Ovaj tekst se bavi i objašnjava neke od najkvalitetnijih Python biblioteka, koje su neophodne za data science stručnjake i timove koji se bave mašinskim učenjem.
Python se ističe kao idealan jezik za ova dva polja, prvenstveno zbog bogatstva biblioteka koje nudi.
Upravo zahvaljujući tim bibliotekama, Python omogućava efikasno obavljanje operacija kao što su unos i izlaz podataka, analiza, i druge manipulacije podacima, koje data science stručnjaci i eksperti za mašinsko učenje koriste prilikom istraživanja i obrade podataka.
Šta su to Python biblioteke?
Python biblioteka predstavlja sveobuhvatnu kolekciju ugrađenih modula, koji sadrže već kompajliran kod, uključujući klase i metode. To eliminiše potrebu da programeri kreiraju kod od početka.
Značaj Pythona u oblasti nauke o podacima i mašinskom učenju
Python je prepoznatljiv po svojim izvanrednim bibliotekama koje su neophodne stručnjacima za mašinsko učenje i nauku o podacima.
Njegova jednostavna sintaksa omogućava efikasnu implementaciju kompleksnih algoritama mašinskog učenja. Pored toga, ova jednostavnost smanjuje vreme potrebno za učenje i olakšava razumevanje.
Python takođe omogućava brzu izradu prototipova i jednostavno testiranje aplikacija.
Velika Python zajednica je izuzetno korisna za data science stručnjake, jer im omogućava da lako pronađu rešenja za svoje probleme i nedoumice.
Koliko su Python biblioteke korisne?
Python biblioteke su ključne za razvoj aplikacija i modela u okviru mašinskog učenja i nauke o podacima.
Ove biblioteke omogućavaju programerima da ponovo koriste već postojeći kod. Umesto da „ponovo izmišljate točak“, možete jednostavno uvesti odgovarajuću biblioteku koja implementira željenu funkciju u vašem programu.
Python biblioteke za mašinsko učenje i data science
Stručnjaci za nauku o podacima preporučuju različite Python biblioteke koje svaki entuzijasta treba da poznaje. U zavisnosti od svoje primene, stručnjaci za mašinsko učenje i nauku o podacima koriste različite biblioteke, a možemo ih kategorizovati kao biblioteke za primenu modela, za rudarenje i skrejpovanje podataka, za obradu podataka i za vizuelizaciju.
U ovom članku će biti predstavljene neke od najčešće korišćenih Python biblioteka u oblasti nauke o podacima i mašinskog učenja.
Pogledajmo ih sada.
NumPy
NumPy, ili Numerički Python, je biblioteka koja je napisana u C jeziku i optimizovana za visoke performanse. Data science stručnjaci je preferiraju zbog njenih mogućnosti za kompleksne matematičke i naučne proračune.
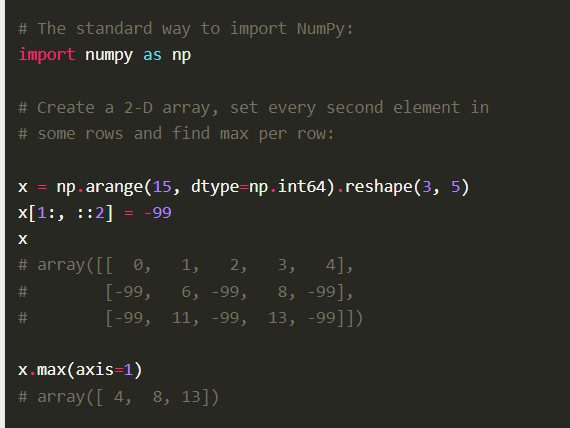
Karakteristike
- NumPy ima sintaksu visokog nivoa, koja je laka za korišćenje i za programere sa manje iskustva.
- Biblioteka je veoma brza i efikasna, zahvaljujući C jeziku u kojem je napisana i optimizovana.
- Sadrži alate za numeričke proračune, uključujući Furijeovu transformaciju, linearnu algebru i generatore slučajnih brojeva.
- Otvorenog je koda, što omogućava konstantan razvoj i doprinos drugih programera.
NumPy dolazi sa mnogim drugim karakteristikama, kao što su vektorizacija matematičkih operacija, indeksiranje i ključni koncepti u implementaciji nizova i matrica.
Pandas
Pandas je veoma popularna biblioteka u mašinskom učenju, koja omogućava rad sa strukturama podataka visokog nivoa, kao i brojne alate za efikasnu analizu velikih količina podataka. Sa samo nekoliko komandi, ova biblioteka može da obavi kompleksne operacije sa podacima.
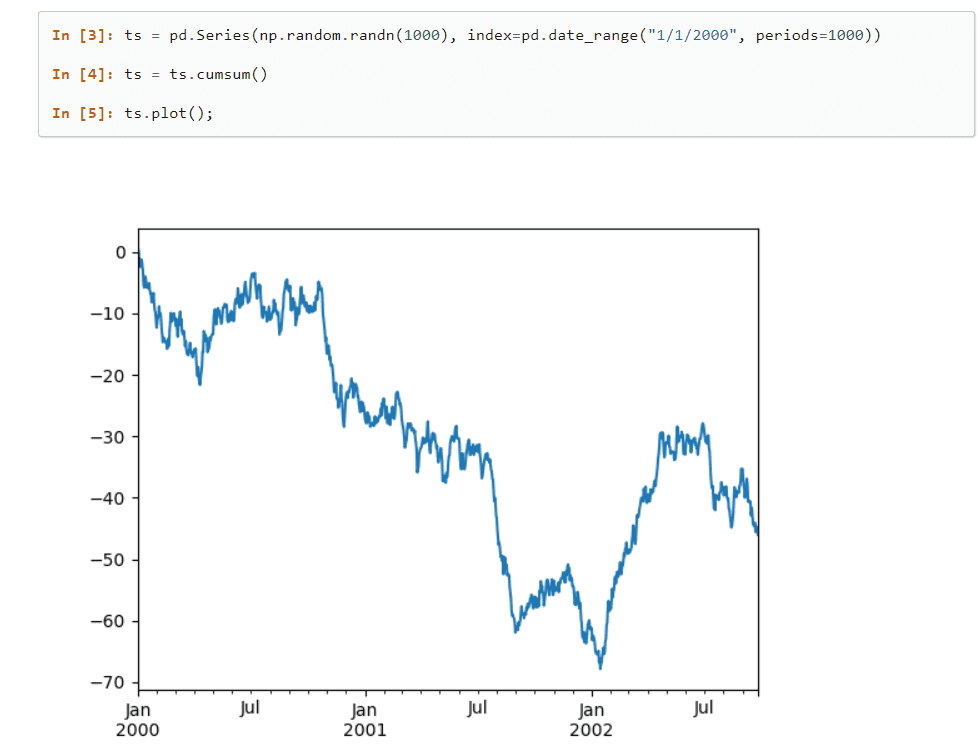
Mnoge ugrađene metode za grupisanje, indeksiranje, preuzimanje, deljenje, restrukturiranje podataka i filtriranje, pre ubacivanja u jednodimenzionalne i višedimenzionalne tabele, čine ovu biblioteku zaista posebnom.
Glavne karakteristike Pandas biblioteke
- Pandas omogućava jednostavno označavanje podataka u tabelama i automatsko poravnavanje i indeksiranje podataka.
- Može brzo učitati i sačuvati formate podataka kao što su JSON i CSV.
Veoma je efikasan zbog odlične funkcionalnosti analize podataka i velike fleksibilnosti.
Matplotlib
Matplotlib je Python biblioteka za 2D grafikone, koja jednostavno manipuliše podacima iz različitih izvora. Vizualizacije koje kreira mogu biti statične, animirane ili interaktivne, a korisnik ih može zumirati. Takođe omogućava prilagođavanje izgleda i vizuelnog stila.
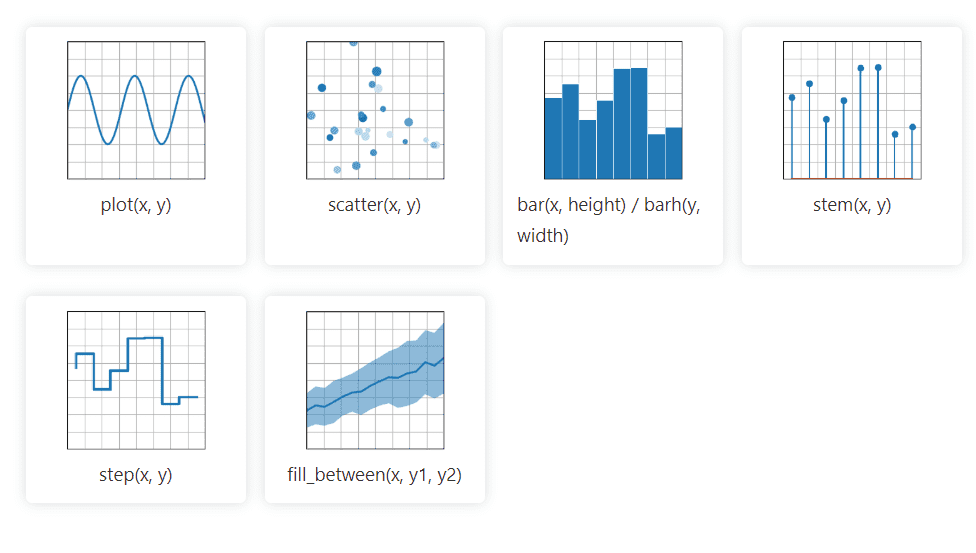
Njena dokumentacija je otvorena i nudi veliki broj alata potrebnih za implementaciju.
Matplotlib uvozi pomoćne klase za implementaciju godine, meseca, dana i nedelje, čime se olakšava manipulacija podacima vremenskih serija.
Scikit-learn
Ako vam je potrebna biblioteka za rad sa kompleksnim podacima, Scikit-learn je idealan izbor. Stručnjaci za mašinsko učenje ga često koriste. Ova biblioteka je povezana sa drugim bibliotekama, kao što su NumPy, SciPy i Matplotlib. Nudi i nadzirane i nenadzirane algoritme učenja, koji se mogu koristiti za različite aplikacije.

Karakteristike Scikit-learn biblioteke
- Identifikacija kategorija objekata, na primer, korišćenjem algoritama kao što su SVM i slučajne šume u aplikacijama za prepoznavanje slika.
- Predviđanje atributa kontinuirane vrednosti koje povezuju objekat sa zadatkom, što se naziva regresija.
- Ekstrakcija svojstava.
- Smanjenje dimenzionalnosti, odnosno smanjenje broja slučajnih varijabli.
- Grupisanje sličnih objekata u skupove.
Scikit-learn je efikasan u ekstrakciji karakteristika iz tekstualnih i slikovnih skupova podataka. Pored toga, moguće je proveriti tačnost nadziranih modela na nepoznatim podacima. Mnogi dostupni algoritmi omogućavaju rudarenje podataka i obavljanje drugih zadataka mašinskog učenja.
SciPy
SciPy (Scientific Python) je biblioteka za mašinsko učenje koja sadrži module za primenu matematičkih funkcija i algoritama. Ovi algoritmi rešavaju algebarske jednačine, interpolaciju, optimizaciju, statistiku i integraciju.
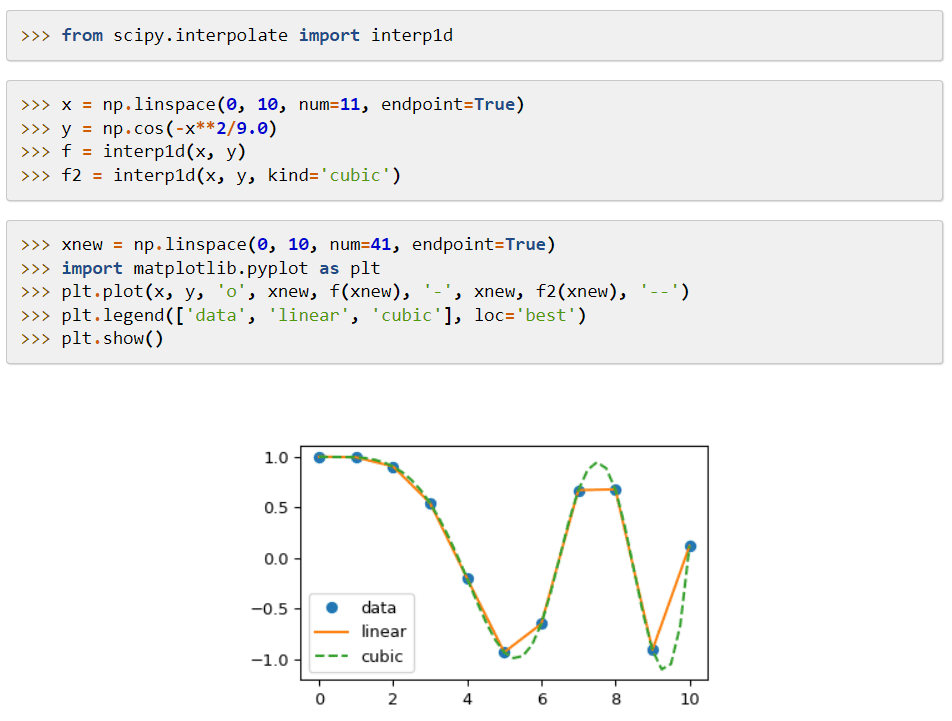
Njena glavna karakteristika je proširenje NumPy biblioteke, uz dodavanje alata za rešavanje matematičkih funkcija i obezbeđivanje struktura podataka, kao što su retke matrice.
SciPy koristi komande i klase visokog nivoa za manipulaciju i vizuelizaciju podataka. Obrada podataka i sistemi prototipova čine ga još efikasnijim alatom.
Takođe, sintaksa SciPy-ja visokog nivoa olakšava korišćenje programerima sa različitim nivoima iskustva.
Jedini nedostatak SciPy-ja je njegov fokus isključivo na numeričke objekte i algoritme, tako da ne nudi nikakvu funkciju crtanja.
PyTorch
Ova raznovrsna biblioteka za mašinsko učenje efikasno implementira tenzorske proračune sa GPU ubrzanjem, kreirajući dinamičke računarske grafikone i automatska izračunavanja gradijenata. Biblioteka Torch, razvijena u C-u, čini osnovu PyTorch biblioteke.

Ključne karakteristike uključuju:
- Podrška za razvoj i skaliranje na glavnim cloud platformama.
- Razvijen ekosistem alata i biblioteka podržava razvoj kompjuterskog vida i drugih oblasti, kao što je obrada prirodnog jezika (NLP).
- Omogućava glatku tranziciju između željenog i grafičkog režima korišćenjem Torch Script-a, dok koristi TorchServe za ubrzanje proizvodnje.
- Torch distribuirani backend omogućava distribuiranu obuku i optimizaciju performansi u istraživanju i proizvodnji.
Možete koristiti PyTorch u razvoju NLP aplikacija.
Keras
Keras je Python biblioteka otvorenog koda za mašinsko učenje, koja se koristi za eksperimentisanje sa dubokim neuronskim mrežama.
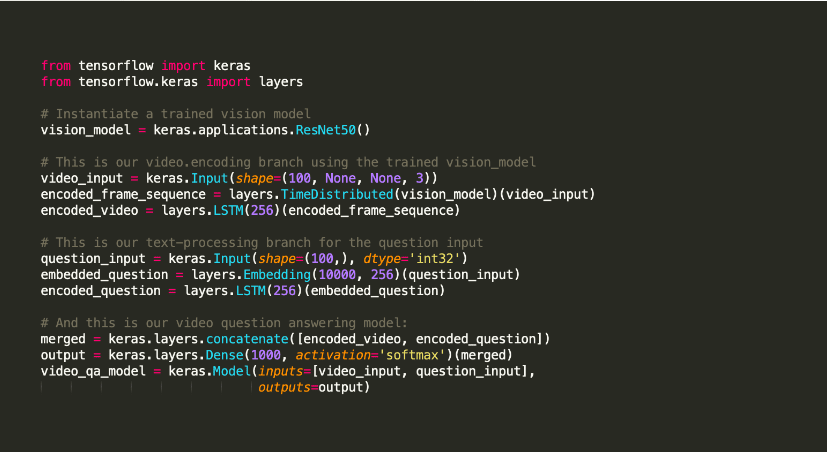
Poznat je po svojim alatima koji podržavaju zadatke kao što su kompajliranje modela i vizuelizacija grafikona. Koristi TensorFlow kao pozadinu, a alternativno, možete koristiti Theano ili neuronske mreže kao što je CNTK. Ova pozadinska infrastruktura mu pomaže da kreira računarske grafikone koji se koriste za implementaciju operacija.
Ključne karakteristike biblioteke
- Efikasno radi i na centralnom procesoru (CPU) i na grafičkom procesoru (GPU).
- Debagovanje je lakše sa Keras-om jer je zasnovan na Python-u.
- Keras je modularan, što ga čini izražajnim i prilagodljivim.
- Keras možete primeniti bilo gde, jednostavnim eksportovanjem njegovih modula u JavaScript za pokretanje u pregledaču.
Primene Kerasa uključuju blokove neuronske mreže, kao što su slojevi i ciljevi, kao i druge alate koji olakšavaju rad sa slikama i tekstualnim podacima.
Seaborn
Seaborn je još jedan koristan alat za vizualizaciju statističkih podataka.
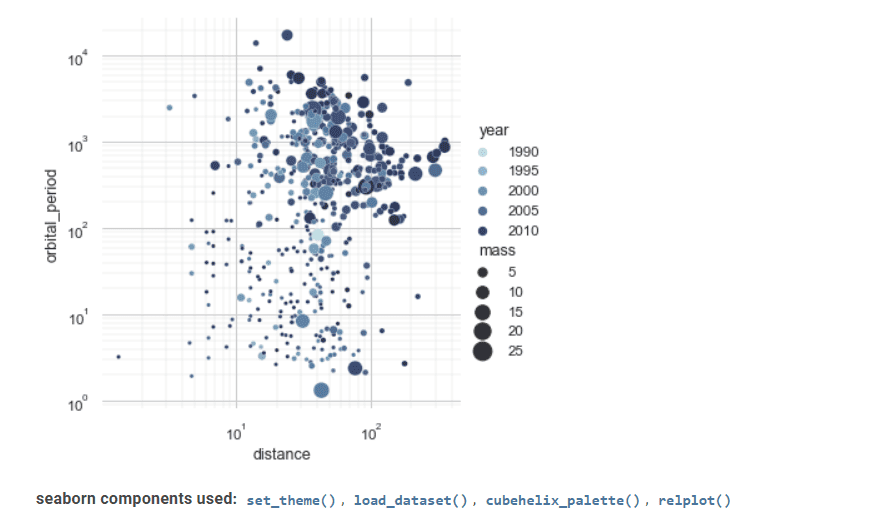
Njegov napredni interfejs omogućava izradu atraktivnih i informativnih statističkih grafika.
Plotly
Plotly je alat za 3D vizuelizaciju na vebu, zasnovan na Plotly JS biblioteci. Nudi široku podršku za različite tipove grafikona, kao što su linijski grafikoni, dijagrami raspršenosti i sparkline.
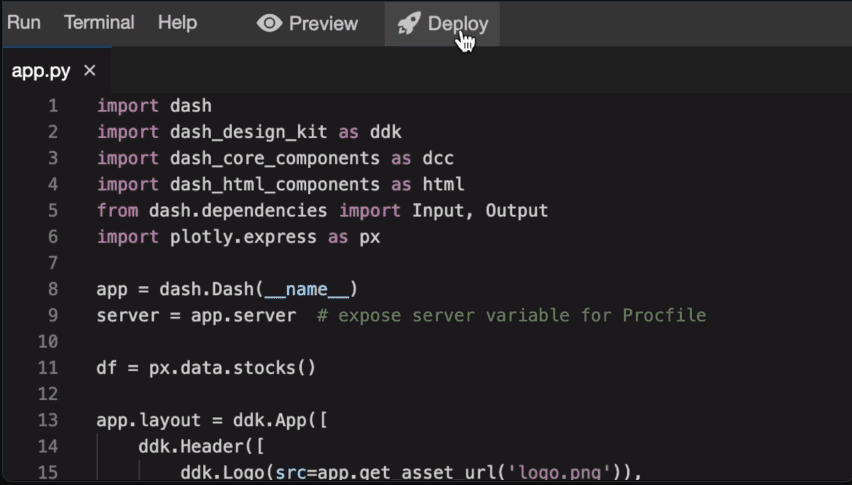
Njegova primena uključuje kreiranje vizualizacija podataka na vebu u Jupyter Notebook okruženju.
Plotly je koristan za vizualizaciju jer može da ukaže na odstupanja ili anomalije na grafikonu pomoću svog alata za lebdenje. Takođe, možete prilagoditi grafikone prema svojim željama.
Nedostatak Plotly-ja je da je njegova dokumentacija zastarela, pa je korišćenje kao vodiča može biti teško za korisnika. Pored toga, ima mnogo alata koje korisnik mora da nauči, što može biti izazovno.
Karakteristike Plotly Python biblioteke
- 3D grafikoni koji su dostupni omogućavaju više interakcija.
- Ima jednostavnu sintaksu.
- Možete da sačuvate privatnost svog koda, dok i dalje delite svoje grafikone.
SimpleITK
SimpleITK je biblioteka za analizu slika koja nudi interfejs za Insight Toolkit (ITK). Zasnovan je na C++ i otvorenog je koda.
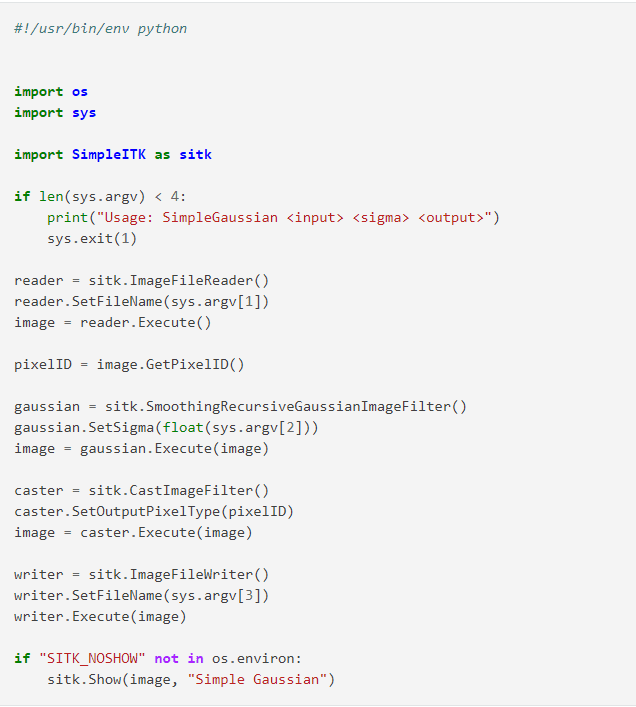
Karakteristike SimpleITK biblioteke
- Njegov I/O fajl sa slikama podržava i može da konvertuje preko 20 formata slika, kao što su JPG, PNG i DICOM.
- Sadrži mnoge filtere za segmentaciju slika, uključujući Otsu, setove nivoa i slivove.
- Tretira slike kao prostorne objekte, a ne kao niz piksela.
Njegov jednostavan interfejs je dostupan u različitim programskim jezicima, kao što su R, C#, C++, Java i Python.
Statsmodel
Statsmodel procenjuje statističke modele, sprovodi statističke testove i istražuje statističke podatke koristeći klase i funkcije.
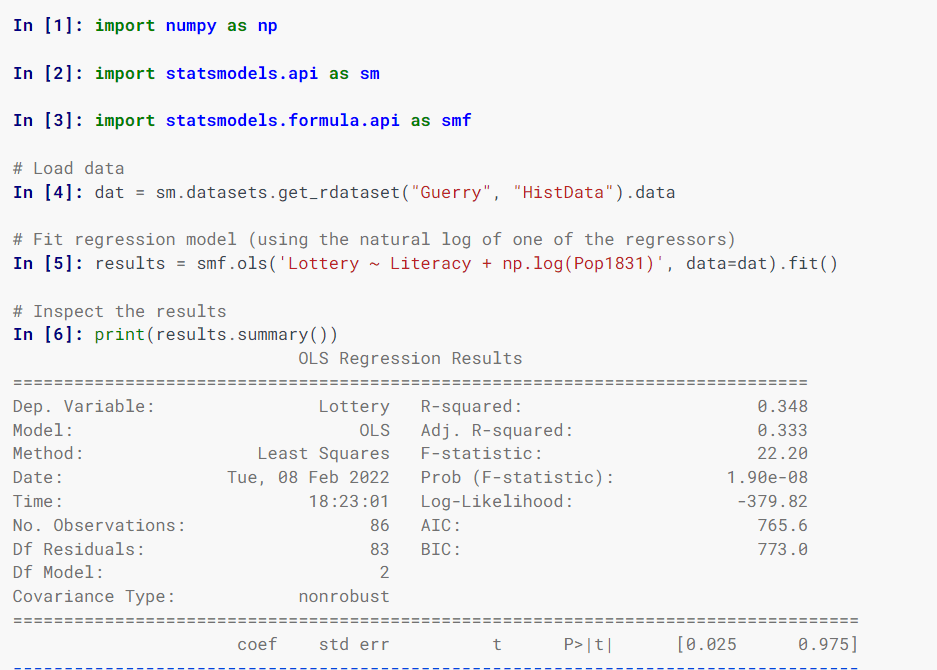
Određivanje modela koristi formule u R stilu, NumPy nizove i Pandas okvire podataka.
Scrapy
Ovaj paket otvorenog koda je preferirani alat za preuzimanje (skrejpovanje) i prikupljanje podataka sa web sajtova. Asinhron je i zbog toga relativno brz. Scrapy ima arhitekturu i karakteristike koje ga čine efikasnim.
S druge strane, njegova instalacija se razlikuje za različite operativne sisteme. Takođe, ne možete ga koristiti na web sajtovima napravljenim u JS-u. Može da radi samo sa Python 2.7 ili novijim verzijama.
Stručnjaci za nauku o podacima ga primenjuju za rudarenje podataka i automatizovano testiranje.
Karakteristike
- Može da eksportuje podatke u JSON, CSV i XML formatu i da ih skladišti na više lokacija.
- Ima ugrađenu funkcionalnost za prikupljanje i izdvajanje podataka iz HTML/XML izvora.
- Možete koristiti dobro definisan API za proširenje Scrapy-ja.
Pillow
Pillow je Python biblioteka za slike, koja manipuliše i obrađuje slike.
Dodaje funkcionalnosti za obradu slika u Python interpreter, podržava različite formate fajlova i nudi odličnu internu reprezentaciju.
Podacima koji se čuvaju u osnovnim formatima datoteka može se lako pristupiti zahvaljujući Pillow-u.
Zaključak 💃
Ovim završavamo naše istraživanje nekih od najboljih Python biblioteka za data science stručnjake i eksperte za mašinsko učenje.
Kao što ovaj članak pokazuje, Python nudi izuzetno korisne pakete za mašinsko učenje i nauku o podacima. Python ima i druge biblioteke koje se mogu koristiti u drugim oblastima.
Možda će vas zanimati i neke od najboljih beležnica za data science.
Srećno učenje!