Tokom proteklih godina, upotreba Pajtona u oblasti nauke o podacima doživela je izuzetan rast, i ta tendencija se nastavlja svakodnevno.
Nauka o podacima predstavlja obimno polje istraživanja sa mnogim specifičnim oblastima. Analiza podataka se ističe kao jedna od ključnih disciplina. Bez obzira na stepen stručnosti u ovoj oblasti, razumevanje osnova analize podataka postaje sve neophodnije.
Šta je analiza podataka?
Analiza podataka obuhvata proces čišćenja i transformisanja obimnih količina nestrukturiranih ili neorganizovanih podataka. Cilj je generisanje relevantnih uvida i informacija koje će olakšati donošenje informisanih odluka.
Postoji niz alata koji se koriste za analizu podataka, uključujući Pajton, Majkrosoft Eksel, Tableu, SAS i druge. U ovom članku fokusiraćemo se na primenu analize podataka koristeći Pajton, konkretno sa bibliotekom pod nazivom Pandas.
Šta je Pandas?
Pandas je biblioteka otvorenog koda, bazirana na Pajtonu, namenjena manipulaciji i obradi podataka. Ona omogućava efikasan i brz rad, sa alatima za učitavanje različitih tipova podataka u memoriju. Može se koristiti za preoblikovanje, selekciju, indeksiranje, pa čak i grupisanje podataka različitih formata.
Strukture podataka u Pandas-u
U Pandas-u postoje tri osnovne strukture podataka:
Najlakše je zamisliti ove strukture tako da jedna sadrži više slojeva druge. Dakle, DataFrame je skup serija, a Panel je skup DataFrame-ova.
Serija je jednodimenzionalni niz.
Kombinacija više serija formira dvodimenzionalni DataFrame.
Kombinacija više DataFrame-ova formira trodimenzionalni Panel.
Najčešće korišćena struktura podataka je dvodimenzionalni DataFrame, koji se često koristi kao standardni način predstavljanja skupova podataka.
Analiza podataka uz pomoć Pandas-a
Za potrebe ovog članka, nije potrebna posebna instalacija. Koristićemo alat pod nazivom Colab, razvijen od strane kompanije Google. To je online Pajton okruženje za analizu podataka, mašinsko učenje i veštačku inteligenciju. Radi se o Jupyter notebook-u baziranom na oblaku, koji već dolazi sa instaliranim gotovo svim potrebnim Pajton paketima za nauku o podacima.
Sada, posetite https://colab.research.google.com/notebooks/intro.ipynb. Trebalo bi da vidite prikaz sličan onome ispod.
U gornjem levom uglu, kliknite na „File“ (Datoteka), a zatim na „New notebook“ (Nova sveska). Otvoriće se nova Jupyter sveska u vašem pretraživaču. Prvo što treba da uradimo je da uvezemo Pandas u naše radno okruženje. To se postiže pokretanjem sledećeg koda:
import pandas as pd
Za ovu demonstraciju, koristimo skup podataka o cenama kuća. Skup podataka koji koristimo možete pronaći ovde. Prvi korak je učitavanje ovog skupa podataka u naše okruženje.
To se radi pomoću sledećeg koda u novoj ćeliji:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
Funkcija .read_csv se koristi za čitanje CSV datoteke, a argument sep specificira da je CSV datoteka razdvojena zarezima.
Takođe, primetimo da se učitana CSV datoteka čuva u promenljivoj df.
U Jupyter svesci, nije neophodno koristiti funkciju print(). Možemo jednostavno uneti naziv promenljive u ćeliju i Jupyter Notebook će ispisati njen sadržaj.
Probajte da unesete df u novu ćeliju i pokrenete je. Ispisaće sve podatke iz našeg skupa kao DataFrame.
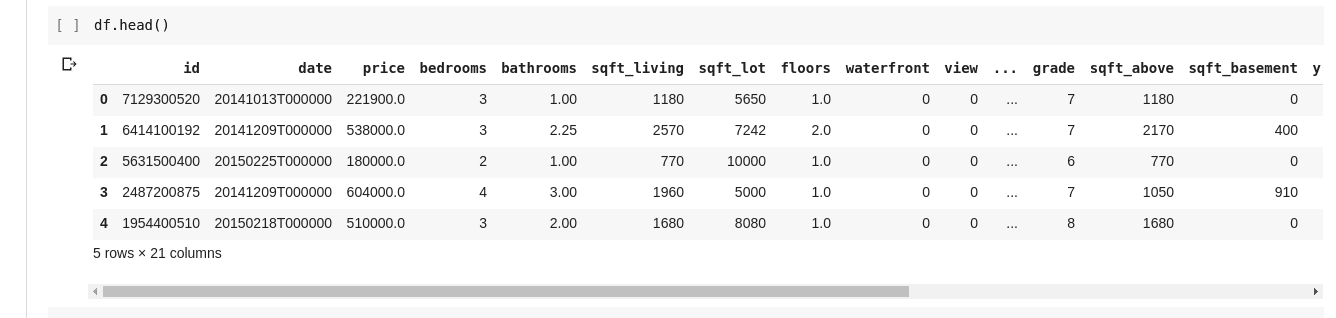
Međutim, nije uvek poželjno videti sve podatke. Ponekad je dovoljno prikazati samo nekoliko prvih redova i imena kolona. Funkcija df.head() prikazuje prvih pet redova, dok df.tail() prikazuje poslednjih pet. Rezultat bilo koje od ovih funkcija izgledaće otprilike ovako:
Korisno je ispitati statističke veze između redova i kolona podataka. Funkcija .describe() je idealna za to.
Pokretanje df.describe() daje sledeći rezultat:
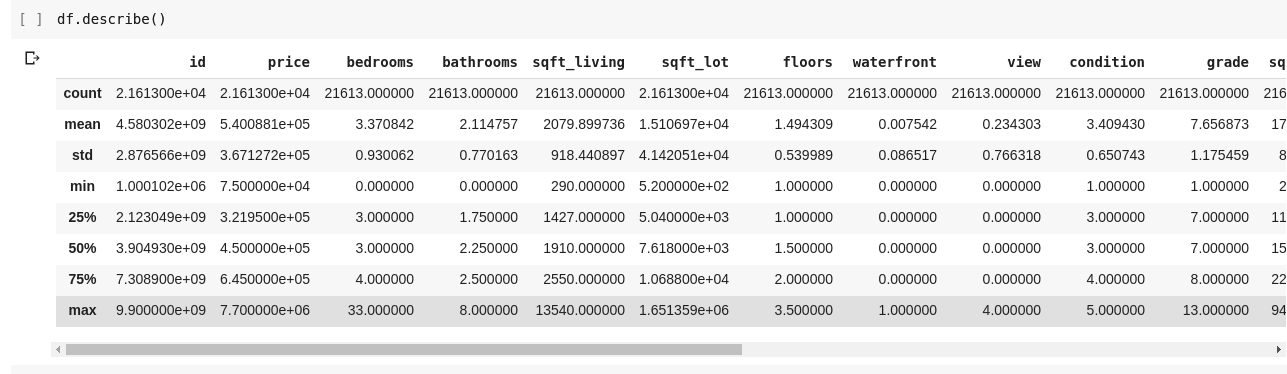
Možemo odmah primetiti da .describe() izračunava srednju vrednost, standardnu devijaciju, minimalne i maksimalne vrednosti, kao i percentile za svaku kolonu u DataFrame-u. Ovo je veoma korisno.
Takođe, možemo proveriti oblik našeg dvodimenzionalnog okvira podataka (DataFrame) da bismo saznali broj redova i kolona. To se postiže pomoću df.shape, koja vraća torku (redovi, kolone).
Nazive svih kolona u DataFrame-u možemo saznati pomoću df.columns.
Šta ako želimo da izaberemo samo jednu kolonu i dobijemo sve podatke iz nje? To se radi na sličan način kao pristupanje elementima rečnika. Unesite sledeći kod u novu ćeliju i pokrenite ga:
df['price ']
Gornji kod vraća kolonu cena. Možemo je sačuvati u novu promenljivu:
price = df['price']
Sada možemo primeniti sve radnje koje se mogu izvesti na DataFrame-u na našu promenljivu price, jer ona predstavlja podskup originalnog DataFrame-a. Možemo koristiti funkcije poput df.head(), df.shape itd.
Takođe, možemo izabrati više kolona tako što prosledimo listu naziva kolona u df:
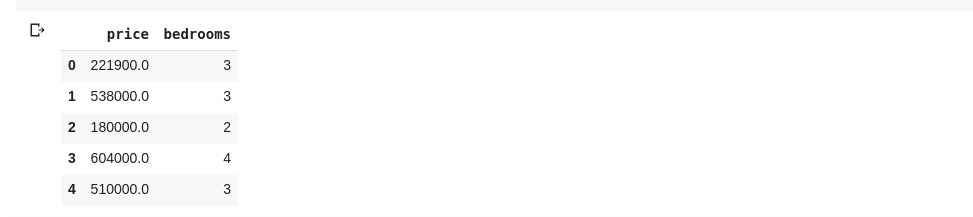
data = df[['price ', 'bedrooms']]
Gore navedeno selektuje kolone sa nazivima ‘price’ i ‘bedrooms’. Ako unesemo data.head() u novu ćeliju, dobićemo sledeći prikaz:
Prethodni način selekcije kolona vraća sve elemente reda u tim kolonama. Šta ako želimo da vratimo podskup redova i podskup kolona iz našeg skupa podataka? To se može uraditi pomoću .iloc, a indeksiranje se vrši na sličan način kao kod Pajton lista. Na primer:
df.iloc[50: , 3]
Ovo vraća treću kolonu, počevši od 50. reda pa do kraja. Veoma je slično rezanju lista u Pajtonu.
Sada, pogledajmo neke interesantnije stvari. Naš skup podataka o cenama kuća sadrži kolonu koja prikazuje cenu kuće i drugu kolonu koja prikazuje broj spavaćih soba. Cene kuća su kontinuirane vrednosti, pa je malo verovatno da će dve kuće imati identičnu cenu. S druge strane, broj spavaćih soba je diskretna vrednost, tako da može postojati više kuća sa dve, tri, ili četiri spavaće sobe, itd.
Šta ako želimo da pronađemo sve kuće sa istim brojem spavaćih soba i da izračunamo prosečnu cenu za svaku grupu soba? To se relativno lako radi u Pandas-u:
df.groupby('bedrooms ')['price '].mean()
Gore navedeni kod prvo grupira DataFrame po podacima sa identičnim brojem spavaćih soba pomoću funkcije df.groupby(). Zatim, kažemo da nam prikaže samo kolonu cena i koristimo funkciju .mean() da izračunamo prosečnu cenu za svaku grupu.
Kako da vizualizujemo dobijene podatke? Želimo da vidimo kako varira prosečna cena u zavisnosti od broja spavaćih soba. Jednostavno, dodamo funkciju .plot() na prethodni kod:
df.groupby('bedrooms ')['price '].mean().plot()
Dobićemo izlaz koji izgleda ovako:
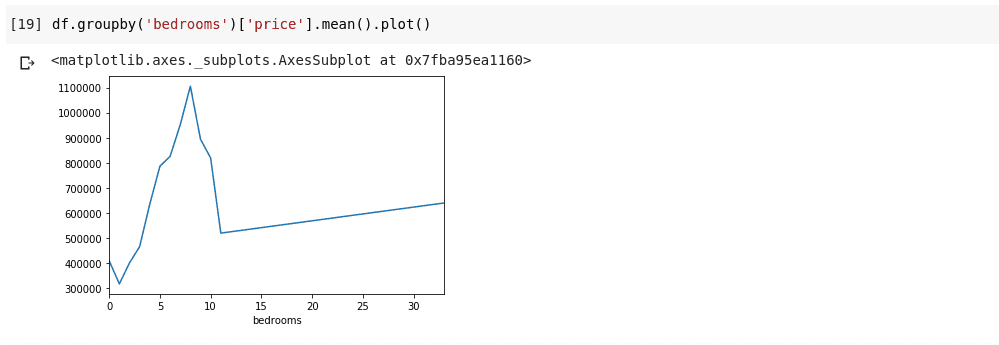
Gore prikazani grafikon nam otkriva određene trendove u podacima. Na horizontalnoj osi imamo različit broj spavaćih soba (imajte na umu da više od jedne kuće može imati X broj spavaćih soba), dok na vertikalnoj osi imamo prosečnu cenu za odgovarajući broj spavaćih soba. Možemo uočiti da su kuće sa 5 do 10 spavaćih soba značajno skuplje od onih sa 3. Takođe je očigledno da kuće sa 7 ili 8 spavaćih soba koštaju mnogo više od onih sa 15, 20 ili čak 30 soba.
Ovakve informacije su ključne, jer omogućavaju izvlačenje korisnih uvida iz podataka koje je teško ili nemoguće uočiti bez analize.
Nedostajući podaci
Zamislite da sprovodimo anketu sa nizom pitanja. Delimo link ka anketi sa hiljadama ljudi. Krajnji cilj je da analiziramo podatke kako bismo dobili korisne uvide.
Međutim, moguće je da neki ispitanici ne odgovore na sva pitanja, ili da ostave pojedina polja prazna. Ovo može stvoriti problem ako je za analizu potrebno izvršiti numeričke operacije nad tim podacima, kao što su izračunavanje zbira ili srednje vrednosti. Nedostajuće vrednosti mogu dovesti do netačnosti u analizi. Zato je neophodno pronaći način da se identifikuju i zamene nedostajuće vrednosti odgovarajućim alternativama.
Pandas nam pruža funkciju isnull() za pronalaženje nedostajućih vrednosti u DataFrame-u.
Funkcija isnull() se koristi na sledeći način:
df.isnull()
Ovo vraća DataFrame logičkih vrednosti koji ukazuje na to da li nedostaju originalni podaci ili ne. Izlaz će izgledati ovako:
Potreban nam je način da zamenimo sve nedostajuće vrednosti. Najčešće se to radi tako da se nedostajuće vrednosti zamene nulom. Ponekad se mogu koristiti srednje vrednosti svih ostalih podataka ili srednje vrednosti podataka u okruženju, u zavisnosti od naučnika koji vrši analizu i specifičnosti podataka.
Da bismo popunili sve nedostajuće vrednosti u DataFrame-u, koristimo funkciju .fillna() na sledeći način:
df.fillna(0)
U gornjem primeru, sve nedostajuće vrednosti popunjavamo nulom. Naravno, ovo može biti i bilo koja druga vrednost.
Značaj podataka je neizmeran. Oni nam omogućavaju da dobijemo odgovore direktno iz naših podataka! Analiza podataka se smatra novom „naftom“ za digitalnu ekonomiju.
Svi primeri iz ovog članka mogu se pronaći ovde.
Za više detalja, pogledajte online kurs Analiza podataka sa Pajtonom i Pandas-om.