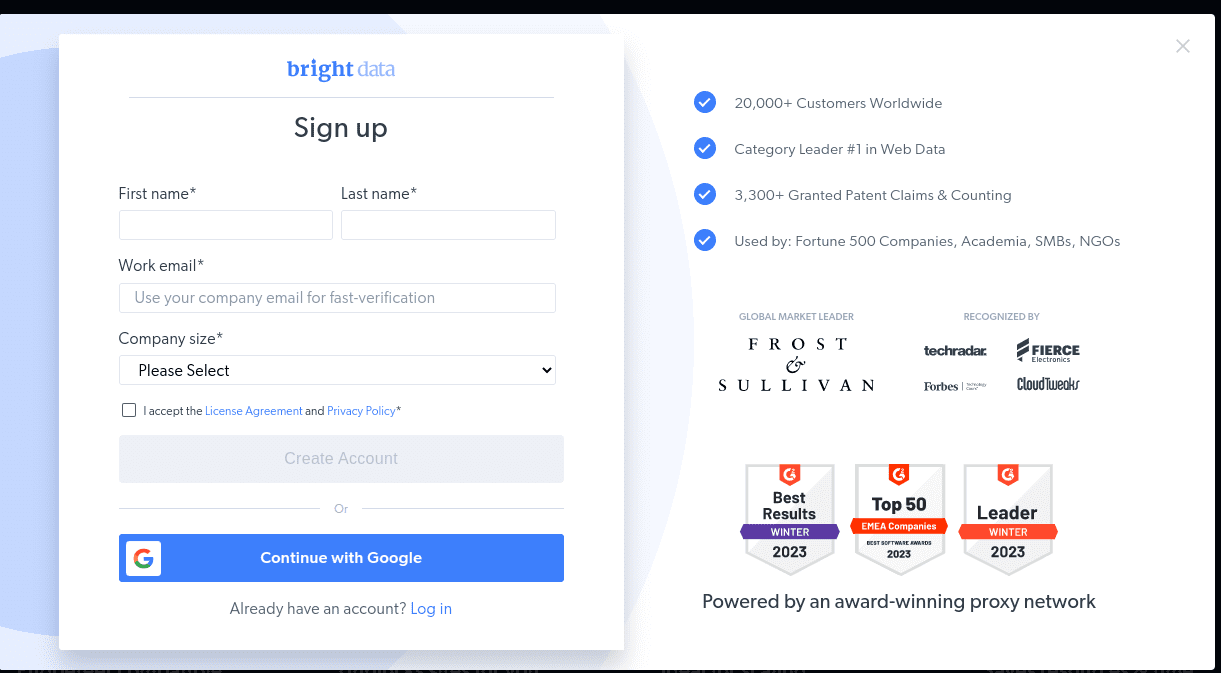
- Када се ваш налог креира, контролна табла ће представити неколико опција. Изаберите „Проксији и инфраструктура за гребање“.
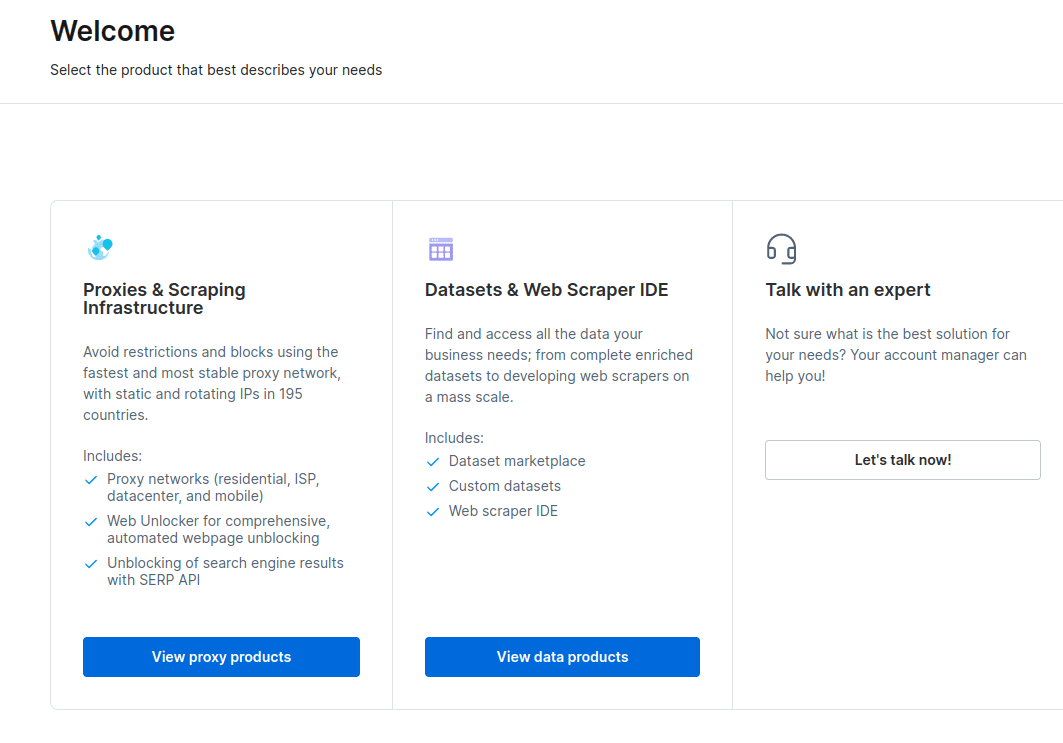
- У новом прозору који се отвори изаберите Сцрапинг Бровсер и кликните на „Започните“.
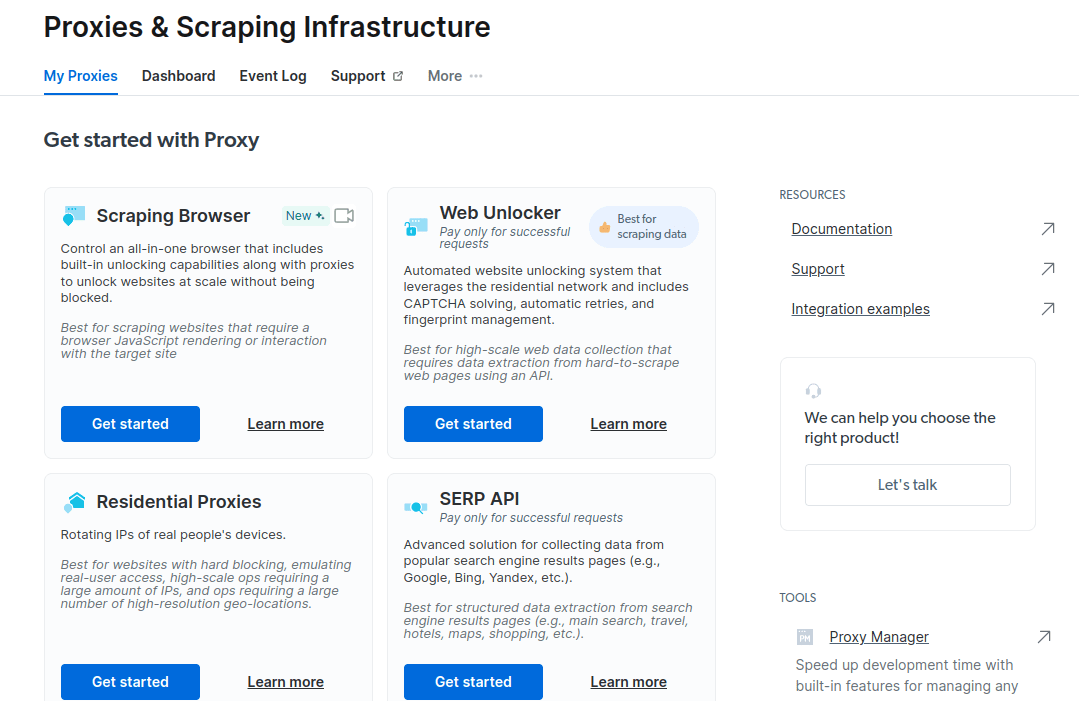
- Сачувајте и активирајте своје конфигурације.
- Активирајте своју бесплатну пробну верзију. Прва опција вам даје кредит од 5 УСД који можете користити за коришћење проксија. Кликните на прву опцију да испробате овај производ. Међутим, ако сте велики корисник, можете кликнути на другу опцију која вам даје 50 долара бесплатно ако учитате свој налог са 50 долара или више.
- Унесите своје информације за обрачун. Не брините, платформа вам неће ништа наплатити. Информације о обрачуну само потврђују да сте нови корисник и да не тражите бесплатне додатке креирањем више налога.
- Креирајте нови прокси. Када сачувате своје детаље о обрачуну, можете да креирате нови прокси. Кликните на икону „додај“ и изаберите Сцрапинг Бровсер као „Тип проксија“. Кликните на „Додај прокси” и пређите на следећи корак.
- Направите нову „зону“. Појавиће се прозор са питањем да ли желите да креирате нову зону; кликните на „Да“ и наставите.
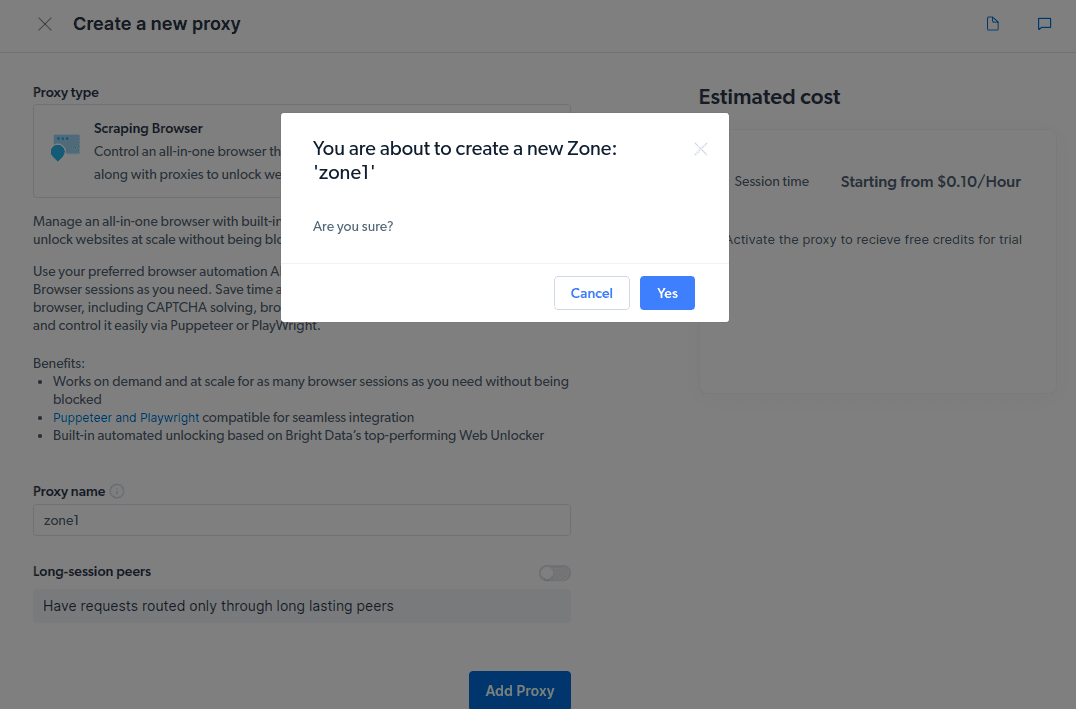
- Кликните на „Провери код и примере интеграције“. Сада ћете добити примере интеграције проксија које можете користити за уклањање података са циљане веб локације. Можете да користите Ноде.јс или Питхон да бисте издвојили податке са циљане веб локације.
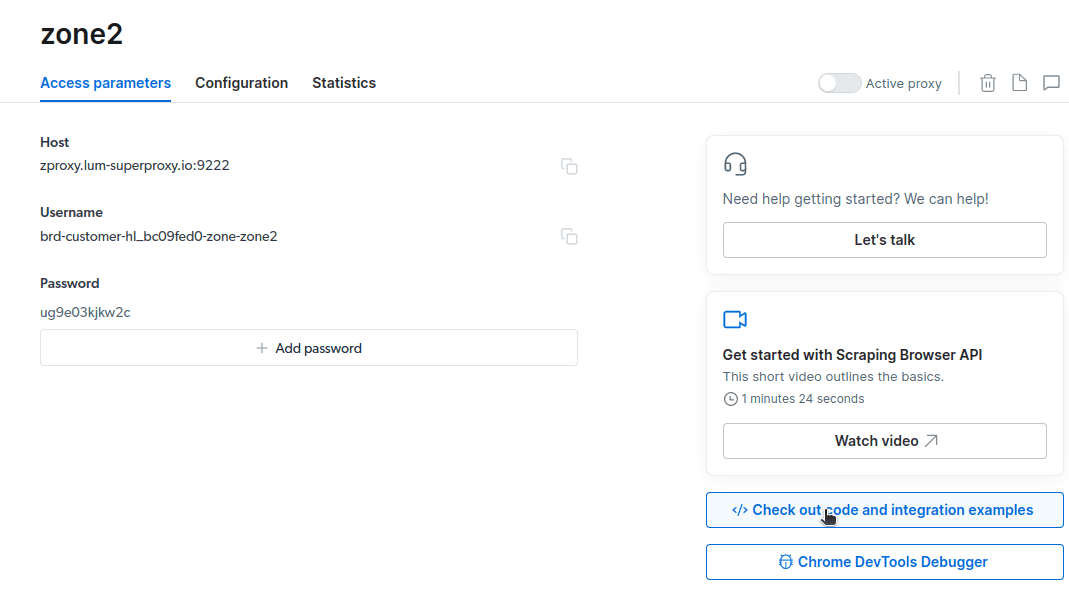
Сада имате све што вам је потребно за издвајање података са веб локације. Користићемо нашу веб страницу, вдзвдз.цом, да покажемо како ради Сцрапинг Бровсер. За ову демонстрацију користићемо ноде.јс. Можете пратити ако имате инсталиран ноде.јс.
Пратите ове кораке;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Променићу свој код у реду 10 да буде следећи;
аваит паге.гото(‘<а хреф=”хттпс://вдзвдз.цом/аутхорс/” таргет=”_бланк” рел=”ноопенер”>хттпс://вдзвдз.цом/аутхорс/‘);
Мој коначни код сада ће бити;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://techblog.co.rs.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Имаћете нешто овако на свом терминалу
Како извести податке
Можете користити неколико приступа за извоз података, у зависности од тога како намеравате да их користите. Данас можемо да извеземо податке у хтмл датотеку тако што ћемо променити скрипту да креирамо нову датотеку под називом дата.хтмл уместо да је штампамо на конзоли.
Можете променити садржај свог кода на следећи начин;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://techblog.co.rs.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Сада можете покренути код помоћу ове команде;
node script.js
Као што можете видети на следећем снимку екрана, терминал приказује поруку која каже: „Извоз података је завршен“.
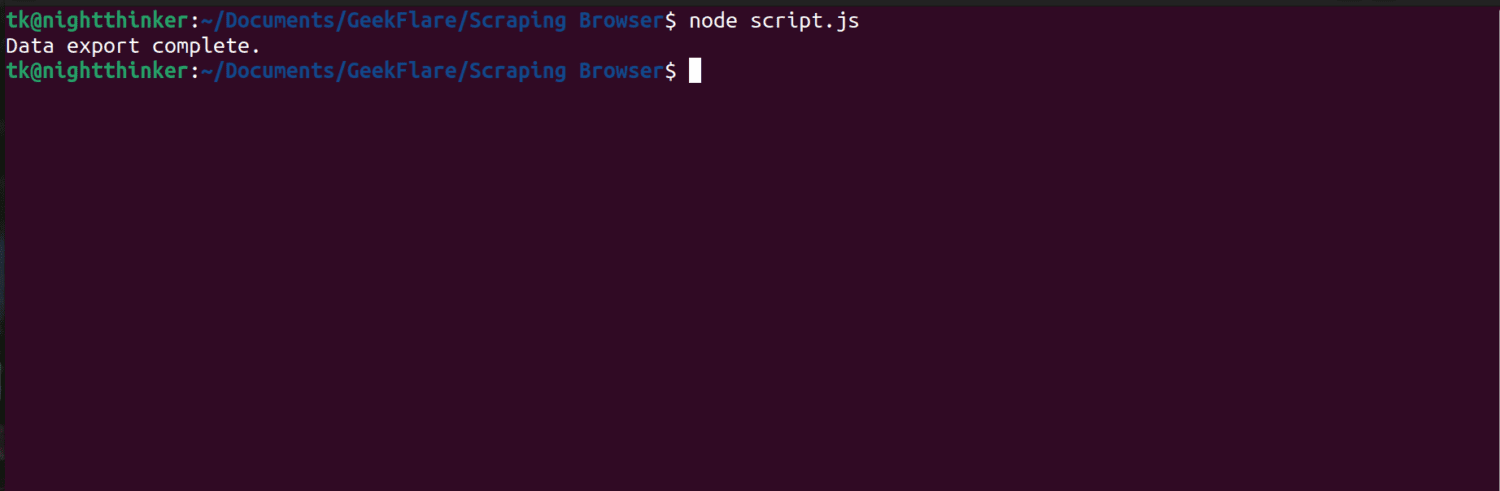
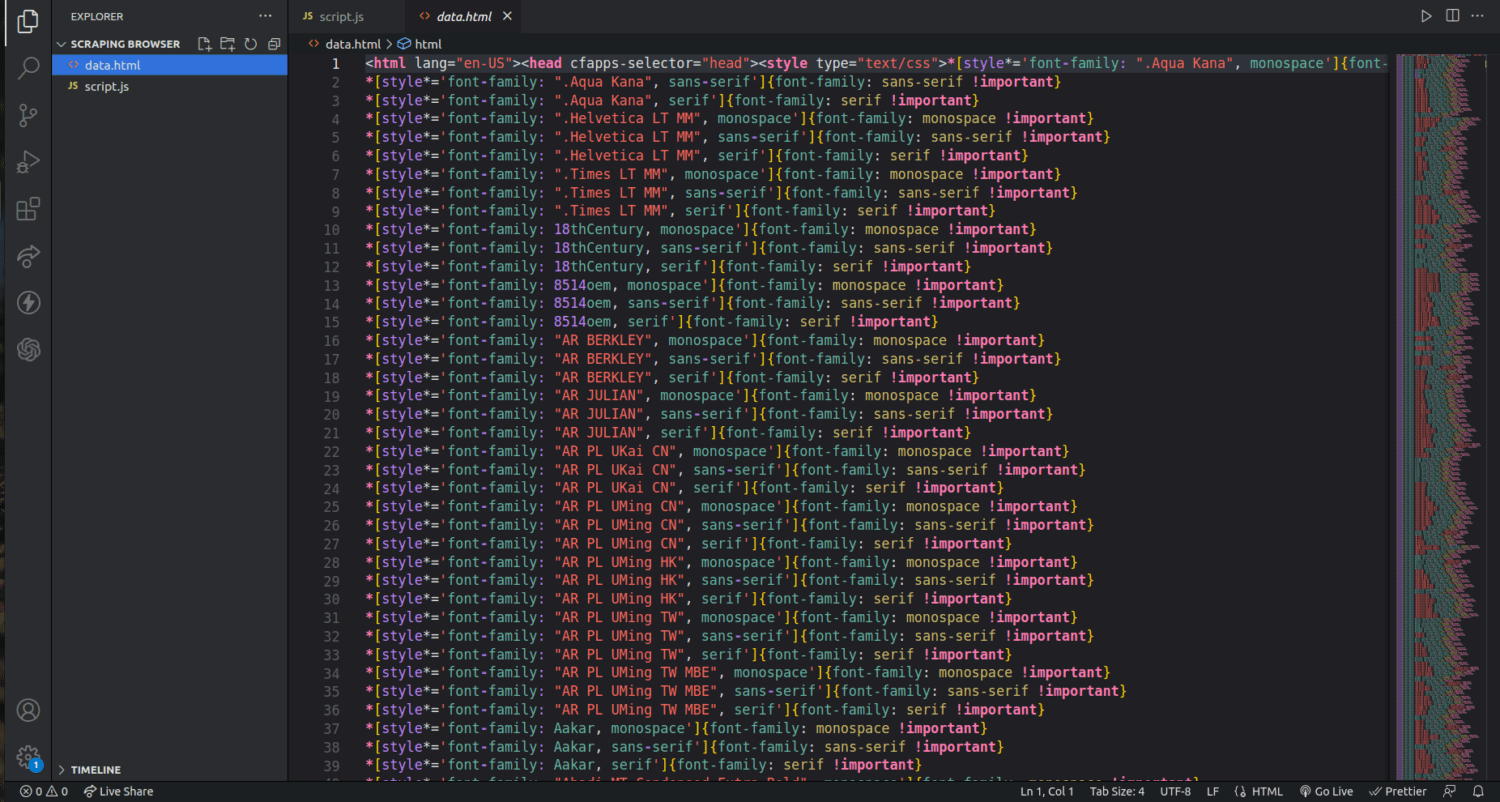
Ако проверимо фасциклу нашег пројекта, сада можемо видети датотеку под називом дата.хтмл са хиљадама линија кода.
Управо сам загребао по површини како да издвојим податке помоћу претраживача Сцрапинг. Могу чак сузити и избацити само имена аутора и њихове описе користећи овај алат.
Ако желите да користите Сцрапинг Бровсер, идентификујте скупове података које желите да издвојите и модификујте код у складу са тим. Можете издвојити текст, слике, видео записе, метаподатке и везе, у зависности од веб локације коју циљате и структуре ХТМЛ датотеке.
ФАКс
Да ли је екстракција података и веб-сцрапинг легална?
Скрапинг на вебу је контроверзна тема, при чему једна група каже да је неморално, док друге сматрају да је у реду. Законитост копирања веба зависиће од природе садржаја који се скрапа и политике циљне веб странице.
Уопштено говорећи, прикупљање података са личним подацима као што су адресе и финансијски детаљи се сматра незаконитим. Пре него што одустанете од података, проверите да ли сајт који циљате има смернице. Увек водите рачуна да не одбаците те податке који нису јавно доступни.
Да ли је Сцрапинг Бровсер бесплатна алатка?
Не. Сцрапинг Бровсер је плаћена услуга. Ако се пријавите за бесплатну пробну верзију, алатка вам даје кредит од 5 долара. Плаћени пакети почињу од 15 УСД/ГБ + 0,1 УСД/х. Такође можете да се одлучите за опцију Паи Ас Иоу Го која почиње од 20 УСД/ГБ + 0,1 УСД/х.
Која је разлика између Сцрапинг претраживача и претраживача без главе?
Сцрапинг Бровсер је брз претраживач, што значи да има графички кориснички интерфејс (ГУИ). С друге стране, претраживачи без главе немају графички интерфејс. Безглави претраживачи, као што је Селениум, користе се за аутоматизацију веб сцрапинг-а, али су понекад ограничени јер морају да се баве ЦАПТЦХА-има и откривањем ботова.
Окончање
Као што видите, Сцрапинг Бровсер поједностављује издвајање података са веб страница. Сцрапинг Бровсер је једноставан за коришћење у поређењу са алатима као што је Селениум. Чак и они који нису програмери могу да користе овај претраживач са одличним корисничким интерфејсом и добром документацијом. Алат има могућности деблокирања које нису доступне у другим алатима за уклањање, што га чини ефикасним за све који желе да аутоматизују такве процесе.
Такође можете да истражите како да спречите ЦхатГПТ додатке да скраћују садржај ваше веб локације.