Računarska tehnologija doživljava svoj vrhunac i nastavlja da se razvija. U protekle tri decenije, mašine su značajno napredovale, posebno u pogledu procesorske snage i sposobnosti obavljanja više zadataka istovremeno.
Možete li da zamislite koliki bi porast performansi bio moguć kada bi se zadaci delili između više računara i izvršavali paralelno? Ovo se naziva distribuirano računarstvo. To je u suštini timski rad za računare.
Možda se pitate zašto uopšte diskutujemo o distribuiranom računarstvu. Razlog je taj što su distribuirano računarstvo i Amazon EMR (Elastic MapReduce) usko povezani. AWS EMR koristi principe distribuiranog računarstva za obradu i analizu velikih količina podataka u oblaku.
Sa Amazon EMR-om, sada možete analizirati i obrađivati ogromne količine podataka koristeći distribuirani okvir za obradu po vašem izboru na S3 instancama.
Kako funkcioniše Amazon EMR?
Izvor: aws.amazon.com
Prvo, unesite podatke u bilo koje skladište podataka, kao što su Amazon S3, DynamoDB ili druge AWS platforme za skladištenje, jer su sve one dobro integrisane sa EMR-om.
Sada vam je potreban okvir za obradu velikih podataka za analizu. Možete birati između različitih okvira kao što su Apache Spark, Hadoop, Hive i Presto. Izaberite onaj koji odgovara vašim zahtevima i postavite ga u odabrano skladište podataka.
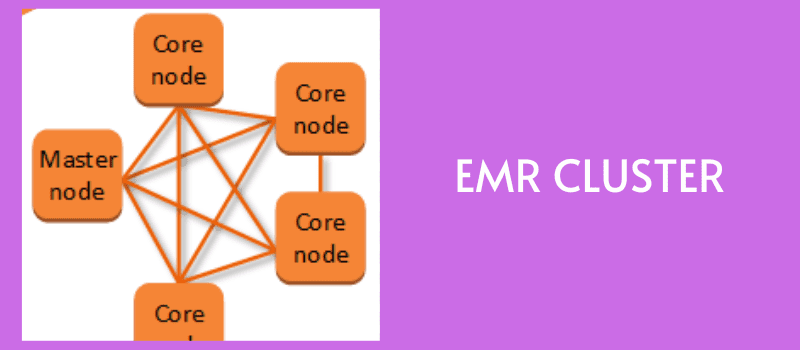
EMR klaster EC2 instanci se kreira da paralelno obrađuje i analizira podatke. Možete podesiti broj čvorova i druge detalje za kreiranje klastera.
Vaše primarno skladište distribuira podatke i okvire do ovih čvorova, gde se delovi podataka individualno obrađuju, a rezultati se kombinuju.
Kada su rezultati obrađeni, možete prekinuti klaster i osloboditi sve alocirane resurse.
Prednosti Amazon EMR-a
Preduzeća, mala ili velika, uvek teže usvajanju isplativih rešenja. Amazon EMR nudi upravo to. On pojednostavljuje pokretanje raznih okvira za velike podatke na AWS-u, pružajući jednostavan način za obradu i analizu vaših podataka, uz istovremeno štednju novca.
✅ Elastičnost: Njegova priroda se može naslutiti iz naziva „Elastic MapReduce“. Ovaj termin sugeriše da Amazon EMR omogućava laku promenu veličine klastera, ručno ili automatski, u zavisnosti od potreba. Na primer, možda vam je potrebno 200 instanci za obradu podataka u datom trenutku, a sat ili dva kasnije taj broj može narasti do 600. Dakle, Amazon EMR je idealan kada vam je potrebna skalabilnost da se prilagodite brzim promenama u potražnji.
✅ Skladišta podataka: Bez obzira da li je u pitanju Amazon S3, Hadoop distribuirani sistem datoteka, Amazon DynamoDB ili bilo koje drugo AWS skladište podataka, Amazon EMR se besprekorno integriše s njima.
✅ Alati za obradu podataka: Amazon EMR podržava različite okvire za velike podatke, uključujući Apache Spark, Hive, Hadoop i Presto. Osim toga, možete pokrenuti algoritme i alate za duboko učenje i mašinsko učenje u ovom okviru.
✅ Isplativost: Za razliku od drugih komercijalnih proizvoda, Amazon EMR vam omogućava da plaćate samo resurse koje koristite po satu. Pored toga, možete birati između različitih modela cena koji odgovaraju vašem budžetu.
✅ Prilagođavanje klastera: Ovaj okvir omogućava prilagođavanje svake instance klastera. Takođe, možete upariti okvir za velike podatke sa savršenim tipom klastera. Na primer, instance zasnovane na Apache Spark i Graviton2 predstavljaju odličnu kombinaciju za optimizovane performanse u EMR-u.
✅ Kontrola pristupa: Možete koristiti AWS alate za upravljanje identitetom i pristupom (IAM) za kontrolu dozvola u EMR-u. Na primer, možete dozvoliti određenim korisnicima da uređuju klaster, dok drugi mogu samo da ga pregledaju.
✅ Integracija: Integracija EMR-a sa svim ostalim AWS uslugama je neometana. Zahvaljujući ovome, možete iskoristiti snagu virtuelnih servera, robusnu bezbednost, proširive kapacitete i analitičke sposobnosti u EMR-u.
Slučajevi upotrebe Amazon EMR-a
#1. Mašinsko učenje

Analizirajte podatke koristeći mašinsko učenje i duboko učenje u Amazon EMR-u. Na primer, pokretanje različitih algoritama na podacima o zdravlju radi praćenja različitih zdravstvenih metrika, kao što su indeks telesne mase, broj otkucaja srca, krvni pritisak, procenat masti itd., ključno je za razvoj fitnes trackera. Sve ovo se može obaviti na EMR instancama brže i efikasnije.
#2. Izvršavanje velikih transformacija
Prodavci obično prikupljaju ogromne količine digitalnih podataka kako bi analizirali ponašanje kupaca i poboljšali poslovanje. U tom smislu, Amazon EMR je efikasan u prikupljanju velikih količina podataka i izvršavanju masovnih transformacija koristeći Spark.
#3. Pretraga podataka

Da li imate skup podataka čija je obrada veoma dugotrajna? Amazon EMR je idealan za rudarenje podataka i prediktivnu analitiku složenih skupova podataka, posebno kod nestrukturiranih podataka. Pored toga, njegova klaster arhitektura je odlična za paralelnu obradu.
#4. Istraživački ciljevi
Obavite svoja istraživanja koristeći ovaj isplativ i efikasan okvir pod nazivom Amazon EMR. Zbog njegove skalabilnosti, retko ćete naići na probleme sa performansama prilikom obrade velikih skupova podataka na EMR-u. Stoga, ovaj okvir je veoma koristan u laboratorijama za istraživanje velikih podataka i analitiku.
#5. Strimg u realnom vremenu
Još jedna velika prednost Amazon EMR-a je njegova podrška za striming u realnom vremenu. Izgradite skalabilne kanale za striming podataka u realnom vremenu za onlajn igre, video striming, praćenje saobraćaja i trgovanje akcijama koristeći Apache Kafka i Apache Flink na Amazon EMR-u.
Kako se EMR razlikuje od Amazon Glua i Redshifta?
AWS EMR nasuprot Glua
Dve moćne AWS usluge – Amazon EMR i Amazon Glue, postale su popularne u radu sa vašim podacima.
Ekstrakcija podataka iz različitih izvora, njihova transformacija i učitavanje u skladišta podataka je brzo i efikasno uz Amazon Glue, dok vam Amazon EMR pomaže da obradite vaše aplikacije za velike podatke koristeći Hadoop, Spark, Hive itd.
U suštini, AWS Glue vam omogućava da prikupite i pripremite podatke za analizu, dok vam Amazon EMR omogućava da ih obradite.
EMR protiv Redshifta
Zamislite da možete lako da se krećete kroz podatke i da ih ispitujete. SQL je nešto što se često koristi za ovo. S tim u vezi, Redshift nudi optimizovane usluge analitičke obrade na mreži za lako ispitivanje velikih količina podataka koristeći SQL.
Kada skladištite podatke, imaćete pristup visoko skalabilnom, bezbednom i dostupnom Amazon EMR-u koji koristi dobavljače skladišta treće strane kao što su S3 i DynamoDB. Nasuprot tome, Redshift ima sopstveni sloj podataka koji vam omogućava da čuvate podatke u kolonskom formatu.
Amazon EMR pristupi optimizaciji troškova

#1. Koristite formatirane podatke
Što je više podataka, to je duže potrebno za njihovu obradu. Štaviše, unošenje sirovih podataka direktno u klaster čini ga još složenijim i oduzima više vremena za pronalaženje onog dela koji želite da obradite.
Dakle, formatirani podaci dolaze sa metapodacima o kolonama, tipovima podataka, veličini i drugim informacijama, pomoću kojih možete uštedeti vreme u pretragama i agregacijama.
Takođe, smanjite veličinu podataka koristeći tehnike kompresije, jer je lakše obraditi manje skupove podataka.
#2. Koristite pristupačne usluge skladištenja
Korišćenje isplativih usluga primarnog skladištenja smanjuje vaše ukupne troškove na EMR-u. Amazon S3 je jednostavna i pristupačna usluga za čuvanje ulaznih i izlaznih podataka. Njegov model „plati koliko koristiš“ naplaćuje samo stvarni prostor za skladištenje koji ste koristili.
#3. Određivanje veličine prave instance
Korišćenje odgovarajućih instanci sa pravim veličinama može značajno da smanji budžet koji trošite na EMR. EC2 instance se obično naplaćuju po sekundi, a cena zavisi od njihove veličine. Međutim, bez obzira da li koristite .7x veliki klaster ili .36x veliki klaster, troškovi upravljanja su isti. Dakle, efikasno korišćenje većih mašina je isplativije u poređenju sa korišćenjem više manjih mašina.
#4. Spot instance
Spot instance su odlična opcija za kupovinu neiskorišćenih EC2 resursa uz popuste. U poređenju sa instancama na zahtev, one su jeftinije, ali nisu trajne jer se mogu vratiti kada se potražnja poveća. Zbog toga su fleksibilne za toleranciju grešaka, ali nisu pogodne za dugotrajne poslove.
#5. Auto-skaliranje
Njegova funkcija automatskog skaliranja je sve što vam je potrebno da biste izbegli prevelike ili premale klastere. Ovo vam omogućava da odaberete pravi broj i tip instanci u vašem klasteru na osnovu opterećenja, optimizujući troškove.
Završne reči
Nema kraja razvoju tehnologija oblaka i velikih podataka, što vam ostavlja beskrajne mogućnosti za učenje i primenu različitih alata i okvira. Jedna takva jedinstvena platforma za korišćenje velikih podataka i oblaka je Amazon EMR, jer pojednostavljuje pokretanje okvira za obradu i analizu velikih količina podataka.
Kako bi vam pomogao da započnete sa EMR-om, ovaj članak vam pokazuje šta je to, koje su njegove prednosti, kako funkcioniše, koje su mu primene i kako ga koristiti na isplativ način.
Pogledajte i sve što treba da znate o AWS Athena.