Tekst sa slika možete izvući pomoću Tesseract OCR alata direktno iz Linux komandne linije. Ovaj alat je brz, precizan i podržava oko 100 različitih jezika. U nastavku teksta ćemo objasniti kako se on koristi.
Optičko prepoznavanje znakova
Optičko prepoznavanje znakova (OCR) je sposobnost da se na slici identifikuju i pronađu reči, a zatim da se one pretvore u tekst koji se može uređivati. Iako je ovo ljudima jednostavan zadatak, računarima predstavlja veliki izazov. Rani pokušaji su bili nespretni, blago rečeno. Računari su često bili zbunjeni ako font ili veličina teksta nisu bili po standardima OCR softvera.
Međutim, pioniri u ovoj oblasti su bili visoko cenjeni. Ako biste izgubili elektronsku verziju dokumenta, a imali ste samo štampanu, OCR je mogao da ponovo kreira elektronsku verziju koja se može menjati. Čak i ako rezultati nisu bili 100% tačni, to je ipak predstavljalo značajnu uštedu vremena.
Uz malo ručnog uređivanja, dokument bi bio vraćen u elektronski oblik. Ljudi su tolerisali greške jer su razumeli kompleksnost zadatka sa kojim se OCR paket suočavao. Pored toga, to je bilo bolje rešenje nego da se ceo dokument prekucava ručno.
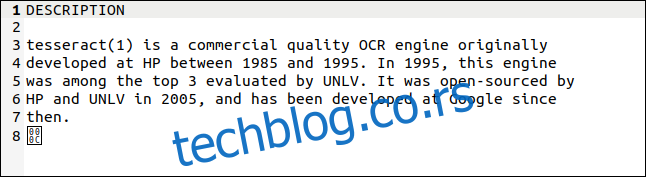
Od tada se situacija značajno popravila. Tesseract OCR aplikaciju je razvio Hewlett Packard tokom 1980-ih godina kao komercijalnu primenu. Postala je open-source 2005. godine, a sada je podržava Google. Poseduje višejezičke mogućnosti i smatra se jednim od najpreciznijih OCR sistema, a dostupan je za besplatno korišćenje.
Instalacija Tesseract OCR-a
Da biste instalirali Tesseract OCR na Ubuntu sistemu, koristite sledeću komandu:
sudo apt-get install tesseract-ocr

Na Fedori, komanda je:
sudo dnf install tesseract

Na Manjaro sistemima, potrebno je da unesete sledeću komandu:
sudo pacman -Syu tesseract

Korišćenje Tesseract OCR-a
Pred Tesseract OCR postavićemo nekoliko izazova. Prva slika sa tekstom koju ćemo koristiti je isečak iz uvodne izjave 63 Opštih propisa o zaštiti podataka. Da vidimo da li OCR može da pročita ovo (i da ostane budan).

Ovo je malo komplikovana slika jer svaka rečenica počinje slabim nadređenim brojem, što je tipično za pravne dokumente.
Potrebno je da komandi Tesseract prosledimo određene informacije, uključujući:
- Naziv datoteke slike koju želimo da obradimo.
- Naziv tekstualne datoteke koju će kreirati za čuvanje ekstrahovanog teksta. Ne moramo da navodimo ekstenziju datoteke (uvek će biti .txt). Ako datoteka sa istim imenom već postoji, ona će biti zamenjena.
- Možemo koristiti opciju –dpi da kažemo Tesseract-u koja je rezolucija u tačkama po inču (dpi) slike. Ako ne navedemo vrednost dpi, Tesseract će pokušati da je sam odredi.
Naša slikovna datoteka se zove „recital-63.png“, a njena rezolucija je 150 dpi. Kreiraćemo tekstualnu datoteku pod nazivom „recital.txt“.
Naša komanda će izgledati ovako:
tesseract recital-63.png recital --dpi 150

Rezultati su prilično dobri. Jedini problem su nadređeni brojevi – oni su bili suviše bledi da bi bili pravilno pročitani. Kvalitet slike je od izuzetne važnosti za postizanje dobrih rezultata.

Tesseract je protumačio brojeve iznad indeksa kao navodnike (“) i simbole stepena (°), ali je stvarni tekst izvučen savršeno (desna strana slike je morala da bude isečena da bi stala ovde).
Poslednji znak je bajt sa heksadecimalnom vrednošću 0x0C, što je znak za prelazak u novi red.
Ispod je još jedna slika sa tekstom različitih veličina, i podebljanim i iskošenim slovima.

Ova datoteka se zove „bold-italic.png“. Želimo da kreiramo tekstualnu datoteku pod nazivom „bold.txt“, tako da naša komanda glasi:
tesseract bold-italic.png bold --dpi 150

Ova slika nije predstavljala nikakav problem, a tekst je izvučen savršeno.
Korišćenje različitih jezika
Tesseract OCR podržava oko 100 jezika. Da biste koristili određeni jezik, prvo ga morate instalirati. Kada na listi pronađete jezik koji želite da koristite, obratite pažnju na njegovu skraćenicu. Mi ćemo instalirati podršku za velški jezik. Njegova skraćenica je „cym“, što je skraćenica od „Cymru“, što znači velški.
Instalacioni paket se zove „tesseract-ocr-“ sa skraćenicom jezika na kraju. Da bismo instalirali jezički paket za velški jezik na Ubuntu, koristićemo:
sudo apt-get install tesseract-ocr-cym

Slika sa tekstom je ispod. To je prvi stih velške himne.

Da vidimo da li je Tesseract OCR dorastao ovom izazovu. Koristićemo opciju -l (jezik) da Tesseract-u kažemo na kom jeziku želimo da radimo:
tesseract hen-wlad-fy-nhadau.png anthem -l cym --dpi 150

Tesseract je odradio odličan posao, kao što se može videti u izvučenom tekstu ispod. Da iawn, Tesseract OCR.

Ako vaš dokument sadrži dva ili više jezika (kao što je rečnik velško-engleskog, na primer), možete koristiti znak plus (+) da kažete Tesseract-u da doda još jedan jezik, na primer:
tesseract image.png textfile -l eng+cym+fra
Korišćenje Tesseract OCR-a sa PDF dokumentima
Komanda Tesseract je dizajnirana da radi sa datotekama slika, ali ne može da čita PDF dokumente. Međutim, ako je potrebno izvući tekst iz PDF-a, možete prvo koristiti drugi alat za generisanje skupa slika. Svaka slika će predstavljati jednu stranicu PDF-a.
Alat koji vam je potreban, pdftoppm, verovatno je već instaliran na vašem Linux računaru. PDF koji ćemo koristiti za naš primer je kopija originalnog rada Alana Tjuringa o veštačkoj inteligenciji, „Računarska mašina i inteligencija“.

Koristimo opciju -png da naznačimo da želimo da kreiramo PNG datoteke. Naziv datoteke našeg PDF-a je „turing.pdf“. Naše slikovne datoteke će se zvati „turing-01.png“, „turing-02.png“ i tako dalje:
pdftoppm -png turing.pdf turing

Da bismo pokrenuli Tesseract na svakoj datoteci slike pomoću jedne komande, moramo koristiti for petlju. Za svaku od naših datoteka „turing-nn.png“, pokrećemo Tesseract i kreiramo tekstualnu datoteku pod nazivom „text-“ plus „turing-nn“ kao deo naziva datoteke slike:
for i in turing-??.png; do tesseract "$i" "text-$i" -l eng; done;

Da bismo kombinovali sve tekstualne datoteke u jednu, možemo koristiti cat:
cat text-turing* > complete.txt

Vertikalni vodeni žig je transkribovan kao red besmislica na dnu stranice. Tekst je bio suviše mali da bi ga Tesseract tačno pročitao, ali bi ga bilo dovoljno lako pronaći i izbrisati. Najgori ishod bi bili zalutali znakovi na kraju svakog reda.
Zanimljivo je da su pojedinačna slova na početku liste pitanja i odgovora na drugoj strani ignorisana. Odeljak iz PDF-a je prikazan ispod.

Kao što možete videti u nastavku, pitanja su ostala, ali su „Q“ i „A“ na početku svakog reda izgubljeni.

Dijagrami takođe neće biti pravilno transkribovani. Pogledajmo šta se dešava kada pokušamo da izvučemo prikazani dijagram iz Tjuringovog PDF-a.

Kao što možete videti u našem rezultatu ispod, znakovi su pročitani, ali je format dijagrama izgubljen.

Tesseract se ponovo borio sa malom veličinom indeksa, i oni su pogrešno prikazani.
Iskreno rečeno, to je bio dobar rezultat. Nismo bili u mogućnosti da izdvojimo jednostavan tekst, ali je ovaj primer namerno odabran jer je predstavljao izazov.
Dobro rešenje kada vam zatreba
OCR nije nešto što ćete morati da koristite svakodnevno. Međutim, kada se ukaže potreba, dobro je znati da imate jedan od najboljih OCR motora na raspolaganju.