Matrica konfuzije predstavlja ključni alat za evaluaciju performansi algoritama mašinskog učenja koji se koriste za klasifikaciju podataka.
Šta je matrica konfuzije?
Ljudska percepcija je subjektivna; čak i kada je reč o istini ili laži, svako od nas može imati različito mišljenje. Ono što se meni čini kao linija duga 10 cm, vama može delovati kao da je 9 cm. Stvarna dužina može biti 9, 10, ili čak i nešto sasvim drugo. Ono što mi pretpostavljamo naziva se predviđena vrednost!
Kako ljudski mozak razmišlja
Baš kao što naš mozak koristi sopstvenu logiku prilikom predviđanja, tako i mašine primenjuju različite algoritme (poznate kao algoritmi mašinskog učenja) da bi došle do predviđene vrednosti za određeni problem. Te vrednosti mogu biti identične ili različite od stvarne vrednosti.
U konkurentnom svetu, ključno je znati da li su naša predviđanja tačna kako bismo razumeli sopstveni učinak. Na sličan način, performanse algoritma mašinskog učenja možemo oceniti na osnovu toga koliko je tačnih predviđanja napravio.
Šta je zapravo algoritam mašinskog učenja?
Mašine pokušavaju da dođu do rešenja određenog problema primenom određene logike ili skupa instrukcija, koji se nazivaju algoritmi mašinskog učenja. Algoritmi mašinskog učenja se dele na tri osnovna tipa: nadgledani, nenadgledani i potkrepljujući.
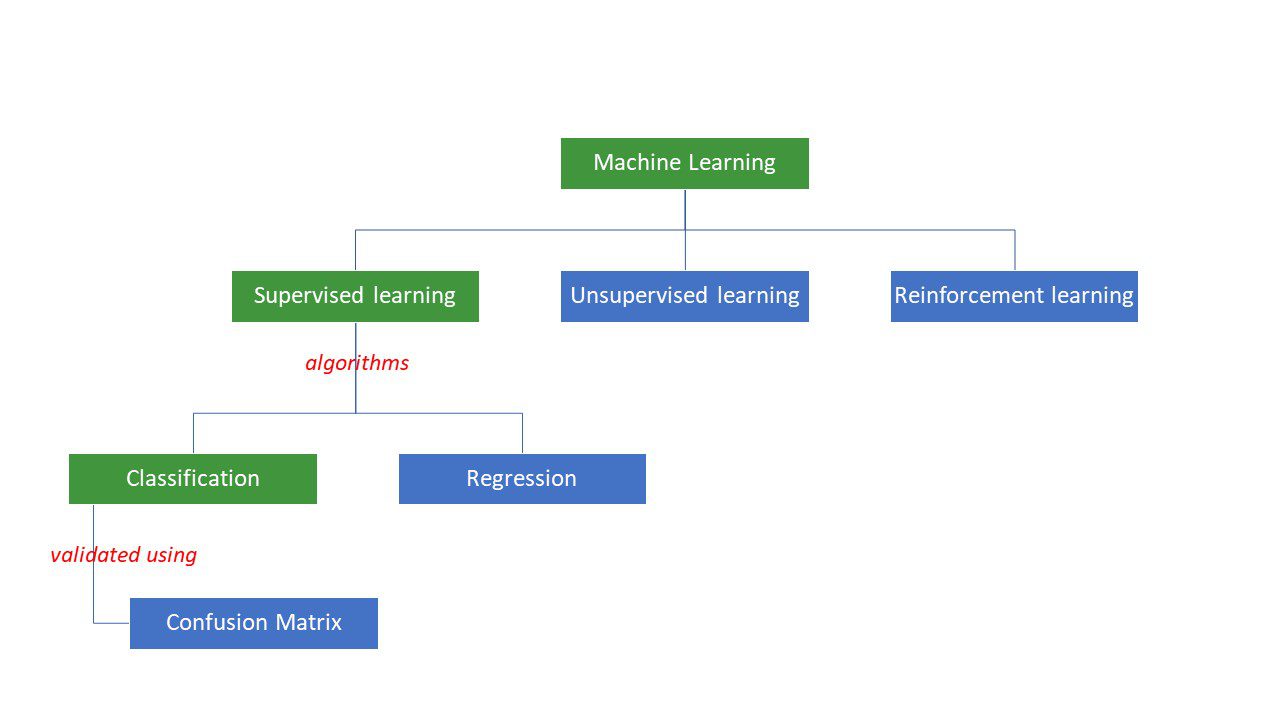
Nadgledani algoritmi su najjednostavniji; u njihovom slučaju, mi već znamo odgovor i koristimo obilje podataka da obučimo mašinu kako da dođe do istog odgovora. To je slično načinu na koji dete uči da razlikuje ljude različite starosne dobi, pažljivo posmatrajući njihove karakteristike iznova i iznova.
Nadgledani ML algoritmi se mogu podeliti na dva tipa: klasifikacione i regresione.
Klasifikacioni algoritmi svrstavaju ili sortiraju podatke na osnovu određenog skupa kriterijuma. Na primer, ako želite da algoritam grupira kupce na osnovu njihovih preferencija u vezi sa hranom – one koji vole picu i one koji je ne vole – upotrebili biste klasifikacioni algoritam poput stabla odlučivanja, nasumične šume, Naive Bayes ili SVM (Support Vector Machine).
Koji od ovih algoritama bi najbolje obavio posao? Zašto biste izabrali jedan algoritam umesto drugog?
Tu na scenu stupa matrica konfuzije…
Matrica konfuzije je tabela ili matrica koja daje detaljne informacije o tome koliko je precizan klasifikacioni algoritam prilikom klasifikovanja skupa podataka. Iako ime može zvučati zbunjujuće, veliki broj netačnih predviđanja verovatno znači da je algoritam bio zbunjen 😉!
Dakle, matrica konfuzije je metoda za procenu performansi klasifikacionog algoritma.
Kako to funkcioniše?
Recimo da ste primenili različite algoritme na naš prethodni binarni problem: klasifikovanje ljudi na osnovu toga da li vole ili ne vole picu. Da biste ocenili koji algoritam daje vrednosti koje su najbliže tačnom odgovoru, koristili biste matricu konfuzije. Za problem binarne klasifikacije (sviđa mi se/ne sviđa mi se, tačno/netačno, 1/0), matrica konfuzije prikazuje četiri vrednosti u mreži:
- Tačno pozitivno (TP)
- Tačno negativno (TN)
- Lažno pozitivno (FP)
- Lažno negativno (FN)
Koje su četiri mreže u matrici konfuzije?
Četiri vrednosti dobijene korišćenjem matrice konfuzije formiraju mreže matrice.
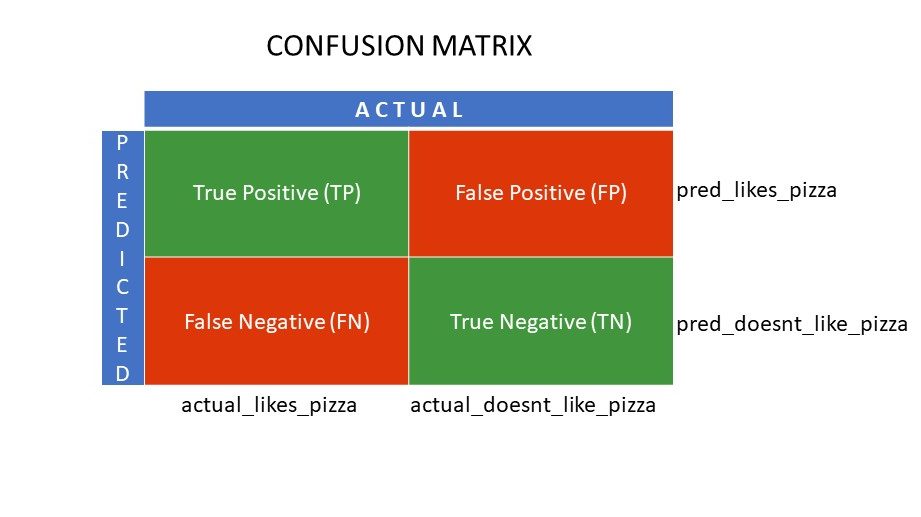
Tačno pozitivno (TP) i tačno negativno (TN) su vrednosti koje je klasifikacioni algoritam tačno predvideo:
- TP predstavlja one koji vole picu, a model ih je pravilno klasifikovao.
- TN predstavlja one koji ne vole picu, a model ih je pravilno klasifikovao.
Lažno pozitivno (FP) i lažno negativno (FN) su vrednosti koje klasifikator pogrešno predviđa:
- FP predstavlja one koji ne vole picu (negativno), ali je klasifikator predvideo da vole picu (pogrešno pozitivno). FP se takođe naziva greškom tipa I.
- FN predstavlja one koji vole picu (pozitivno), ali je klasifikator predvideo da ne vole (pogrešno negativno). FN se takođe naziva greškom tipa II.
Da bismo bolje razumeli koncept, posmatrajmo primer iz stvarnog života.
Pretpostavimo da imate skup podataka od 400 ljudi koji su bili podvrgnuti testu na COVID. Sada ste dobili rezultate različitih algoritama koji su odredili broj COVID pozitivnih i COVID negativnih ljudi.
Evo dve matrice konfuzije za poređenje:
| Algoritam 1 | Pozitivno | Negativno |
| Predviđeno pozitivno | 100 | 20 |
| Predviđeno negativno | 10 | 270 |
| Algoritam 2 | Pozitivno | Negativno |
| Predviđeno pozitivno | 105 | 35 |
| Predviđeno negativno | 5 | 255 |
Na prvi pogled, mogli biste pomisliti da je algoritam 1 precizniji. Međutim, da bismo dobili konkretan rezultat, potrebne su nam metrike koje mogu izmeriti preciznost, tačnost i mnoge druge vrednosti koje dokazuju koji je algoritam bolji.
Metrike zasnovane na matrici konfuzije i njihov značaj
Glavni pokazatelji koji nam pomažu da procenimo da li je klasifikator napravio tačna predviđanja su:
#1. Opoziv/Osetljivost
Opoziv ili Osetljivost ili Stopa tačnih pozitivnih (TPR) ili Verovatnoća detekcije predstavlja odnos tačnih pozitivnih predviđanja (TP) i ukupnih pozitivnih rezultata (tj. TP i FN).
R = TP/(TP + FN)
Opoziv je mera tačnih pozitivnih rezultata dobijenih od broja tačnih pozitivnih rezultata koji su mogli biti proizvedeni. Viša vrednost opoziva znači manje lažnih negativnih rezultata, što je dobro za algoritam. Opoziv je posebno važan kada je potrebno prepoznati lažne negativne rezultate. Na primer, ako osoba ima ozbiljne srčane probleme, a model pokazuje da je potpuno zdrava, to bi moglo imati fatalne posledice.
#2. Preciznost
Preciznost je mera tačnih pozitivnih rezultata od svih predviđenih pozitivnih rezultata, uključujući tačne i lažne pozitivne.
Pr = TP/(TP + FP)
Preciznost je od ključnog značaja kada su lažni pozitivni rezultati previše važni da bi se zanemarili. Na primer, ako osoba nema dijabetes, ali model pokazuje da ima, a lekar prepisuje određene lekove. Ovo može dovesti do ozbiljnih neželjenih efekata.
#3. Specifičnost
Specifičnost ili Stopa tačnih negativnih (TNR) predstavlja tačne negativne rezultate dobijene od svih rezultata koji su mogli biti negativni.
S = TN/(TN + FP)
To je mera toga koliko dobro vaš klasifikator identifikuje negativne vrednosti.
#4. Tačnost
Tačnost predstavlja broj tačnih predviđanja u odnosu na ukupan broj predviđanja. Dakle, ako ste tačno pronašli 20 pozitivnih i 10 negativnih vrednosti iz uzorka od 50, tačnost vašeg modela će biti 30/50.
Tačnost A = (TP + TN)/(TP + TN + FP + FN)
#5. Prevalencija
Prevalencija je mera broja pozitivnih rezultata u odnosu na ukupan broj rezultata.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F-mera
Ponekad je teško uporediti dva klasifikatora (modela) koristeći samo preciznost i opoziv, koji su samo aritmetičke sredine kombinacije četiri mreže. U takvim slučajevima, možemo koristiti F-meru ili F1-meru, koja je harmonijska sredina – i smatra se preciznijom jer nije podložna velikim varijacijama kod ekstremnih vrednosti. Viša F-mera (maksimalno 1) ukazuje na bolji model.
F-mera = 2 * Preciznost * Opoziv / (Opoziv + Preciznost)
Kada je od suštinske važnosti voditi računa i o lažno pozitivnim i lažno negativnim rezultatima, F1-mera je dobar indikator. Na primer, osobe koje nisu pozitivne na COVID (ali je algoritam to pokazao) ne bi trebalo nepotrebno da budu izolovane. Sa druge strane, osobe koje su pozitivne na COVID (ali je algoritam pokazao da nisu) moraju biti izolovane.
#7. ROC krive
Parametri poput tačnosti i preciznosti su dobri indikatori ako su podaci uravnoteženi. Kod neuravnoteženog skupa podataka, visoka preciznost ne mora nužno značiti da je klasifikator efikasan. Na primer, ako 90 od 100 učenika u grupi zna španski, čak i ako vaš algoritam pokaže da svih 100 zna španski, njegova tačnost će biti 90%, što može dati pogrešan utisak o modelu. U slučajevima neuravnoteženih skupova podataka, metrike poput ROC su efikasnije.
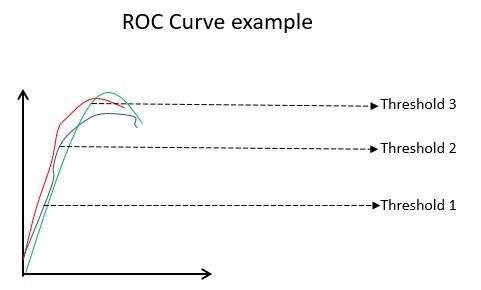
ROC (Receiver Operating Characteristic) kriva vizuelno prikazuje performanse binarnog modela klasifikacije na različitim pragovima klasifikacije. To je grafikon TPR-a (True Positive Rate) u odnosu na FPR (False Positive Rate), koji se izračunava kao (1-specifičnost) za različite vrednosti praga. Vrednost koja je najbliža 45 stepeni (gore levo) na grafikonu je najtačnija granična vrednost. Ako je prag previsok, nećemo imati mnogo lažnih pozitivnih rezultata, ali ćemo dobiti više lažnih negativa i obrnuto.
Generalno, kada se crta ROC kriva za različite modele, boljim modelom se smatra onaj koji ima najveću površinu ispod krive (AUC).
Hajde da izračunamo sve metričke vrednosti za naše matrice konfuzije klasifikatora I i klasifikatora II:
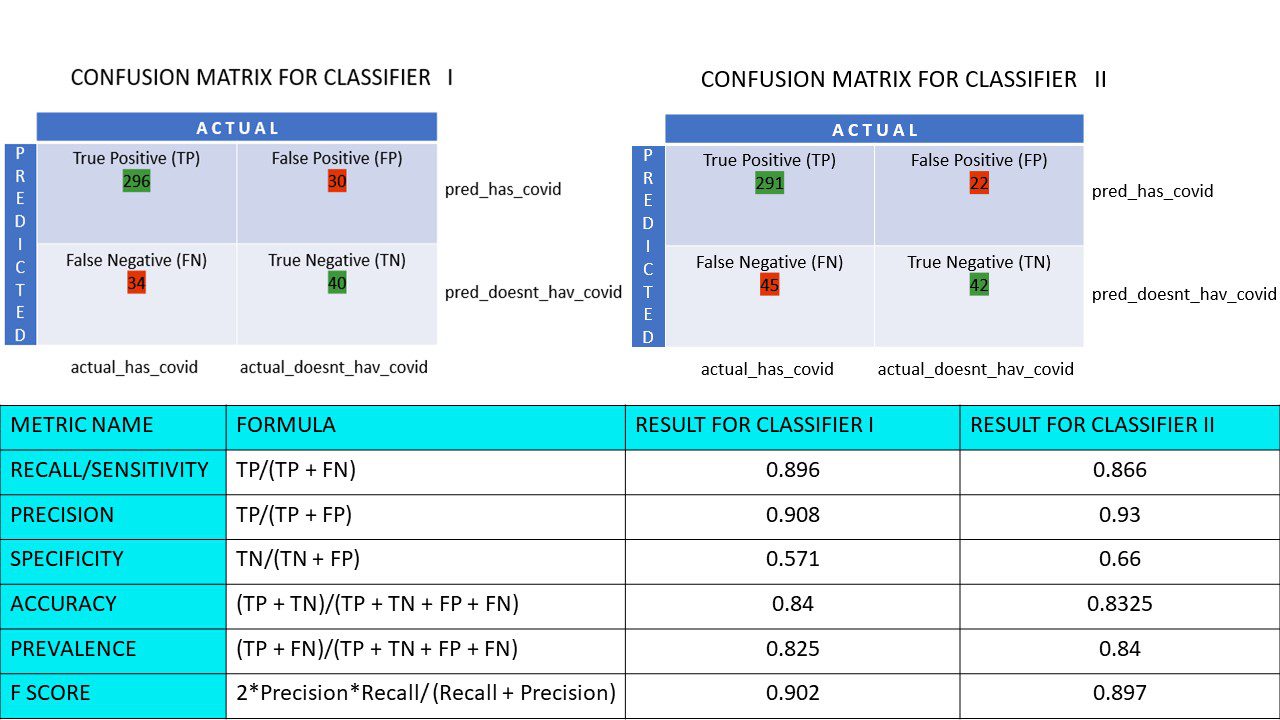
Možemo primetiti da je preciznost veća kod klasifikatora II, dok je tačnost nešto veća kod klasifikatora I. U zavisnosti od problema, donosioci odluka mogu izabrati klasifikator I ili II.
N x N matrica konfuzije
Do sada smo razmatrali matricu konfuzije za binarne klasifikatore. Šta ako postoji više kategorija od jednostavnog da/ne ili sviđa mi se/ne sviđa mi se? Na primer, ako je vaš zadatak da algoritam sortira slike u crvenu, zelenu i plavu boju. Ova vrsta klasifikacije se naziva višeklasna klasifikacija. Broj izlaznih varijabli određuje veličinu matrice. Dakle, u ovom slučaju, matrica konfuzije će biti 3×3.

Rezime
Matrica konfuzije je izvanredan sistem za evaluaciju, jer pruža detaljne informacije o performansama klasifikacionog algoritma. Odlično funkcioniše za binarne i višeklasne klasifikatore, gde postoji više od 2 parametra koje treba uzeti u obzir. Matrica konfuzije se lako vizualizuje, a pomoću nje možemo generisati i sve ostale metrike performansi kao što su F-mera, preciznost, ROC i tačnost.
Takođe, možete pogledati kako odabrati ML algoritme za probleme regresije.