U današnjem digitalnom dobu, gde podaci igraju ključnu ulogu, tradicionalni načini ručnog prikupljanja informacija postali su prevaziđeni. Zahvaljujući sveprisutnosti računara i interneta, veb je postao nepresušan izvor podataka. Stoga, efikasnije i savremenije rešenje za dobijanje informacija, koje štedi vreme, jeste veb skreping. Kada je reč o veb skrepingu, Python nudi moćan alat pod nazivom Beautiful Soup. U ovom članku, vodiću vas kroz proces instalacije Beautiful Soup-a kako biste započeli sa svojim veb skreping projektima.
Pre nego što počnemo sa instalacijom i korišćenjem Beautiful Soup-a, razmotrimo zašto je ova biblioteka korisna.
Šta je Beautiful Soup?
Zamislite da istražujete temu „Uticaj COVID-a na zdravlje ljudi“ i naišli ste na brojne veb stranice sa relevantnim podacima. Međutim, šta ako te stranice ne nude mogućnost preuzimanja podataka jednim klikom? Tu na scenu stupa Beautiful Soup.
Beautiful Soup je popularna Python biblioteka koja se koristi za ekstrakciju podataka sa veb stranica. Ona olakšava preuzimanje podataka sa HTML ili XML stranica.
Leonard Richardson je 2004. godine predstavio koncept Beautiful Soup-a za veb skreping. Njegov doprinos projektu je kontinuiran, a svaku novu verziju Beautiful Soup-a ponosno objavljuje na svom Twitter nalogu.
Iako je Beautiful Soup razvijen za veb skreping pomoću Python-a 3.8, savršeno radi i sa Python-om 3 i Python-om 2.4.
Veb sajtovi često koriste captcha zaštitu kako bi zaštitili svoje podatke od AI alata. U takvim slučajevima, izmene u headeru ‘user-agent’ u Beautiful Soup-u ili korišćenje API-ja za rešavanje captcha mogu oponašati ponašanje pravog pretraživača i zavarati alatku za detekciju.
Međutim, ukoliko nemate vremena za učenje Beautiful Soup-a ili želite da skreping bude obavljen efikasno i jednostavno, vredi razmotriti API za veb skreping, gde je dovoljno da navedete URL i dobijete željene podatke.
Ako ste programer, korišćenje Beautiful Soup-a za skreping neće biti teško zbog jednostavne sintakse za navigaciju kroz veb stranice i izdvajanje željenih podataka na osnovu uslovnog raščlanjivanja. Istovremeno, pogodan je i za početnike.
Iako Beautiful Soup nije najbolji izbor za napredni skreping, idealan je za izvlačenje podataka iz datoteka napisanih u markup jezicima.
Jasna i detaljna dokumentacija je još jedna prednost Beautiful Soup-a.
Hajde da pogledamo kako lako instalirati Beautiful Soup na vašem računaru.
Kako instalirati Beautiful Soup za veb skreping?
Pip, Python menadžer paketa koji je razvijen 2008. godine, sada je standardni alat među programerima za instalaciju bilo koje Python biblioteke ili zavisnosti.
Pip je standardno uključen u instalaciju najnovijih verzija Python-a. Dakle, ako imate bilo koju noviju verziju Python-a instaliranu na svom sistemu, možete odmah početi.
Otvorite komandnu liniju i unesite sledeću pip komandu da biste odmah instalirali Beautiful Soup.
pip install beautifulsoup4
Na ekranu ćete videti nešto slično prikazu na slici ispod.
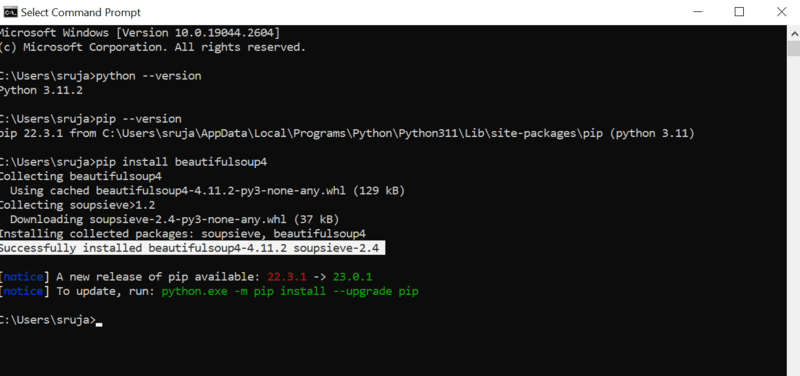
Uverite se da ste ažurirali PIP instalater na najnoviju verziju kako biste izbegli uobičajene greške.
Komanda za ažuriranje pip instalatera na najnoviju verziju je:
pip install --upgrade pip
Uspešno smo prešli pola puta u ovom članku.
Sada kada imate instaliran Beautiful Soup na svom računaru, pogledajmo kako ga koristiti za veb skreping.
Kako uvesti i raditi sa Beautiful Soup za veb skreping?
Unesite sledeću komandu u svoj Python IDE kako biste uvezli Beautiful Soup u svoju trenutnu Python skriptu.
from bs4 import BeautifulSoup
Sada je Beautiful Soup dostupan u vašoj Python datoteci i možete ga koristiti za skreping.
Pogledajmo primer koda da naučimo kako da izvučemo željene podatke pomoću Beautiful Soup-a.
Možemo reći Beautiful Soup-u da traži određene HTML tagove na izvornoj veb stranici i da izvuče podatke koji se nalaze unutar tih tagova.
U ovom delu ću koristiti marketwatch.com, koji ažurira cene akcija različitih kompanija u realnom vremenu. Hajde da izvučemo neke podatke sa ove veb stranice kako bismo se upoznali sa bibliotekom Beautiful Soup.
Uvezite paket „requests“ koji će nam omogućiti da primamo i odgovaramo na HTTP zahteve i „urllib“ za učitavanje veb stranice sa njenog URL-a.
from urllib.request import urlopen import requests
Sačuvajte vezu do veb stranice u promenljivoj kako biste joj kasnije mogli lako pristupiti.
url="https://www.marketwatch.com/investing/stock/amzn"
Sledeće bi bilo korišćenje metode „urlopen“ iz biblioteke „urllib“ za čuvanje HTML stranice u promenljivoj. Prosledite URL funkciji „urlopen“ i sačuvajte rezultat u promenljivoj.
page = urlopen(url)
Napravite objekat Beautiful Soup i analizirajte željenu veb stranicu koristeći „html.parser“.
soup_obj = BeautifulSoup(page, 'html.parser')
Sada je ceo HTML kod ciljane veb stranice sačuvan u promenljivoj ‘soup_obj’.
Pre nego što nastavimo, pogledajmo izvorni kod ciljane stranice da bismo saznali više o HTML kodu i tagovima.
Kliknite desnim tasterom miša bilo gde na veb stranici. Zatim ćete pronaći opciju pregleda, kao što je prikazano u nastavku.
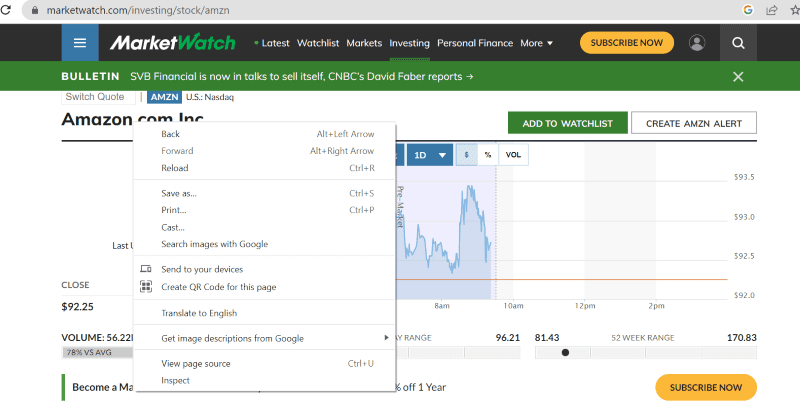
Kliknite na inspect da biste videli izvorni kod.
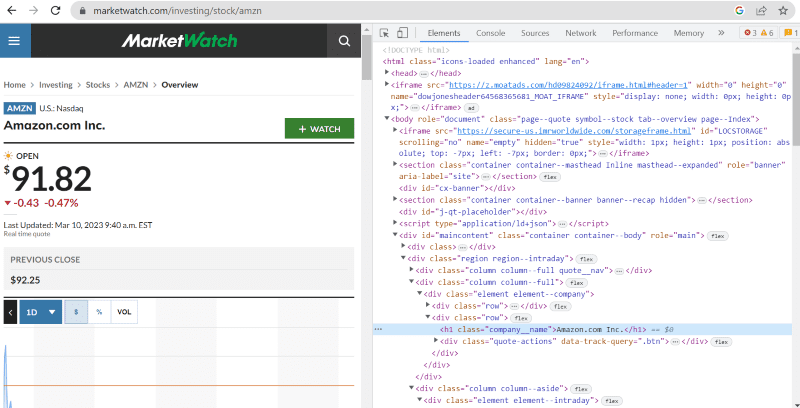
U gornjem izvornom kodu možete pronaći tagove, klase i konkretnije informacije o svakom elementu vidljivom na interfejsu veb sajta.
Metoda „find“ u Beautiful Soup-u nam omogućava da tražimo željene HTML tagove i preuzmemo podatke. Da bismo to uradili, prosleđujemo ime klase i taga metodi, koja izdvaja određene podatke.
Na primer, „Amazon.com Inc.“ prikazan na veb stranici ima naziv klase: ‘company__name’ označen pod ‘h1’. Možemo da unesemo ove informacije u metod ‘find’ da bismo izdvojili relevantni HTML isječak u promenljivu.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Hajde da ispišemo HTML kod sačuvan u promenljivoj „name“ i traženi tekst na ekranu.
print(name) print(name.text)

Možete videti ekstrahovane podatke ispisane na ekranu.
Veb skrejp IMDB veb sajt
Mnogi od nas traže ocene filmova na IMDB sajtu pre nego što pogledaju film. Ova demonstracija će vam dati listu najbolje ocenjenih filmova i pomoći vam da se naviknete na Beautiful Soup za veb skreping.
Korak 1: Uvezite Beautiful Soup i biblioteke zahteva.
from bs4 import BeautifulSoup import requests
Korak 2: Hajde da dodelimo URL adresu koju želimo da izvučemo promenljivoj koja se zove ‘url’ radi lakšeg pristupa u kodu.
Paket „requests“ se koristi za dobijanje HTML stranice sa URL-a.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Korak 3: U sledećem isečku koda, analiziraćemo HTML stranicu trenutnog URL-a da bismo napravili objekat Beautiful Soup-a.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Promenljiva „soup_obj“ sada sadrži ceo HTML kod željene veb stranice, kao na sledećoj slici.
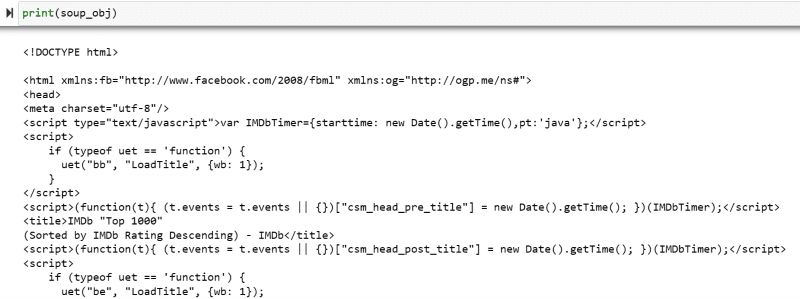
Hajde da pregledamo izvorni kod veb stranice da bismo pronašli HTML kod podataka koje želimo da skrepujemo.
Pređite kursorom preko elementa veb stranice koji želite da izdvojite. Zatim kliknite desnim tasterom miša na njega i idite na opciju pregleda da biste videli izvorni kod tog specifičnog elementa. Sledeći vizuelni prikazi će vam bolje pomoći.
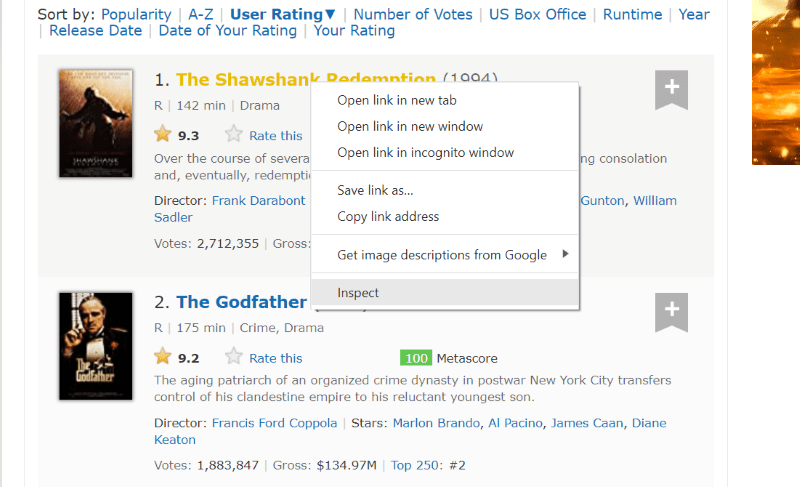
Klasa ‘lister-list’ sadrži sve najbolje ocenjene podatke u vezi sa filmovima kao pod-podele u uzastopnim div tagovima.
U HTML kodu svake filmske kartice, ispod klase „lister-item mode-advanced“, imamo tag „h3“ koji čuva naziv filma, rang i godinu izdanja, kao što je istaknuto na slici ispod.
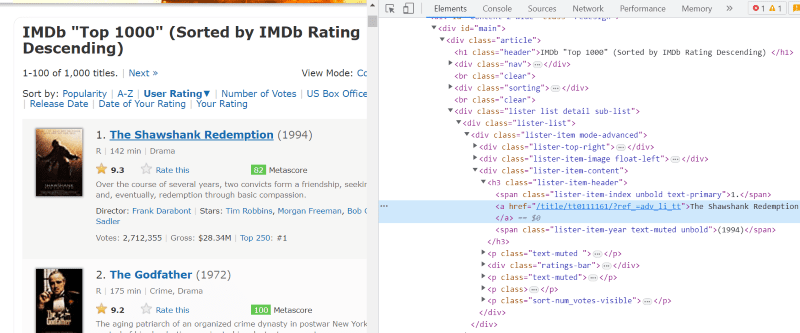
Napomena: Metoda „find“ u Beautiful Soup-u traži prvi tag koji odgovara nazivu unosa koji mu je dat. Za razliku od „find“, „find_all“ metoda traži sve tagove koji odgovaraju datom unosu.
Korak 4: Možete koristiti metode „find“ i „find_all“ da biste sačuvali HTML kod imena, ranga i godine svakog filma u promenljivoj liste.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
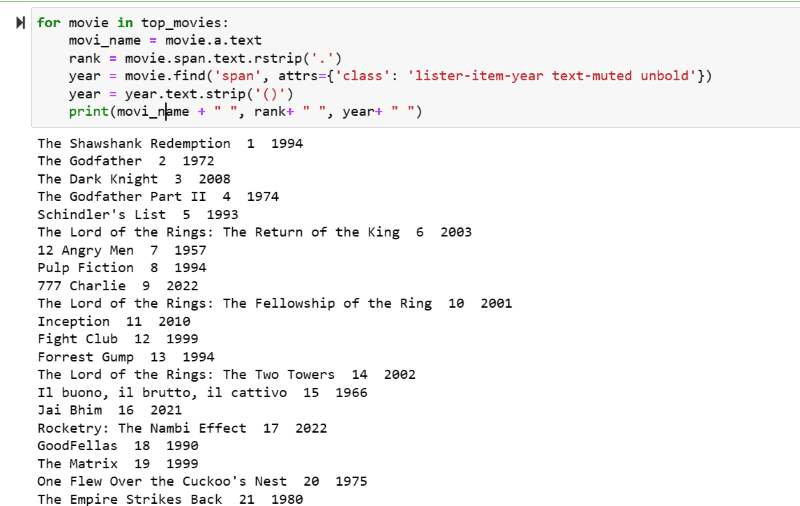
Korak 5: Prođite kroz listu filmova uskladištenih u promenljivoj: „top_movies“ i izvucite ime, rang i godinu svakog filma u tekstualnom formatu iz njegovog HTML koda koristeći kod ispod.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
Na izlaznom prikazu ekrana možete videti listu filmova sa njihovim imenom, rangom i godinom izdanja.
Možete lako da prebacite ispisane podatke u Excel tabelu uz pomoć nekog Python koda i koristite ih za svoju analizu.
Završne reči
Ovaj članak vas vodi kroz proces instalacije Beautiful Soup-a za veb skreping. Takođe, primeri skrepinga koje sam prikazao trebalo bi da vam pomognu da započnete sa Beautiful Soup-om.
S obzirom da ste zainteresovani za instalaciju Beautiful Soup-a za veb skreping, preporučujem da pogledate ovaj detaljan vodič kako biste saznali više o veb skrepingu koristeći Python.