
Дељење базе података је техника за постизање хоризонталне скалабилности у системима великих размера.
Скоро сви системи у стварном свету се састоје од сервера базе података који прима много захтева за читање и незанемарљиву количину захтева за писање. Ово може преоптеретити сервер и пореметити перформансе система.
Да би се ублажили такви утицаји и побољшале перформансе система, постоје приступи као што су репликација базе података и дељење базе података. У овом водичу ћемо прво истражити технике за побољшање перформанси система, укључујући:
- Скалирање сервера базе података
- Репликација базе података
- Хоризонтално преграђивање
Након дискусије о овим техникама, наставићемо да учимо како функционише дељење базе података и такође ћемо погледати предности и ограничења овог приступа.
Почнимо!
Преглед садржаја
Технике за побољшање перформанси система
Почнимо тако што ћемо разговарати о техникама за побољшање перформанси система када постоје уска грла због сервера базе података:
#1. Скалирање сервера базе података
Повећање инстанце сервера базе података може изгледати као једноставан приступ за побољшање перформанси система. Ово укључује повећање снаге обраде, додавање више РАМ-а и слично.
Међутим, ова техника долази са следећим ограничењем. Не можемо имати сервер са бесконачном снагом складиштења и обраде. И преко одређене границе, добијамо све мањи принос.
#2. Репликација базе података
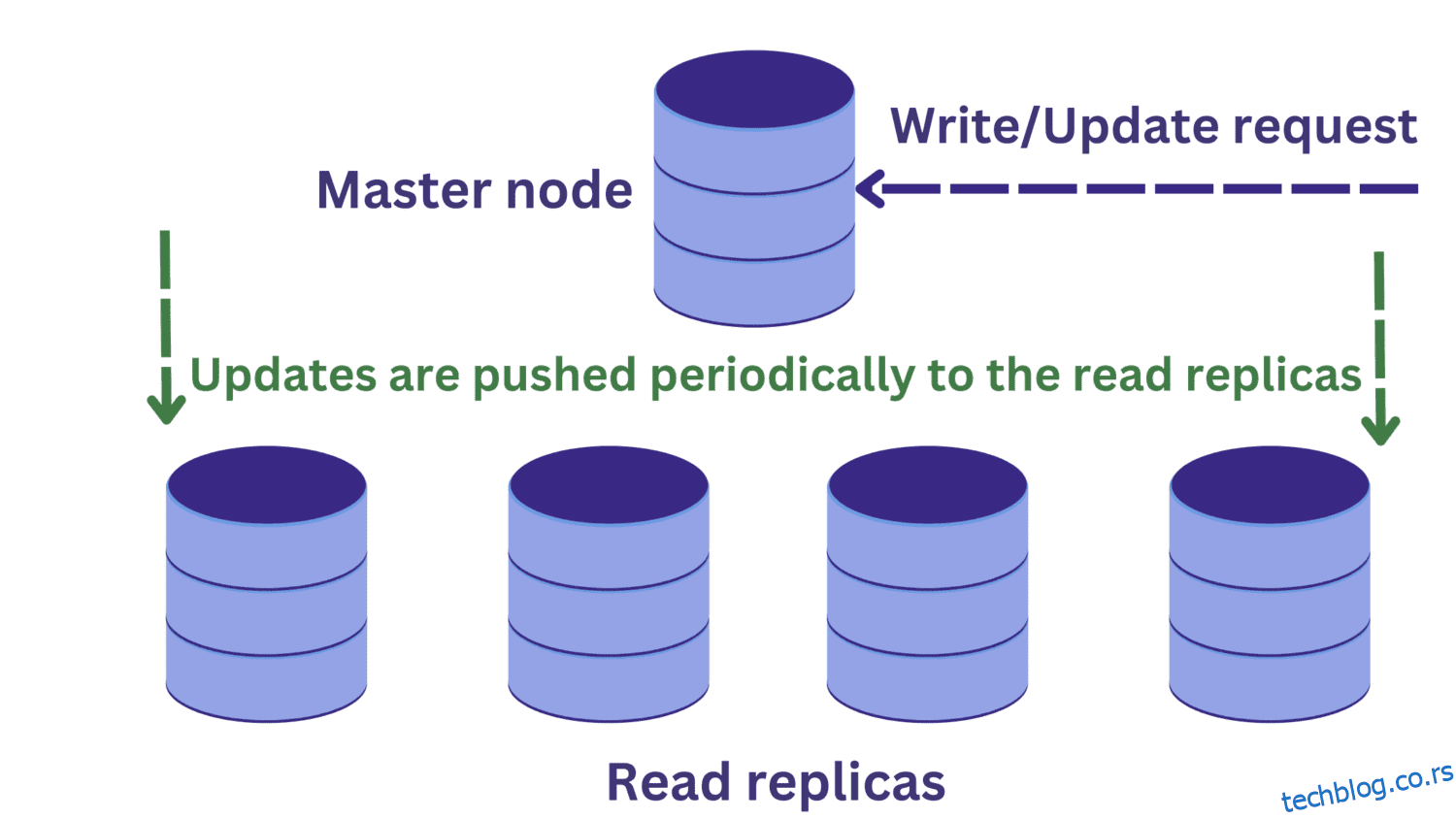
Када дође до преоптерећења инстанце сервера базе података због долазних захтева, можемо размотрити репликацију базе података.
У оквиру репликације базе података, имамо један главни чвор који обично прима захтеве за писање. Постоји више прочитаних реплика.
Ово побољшава доступност и ублажава преоптерећење система. Сада можемо паралелно да обрађујемо више упита јер се захтеви за читање могу усмерити на једну од реплика за читање.
Али ово уводи још један проблем. Захтеви за писање главном чвору могу променити податке, а ова ажурирања се периодично пропагирају на реплике читања.
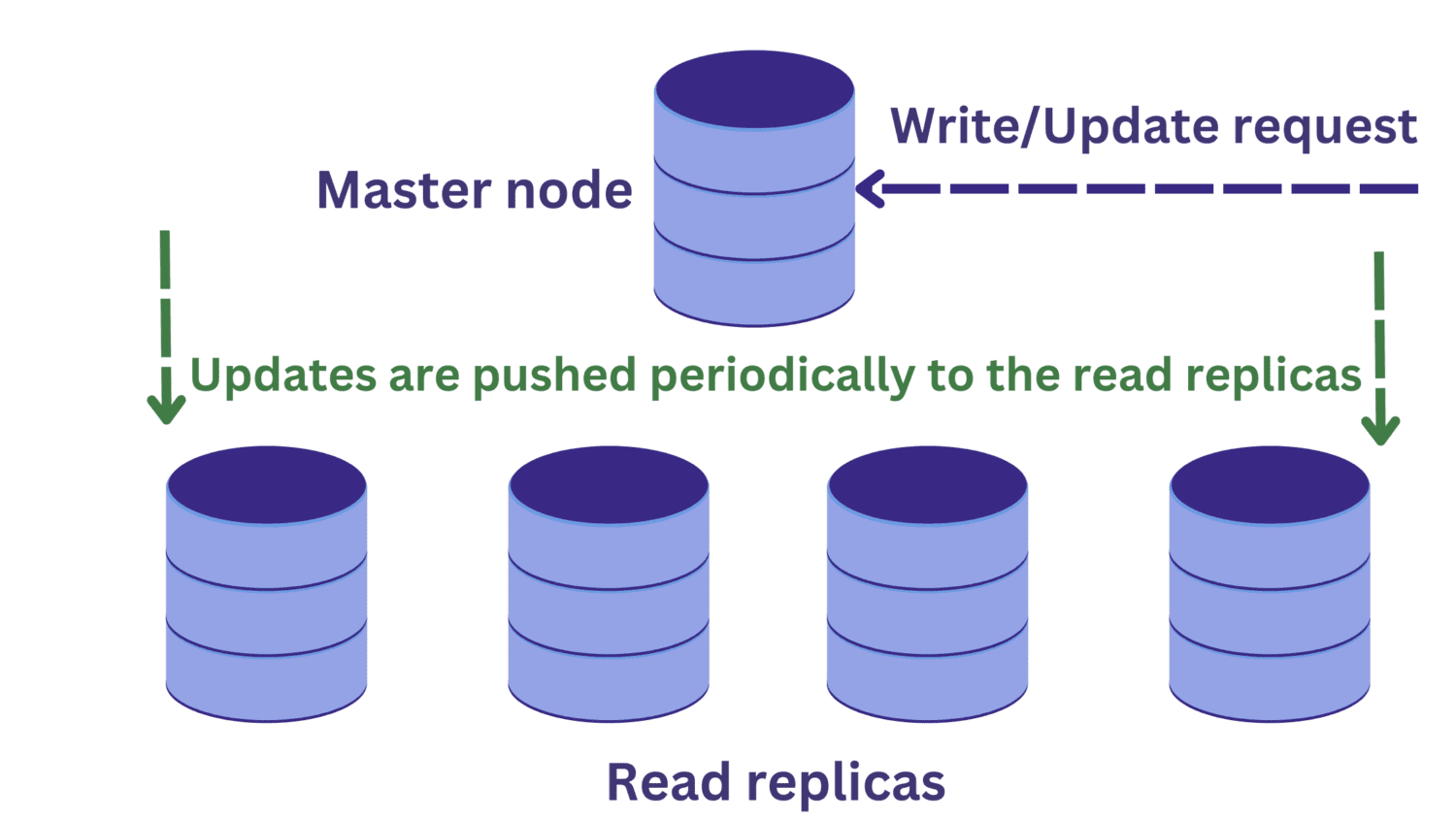
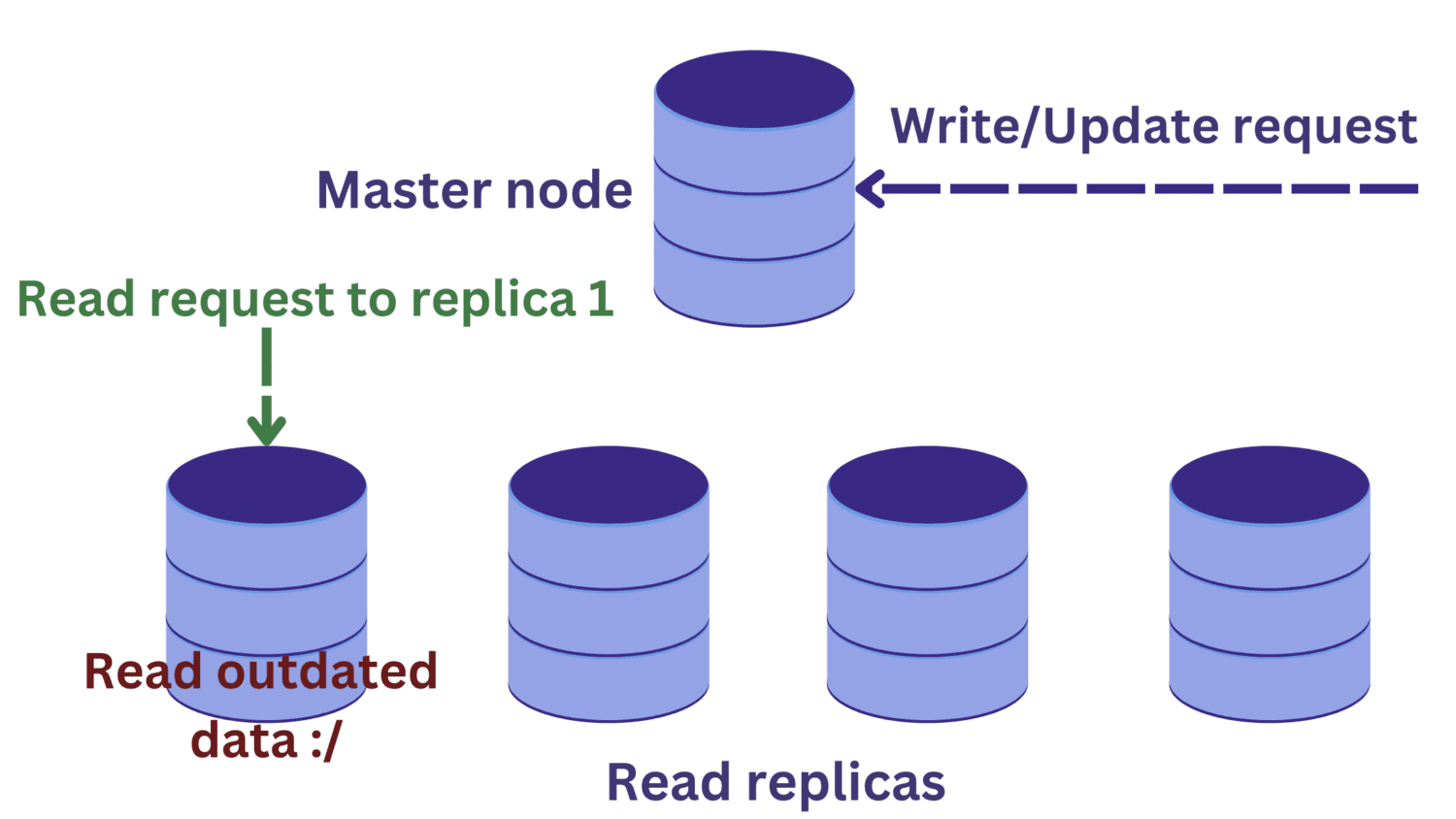
Претпоставимо да постоји захтев за читање једној од реплика читања у исто време када је операција писања у току на главном чвору.
Промене у главном чвору се још увек неће проширити на прочитане реплике. У овом случају, можда читамо застареле податке, што није пожељно.
#3. Хоризонтална партиција
Хоризонтално партиционисање је још једна техника за оптимизацију перформанси система. Можда имамо једну велику табелу са милијардама редова (као што је табела купаца и података о трансакцијама).
Операције читања из такве табеле базе података су спорије. Али коришћењем хоризонталног партиционисања, једна велика табела је сада подељена на више партиција (или мањих табела) из којих можемо да читамо. Релационе базе података као што је ПостгреСКЛ изворно подржавају партиционисање.
Међутим, све партиције су и даље унутар једне инстанце сервера базе података. Једина разлика је у томе што сада можемо да читамо са партиција уместо из једне велике табеле.
Стога, када дође до повећања броја долазних захтева, сервер можда неће моћи да подржи повећану потражњу.
Како функционише дељење базе података?
Сада када смо разговарали о приступима за побољшање перформанси система и њиховим ограничењима, хајде да разумемо како функционише дељење базе података.
У дијељењу, подијелили смо једну велику базу података на више мањих база података, од којих свака ради на инстанци сервера базе података. Свака таква мања база података назива се шард. И сваки део садржи јединствени подскуп података.
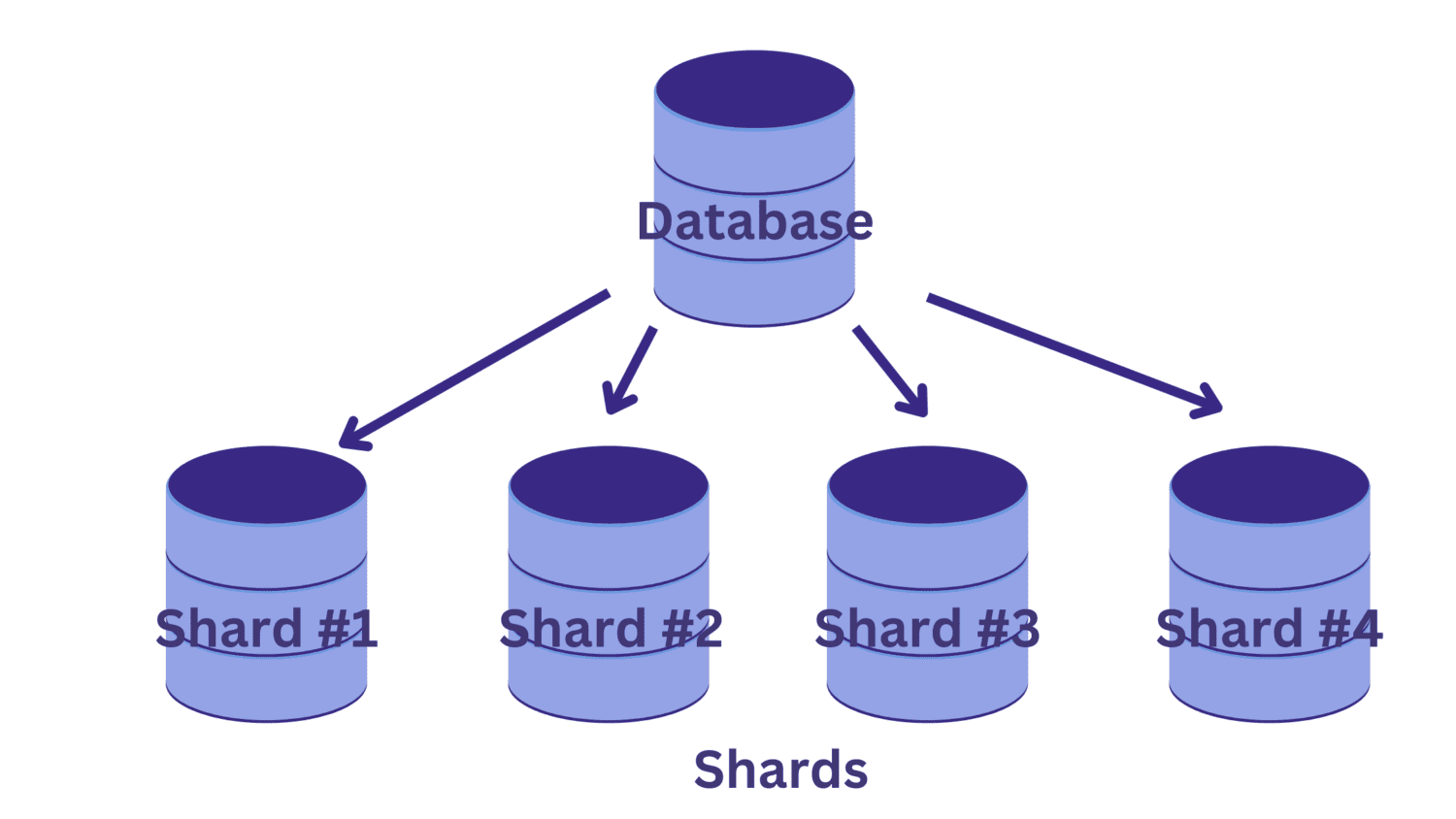
Али како да поделимо базу података на делове? И како да одредимо који од редова улази у који од крхотина?
🔑 Унесите кључ за шардирање.
Разумевање кључа за разбијање
Хајде да разумемо улогу кључа за шардирање.
Кључ за дељење, који је обично колона (или комбинација колона) у табели базе података, треба изабрати тако да дистрибуција података буде равномерна у више делова. Зато што не желимо да одређена крхотина буде много већа од осталих делова.
У бази података која чува податке о клијентима и трансакцијама, цустомер_ИД је добар кандидат за кључ за дељење.
Када се одлучимо за кључ за дељење, можемо смислити функцију хеширања која одређује који од редова улази у који од делова.
У овом примеру, рецимо да морамо да поделимо базу података на пет делова (део од 0 до део 4) користећи цустомер_ИД као кључ за шардирање. У овом случају, једноставна функција хеширања је цустомер_ИД % 5.
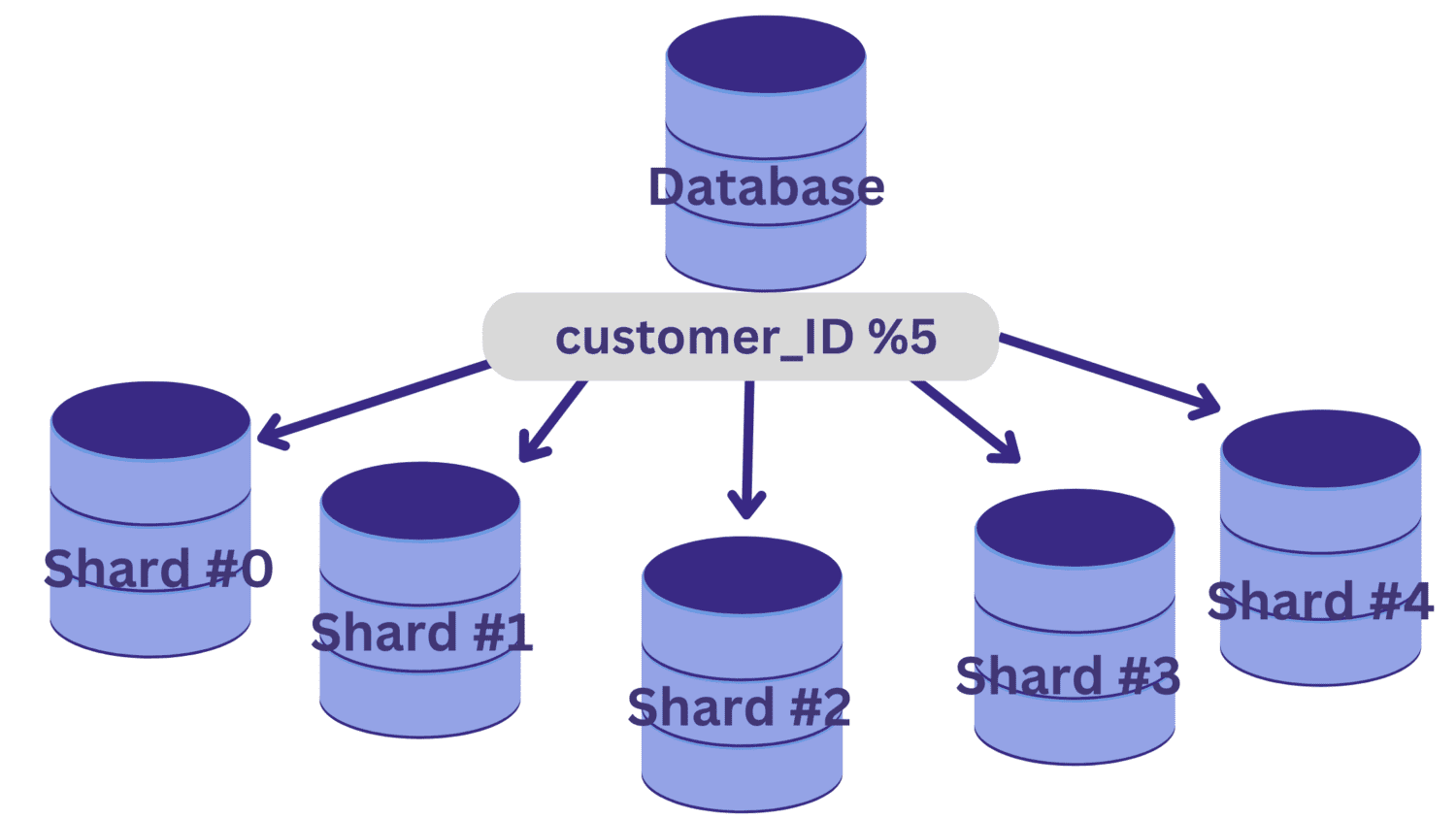
Све вредности цустомер_ИД које остављају остатак од нуле када се поделе са 5 мапираће се у део бр. 0. И вредности цустомер_ИД које остављају остатке од 1 до 4 ће се мапирати на део од 1 до деонице #4, респективно.
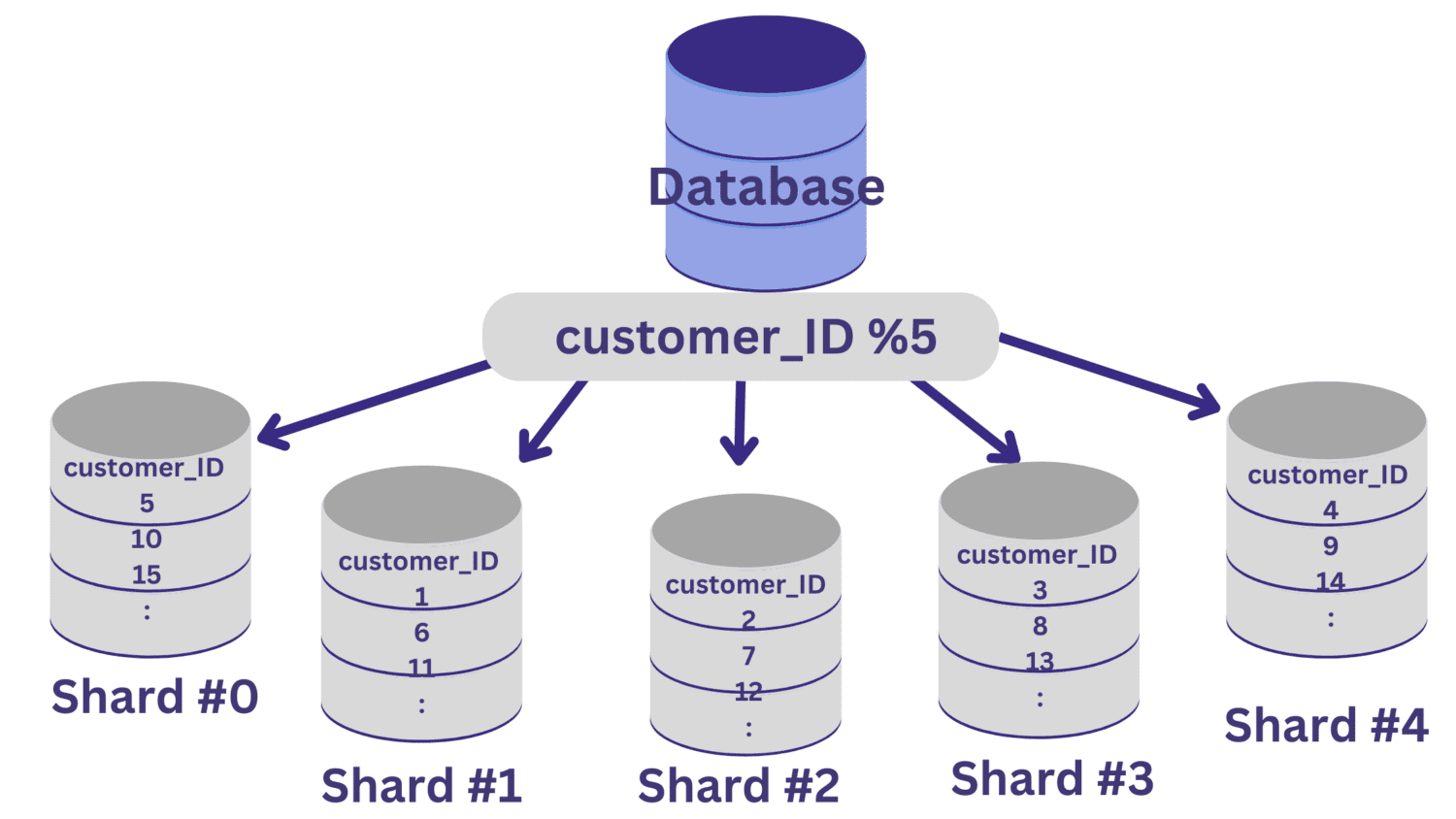
Након што се дељење базе података имплементира на овај начин, важно је да имате слој за рутирање који усмерава долазне захтеве на исправан део базе података.
Предности дељења базе података
Ево неких од предности дељења базе података:
#1. Висока скалабилност
Увек је могуће поделити већу базу података у више мањих делова. Дакле, дељење базе података нам омогућава хоризонтално скалирање.
#2. Висока доступност
Када постоји једна инстанца сервера базе података која обрађује све долазне захтеве, имамо једну тачку грешке. Ако сервер базе података не ради, цела апликација не ради.
Са дељењем базе података, вероватноћа да ће сви делови базе података бити искључени у датом тренутку је релативно мала. Због тога, ако је одређена шарда неисправна, нећемо моћи да обрадимо захтеве за читање тог шарда. Али други делови и даље могу да обрађују долазне захтеве. Ово резултира високом доступношћу и повећаном толеранцијом на грешке.
Ограничења дељења базе података
Хајде сада да пређемо на нека од ограничења дељења базе података:
#1. Сложеност
Иако шардирање има предности у смислу скалабилности и толеранције грешака, оно уноси сложеност у систем.
Од мапирања записа на партиције до имплементације слоја за рутирање за усмеравање упита до одговарајућих шардова, постоји значајна сложеност која је повезана са базама података за шарање.
#2. Ресхардинг
Још једно ограничење шардирања је потреба за поновним шардирањем.
Иако користимо функцију хеширања да бисмо добили равномерну дистрибуцију записа података, могуће је да је једна од делова много већа од других делова и да се може раније исцрпити. У овом случају, морамо да узмемо у обзир поновно рашчлањивање (или преуређивање), а то долази са значајним трошковима.
#3. Покретање сложених упита
Када треба да покренете упите за анализу који укључују спајања, морате да користите записе из више делова уместо једне базе података. Дакле, ово може бити изазов када треба да покренете превише аналитичких упита. Ово можете заобићи денормализацијом база података, али то ипак захтева одређени напор!
Закључак
Хајде да завршимо дискусију резимеом онога што смо научили.
Повећање хардвера није увек оптимално. Стога се не препоручује појачавање инстанце сервера. Такође смо прегледали технике као што су репликација базе података и хоризонтално партиционисање и њихова ограничења.
Затим смо научили како функционише дељење базе података тако што смо велику базу података поделили на мање делове којима је лако управљати. Разговарали смо о томе како кључ за шардирање треба пажљиво одабрати како би се добиле равномерне партиције и потреба за слојем за рутирање који би усмеравао долазне захтеве у исправну деоницу базе података.
Дељење базе података има предности као што су висока доступност и скалабилност. Неки од недостатака укључују сложеност подешавања шардирања и поновног шардирања када се једна или више фрагмената исцрпе.
Дакле, можете размотрити сердинг када мислите да предности надмашују сложеност коју уноси дељење. Затим погледајте поређење различитих АВС релационих база података.