
У области савремене вештачке интелигенције (АИ), учење са појачањем (РЛ) је једна од најзгоднијих истраживачких тема. Програмери вештачке интелигенције и машинског учења (МЛ) такође се фокусирају на РЛ праксе како би импровизовали интелигентне апликације или алате које развијају.
Машинско учење је принцип иза свих АИ производа. Људски програмери користе различите МЛ методологије за обуку својих интелигентних апликација, игара итд. МЛ је веома разнолико поље, а различити развојни тимови долазе са новим методама обуке машине.
Један такав уносан метод МЛ је учење са дубоким појачањем. Овде кажњавате нежељено понашање машине и награђујете жељене акције интелигентне машине. Стручњаци сматрају да ће овај метод МЛ подстаћи АИ да учи из сопствених искустава.
Наставите да читате овај врхунски водич о методама учења са појачањем за интелигентне апликације и машине ако размишљате о каријери у области вештачке интелигенције и машинског учења.
Преглед садржаја
Шта је учење са појачањем у машинском учењу?
РЛ је подучавање модела машинског учења компјутерским програмима. Затим, апликација може донети низ одлука на основу модела учења. Софтвер учи да постигне циљ у потенцијално сложеном и неизвесном окружењу. У оваквом моделу машинског учења, АИ се суочава са сценаријем сличним игрици.
Апликација АИ користи покушаје и грешке да би измислила креативно решење за проблем који је у питању. Једном када АИ апликација научи одговарајуће МЛ моделе, она даје упутства машини коју контролише да уради неке задатке које програмер жели.
На основу тачне одлуке и извршења задатка, АИ добија награду. Међутим, ако АИ направи погрешне изборе, суочава се са казнама, попут губитка наградних поена. Крајњи циљ за АИ апликацију је да сакупи максималан број наградних поена за победу у игри.
Програмер АИ апликације поставља правила игре или политику награда. Програмер такође пружа проблем који АИ треба да реши. За разлику од других МЛ модела, АИ програм не добија никакав наговештај од софтверског програмера.
АИ треба да смисли како да реши изазове у игри да би зарадио максималне награде. Апликација може да користи покушаје и грешке, насумичне покушаје, вештине суперкомпјутера и софистициране тактике мисаоног процеса да би дошла до решења.
Морате опремити АИ програм снажном рачунарском инфраструктуром и повезати његов систем размишљања са различитим паралелним и историјским играма. Затим, АИ може показати критичку креативност на високом нивоу коју људи не могу замислити.
Популарни примери учења са појачањем
#1. Побеђивање најбољег човека Го играча
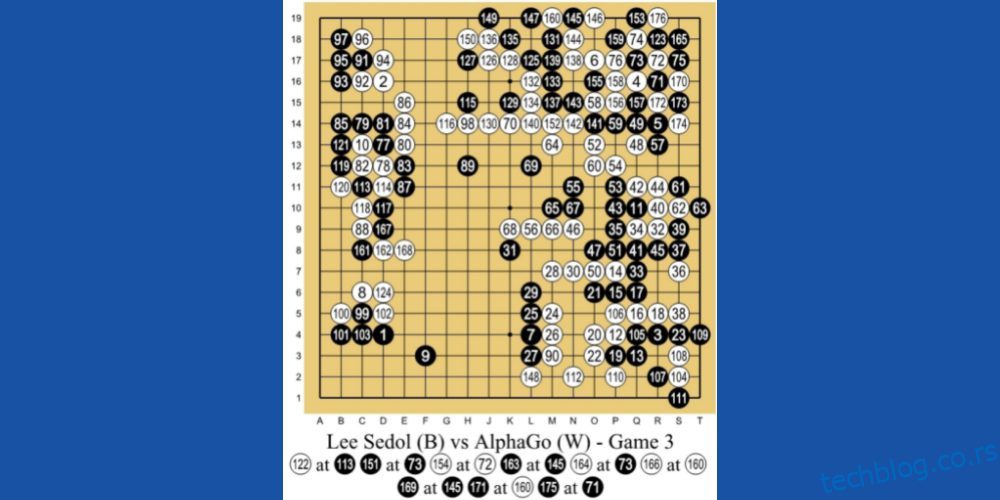
АлпхаГо АИ из ДеепМинд Тецхнологиес, подружнице Гоогле-а, један је од водећих примера машинског учења заснованог на РЛ. АИ игра кинеску друштвену игру под називом Го. То је 3.000 година стара игра која се фокусира на тактику и стратегије.
Програмери су користили РЛ метод учења за АлпхаГо. Играо је на хиљаде Го сесија са људима и самим собом. Затим је 2016. победио најбољег светског Го играча Лее Се-Дола у мечу један на један.
#2. Роботика из стварног света
Људи већ дуго користе роботику у производним линијама где су задаци унапред планирани и понављају. Али, ако треба да направите робота опште намене за стварни свет где акције нису унапред планиране, онда је то велики изазов.
Али, вештачка интелигенција са подршком за учење могла би да открије глатку, пловну и кратку руту између две локације.
#3. Селф-Дривинг Вехицлес
Истраживачи аутономних возила широко користе РЛ метод да подучавају своје АИ за:
- Динамички пут
- Оптимизација путање
- Планирање кретања попут паркирања и промене траке
- Оптимизујући контролери, (електронска контролна јединица) ЕЦУ, (микроконтролери) МЦУ, итд.
- Учење засновано на сценарију на аутопутевима
#4. Аутоматизовани системи за хлађење

РЛ засноване на вештачкој интелигенцији могу помоћи да се смањи потрошња енергије система за хлађење у огромним пословним зградама, пословним центрима, тржним центрима и, што је најважније, центрима података. АИ прикупља податке са хиљада топлотних сензора.
Такође прикупља податке о људским и машинским активностима. На основу ових података, АИ може да предвиди будући потенцијал за производњу топлоте и на одговарајући начин укључује и искључује системе за хлађење како би уштедела енергију.
Како поставити модел учења за појачавање
Можете да подесите РЛ модел на основу следећих метода:
#1. Засновано на политици
Овај приступ омогућава програмеру вештачке интелигенције да пронађе идеалну политику за максималне награде. Овде програмер не користи функцију вредности. Једном када поставите метод заснован на политици, агент за учење појачања покушава да примени политику тако да радње које обавља у сваком кораку омогућавају вештачкој интелигенцији да максимизира поене за награду.
Пре свега постоје две врсте политика:
#1. Детерминистички: Политика може произвести исте акције у било којој држави.
#2. Стохастички: Произведене акције су одређене вероватноћом појаве.
#2. На основу вредности
Приступ заснован на вредности, напротив, помаже програмеру да пронађе оптималну функцију вредности, која је максимална вредност у оквиру политике у било ком датом стању. Када се једном примени, РЛ агент очекује дугорочни поврат у било којој или више држава у складу са поменутом политиком.
#3. На основу модела
У РЛ приступу заснованом на моделу, АИ програмер креира виртуелни модел за окружење. Затим, РЛ агент се креће по окружењу и учи из њега.
Врсте учења са појачањем
#1. Учење са позитивним појачањем (ПРЛ)
Позитивно учење значи додавање неких елемената како би се повећала вероватноћа да ће се очекивано понашање поновити. Ова метода учења позитивно утиче на понашање РЛ агента. ПРЛ такође побољшава снагу одређених понашања ваше вештачке интелигенције.
ПРЛ тип поткрепљења учења треба да припреми АИ да се прилагођава променама на дуже време. Али убризгавање превише позитивног учења може довести до преоптерећења стања која могу смањити ефикасност АИ.

#2. Негативно учење уз помоћ (НРЛ)
Када РЛ алгоритам помаже АИ да избегне или заустави негативно понашање, он учи из њега и побољшава своје будуће акције. Познато је као негативно учење. Он само пружа вештачкој интелигенцији ограничену интелигенцију само да испуни одређене захтеве понашања.
Стварни случајеви употребе учења са појачањем
#1. Програмери решења за е-трговину су направили персонализоване алате за сугерисање производа или услуга. Можете да повежете АПИ алатке са својом веб локацијом за куповину на мрежи. Затим ће АИ учити од појединачних корисника и предложити прилагођена добра и услуге.
#2. Видео игре отвореног света долазе са неограниченим могућностима. Међутим, иза програма игре постоји АИ програм који учи на основу уноса играча и модификује код видео игре да би се прилагодио непознатој ситуацији.
#3. Платформе за трговање акцијама и инвестиционе платформе засноване на вештачкој интелигенцији користе РЛ модел да уче из кретања акција и глобалних индекса. Сходно томе, они формулишу модел вероватноће да би предложили акције за улагање или трговање.
#4. Онлине видеотеке као што су ИоуТубе, Метацафе, Даилимотион, итд., користе АИ ботове обучене на РЛ моделу да предлажу персонализоване видео записе својим корисницима.
Учење са појачањем вс. Учење под надзором
Учење са појачањем има за циљ обуку агента АИ да доноси одлуке секвенцијално. Укратко, можете узети у обзир да излаз АИ зависи од стања тренутног улаза. Слично томе, следећи улаз у РЛ алгоритам зависиће од излаза прошлих улаза.

Роботска машина заснована на вештачкој интелигенцији која игра партију шаха против човека шаха је пример РЛ модела машинског учења.
Напротив, у надгледаном учењу, програмер обучава АИ агента да доноси одлуке на основу инпута датих на почетку или било ког другог почетног уноса. АИ за аутономну вожњу аутомобила који препознаје објекте животне средине је одличан пример учења под надзором.
Учење са појачањем вс. Учење без надзора
До сада сте разумели да РЛ метода гура АИ агента да учи из политика модела машинског учења. Углавном, АИ ће направити само оне кораке за које добија максималне наградне поене. РЛ помаже АИ да импровизује путем покушаја и грешака.
С друге стране, у учењу без надзора, АИ програмер уводи софтвер АИ са неозначеним подацима. Такође, инструктор МЛ не говори АИ ништа о структури података или шта да тражи у подацима. Алгоритам учи различите одлуке тако што каталогизује сопствена запажања о датим непознатим скуповима података.
Курсеви учења за појачавање
Сада када сте научили основе, ево неколико онлајн курсева за учење напредног учења са појачањем. Такође добијате сертификат који можете да прикажете на ЛинкедИн-у или другим друштвеним платформама:
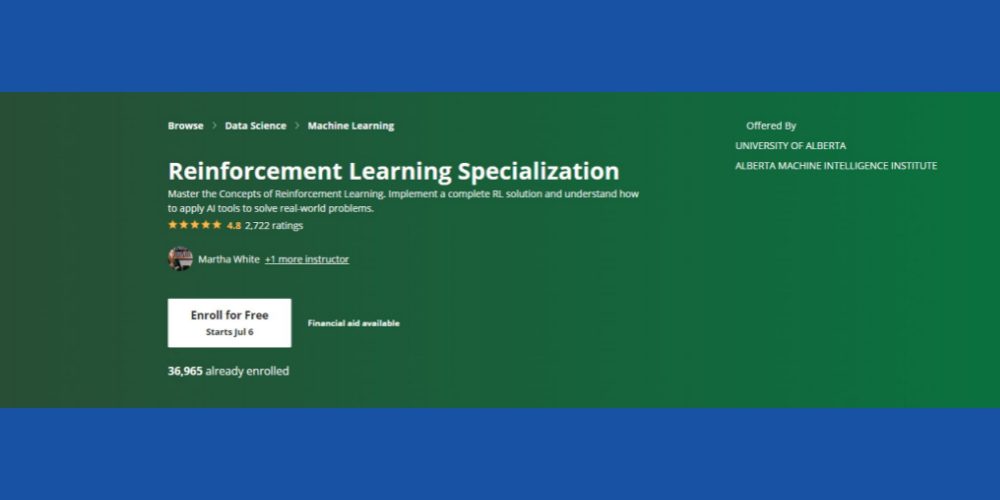
Специјализација учења за појачавање: Цоурсера
Да ли желите да савладате основне концепте учења уз помоћ МЛ контекста? Можете пробати ово Цоурсера РЛ курс који је доступан на мрежи и долази са самосталним учењем и опцијом сертификације. Курс ће бити прикладан за вас ако понесете следеће као основне вештине:
- Знање програмирања у Питхон-у
- Основни статистички појмови
- Можете да конвертујете псеудокодове и алгоритме у Питхон кодове
- Искуство у развоју софтвера од две до три године
- Студенти друге године основних студија у области информатике такође имају право
Курс има оцену 4,8 звездица, а преко 36.000 студената се већ уписало на курс у различитим временским курсевима. Штавише, курс долази уз финансијску помоћ под условом да кандидат испуњава одређене критеријуме подобности за Цоурсера.
Коначно, Институт за машинску интелигенцију Алберте Универзитета Алберта нуди овај курс (без бодова). Поштовани професори из области информатике ће функционисати као ваши инструктори курса. Добићете Цоурсера сертификат по завршетку курса.
Учење са АИ појачањем у Питхону: Удеми
Ако се бавите финансијским тржиштем или дигиталним маркетингом и желите да развијете интелигентне софтверске пакете за наведена поља, морате погледати ово Удеми курс на РЛ. Поред основних принципа РЛ, садржај обуке ће вас такође научити како да развијете РЛ решења за онлајн оглашавање и трговање акцијама.

Неке значајне теме које курс покрива су:
- Преглед РЛ на високом нивоу
- Динамичко програмирање
- Монет Царло
- Методе апроксимације
- Пројекат трговања акцијама са РЛ
Курс је до сада похађало преко 42.000 ученика. Ресурс за учење на мрежи тренутно има оцену од 4,6 звездица, што је прилично импресивно. Штавише, курс има за циљ пружање услуга глобалној студентској заједници пошто је садржај учења доступан на француском, енглеском, шпанском, немачком, италијанском и португалском.
Дееп Реинфорцемент Леарнинг ин Питхон: Удеми
Ако имате радозналост и основно знање о дубоком учењу и вештачкој интелигенцији, можете испробати ово напредно РЛ курс у Питхон-у из Удеми. Са оценом од 4,6 звездица од стране студената, то је још један популаран курс за учење РЛ у контексту АИ/МЛ.

Курс има 12 секција и покрива следеће виталне теме:
- ОпенАИ теретана и основне РЛ технике
- ТД Ламбда
- А3Ц
- Тхеано Басицс
- Тенсорфлов Басицс
- Питхон кодирање за почетак
Цео курс ће захтевати посвећено улагање од 10 сати и 40 минута. Осим текстова, долази и са 79 стручних предавања.
Експерт за учење дубоког појачања: Удацити
Желите да научите напредно машинско учење од светских лидера у АИ/МЛ као што су Нвидиа Дееп Леарнинг Институте и Унити? Удацити вам омогућава да испуните свој сан. Погледај ово Дееп Реинфорцемент Леарнинг курс да постане стручњак за МЛ.

Међутим, потребно је да имате позадину напредног Питхон-а, средње статистике, теорије вероватноће, ТенсорФлов-а, ПиТорцх-а и Кераса.
За завршетак курса биће потребно марљиво учење до 4 месеца. Током курса научићете виталне РЛ алгоритме као што су дубоки детерминистички градијенти политике (ДДПГ), дубоке К-мреже (ДКН) итд.
Завршне речи
Учење са појачањем је следећи корак у развоју вештачке интелигенције. Агенције за развој вештачке интелигенције и ИТ компаније улажу у овај сектор како би створили поуздане и поуздане методологије обуке АИ.
Иако је РЛ много напредовао, има више домета развоја. На пример, одвојени РЛ агенти не деле знање међу собом. Стога, ако обучавате апликацију за вожњу аутомобила, процес учења ће постати спор. Зато што РЛ агенти попут откривања објеката, референци на путеве, итд., неће делити податке.
Постоје могућности да у такве изазове уложите своју креативност и МЛ стручност. Пријављивање за онлајн курсеве ће вам помоћи да унапредите своје знање о напредним РЛ методама и њиховој примени у пројектима из стварног света.
Још једно повезано учење за вас су разлике између АИ, машинског учења и дубоког учења.