Google JAX, ili Just After Execution, predstavlja okvir koji je razvio Google sa ciljem ubrzanja procesa mašinskog učenja.
Može se posmatrati kao biblioteka za Python, koja omogućava brže izvršavanje zadataka u naučnom računarstvu, transformacijama funkcija, dubokom učenju, neuronskim mrežama i drugim srodnim oblastima.
O Google JAX-u
Osnovni računarski paket u Python-u je NumPy, koji obuhvata sve funkcije poput agregacija, vektorskih operacija, linearne algebre, manipulacije n-dimenzionalnim nizovima i matricama, kao i mnoge druge napredne funkcije.
Postavlja se pitanje, da li je moguće dodatno ubrzati proračune koji se izvode pomoću NumPy-a, posebno kada je reč o obimnim skupovima podataka?
Da li postoji rešenje koje bi podjednako efikasno funkcionisalo na različitim tipovima procesora, poput GPU-a ili TPU-a, bez potrebe za izmenom koda?
Šta ako bismo imali sistem koji bi automatski i efikasnije sprovodio transformacije funkcija koje se mogu sastavljati?
Google JAX je biblioteka, ili okvir, kako ga Wikipedia definiše, koja upravo to omogućava, a možda i mnogo više. Dizajniran je da optimizuje performanse i efikasno izvršava zadatke mašinskog učenja i dubokog učenja. Google JAX nudi sledeće transformacione funkcije koje ga izdvajaju od drugih biblioteka za mašinsko učenje i doprinose naprednom naučnom računarstvu u oblasti dubokog učenja i neuronskih mreža:
- Automatska diferencijacija
- Automatska vektorizacija
- Automatska paralelizacija
- Just-in-time (JIT) kompilacija
Jedinstvene funkcije Google JAX-a
Sve transformacije koriste XLA (Accelerated Linear Algebra) za poboljšanje performansi i optimizaciju memorije. XLA je kompajler za optimizaciju specifičan za domen koji izvodi linearnu algebru i ubrzava TensorFlow modele. Korišćenje XLA na vrhu vašeg Python koda ne zahteva značajne promene u kodu!
Hajde da detaljno istražimo svaku od ovih karakteristika.
Karakteristike Google JAX-a
Google JAX sadrži ključne transformacione funkcije za poboljšanje performansi i efikasnije obavljanje zadataka dubokog učenja. Na primer, automatska diferencijacija omogućava dobijanje gradijenta funkcije i pronalaženje izvoda bilo kog reda. Slično tome, automatska paralelizacija i JIT omogućavaju paralelno izvršavanje više zadataka. Ove transformacije su od suštinskog značaja za primene u robotici, igrama, pa čak i u istraživanju.
Funkcija sastavljanja transformacije je čista funkcija koja transformiše skup podataka u drugi oblik. Nazivaju se sastavljajućim jer su samostalne (tj. ove funkcije nemaju zavisnosti od ostatka programa) i nemaju stanje (tj. isti ulaz će uvek rezultirati istim izlazom).
I(x) = T: (f(x))
U gornjoj jednačini, f(x) je originalna funkcija na koju se primenjuje transformacija. I(x) je rezultujuća funkcija nakon primene transformacije.
Na primer, ako imate funkciju pod nazivom ‘total_bill_amt’ i želite rezultat kao transformaciju funkcije, možete jednostavno koristiti željenu transformaciju, recimo gradijent (grad):
grad_total_bill = grad(ukupni_račun_amt)
Transformacijom numeričkih funkcija pomoću funkcija kao što je grad(), lako možemo dobiti njihove izvode višeg reda, koje možemo intenzivno koristiti u algoritmima za optimizaciju dubokog učenja, kao što je spuštanje gradijenta, čime algoritmi postaju brži i efikasniji. Slično tome, korišćenjem jit(), možemo kompajlirati Python programe tačno na vreme (lenjo).
#1. Automatska diferencijacija
Python koristi funkciju autograd za automatsku diferencijaciju NumPy-a i izvornog Python koda. JAX koristi modifikovanu verziju autograd (tj. grad) i kombinuje je sa XLA (Accelerated Linear Algebra) kako bi izvršio automatsku diferencijaciju i pronašao izvode bilo kog reda za GPU (Grafičke procesorske jedinice) i TPU (Tenzorske procesorske jedinice).
Kratka napomena o TPU-u, GPU-u i CPU-u: CPU ili centralna procesorska jedinica upravlja svim operacijama na računaru. GPU je dodatni procesor koji poboljšava računarsku snagu i pokreće napredne operacije. TPU je moćna jedinica specijalno razvijena za složena i teška radna opterećenja, poput veštačke inteligencije i algoritama dubokog učenja.
Na isti način kao što funkcija autograd može da se razlikuje kroz petlje, rekurzije, grane i tako dalje, JAX koristi funkciju grad() za gradijente obrnutog režima (povratno širenje). Takođe, možemo razlikovati funkciju bilo kog reda koristeći grad:
grad(grad(grad(sin θ))) (1.0)
Automatska diferencijacija višeg reda
Kao što je ranije spomenuto, grad je izuzetno koristan za pronalaženje parcijalnih izvoda funkcije. Parcijalni izvod možemo koristiti za izračunavanje gradijenta spuštanja funkcije troškova u odnosu na parametre neuronske mreže u dubokom učenju, sa ciljem minimizacije gubitaka.
Izračunavanje parcijalnog izvoda
Pretpostavimo da funkcija ima više promenljivih, x, y i z. Pronalaženje izvoda jedne promenljive, dok se ostale promenljive drže konstantnim, naziva se parcijalni izvod. Pretpostavimo da imamo funkciju,
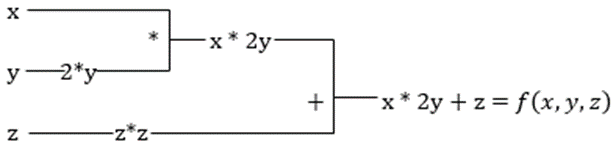
f(x,y,z) = x + 2y + z2
Primer za prikaz parcijalnog izvoda
Parcijalni izvod x će biti ∂f/∂x, što nam pokazuje kako se funkcija menja u odnosu na promenljivu kada su ostale konstantne. Ako ovo izvodimo ručno, moramo napisati program za razlikovanje, primeniti ga na svaku promenljivu, a zatim izračunati spuštanje gradijenta. Ovo bi postalo složeno i dugotrajno za više varijabli.
Automatska diferencijacija razlaže funkciju na skup elementarnih operacija, kao što su +, -, *, /, ili sin, cos, tan, exp, itd., a zatim primenjuje lančano pravilo za izračunavanje izvoda. To možemo učiniti i u naprednom i u povratnom režimu.
I to nije sve! Svi ovi proračuni se odvijaju neverovatno brzo. Zamislite samo milione kalkulacija sličnih gore navedenim i vreme koje bi to inače zahtevalo! XLA se brine o brzini i performansama.
#2. Ubrzana linearna algebra
Pogledajmo prethodnu jednačinu. Bez XLA, proračun bi se odvijao na tri (ili više) jezgara, gde bi svako jezgro obavljalo manji zadatak. Na primer:
Jezgro k1 –> x * 2y (množenje)
k2 –> x * 2y + z (sabiranje)
k3 –> Smanjenje
Ako isti zadatak obavlja XLA, jedno jezgro se brine o svim međukoracima tako što ih spaja. Srednji rezultati elementarnih operacija se strimuju umesto da se čuvaju u memoriji, čime se štedi memorija i povećava brzina.
#3. Kompilacija tačno na vreme
JAX interno koristi XLA kompajler za povećanje brzine izvršavanja. XLA može povećati brzinu CPU-a, GPU-a i TPU-a. Sve ovo je moguće korišćenjem izvršavanja JIT koda. Da bismo ovo koristili, možemo koristiti jit putem uvoza:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
Drugi način je ukrašavanje jit-a iznad definicije funkcije:
@jit def my_function(x): …………some lines of code
Ovaj kod je mnogo brži jer će transformacija vratiti prevedenu verziju koda pozivaocu umesto da koristi Python interpreter. Ovo je posebno korisno za vektorske ulaze, poput nizova i matrica.
Isto važi i za sve postojeće Python funkcije. Na primer, funkcije iz paketa NumPy. U ovom slučaju, trebalo bi da uvezemo jax.numpy kao jnp umesto NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Kada to uradite, osnovni objekat JAX niza koji se zove DeviceArray zamenjuje standardni NumPy niz. DeviceArray je lenj – vrednosti se čuvaju u akceleratoru dok ne budu potrebne. Ovo takođe znači da JAX program ne čeka da se rezultati vrate u pozivajući (Python) program, već prati asinhrono slanje.
#4. Automatska vektorizacija (vmap)
U tipičnom svetu mašinskog učenja, imamo skupove podataka sa milion ili više tačaka podataka. Najverovatnije bismo izvršili neke proračune ili manipulacije na svakoj ili većini ovih tačaka podataka – što je zadatak koji oduzima mnogo vremena i memorije! Na primer, ako želite da pronađete kvadrat svake tačke podataka u skupu podataka, prva stvar na koju biste pomislili je da napravite petlju i uzmete kvadrat jedan po jedan – argh!
Ako kreiramo ove tačke kao vektore, mogli bismo da uradimo sve kvadrate odjednom vršeći vektorske ili matrične manipulacije na tačkama podataka pomoću našeg omiljenog NumPy-a. A ako bi vaš program mogao to da uradi automatski – možete li tražiti nešto više? To je upravo ono što JAX radi! Može automatski da vektorizuje sve vaše tačke podataka tako da možete lako da izvršite sve operacije na njima – čineći vaše algoritme mnogo bržim i efikasnijim.
JAX koristi funkciju vmap za automatsku vektorizaciju. Razmotrite sledeći niz:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Kada izvršimo samo gore navedeno, kvadrat metode će se izvršiti za svaku tačku u nizu. Ali ako uradite sledeće:
vmap(jnp.square(x))
Kvadrat metode će se izvršiti samo jednom jer se tačke podataka sada automatski vektorizuju pomoću vmap metode pre izvršavanja funkcije, a petlja se gura naniže na elementarni nivo operacije – što rezultira množenjem matrice umesto skalarnog množenja, što daje bolje performanse.
#5. SPMD programiranje (pmap)
SPMD – ili jednoprogramsko programiranje više podataka, neophodno je u kontekstu dubokog učenja. Često biste primenili iste funkcije na različite skupove podataka koji se nalaze na više GPU-ova ili TPU-ova. JAX ima funkciju pod nazivom pmap, koja omogućava paralelno programiranje na više GPU-ova ili bilo kom akceleratoru. Kao i JIT, XLA će kompajlirati programe koji koriste pmap i izvršavati ih istovremeno u svim sistemima. Ova automatska paralelizacija radi i za unapred i za obrnuta izračunavanja.
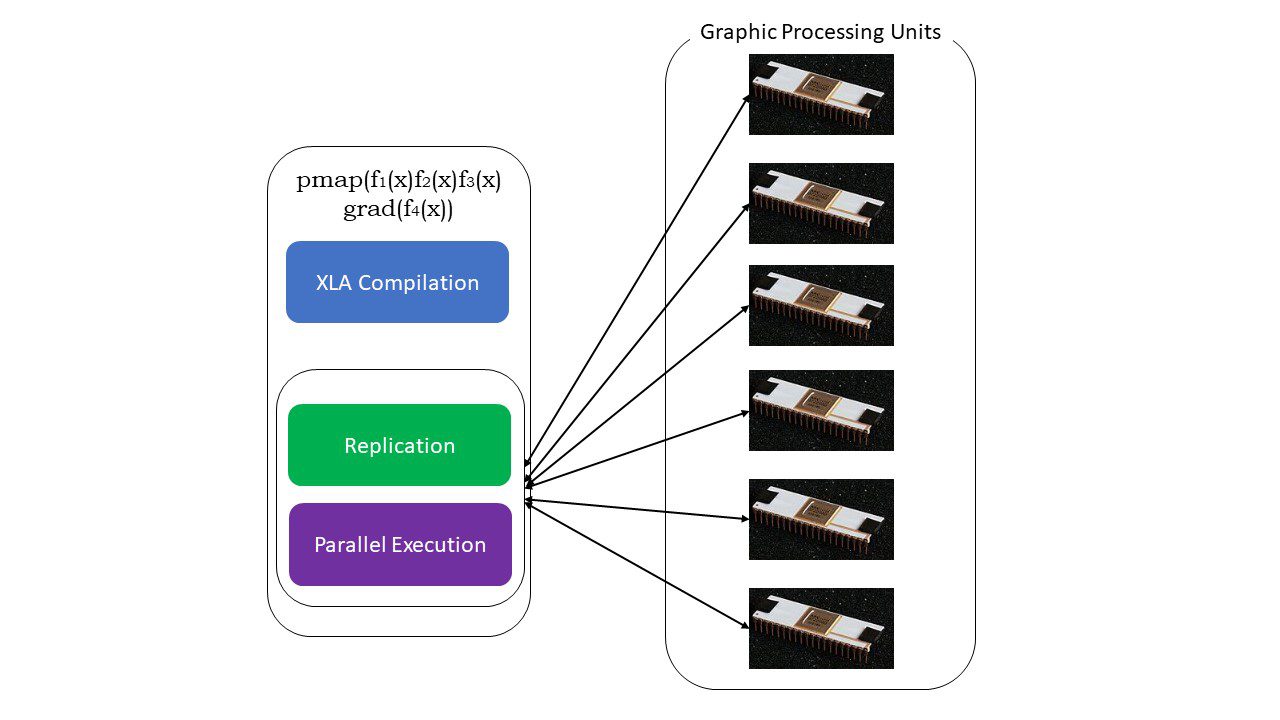 Kako funkcioniše pmap
Kako funkcioniše pmap
Takođe možemo primeniti više transformacija odjednom u bilo kom redosledu na bilo koju funkciju kao:
pmap(vmap(jit(grad (f(x)))))
Višestruke kompozitne transformacije
Ograničenja Google JAX-a
Programeri Google JAX-a su pažljivo razmotrili ubrzanje algoritama dubokog učenja prilikom uvođenja svih ovih sjajnih transformacija. Funkcije i paketi naučnog računarstva su u skladu sa NumPy-om, tako da ne morate brinuti o krivoj učenja. Međutim, JAX ima sledeća ograničenja:
- Google JAX je još u ranim fazama razvoja, i iako je njegova primarna svrha optimizacija performansi, ne pruža mnogo koristi za CPU računarstvo. Čini se da NumPy radi bolje, a korišćenje JAX-a može samo povećati troškove.
- JAX je još uvek u fazi istraživanja ili ranoj fazi i potrebno mu je više finog podešavanja da bi dostigao infrastrukturne standarde okvira kao što je TensorFlow, koji su više uspostavljeni i imaju više unapred definisanih modela, projekata otvorenog koda i materijala za učenje.
- Za sada, JAX ne podržava Windows operativni sistem – potrebna vam je virtuelna mašina da bi funkcionisao.
- JAX radi samo na čistim funkcijama – onima koje nemaju nikakve nuspojave. Za funkcije sa neželjenim efektima, JAX možda nije dobra opcija.
Kako da instalirate JAX u vašem Python okruženju
Ako imate Python podešavanje na vašem sistemu i želite da pokrenete JAX na vašoj lokalnoj mašini (CPU), koristite sledeće komande:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Ako želite da pokrenete Google JAX na GPU ili TPU, pratite uputstva data na GitHub JAX stranici. Da biste podesili Python, posetite python zvanična preuzimanja stranicu.
Zaključak
Google JAX je odličan za pisanje efikasnih algoritama dubokog učenja, robotike i istraživanja. Uprkos ograničenjima, intenzivno se koristi sa drugim okvirima kao što su Haiku, Flax i mnogi drugi. Moći ćete da cenite šta JAX radi kada pokrenete programe i vidite vremenske razlike u izvršavanju koda sa i bez JAX-a. Možete početi čitanjem zvanične Google JAX dokumentacije, koja je prilično sveobuhvatna.