MapReduce pruža delotvoran, ubrzan i ekonomičan način za izradu aplikacija.
Ovaj model koristi napredne koncepte, poput paralelnog procesiranja i lokalizacije podataka, pružajući tako brojne pogodnosti programerima i organizacijama.
Međutim, na tržištu postoji toliko mnogo modela i programskih okvira da je odabir pravog postao izazov.
Kada se radi o velikim količinama podataka, ne možete jednostavno izabrati bilo koju tehnologiju. Potrebno je odabrati one koje su sposobne obraditi ogromne količine podataka.
MapReduce je odlično rešenje za to.
U ovom tekstu ću objasniti šta je zapravo MapReduce i kako vam može biti od pomoći.
Počnimo!
Šta je MapReduce?
MapReduce je programski model ili softverski okvir unutar Apache Hadoop okvira. Koristi se za kreiranje aplikacija koje mogu paralelno obraditi ogromne količine podataka na hiljadama čvorova (koji se nazivaju klasteri ili mreže), uz toleranciju grešaka i pouzdanost.
Obrada podataka odvija se unutar baze podataka ili sistema datoteka gde se podaci čuvaju. MapReduce može koristiti Hadoop sistem datoteka (HDFS) za pristup i upravljanje velikim količinama podataka.
Ovaj okvir je predstavljen od strane Google-a 2004. godine, a popularizovan je od strane Apache Hadoop-a. To je sloj za obradu ili mehanizam u Hadoop-u koji pokreće MapReduce programe razvijene u različitim jezicima, uključujući Java, C++, Python i Ruby.
MapReduce programi u računarstvu u oblaku rade paralelno, što ih čini pogodnim za obavljanje analiza podataka velikih razmera.
Cilj MapReduce-a je podeliti zadatak na manje, jednostavnije zadatke koristeći funkcije „map“ i „reduce“. On će mapirati svaki zadatak, a zatim ga svesti na nekoliko ekvivalentnih zadataka, što smanjuje procesorsku snagu i dodatno opterećenje na mreži klastera.
Primer: Zamislite da pripremate obrok za veliki broj gostiju. Ako biste pokušali da pripremite sva jela i obavite sve procese sami, to bi bilo naporno i dugotrajno.
Ali, zamislite da uključite prijatelje ili kolege (ne goste) da vam pomognu u pripremi obroka tako što ćete podeliti različite procese između njih. U tom slučaju, brže i lakše ćete pripremiti obrok dok su gosti još u kući.
MapReduce funkcioniše na sličan način sa distribucijom zadataka i paralelnim procesiranjem, omogućavajući brži i lakši način za obavljanje datog zadatka.
Apache Hadoop omogućava programerima da koriste MapReduce za pokretanje modela na velikim distribuiranima skupovima podataka i primenjuju napredno mašinsko učenje i statističke tehnike za pronalaženje obrazaca, predviđanja, uočavanje korelacija i još mnogo toga.
Karakteristike MapReduce-a
Neke od glavnih karakteristika MapReduce-a su:
- Korisnički interfejs: Dobijate intuitivan korisnički interfejs koji pruža detaljne informacije o svakom aspektu okvira. To vam pomaže da neometano konfigurišete, primenite i prilagodite svoje zadatke.

- Radno opterećenje: Aplikacije koriste interfejse Mapper i Reducer da bi omogućile funkcije mapiranja i redukcije. Mapper preslikava ulazne parove ključ-vrednost u međuparne parove ključ-vrednost. Reducer se koristi za smanjenje međuparnih parova ključ-vrednost koji dele ključ na druge manje vrednosti. On obavlja tri funkcije – sortiranje, mešanje i redukciju.
- Particioner: On kontroliše raspodelu međuključeva za izlaz mape.
- Reporter: To je funkcija za izveštavanje o napretku, ažuriranje brojača i postavljanje statusnih poruka.
- Brojači: Predstavljaju globalne brojače koje definiše MapReduce aplikacija.
- OutputCollector: Ova funkcija prikuplja izlazne podatke iz Mapper-a ili Reducer-a umesto međuparnih izlaza.
- RecordWriter: Zapisuje izlazne podatke ili parove ključ-vrednost u izlaznu datoteku.
- DistributedCache: Efikasno distribuira veće datoteke samo za čitanje, specifične za aplikaciju.
- Kompresija podataka: Programer aplikacije može komprimirati izlaze posla i izlaze srednje mape.
- Preskakanje loših zapisa: Možete preskočiti određene loše zapise tokom obrade ulaza u mapi. Ova funkcija se kontroliše putem klase – SkipBadRecords.
- Otklanjanje grešaka: Imate mogućnost pokretanja korisnički definisanih skripti i omogućavanja otklanjanja grešaka. Ako zadatak u MapReduce-u ne uspe, možete pokrenuti skriptu za otklanjanje grešaka i pronaći problem.
MapReduce Arhitektura
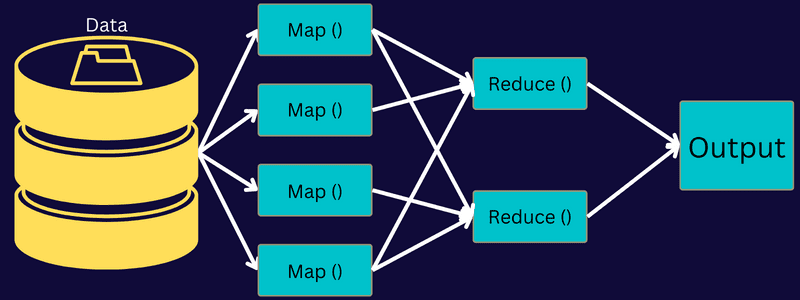
Hajde da detaljnije objasnimo MapReduce arhitekturu kroz njene komponente:
- Posao: Posao u MapReduce-u je stvarni zadatak koji MapReduce klijent želi da izvrši. Sastoji se od nekoliko manjih zadataka koji se kombinuju u konačni zadatak.
- Server istorije poslova: To je demonski proces za skladištenje i čuvanje svih istorijskih podataka o aplikaciji ili zadatku, kao što su zapisi generisani nakon ili pre izvršavanja posla.
- Klijent: Klijent (program ili API) donosi posao u MapReduce za izvršavanje ili obradu. U MapReduce-u, jedan ili više klijenata mogu kontinuirano slati poslove MapReduce Manager-u na obradu.
- MapReduce Master: MapReduce Master deli posao na nekoliko manjih delova, osiguravajući da zadaci napreduju istovremeno.
- Delovi posla: Pod-poslovi ili delovi posla se dobijaju podelom primarnog posla. Oni se obavljaju i konačno se kombinuju da bi se stvorio konačni zadatak.
- Ulazni podaci: To je skup podataka koji se šalje u MapReduce za obradu zadataka.
- Izlazni podaci: To je konačni rezultat dobijen kada se zadatak obradi.
Dakle, ono što se dešava u ovoj arhitekturi je da klijent predaje posao MapReduce Master-u, koji ga deli na manje, jednake delove. To omogućava bržu obradu posla, jer je za obradu manjih zadataka potrebno manje vremena, umesto većih zadataka.
Međutim, treba osigurati da zadaci nisu podeljeni na premale zadatke jer, u tom slučaju, možete se suočiti sa većim troškovima upravljanja podelama i izgubiti značajno vreme na to.
Zatim, delovi posla se stavljaju na raspolaganje za nastavak sa zadacima Map i Reduce. Štaviše, zadaci Map i Reduce imaju odgovarajući program, zasnovan na slučaju upotrebe, na kojem tim radi. Programer razvija kod zasnovan na logici da ispuni zahteve.
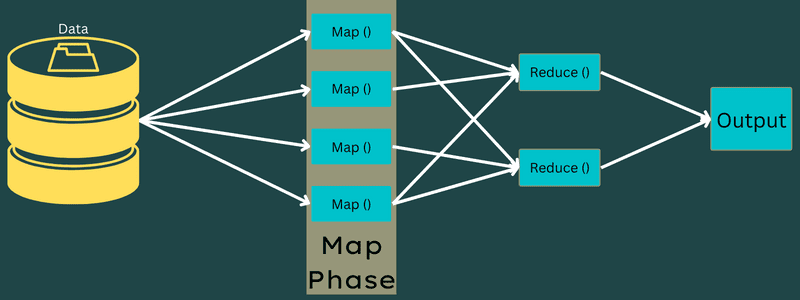
Nakon toga, ulazni podaci se unose u zadatak mape kako bi mapa mogla brzo generisati izlaz kao par ključ-vrednost. Umesto čuvanja tih podataka na HDFS-u, lokalni disk se koristi za skladištenje podataka kako bi se eliminisala mogućnost replikacije.
Kada je zadatak završen, možete odbaciti izlaz. Dakle, replikacija će postati suvišna kada sačuvate izlaz na HDFS-u. Izlaz svakog zadatka mape biće poslat zadatku smanjenja, a izlaz mape će biti obezbeđen mašini koja obavlja zadatak smanjenja.
Zatim, izlaz će biti spojen i prosleđen funkciji redukcije koju definiše korisnik. Konačno, smanjeni izlaz biće sačuvan na HDFS-u.
Štaviše, proces može imati nekoliko zadataka Map i Reduce za obradu podataka, u zavisnosti od krajnjeg cilja. Algoritmi Map i Reduce su optimizovani kako bi vremenska ili prostorna složenost bila minimalna.
Pošto MapReduce primarno uključuje zadatke Map i Reduce, važno je da ih bolje razumemo. Stoga, hajde da diskutujemo o fazama MapReduce-a da bismo stekli jasnu predstavu o tim temama.
Faze MapReduce-a
Mapa
Ulazni podaci se mapiraju u izlazne ili parove ključ-vrednost u ovoj fazi. Ovde se ključ može odnositi na ID adrese, dok vrednost može biti stvarna vrednost te adrese.
U ovoj fazi postoje samo jedan ali dva zadatka – razdvajanje i mapiranje. Podela znači pod-delove ili delove posla koji su podeljeni od glavnog posla. Oni se takođe nazivaju podelama ulaza. Dakle, ulazni split se može nazvati ulaznim komadom koji koristi mapa.
Zatim se odvija zadatak mapiranja. Smatra se prvom fazom prilikom izvršavanja programa za smanjenje mape. Ovde će podaci sadržani u svakom razdvajanju biti prosleđeni funkciji mape da obradi i generiše izlaz.
Funkcija – Map() se izvršava u memorijskom spremištu na ulaznim parovima ključ-vrednost, generišući srednji par ključ-vrednost. Ovaj novi par ključ/vrednost će raditi kao ulaz koji će se ubaciti u funkciju Reduce() ili Reducer.
Smanjenje
Srednji parovi ključ-vrednost, dobijeni u fazi mapiranja, rade kao ulaz za funkciju Reduce ili Reducer. Slično fazi mapiranja, uključena su dva zadatka – mešanje i smanjenje.
Dakle, dobijeni parovi ključ-vrednost se sortiraju i izmešaju da bi se uneli u Reducer. Zatim, Reducer grupiše ili agregira podatke prema svom paru ključ/vrednost, na osnovu algoritma reduktora koji je napisao programer.
Ovde se vrednosti iz faze mešanja kombinuju da bi se vratila izlazna vrednost. Ova faza sumira ceo skup podataka.
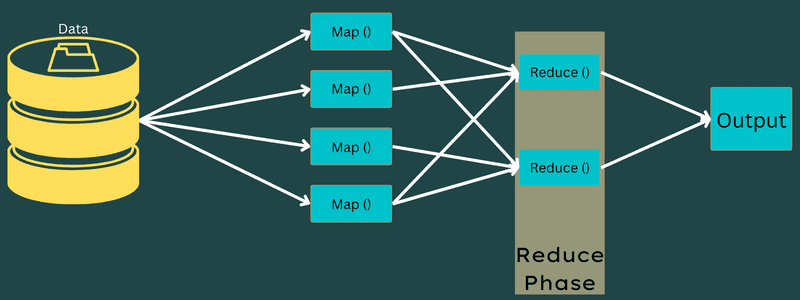
Sada, kompletan proces izvršavanja zadataka Map i Reduce kontrolišu neki entiteti. To su:
- Job Tracker: Jednostavno rečeno, program za praćenje poslova funkcioniše kao nadzornik koji je odgovoran za potpuno izvršenje poslatog posla. Praćenje poslova upravlja svim poslovima i resursima u klasteru. Pored toga, program za praćenje poslova planira svaku mapu koja je dodata u Task Tracker koja radi na određenom čvoru podataka.
- Višestruki uređaji za praćenje zadataka: Jednostavno rečeno, višestruki uređaji za praćenje zadataka rade kao izvršioci koji obavljaju zadatke prateći uputstva Job Tracker-a. Praćenje zadataka je raspoređeno na svakom čvoru posebno u klasteru koji izvršava zadatke Map i Reduce.
Ovo radi jer će posao biti podeljen na nekoliko zadataka koji će se izvoditi na različitim čvorovima podataka iz klastera. Job Tracker je odgovoran za koordinaciju zadatka tako što planira zadatke i pokreće ih na više čvorova podataka. Zatim, Task Tracker, koji se nalazi na svakom čvoru podataka, izvršava delove posla i vodi računa o svakom zadatku.
Štaviše, Task Trackeri šalju izveštaje o napretku praćenju poslova. Takođe, Task Tracker periodično šalje signal „otkucaja srca“ Job Tracker-u, obaveštavajući ih o statusu sistema. U slučaju bilo kakvog kvara, program za praćenje poslova može ponovo zakazati posao na drugom alatu za praćenje zadataka.
Izlazna faza: Kada dođete do ove faze, imaćete konačne parove ključ-vrednost generisane iz Reducer-a. Možete da koristite izlazni formater da prevedete parove ključ-vrednost i upišete ih u datoteku uz pomoć pisca zapisa.
Zašto koristiti MapReduce?
Evo nekih od prednosti MapReduce-a, objašnjavajući razloge zašto ga morate koristiti u svojim aplikacijama za velike podatke:
Paralelna obrada
Možete podeliti posao na različite čvorove, gde svaki čvor istovremeno obrađuje deo posla u MapReduce-u. Dakle, podela većih zadataka na manje smanjuje složenost. Takođe, pošto se različiti zadaci pokreću paralelno na različitim mašinama, umesto na jednoj mašini, potrebno je znatno manje vremena za obradu podataka.
Lokalitet podataka
U MapReduce-u možete premestiti jedinicu za obradu u podatke, a ne obrnuto.
Na tradicionalne načine, podaci su dovođeni u jedinicu za obradu. Međutim, sa brzim rastom podataka, taj proces je počeo da predstavlja mnoge izazove. Neki od njih su bili skupi, dugotrajni, opterećivali su glavni čvor, dolazilo je do čestih kvarova, kao i do smanjenih performansi mreže.
Ali MapReduce pomaže u prevazilaženju tih problema, prateći obrnuti pristup – dovodeći jedinicu za obradu podacima. Na taj način, podaci se distribuiraju između različitih čvorova, gde svaki čvor može da obradi deo uskladištenih podataka.
Kao rezultat, pruža ekonomičnost i smanjuje vreme obrade, pošto svaki čvor radi paralelno sa svojim odgovarajućim delom podataka. Pored toga, pošto svaki čvor obrađuje deo tih podataka, nijedan čvor neće biti preopterećen.
Bezbednost

MapReduce model nudi veću sigurnost. Pomaže u zaštiti vaše aplikacije od neovlašćenih podataka, istovremeno poboljšavajući sigurnost klastera.
Skalabilnost i fleksibilnost
MapReduce je visoko skalabilan okvir. Omogućava vam da pokrećete aplikacije sa nekoliko mašina, koristeći podatke sa hiljadama terabajta. Takođe nudi fleksibilnost obrade podataka koji mogu biti strukturirani, polustrukturirani ili nestrukturirani i bilo kog formata ili veličine.
Jednostavnost
MapReduce programe možete pisati na bilo kom programskom jeziku, kao što su Java, R, Perl, Python i još mnogo toga. Zbog toga je svima lako da nauče i pišu programe, obezbeđujući da se ispune njihovi zahtevi za obradom podataka.
Slučajevi upotrebe MapReduce-a
- Indeksiranje celog teksta: MapReduce se koristi za indeksiranje celog teksta. Njegov Mapper može mapirati svaku reč ili frazu u jednom dokumentu. A Reducer se koristi za upisivanje svih mapiranih elemenata u indeks.
- Izračunavanje ranga stranice: Google koristi MapReduce za izračunavanje ranga stranice.
- Analiza dnevnika: MapReduce može analizirati datoteke dnevnika. Može da razbije veliku datoteku evidencije na različite delove ili podeli, dok mapper traži web stranice kojima se pristupa.
Par ključ-vrednost biće dostavljen reduktoru ako je web stranica uočena u evidenciji. Ovde će web stranica biti ključ, a indeks „1“ je vrednost. Nakon davanja para ključ/vrednost Reducer-u, različite web stranice će biti agregirane. Konačan rezultat je ukupan broj pogodaka za svaku web stranicu.

- Reverse Web-Link Graph: Okvir se takođe koristi u Reverse Web-Link Graph-u. Ovde Map() daje ciljnu URL adresu i izvor, uzimajući ulaz sa izvora ili web stranice.
Zatim, Reduce() agregira listu svakog izvornog URL-a povezanog sa ciljnim URL-om. Konačno, daje izvore i cilj.
- Brojanje reči: MapReduce se koristi za brojanje koliko puta se reč pojavljuje u datom dokumentu.
- Globalno zagrevanje: Organizacije, vlade i kompanije mogu da koriste MapReduce za rešavanje problema globalnog zagrevanja.
Na primer, možda želite da saznate o povećanom nivou temperature okeana zbog globalnog zagrevanja. Za to možete prikupiti hiljade podataka širom sveta. Podaci mogu biti visoka temperatura, niska temperatura, geografska širina, dužina, datum, vreme itd. Ovo će zahtevati nekoliko mapa i smanjenje zadataka za izračunavanje izlaza koristeći MapReduce.
- Ispitivanja lekova: Tradicionalno, naučnici podataka i matematičari su radili zajedno na formulisanju novog leka koji može da se bori protiv bolesti. Uz širenje algoritama i MapReduce-a, IT odeljenja u organizacijama mogu lako da se pozabave problemima kojima su se bavili samo superkompjuteri, dr. naučnici itd. Sada možete da proverite efikasnost leka za grupu pacijenata.
- Druge aplikacije: MapReduce može da obrađuje čak i podatke velikih razmera koji se inače ne uklapaju u relacionu bazu podataka. Takođe koristi alate za nauku o podacima i omogućava njihovo pokretanje preko različitih, distribuiranih skupova podataka, što je ranije bilo moguće samo na jednom računaru.
Kao rezultat robusnosti i jednostavnosti MapReduce-a, on pronalazi primenu u vojsci, biznisu, nauci itd.
Zaključak
MapReduce se može smatrati napretkom u tehnologiji. To nije samo brži i jednostavniji proces, već je i isplativ i oduzima manje vremena. S obzirom na njegove prednosti i sve veću upotrebu, verovatno ćemo svedočiti njegovom većem usvajanju u svim industrijama i organizacijama.
Takođe možete istražiti neke od najboljih resursa za učenje velikih podataka i Hadoop-a.