Апач Паркет представља значајне предности у погледу складиштења и преузимања података у поређењу са традиционалним приступима, попут CSV формата.
Паркет формат је посебно дизајниран за убрзану обраду сложених типова података. У овом чланку ћемо размотрити како Паркет формат одговара савременим захтевима за великим количинама података.
Пре него што детаљније уђемо у спецификације Паркет формата, појаснимо шта су CSV подаци и какве изазове представљају у контексту складиштења података.
Шта је CSV складиште?
Сви смо се сусрели са CSV (вредности раздвојене зарезом) форматом – једним од најраспрострањенијих начина за организацију и форматирање података. CSV складиштење је засновано на редовима. CSV фајлови се чувају са екстензијом .csv. CSV податке можемо складиштити и отварати користећи Excel, Google Sheets, или било који едитор текста. Подаци су јасно видљиви када се фајл отвори.
Међутим, ово није идеално решење за формат базе података.
Поред тога, како се обим података повећава, постаје све теже претраживати, управљати и преузимати податке.
Ево примера података ускладиштених у .CSV фајлу:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
У Excel-у, структура ред-колона изгледа овако:
Проблеми са CSV складиштем
Складишта заснована на редовима, као што је CSV, су прилагођена за операције креирања, ажурирања и брисања.
А шта је са „читањем“ (Read) у CRUD операцијама?
Замислите фајл од милион редова у .csv формату. Било би потребно значајно време да се фајл отвори и пронађу подаци који су потребни. Већина добављача клауд сервиса, попут AWS-а, наплаћује корисницима на основу количине скенираних или ускладиштених података – а CSV фајлови заузимају значајан простор.
CSV складиште нема специфичну опцију за чување метаподатака, што скенирање података чини компликованим задатком.
Дакле, које је ефикасно и оптимално решење за обављање свих CRUD операција? Истражимо.
Шта је складиште података у Паркет формату?
Паркет је формат отвореног кода намењен за складиштење података. Широко је заступљен у Hadoop и Spark екосистемима. Паркет фајлови имају екстензију .parquet.
Паркет је високо структуриран формат. Такође је погодан за оптимизацију сложених, неструктурираних података који се налазе у великим количинама у језерима података. Ово може значајно убрзати време трајања упита.
Паркет чини складиштење података ефикаснијим и убрзава претрагу, користећи комбинацију редног и колонастог формата складиштења (хибрид). У овом формату, подаци су подељени хоризонтално и вертикално. Паркет формат у великој мери елиминише процес рашчлањивања.
Формат смањује укупан број I/O операција, а самим тим и трошкове.
Паркет такође складишти метаподатке који садрже информације о подацима, као што су шема података, број вредности, локације колона, минимална и максимална вредност, број група редова, тип кодирања, итд. Метаподаци су сачувани на различитим нивоима у фајлу, што убрзава приступ подацима.
У приступу заснованом на редовима, као што је CSV, преузимање података захтева време, јер упит мора да прође кроз сваки ред да би пронашао одређене вредности колоне. Код складиштења у Паркет формату, свим потребним колонама се може приступити истовремено.
Укратко:
- Паркет користи колонасту структуру за складиштење података.
- Представља оптимизован формат података за чување великих количина сложених података у системима за складиштење.
- Паркет формат укључује различите методе за компресију и кодирање података.
- Значајно смањује време скенирања података и време трајања упита, заузимајући мање простора на диску у поређењу са другим форматима складиштења, као што је CSV.
- Минимизира број I/O операција, смањујући трошкове складиштења и извршења упита.
- Садржи метаподатке који олакшавају претрагу података.
- Пружа подршку отвореног кода.
Структура података у Паркет формату
Пре него што пређемо на пример, детаљније ћемо размотрити како се подаци чувају у Паркет формату:
У једном фајлу може бити више хоризонталних партиција, познатих као групе редова. Унутар сваке групе редова примењује се вертикална партиција. Колоне су подељене на делове колона. Подаци се чувају као странице унутар делова колона. Свака страница садржи вредности кодираних података и метаподатке. Као што је раније напоменуто, метаподаци за цео фајл се чувају на крају фајла, на нивоу групе редова.
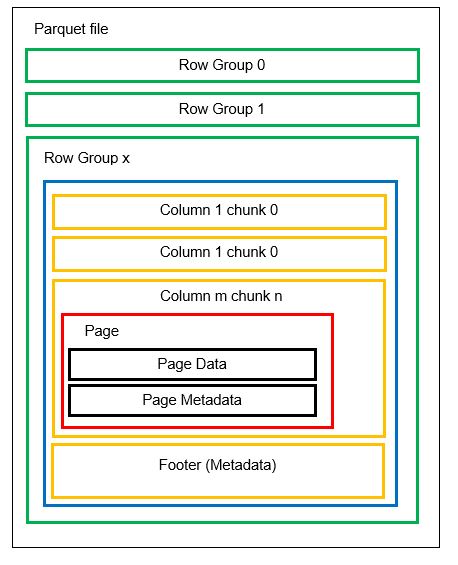
Пошто су подаци подељени у делове колона, додавање нових података је једноставно, кодирањем нових вредности у нови део и фајл. Метаподаци се затим ажурирају за дотичне фајлове и групе редова. Стога, Паркет се може сматрати флексибилним форматом.
Паркет изворно подржава компресију података користећи компресију страница и технике кодирања речника. Размотримо једноставан пример компресије речника:
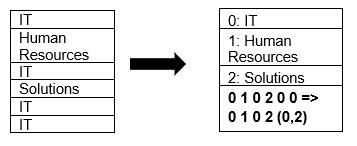
Приметимо да се у горњем примеру ИТ одељење појављује четири пута. Када се подаци чувају у речнику, формат кодира податке користећи другу вредност, која се лако чува (0,1,2…) заједно са бројем појављивања – ИТ, ИТ се мења у 0,2 ради уштеде простора. Упит за компримоване податке се извршава брже.
Упоредно поређење
Сада када имамо основно разумевање CSV и Паркет формата, време је да упоредимо статистике ова два формата:
| CSV | Паркет |
| Формат складиштења заснован на редовима. | Хибрид редног и колонастог формата складиштења. |
| Заузима више простора због недостатка подразумеване опције компресије. На пример, фајл од 1ТБ ће заузети исти простор када се чува на Amazon S3 или другом клауд сервису. | Компримује податке током складиштења и тако троши мање простора. Фајл од 1ТБ сачуван у Паркет формату заузима само 130ГБ простора. |
| Време извршења упита је споро због претраге засноване на редовима. За сваку колону мора се преузети сваки ред података. | Време трајања упита је око 34 пута брже захваљујући складиштењу заснованом на колонама и метаподацима. |
| Више података се мора скенирати по упиту. | Око 99% мање података се скенира за извршење упита, што оптимизује учинак. |
| Већина уређаја за складиштење наплаћује се на основу простора за складиштење, што значи да CSV формат доводи до високих трошкова складиштења. | Мањи трошкови складиштења јер се подаци чувају у компримованом, кодираном формату. |
| Шема фајла мора бити или закључена (што доводи до грешака) или достављена (што је заморно). | Шема фајла се чува у метаподацима. |
| Формат је погодан за једноставне типове података. | Паркет је погодан чак и за сложене типове, као што су угнежђене шеме, низови и речници. |
Закључак 👩💻
Приказали смо низ примера који показују да је Паркет ефикаснији од CSV формата у погледу трошкова, флексибилности и перформанси. Представља ефикасан механизам за складиштење и преузимање података, посебно у свету који се креће ка складиштењу у клауду и оптимизацији простора. Све главне платформе, као што су Azure, AWS и BigQuery, подржавају Паркет формат.