
Научите све што треба да знате о истраживачкој анализи података, критичном процесу који се користи за откривање трендова и образаца и сумирање скупова података уз помоћ статистичких сажетака и графичких приказа.
Као и сваки пројекат, пројекат науке о подацима је дуг процес који захтева време, добру организацију и савесно поштовање неколико корака. Истраживачка анализа података (ЕДА) је један од најважнијих корака у овом процесу.
Стога ћемо у овом чланку укратко размотрити шта је истраживачка анализа података и како је можете извести помоћу Р!
Преглед садржаја
Шта је истраживачка анализа података?
Експлораторна анализа података испитује и проучава карактеристике скупа података пре него што се преда апликацији, било да се ради о искључиво пословном, статистичком или машинском учењу.
Овај сажетак природе информација и његових главних специфичности обично се ради визуелним методама, као што су графички прикази и табеле. Пракса се спроводи унапред управо да би се проценио потенцијал ових података, који ће у будућности бити сложенији.
ЕДА стога дозвољава:
- Формулисати хипотезе за коришћење ових информација;
- Истражите скривене детаље у структури података;
- Идентификујте вредности које недостају, одступања или абнормална понашања;
- Откријте трендове и релевантне варијабле у целини;
- Одбаците ирелевантне варијабле или варијабле које су у корелацији са другима;
- Одредите формално моделирање које ће се користити.
Која је разлика између дескриптивне и истраживачке анализе података?
Постоје две врсте анализе података, дескриптивна анализа и истраживачка анализа података, које иду руку под руку, упркос томе што имају различите циљеве.
Док се први фокусира на описивање понашања варијабли, на пример, средња вредност, медијана, мод, итд.
Истраживачка анализа има за циљ да идентификује односе између варијабли, извуче прелиминарне увиде и усмери моделовање на најчешће парадигме машинског учења: класификацију, регресију и груписање.
Заједничко, обоје се могу бавити графичким представљањем; међутим, само истраживачка анализа настоји да донесе увиде који се могу применити, односно увиде који изазивају акцију доносиоца одлуке.
Коначно, док истраживачка анализа података настоји да реши проблеме и донесе решења која ће водити кораке моделирања, дескриптивна анализа, као што јој назив имплицира, има за циљ само да произведе детаљан опис скупа података у питању.
Дескриптивна анализа Експлораторна анализа података Анализира понашање Анализира понашање и односе Пружа резиме Води до спецификације и радњи Организује податке у табеле и графиконе Организује податке у табеле и графиконе Нема значајну моћ објашњења Има значајну моћ објашњења
Неки случајеви практичне употребе ЕДА
#1. Дигитални маркетинг
Дигитални маркетинг је еволуирао од креативног процеса до процеса вођеног подацима. Маркетиншке организације користе истраживачку анализу података да би утврдиле резултате кампања или напора и да би водиле улагања потрошача и одлуке о циљању.
Демографске студије, сегментација купаца и друге технике омогућавају трговцима да користе велике количине података о куповини потрошача, анкетама и панелним подацима како би разумели и пренели стратегију маркетинга.
Аналитика веб истраживања омогућава трговцима да прикупе информације на нивоу сесије о интеракцијама на веб локацији. Гоогле аналитика је пример бесплатног и популарног алата за аналитику који трговци користе у ту сврху.
Истраживачке технике које се често користе у маркетингу укључују моделирање маркетинг микса, анализе цена и промоције, оптимизацију продаје и истраживачку анализу купаца, нпр. сегментацију.
#2. Истраживачка анализа портфеља
Уобичајена примена истраживачке анализе података је истраживачка анализа портфолија. Банка или агенција за кредитирање има збирку рачуна различите вредности и ризика.
Рачуни се могу разликовати у зависности од друштвеног статуса власника (богат, средња класа, сиромашан, итд.), географске локације, нето вредности и многих других фактора. Зајмодавац мора да уравнотежи принос на кредит са ризиком неиспуњавања обавеза за сваки зајам. Тада се поставља питање како вредновати портфолио у целини.
Зајам са најнижим ризиком може бити за веома богате људе, али постоји веома ограничен број богатих људи. С друге стране, многи сиромашни људи могу да позајмљују, али под већим ризиком.
Решење за истраживачку анализу података може комбиновати анализу временских серија са многим другим проблемима како би се одлучило када да се позајми новац овим различитим сегментима зајмопримаца или стопа позајмљивања. Камата се наплаћује члановима сегмента портфеља за покриће губитака међу члановима тог сегмента.
#3. Експлораторна анализа ризика
Предиктивни модели у банкарству се развијају како би се обезбедила сигурност у погледу оцена ризика за појединачне клијенте. Кредитни резултати су дизајнирани да предвиде делинквентно понашање појединца и нашироко се користе за процену кредитне способности сваког кандидата.
Поред тога, анализа ризика се спроводи у научном свету и индустрији осигурања. Такође се нашироко користи у финансијским институцијама као што су компаније за мрежне пролазе за плаћање за анализу да ли је трансакција оригинална или лажна.
У ту сврху користе историју трансакција клијента. Чешће се користи у куповини кредитном картицом; када дође до изненадног пораста обима клијентских трансакција, клијент добија позив за потврду да ли је он покренуо трансакцију. Такође помаже у смањењу губитака због таквих околности.
Истраживачка анализа података са Р
Прва ствар коју треба да извршите ЕДА са Р је да преузмете Р базу и Р Студио (ИДЕ), а затим инсталирате и учитате следеће пакете:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
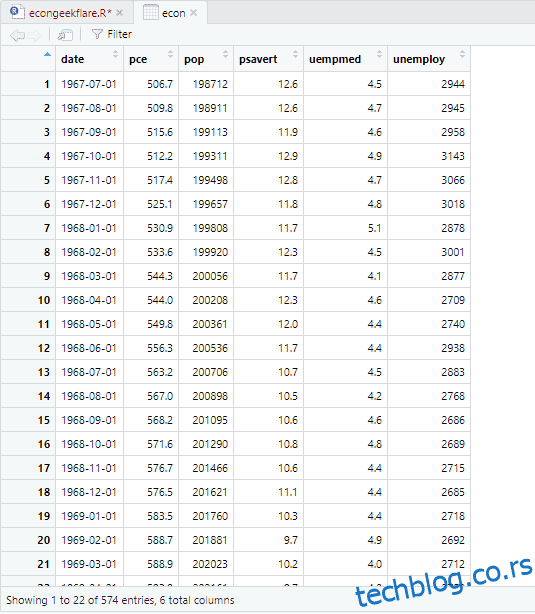
За овај водич користићемо скуп економских података који долази са Р и пружа годишње податке о економским показатељима америчке економије, и променићемо његово име у ецон ради једноставности:
econ <- ggplot2::economics
Да бисмо извршили дескриптивну анализу, користићемо пакет скимр, који израчунава ове статистике на једноставан и добро представљен начин:
#Descriptive Analysis skimr::skim(econ)

Такође можете користити функцију сажетка за дескриптивну анализу:
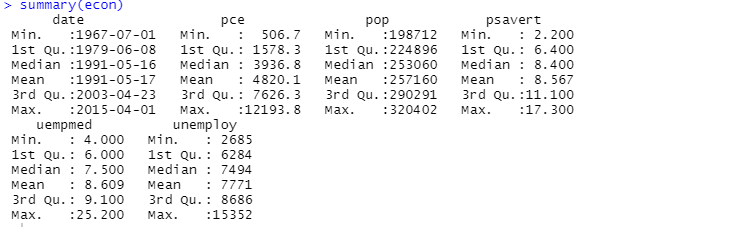
Овде дескриптивна анализа показује 547 редова и 6 колона у скупу података. Минимална вредност је за 1967-07-01, а максимална за 2015-04-01. Слично, такође показује средњу вредност и стандардну девијацију.
Сада имате основну идеју о томе шта се налази унутар ецон скупа података. Хајде да нацртамо хистограм променљиве уемпмед да боље погледамо податке:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
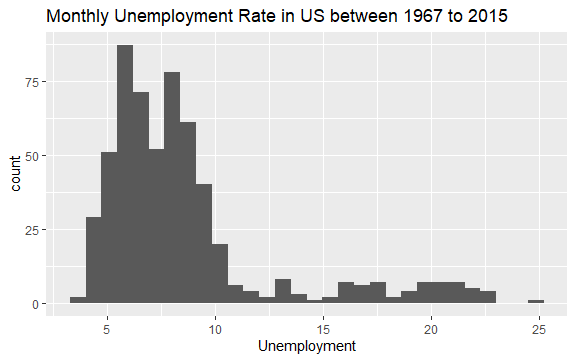
Расподела хистограма показује да има издужени реп на десној страни; то јест, могуће је да постоји неколико запажања ове променљиве са „екстремнијим“ вредностима. Поставља се питање: у ком периоду су се ове вредности одиграле и какав је тренд варијабле?
Најдиректнији начин да се идентификује тренд променљиве је преко линијског графикона. Испод генеришемо линијски графикон и додајемо линију за изравнавање:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
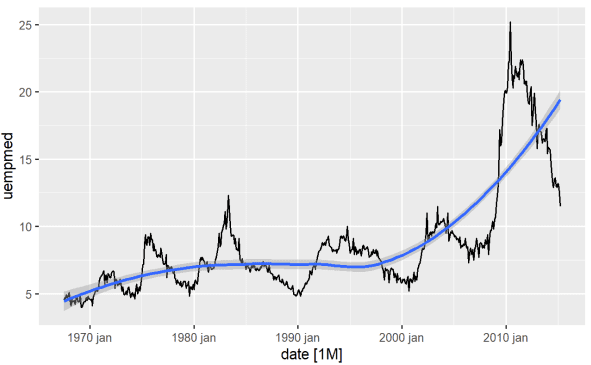
Користећи овај графикон, можемо идентификовати да у последњем периоду, у последњим посматрањима из 2010. године, постоји тенденција раста незапослености, која превазилази историју забележену претходних деценија.
Друга важна тачка, посебно у контексту економетријског моделирања, је стационарност серије; односно да ли су средња вредност и варијанса константне током времена?
Када ове претпоставке нису тачне у променљивој, кажемо да серија има јединични корен (нестационаран) тако да шокови које варијабла трпи стварају трајни ефекат.
Чини се да је то био случај са варијаблом о коме је реч, трајањем незапослености. Видели смо да су се флуктуације варијабле значајно промениле, што има снажне импликације у вези са економским теоријама које се баве циклусима. Али, одступајући од теорије, како да практично проверимо да ли је променљива стационарна?
Пакет прогнозе има одличну функцију која омогућава примену тестова, као што су АДФ, КПСС и други, који већ враћају број разлика неопходних да би серија била стационарна:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Овде п-вредност већа од 0,05 показује да подаци нису стационарни.
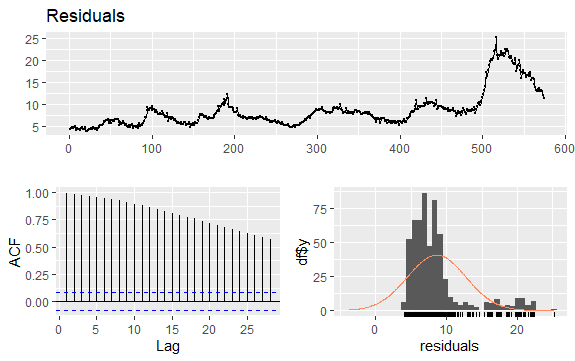
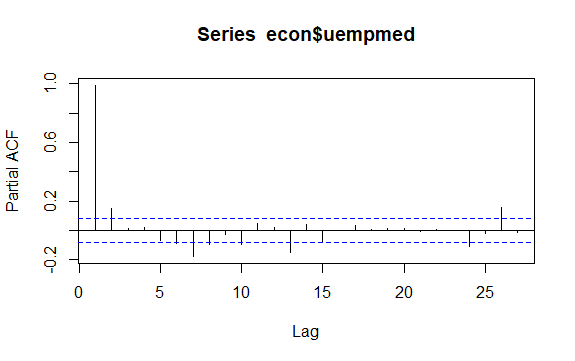
Још једно важно питање у временским серијама је идентификација могућих корелација (линеарни однос) између заосталих вредности серије. Корелограми АЦФ и ПАЦФ помажу да се то идентификује.
Како серија нема сезоналност већ има одређени тренд, почетне аутокорелације имају тенденцију да буду велике и позитивне јер су посматрања блиска у времену такође блиска по вредности.
Дакле, функција аутокорелације (АЦФ) временске серије у тренду има тенденцију да има позитивне вредности које се полако смањују како се кашњење повећава.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
Закључак
Када се дочепамо података који су мање-више чисти, односно већ очишћени, одмах смо у искушењу да заронимо у фазу изградње модела како бисмо нацртали прве резултате. Морате да се одупрете овом искушењу и почнете да радите истраживачку анализу података, која је једноставна, али нам помаже да извучемо моћне увиде у податке.
Такође можете истражити неке најбоље ресурсе за учење статистике за науку о подацима.