Informacije su ključni element poslovanja i organizacija, a njihova vrednost dolazi do izražaja tek kada su pravilno uređene i kada se njima efikasno upravlja.
Statistički podaci pokazuju da čak 95% kompanija danas smatra da je upravljanje i strukturiranje neobrađenih podataka izazov.
Tu na scenu stupa rudarenje podataka. To je proces prepoznavanja, analize i izdvajanja smislenih šablona i korisnih informacija iz velikih baza neuređenih podataka.
Kompanije koriste softvere za identifikaciju šablona u velikim skupovima podataka kako bi stekle bolji uvid u svoje klijente i ciljnu grupu, te razvile poslovne i marketinške strategije za unapređenje prodaje i smanjenje troškova.
Pored ovih prednosti, otkrivanje prevara i anomalija predstavlja jednu od najvažnijih primena rudarenja podataka.
Ovaj članak će objasniti koncept detekcije anomalija i analizirati kako ona može pomoći u sprečavanju zloupotrebe podataka i upada u mrežu, osiguravajući sigurnost informacija.
Šta je detekcija anomalija i koji su njeni tipovi?
Dok rudarenje podataka podrazumeva pronalazak veza, korelacija i trendova koji su međusobno povezani, ono predstavlja i odličan način za pronalaženje anomalija ili izuzetaka u podacima unutar mreže.
Anomalije u rudarenju podataka predstavljaju tačke podataka koje se razlikuju od ostalih u skupu podataka i odstupaju od uobičajenog obrasca ponašanja celog skupa.
Anomalije se mogu klasifikovati u različite vrste i kategorije, uključujući:
- Promene u događajima: Odnose se na iznenadne ili sistemske promene u odnosu na prethodno uobičajeno ponašanje.
- Autlajeri: Mali anomalni obrasci koji se pojavljuju nesistematski u okviru prikupljenih podataka. Mogu se dalje klasifikovati kao globalni, kontekstualni i kolektivni.
- Pomeraji: Postepena, neusmerena i dugoročna promena u skupu podataka.
Dakle, detekcija anomalija je tehnika obrade podataka koja je veoma korisna za otkrivanje lažnih transakcija, rešavanje studija slučaja sa visokim disbalansom i otkrivanje bolesti za izgradnju pouzdanih modela u nauci o podacima.
Na primer, kompanija može želeti da analizira svoj novčani tok kako bi pronašla neuobičajene ili ponavljajuće transakcije na nepoznatom bankovnom računu, kako bi otkrila potencijalnu prevaru i pokrenula dalju istragu.
Prednosti detekcije anomalija
Detekcija anomalija u ponašanju korisnika pomaže u jačanju sigurnosnih sistema i čini ih preciznijim.
Ova tehnika analizira i tumači različite informacije koje sigurnosni sistemi pružaju kako bi identifikovala pretnje i moguće rizike unutar mreže.
Evo prednosti detekcije anomalija za kompanije:
- Otkrivanje sajber pretnji i zloupotrebe podataka u realnom vremenu, zahvaljujući algoritmima veštačke inteligencije koji neprekidno skeniraju podatke u potrazi za neobičnim ponašanjem.
- Olakšava i ubrzava praćenje neuobičajenih aktivnosti i obrazaca u odnosu na ručno otkrivanje anomalija, smanjujući vreme i trud potreban za rešavanje pretnji.
- Smanjuje operativne rizike identifikujući greške u radu, kao što su nagli padovi performansi, pre nego što se jave.
- Pomaže u sprečavanju većih poslovnih šteta brzim otkrivanjem anomalija, jer bez sistema za detekciju anomalija, kompanijama mogu biti potrebne nedelje ili meseci da identifikuju potencijalne pretnje.
Detekcija anomalija predstavlja veliku prednost za preduzeća koja čuvaju obimne skupove podataka o klijentima i poslovnim informacijama, pomažući im da pronađu mogućnosti za rast i eliminišu sigurnosne pretnje i operativne uske tačke.
Tehnike detekcije anomalija
Detekcija anomalija koristi nekoliko procedura i algoritama mašinskog učenja (ML) za praćenje podataka i otkrivanje potencijalnih pretnji.
Glavne tehnike za otkrivanje anomalija uključuju:
#1. Tehnike mašinskog učenja

Tehnike mašinskog učenja koriste ML algoritme za analizu podataka i otkrivanje anomalija. Različite vrste algoritama mašinskog učenja za detekciju anomalija uključuju:
- Algoritmi grupisanja
- Algoritmi klasifikacije
- Algoritmi dubokog učenja
Najčešće korišćene ML tehnike za otkrivanje anomalija i pretnji obuhvataju mašine sa vektorskom podrškom (SVM), k-means klasterisanje i autoenkodere.
#2. Statističke tehnike
Statističke tehnike koriste statističke modele za otkrivanje neobičnih obrazaca (kao što su neuobičajene fluktuacije u performansama određenog uređaja) u podacima, kako bi se izdvojile vrednosti koje su izvan opsega očekivanih vrednosti.
Uobičajene tehnike za otkrivanje statističkih anomalija obuhvataju testiranje hipoteza, IQR, Z-skor, modifikovani Z-skor, procenu gustine, boxplot, analizu ekstremnih vrednosti i histogram.
#3. Tehnike rudarenja podataka

Tehnike rudarenja podataka koriste klasifikaciju i grupisanje podataka za pronalaženje anomalija u okviru skupa podataka. Neke uobičajene tehnike rudarenja podataka za detekciju anomalija uključuju spektralno grupisanje, klasterisanje zasnovano na gustini i analizu glavnih komponenti.
Algoritmi za klasterisanje podataka se koriste za grupisanje različitih tačaka podataka u klastere na osnovu njihove sličnosti, kako bi se pronašle tačke podataka i anomalije koje se ne uklapaju u te klastere.
S druge strane, algoritmi klasifikacije dodeljuju tačke podataka određenim unapred definisanim klasama i identifikuju tačke podataka koje ne pripadaju tim klasama.
#4. Tehnike zasnovane na pravilima
Kao što ime sugeriše, tehnike detekcije anomalija zasnovane na pravilima koriste skup unapred definisanih pravila za pronalazak anomalija u podacima.
Ove tehnike se relativno lako postavljaju i jednostavne su, ali mogu biti nefleksibilne i možda neće biti efikasne u prilagođavanju promenljivom ponašanju i obrascima podataka.
Na primer, možete lako programirati sistem zasnovan na pravilima da označi transakcije koje premašuju određeni novčani iznos kao sumnjive.
#5. Tehnike specifične za domen
Možete koristiti tehnike specifične za domen da biste otkrili anomalije u određenim sistemima podataka. Iako mogu biti veoma efikasne u detekciji anomalija u određenim oblastima, mogu biti manje efikasne u drugim oblastima izvan tog konteksta.
Na primer, koristeći tehnike specifične za domen, možete dizajnirati tehnike posebno za pronalaženje anomalija u finansijskim transakcijama, ali one možda neće raditi za pronalaženje anomalija ili padova u performansama neke mašine.
Potreba za mašinskim učenjem za detekciju anomalija
Mašinsko učenje je od izuzetne važnosti i koristi u otkrivanju anomalija.
Danas, većina kompanija i organizacija koje žele da otkriju neuobičajene vrednosti obrađuju ogromne količine podataka, od teksta, informacija o klijentima i transakcija, do multimedijalnih datoteka kao što su slike i video snimci.
Ručno pregledanje svih bankarskih transakcija i podataka koji se generišu svake sekunde kako bi se dobio smisleni uvid je gotovo nemoguće. Pored toga, većina kompanija se suočava sa izazovima i poteškoćama u strukturiranju neuređenih podataka i njihovom organizovanju na način koji omogućava efikasnu analizu.
U tom kontekstu, alati i tehnike kao što je mašinsko učenje (ML) igraju ključnu ulogu u prikupljanju, čišćenju, strukturiranju, organizaciji, analizi i skladištenju ogromnih količina neobrađenih podataka.
Tehnike i algoritmi mašinskog učenja obrađuju velike skupove podataka i nude fleksibilnost za korišćenje i kombinovanje različitih tehnika i algoritama kako bi se postigli najbolji rezultati.
Osim toga, mašinsko učenje pomaže da se pojednostave procesi detekcije anomalija u stvarnim aplikacijama i štede vredne resurse.
Evo dodatnih prednosti i važnosti mašinskog učenja u detekciji anomalija:
- Olakšava otkrivanje anomalija u velikom obimu, automatizujući identifikaciju obrazaca i anomalija bez potrebe za eksplicitnim programiranjem.
- Algoritmi mašinskog učenja se lako prilagođavaju promenama u obrascima skupova podataka, što ih čini veoma efikasnim i pouzdanim tokom vremena.
- Lako upravljaju velikim i složenim skupovima podataka, čineći detekciju anomalija efikasnom uprkos složenosti podataka.
- Osiguravaju ranu identifikaciju i otkrivanje anomalija, pronalazeći ih u trenutku kada se dešavaju, što štedi vreme i resurse.
- Sistemi za detekciju anomalija zasnovani na mašinskom učenju pomažu u postizanju višeg nivoa tačnosti u poređenju sa tradicionalnim metodama.
Stoga, detekcija anomalija u kombinaciji sa mašinskim učenjem pomaže u bržem i ranijem otkrivanju anomalija kako bi se sprečile sigurnosne pretnje i zlonamerni upadi.
Algoritmi mašinskog učenja za detekciju anomalija
Možete otkriti anomalije i odstupanja u podacima uz pomoć različitih algoritama rudarenja podataka za klasifikaciju, grupisanje ili učenje pravila asocijacije.
Obično su ovi algoritmi za rudarenje podataka podeljeni u dve različite kategorije: algoritmi učenja pod nadzorom i algoritmi učenja bez nadzora.
Učenje pod nadzorom
Učenje pod nadzorom je uobičajen tip algoritma koji se sastoji od algoritama kao što su mašine sa vektorskom podrškom, logistička i linearna regresija i klasifikacija u više klasa. Ovaj tip algoritma se trenira na obeleženim podacima, što znači da njegov skup podataka za trening uključuje i uobičajene ulazne podatke i odgovarajuće ispravne izlazne ili anomalne primere, za konstruisanje prediktivnog modela.
Dakle, cilj mu je da kreira predikcije izlaza za neviđene i nove podatke, na osnovu obrazaca u skupu podataka za trening. Primene algoritama za učenje pod nadzorom uključuju prepoznavanje slika i govora, prediktivno modeliranje i obradu prirodnog jezika (NLP).
Učenje bez nadzora
Učenje bez nadzora se ne trenira na obeleženim podacima. Umesto toga, otkriva kompleksne procese i strukture u podacima bez pružanja smernica algoritmu za treniranje, i ne daje konkretna predviđanja.
Primene algoritama učenja bez nadzora uključuju otkrivanje anomalija, procenu gustine i kompresiju podataka.
Hajde sada da istražimo neke popularne algoritme za otkrivanje anomalija zasnovane na mašinskom učenju.
Lokalni faktor odstupanja (LOF)
Faktor lokalnog odstupanja ili LOF je algoritam za detekciju anomalija koji uzima u obzir gustinu lokalnih podataka kako bi utvrdio da li je neka tačka podataka anomalija.
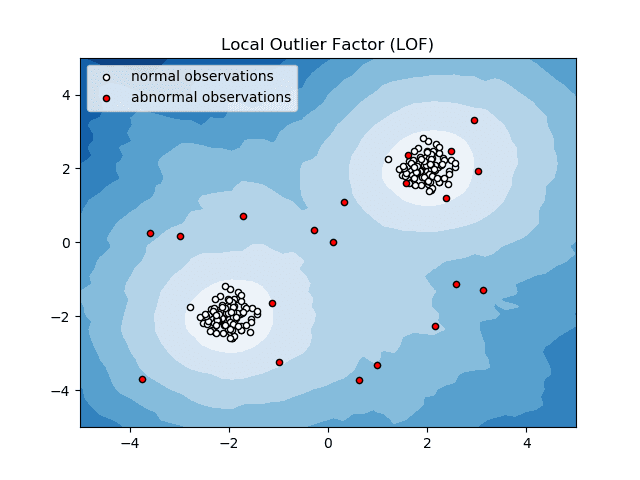 Izvor: scikit-learn.org
Izvor: scikit-learn.org
On upoređuje lokalnu gustinu stavke sa lokalnim gustinama njenih suseda kako bi analizirao oblasti slične gustine i stavke sa relativno nižom gustinom od njihovih suseda, koje predstavljaju anomalije ili odstupanja.
Dakle, jednostavnim rečima, gustina koja okružuje neuobičajenu ili anomalnu stavku se razlikuje od gustine oko njenih suseda. Zbog toga se ovaj algoritam naziva i algoritam za detekciju autlajera zasnovan na gustini.
K-najbliži sused (K-NN)
K-NN je najjednostavniji algoritam za klasifikaciju i detekciju anomalija pod nadzorom, koji je jednostavan za implementaciju. On čuva sve dostupne primere i podatke i klasifikuje nove primere na osnovu sličnosti u metriki udaljenosti.
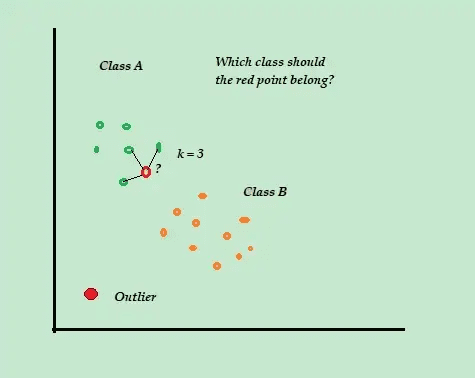 Izvor: todatascience.com
Izvor: todatascience.com
Ovaj algoritam klasifikacije se takođe naziva lenji učenik jer čuva samo označene podatke za obuku i ne radi ništa više tokom procesa obuke.
Kada stigne nova neoznačena tačka podataka za obuku, algoritam analizira K-najbliže tačke podataka za obuku kako bi ih iskoristio za klasifikaciju i određivanje klase nove neoznačene tačke podataka.
K-NN algoritam koristi sledeće metode detekcije za određivanje najbližih tačaka podataka:
- Euklidsko rastojanje za merenje udaljenosti za kontinuirane podatke.
- Hemingova udaljenost za merenje blizine dva tekstualna niza za diskretne podatke.
Na primer, pretpostavimo da se vaši skupovi podataka za trening sastoje od dve oznake klase, A i B. Ako stigne nova tačka podataka, algoritam će izračunati rastojanje između nove tačke i svake tačke u skupu podataka i odabrati tačke koje su najbliže novoj tački.
Dakle, pretpostavimo da je K=3, i 2 od 3 tačke podataka su označene kao A, onda je nova tačka označena kao klasa A.
Stoga, K-NN algoritam najbolje funkcioniše u dinamičkim okruženjima sa čestim zahtevima za ažuriranje podataka.
Ovo je popularan algoritam za detekciju anomalija i rudarenje teksta, sa primenama u finansijama i poslovanju za otkrivanje lažnih transakcija i povećanje stope otkrivanja prevara.
Mašina za vektorsku podršku (SVM)
Mašina sa vektorskom podrškom je algoritam za otkrivanje anomalija pod nadzorom, zasnovan na mašinskom učenju, koji se uglavnom koristi u problemima regresije i klasifikacije.
Ovaj algoritam koristi višedimenzionalnu hiperravan za razdvajanje podataka u dve grupe (nove i uobičajene). Dakle, hiperravan deluje kao granica odluke koja razdvaja normalna posmatranja podataka i nove podatke.
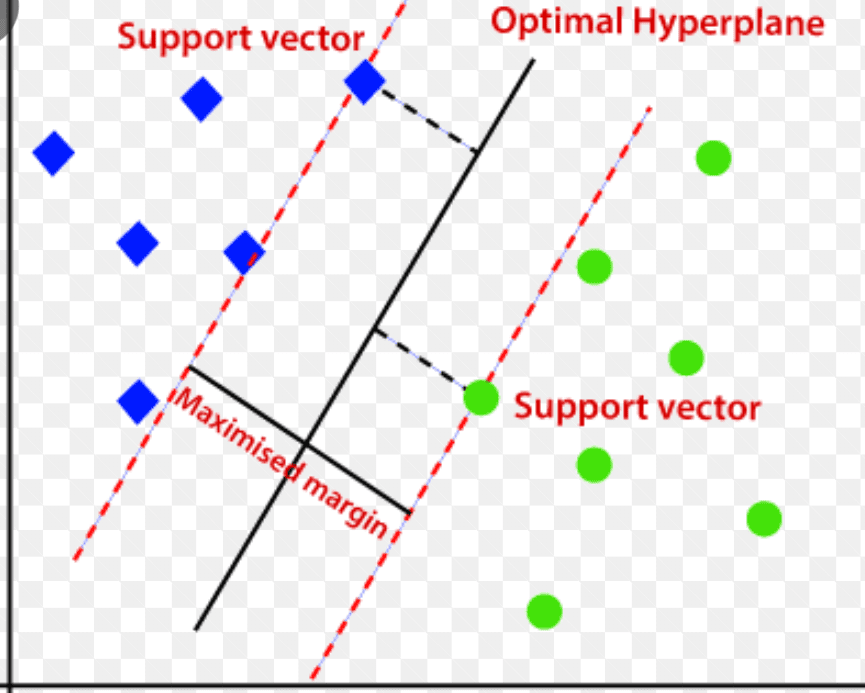 Izvor: www.analyticsvidhya.com
Izvor: www.analyticsvidhya.com
Udaljenost između ove dve tačke podataka se naziva marginom.
Pošto je cilj da se poveća rastojanje između dve tačke, SVM određuje najbolju ili optimalnu hiperravan sa maksimalnom marginom kako bi se osiguralo što veće rastojanje između dve klase.
Kada je u pitanju detekcija anomalija, SVM izračunava marginu posmatranja nove tačke podataka u odnosu na hiperravan, kako bi je klasifikovao.
Ako margina premašuje zadati prag, algoritam klasifikuje novo posmatranje kao anomaliju. Istovremeno, ako je margina manja od praga, posmatranje se klasifikuje kao normalno.
Dakle, SVM algoritmi su veoma efikasni u rukovanju visoko-dimenzionalnim i složenim skupovima podataka.
Izolacioni šuma
Izolacioni šuma je algoritam za detekciju anomalija bez nadzora, zasnovan na konceptu klasifikatora slučajnih šuma.
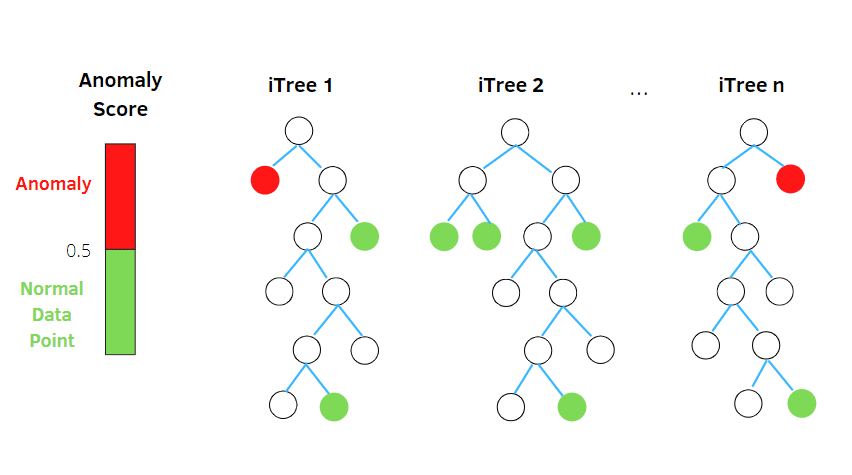 Izvor: betterprogramming.pub
Izvor: betterprogramming.pub
Ovaj algoritam obrađuje nasumično poduzorkovane podatke u skupu podataka u strukturi stabla, na osnovu nasumičnih atributa. Konstruiše nekoliko stabala odlučivanja kako bi izolovao posmatranja. Određeno posmatranje se smatra anomalijom ako je izolovano u manjem broju stabala na osnovu stope kontaminacije.
Jednostavno rečeno, algoritam izolacione šume deli tačke podataka u različita stabla odlučivanja, obezbeđujući da svako posmatranje bude izolovano od ostalih.
Anomalije se obično nalaze dalje od klastera tačaka podataka, što olakšava njihovu identifikaciju u poređenju sa normalnim tačkama podataka.
Algoritmi izolacione šume lako upravljaju kategoričkim i numeričkim podacima. Kao rezultat toga, brži su za obuku i veoma efikasni u otkrivanju anomalija u visokodimenzionalnim i velikim skupovima podataka.
Interkvartilni raspon
Interkvartilni raspon ili IQR se koristi za merenje statističke varijabilnosti ili disperzije, kako bi se pronašle anomalne tačke u skupovima podataka tako što će se podeliti na kvartile.
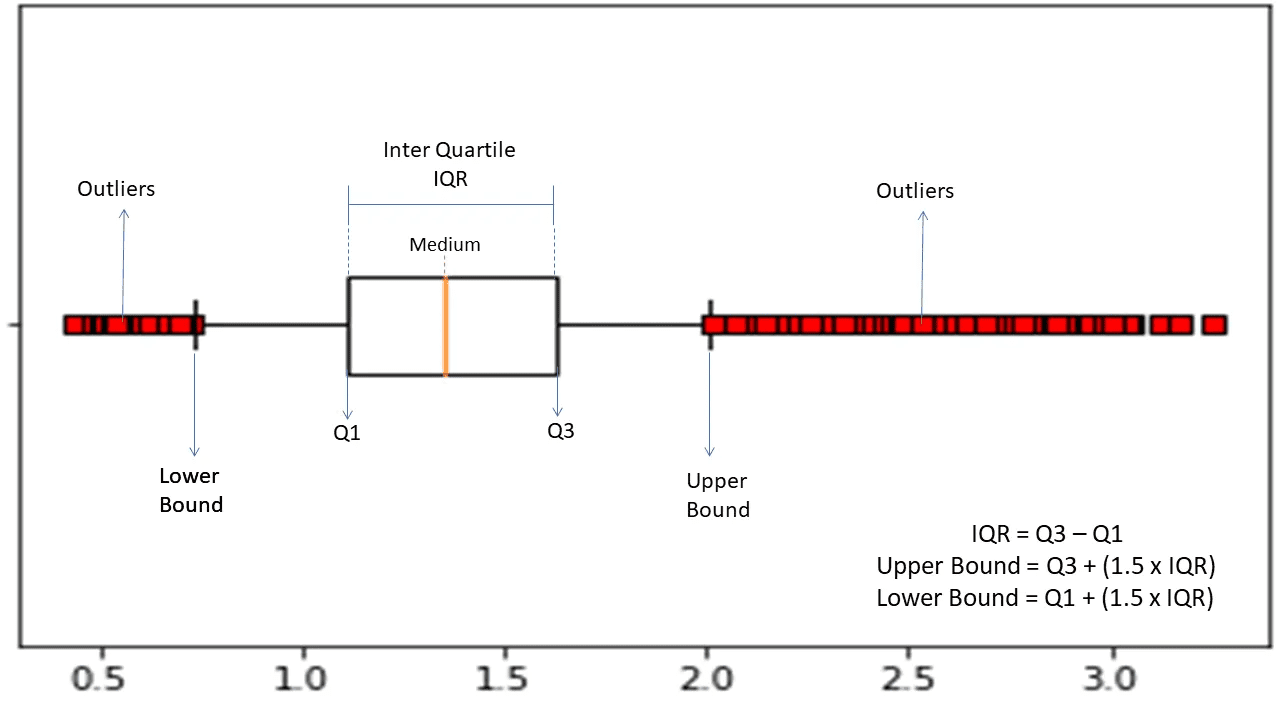 Izvor: morioh.com
Izvor: morioh.com
Algoritam sortira podatke u rastućem redosledu i deli skup na četiri jednaka dela. Vrednosti koje razdvajaju ove delove su Q1, Q2 i Q3, tj. prvi, drugi i treći kvartil.
Evo procentualne distribucije ovih kvartila:
- Q1 označava 25. percentil podataka.
- Q2 označava 50. percentil podataka.
- Q3 označava 75. percentil podataka.
IQR je razlika između trećeg (75.) i prvog (25.) percentila podataka, koja predstavlja 50% podataka.
Korišćenje IQR-a za detekciju anomalija zahteva izračunavanje IQR-a vašeg skupa podataka i definisanje donje i gornje granice podataka za pronalaženje anomalija.
- Donja granica: Q1 – 1,5 * IQR
- Gornja granica: Q3 + 1,5 * IQR
Obično se posmatranja koja su izvan ovih granica smatraju anomalijama.
IQR algoritam je efikasan za skupove podataka sa neravnomerno raspoređenim podacima i gde distribucija nije dobro definisana.
Zaključak
Čini se da se rizici za sajber bezbednost i zloupotrebu podataka neće smanjiti u narednim godinama, i očekuje se dalji rast ove rizične industrije u 2023. godini. Očekuje se da će se samo IoT sajber napadi udvostručiti do 2025.
Osim toga, sajber kriminal će koštati globalne kompanije i organizacije procenjenih 10,3 biliona dolara godišnje do 2025.
Stoga, potreba za tehnikama detekcije anomalija danas postaje sve veća i neophodna za otkrivanje prevara i sprečavanje upada u mrežu.
Ovaj članak će vam pomoći da razumete šta su anomalije u rudarenju podataka, koje su njihove različite vrste i kako sprečiti upade u mrežu korišćenjem tehnika detekcije anomalija zasnovanih na mašinskom učenju.
Zatim možete istražiti sve o matrici konfuzije u mašinskom učenju.