Prepoznavanje imenovanih entiteta (NER) pruža izvanredan način da se shvate zadate tekstualne informacije i identifikuju specifični entiteti ili oznake unutar njih, što je korisno za različite primene.
Od kategorizacije imena ljudi do označavanja datuma, organizacija, lokacija i mnogih drugih elemenata, NER kreira jedinstven put ka boljem razumevanju jezika.
Brojne organizacije se suočavaju s obimnim količinama podataka u različitim oblicima, uključujući sadržaj, lične podatke, povratne informacije kupaca, detalje o proizvodima i još mnogo toga.
Kada vam je potrebno da brzo dođete do informacija, neophodno je izvršiti pretragu da biste dobili traženi rezultat, a to može oduzeti dosta vremena, energije i resursa, naročito kada se radi o velikim količinama podataka.
Da bi se organizacijama omogućilo efikasno rešenje za pretragu i brzo pronalaženje relevantnih podataka, NER predstavlja izuzetnu opciju.
U ovom tekstu detaljno ću razmotriti NER, njegove matematičke osnove, različite načine primene, kao i druge važne aspekte.
Započnimo!
Šta je prepoznavanje imenovanih entiteta?
Prepoznavanje imenovanih entiteta (NER) je metoda obrade prirodnog jezika (NLP) koja je sposobna da identifikuje i klasifikuje entitete unutar tekstualnih, nestrukturiranih podataka.
Ovi entiteti obuhvataju širok spektar informacija, kao što su organizacije, lokacije, imena pojedinaca, numeričke vrednosti, datumi i drugo. NER omogućava mašinama da izdvoje navedene entitete, čineći ga korisnim alatom za primene kao što su prevođenje, odgovaranje na pitanja i druge aplikacije u različitim industrijama.
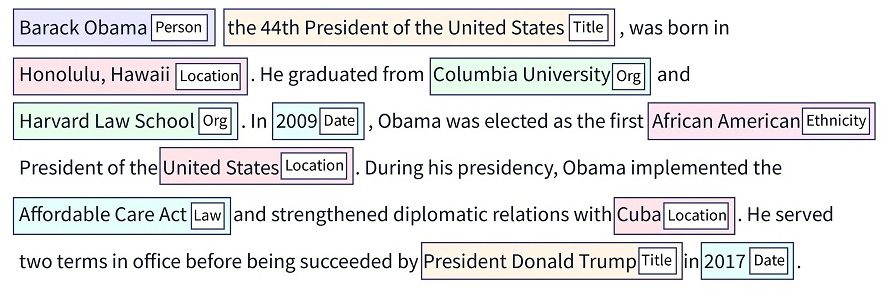 Izvor: Scaler
Izvor: Scaler
Dakle, NER ima za cilj da locira i kategoriše različite entitete u nestrukturiranom tekstu u unapred definisane grupe, kao što su organizacije, medicinski kodovi, količine, imena osoba, procenti, monetarne vrednosti, vremenski izrazi i mnoge druge.
Razjasnimo ovo na primeru:
[William] je kupio imanje od [Z1 Corp.] u [2023]. Ovde su blokovi entiteti koje je identifikovao NER. Oni su klasifikovani kao:
- Vilijam – ime osobe
- Z1 Corp. – Organizacija
- 2003 – Vreme
NER se koristi u nekoliko oblasti veštačke inteligencije, uključujući duboko učenje, mašinsko učenje (ML) i neuronske mreže. To je ključna komponenta NLP sistema, kao što su alati za analizu sentimenta, pretraživači i čet-botovi. Pored toga, može se primeniti u finansijama, korisničkoj podršci, visokom obrazovanju, zdravstvu, ljudskim resursima i analizi društvenih medija.
Jednostavno rečeno, NER identifikuje, klasifikuje i izdvaja bitne informacije iz nestrukturiranog teksta bez potrebe za ljudskom analizom. Može brzo izdvojiti ključne informacije iz dostupnog skupa velikih podataka.
Nadalje, NER pruža ključne uvide vašoj organizaciji o proizvodima, tržišnim trendovima, kupcima i konkurenciji. Na primer, zdravstvene ustanove koriste NER za izdvajanje osnovnih medicinskih podataka iz kartona pacijenata. Brojne kompanije ga koriste za identifikaciju da li se pominju u bilo kojoj publikaciji.
Ključni koncepti: NER

Važno je poznavati osnovne koncepte koji se koriste u NER-u. Hajde da razmotrimo neke ključne termine vezane za NER koje treba upoznati.
- Imenovani entitet: Svaka reč koja se odnosi na mesto, organizaciju, osobu ili drugi entitet.
- Korpus: Zbirka različitih tekstova koji se koriste za analizu jezika i obuku NER modela.
- POS označavanje: Proces u kojem se tekst označava prema odgovarajućem delu govora, kao što su pridevi, glagoli i imenice.
- Seckanje: To je proces koji se koristi za grupisanje reči u različite fraze sa značenjem na osnovu sintaksičke strukture i delova govora.
- Podaci za obuku i testiranje: Ovo je proces koji se koristi za obuku modela sa označenim podacima i procenu performansi prvog skupa na drugom skupu podataka.
Upotreba NER-a u NLP-u

NER ima višestruke primene u NLP-u, kao što su analiza sentimenta, sistemi preporuka, odgovaranje na pitanja, ekstrakcija informacija i mnoge druge.
- Analiza sentimenta: NER se koristi za otkrivanje osećanja izraženog u rečenici ili pasusu prema određenom imenovanom entitetu, kao što je proizvod ili usluga. Ovi podaci se koriste za poboljšanje korisničkog iskustva i identifikaciju oblasti za poboljšanje.
- Sistemi preporuka: NER se koristi za identifikaciju preferencija i interesovanja korisnika na osnovu imenovanih entiteta pomenutih u onlajn interakcijama ili upitima za pretragu. Ovi podaci se koriste za unapređenje korisničkog iskustva pružanjem personalizovanih preporuka.
- Odgovaranje na pitanja: NER se koristi za detektovanje određenih entiteta iz teksta, koji se dalje koriste za odgovor na upit ili konkretno pitanje. Ovo se uglavnom koristi za virtuelne pomoćnike i čet-botove.
- Ekstrakcija informacija: NER se koristi za izdvajanje bitnih informacija iz većeg skupa nestrukturiranog teksta. Ovo uključuje postove na društvenim mrežama, onlajn recenzije, članke vesti i još mnogo toga. Ovi podaci se koriste za generisanje vrednih uvida i donošenje odluka zasnovanih na podacima.
Matematički koncepti: NER
NER proces obuhvata različite matematičke koncepte, kao što su mašinsko učenje, duboko učenje, teorija verovatnoće i mnogi drugi. Evo nekoliko matematičkih tehnika:
- Skriveni Markov modeli: Skriveni Markovljevi modeli ili HMM su statistički pristup za sekvenciranje zadataka klasifikacije, kao što je NER. To uključuje predstavljanje niza reči u tekstu kao različita stanja, pri čemu svako stanje predstavlja određeni imenovani entitet. Analizom verovatnoće možete identifikovati imenovane entitete iz teksta.
- Duboko učenje: Tehnike dubokog učenja kao što su neuronske mreže koriste se u NER zadacima. Ovo vam omogućava da efikasno i precizno identifikujete i kategorišete imenovane entitete.
- Uslovna nasumična polja: Ova polja spadaju u grafički model koji se koristi u zadacima označavanja sekvenci. Ona nude modeliranje uslovne verovatnoće svake oznake koja sadrži niz reči. Ovo vam omogućava da identifikujete imenovane entitete u tekstu.
Kako NER funkcioniše?
 Izvor: ACS Publications
Izvor: ACS Publications
Prepoznavanje imenovanih entiteta (NER) funkcioniše kao ekstrakcija informacija. Njegovo funkcionisanje je podeljeno na različite ključne korake:
#1. Prethodno obradite tekst
U prvom koraku, NER uključuje pripremu tekstualnih informacija za analizu. Obično uključuje zadatke kao što je tokenizacija. Ovde se tekst prvo deli na tokene pre nego što NER počne da identifikuje entitete.
Na primer, „Bil Gejts je osnovao Microsoft“ može se podeliti na različite tokene kao što su „Bill“, „Gates“, „osnovao“ i „Microsoft“.
#2. Identifikujte entitete
Potencijalni imenovani entiteti mogu se otkriti korišćenjem statističkih metoda ili jezičkih pravila. Ovaj korak uključuje prepoznavanje obrazaca, kao što su određeni formati (datumi) ili pisanje velikih slova u imenima („Bill Gates“). Kada se završi funkcija predobrade, NER algoritmi skeniraju tekst da bi identifikovali reči u sekvencama koje odgovaraju entitetima.
#3. Klasifikujte entitete
Nakon što NER identifikuje entitete, kategoriše ove prepoznate entitete u tipove, klase ili grupe. Uobičajene kategorije su organizacija, datum, lokacija, osoba i još mnogo toga. Ovo se postiže modelima mašinskog učenja koji se obučavaju na označenim podacima.
Na primer, „Bil Gejts“ bi bio prepoznat kao „osoba“, a „Microsoft“ kao „organizacija“.
#4. Kontekstualna analiza
NER se nikada ne zaustavlja na prepoznavanju i klasifikovanju entiteta. Često uzima u obzir kontekst kako bi poboljšao tačnost. Ovaj korak uzima u obzir kontekst u kojem se entiteti pojavljuju, dajući tačnu kategorizaciju.
Na primer, „Bil Gejts je osnovao Microsoft“. Ovde kontekst omogućava sistemima da identifikuju „račun“ kao ime osobe, a ne kao račun za plaćanje.
#5. Post obrada
Nakon početne identifikacije i kategorizacije, neophodna je naknadna obrada da bi se precizirali konačni rezultati. Ovo uključuje rešavanje nejasnoća, korišćenje baza znanja, spajanje entiteta sa više tokena i još mnogo toga za poboljšanje podataka o entitetima.
Neverovatan deo NER-a je to što ima sposobnost da tumači i razume nestrukturirani tekst, koji sadrži podatke koji su potrebni za vaše poslovanje. On prima suštinski deo podataka iz novinskih članaka, web stranica, istraživačkih radova, postova na društvenim mrežama i još mnogo toga.
Prepoznavanjem i kategorizacijom imenovanih entiteta, NER dodaje dodatni sloj značenja i strukture tekstualnom okruženju.
Metode NER-a

Najčešće korišćene metode su sledeće:
#1. Metoda zasnovana na nadgledanom mašinskom učenju
Ova metoda koristi modele mašinskog učenja koji su obučeni na tekstovima koje su ljudi unapred označili imenovanim kategorijama entiteta.
Ovaj pristup koristi algoritme, uključujući maksimalnu entropiju i uslovna slučajna polja, da bi se dobili složeni statistički modeli jezika. Efikasan je za rešavanje lingvističkih značenja zajedno sa drugim složenostima, ali mu je potrebna velika količina podataka za obuku da bi se izvršila operacija.
#2. Sistemi zasnovani na pravilima
Ova metoda koristi različita pravila za prikupljanje informacija. Uključuje naslove ili velika slova, kao što je „Er”. U ovoj metodi, potrebna je značajna ljudska intervencija da bi se dali unosi, nadgledala i usavršila pravila. Ova metoda može propustiti tekstualne varijacije koje nisu uključene u napomene za obuku. Zato sistemi zasnovani na pravilima nisu u stanju da se nose sa složenošću modela mašinskog učenja.
#3. Sistemi zasnovani na rečnicima
U ovoj metodi, rečnik koji sadrži veliku količinu sinonima i kolekciju rečnika koristi se za identifikaciju i unakrsnu proveru imenovanih identiteta. Ova metoda se suočava sa problemima u kategorizaciji imenovanih entiteta koji imaju različite varijacije u pisanju.
Takođe, postoje mnoge druge nove NER metode. Hajde da razmotrimo i njih:
#4. Sistemi mašinskog učenja bez nadzora
Ovi ML sistemi koriste modele mašinskog učenja koji nisu prethodno obučeni za tekstualne podatke. Modeli učenja bez nadzora su sposobniji za izvršavanje složenih poslova od modela pod nadzorom.
#5. Bootstrapping sistemi
Sistemi za pokretanje su takođe poznati kao sistemi sa samo-nadzorom koji kategorišu imenovane entitete u zavisnosti od gramatičkih karakteristika, uključujući delove govornih oznaka, pisanje velikih slova i druge unapred obučene kategorije.
Čovek zatim podešava sistem za pokretanje tako što označava predviđanja sistema kao netačna ili tačna i dodaje ispravna u novi set za obuku.
#6. Neural Network Sistemi
On gradi model prepoznavanja imenovanih entiteta koristeći dvosmerne modele učenja arhitekture (Bidirectional Encoder Representations from Transformers), neuronske mreže i tehnike kodiranja. Ova metoda minimizira ljudsku interakciju.
#7. Statistical Sistemi
Ova metoda koristi probabilističke modele koji su obučeni na tekstualnim odnosima i obrascima. Pomaže da se lako predvide imenovani entiteti iz novih tekstualnih podataka.
#8. Sistemi označavanja semantičkih uloga
Ovaj sistem prethodno obrađuje model prepoznavanja imenovanih entiteta koristeći tehnike semantičkog učenja koje podučavaju odnos između kategorija i konteksta.
#9. Hibrid Sistemi
Ova metoda je interesantna jer koristi aspekte nekoliko pristupa na kombinovan način.
Prednosti NER-a
NER modeli pružaju brojne prednosti.
- NER automatizuje proces ekstrakcije podataka za veliku količinu podataka.
- Koristi se u svakoj industriji za izdvajanje ključnih informacija iz nestrukturiranog teksta.
- Ovo može uštedeti vama i vašim zaposlenima vreme u obavljanju zadataka ekstrakcije podataka.
- Može poboljšati tačnost NLP procesa i zadataka.
- Osigurava bezbednost podataka hostovanjem prilagođenih NER modela, eliminišući potrebu za deljenjem osetljivih informacija sa nezavisnim dobavljačima.
- On prihvata nove tipove entiteta i terminologije kako se domen razvija.
Izazovi NER-a
- Dvosmislenost: Mnoge reči koje se koriste u tekstu mogu biti varljive. Na primer, reč „Amazon” se odnosi na kompaniju, reku i šumu. Može se razlikovati po specifičnom kontekstu. Dakle, ovo čini prepoznavanje entiteta malo složenijim.
- Zavisnost od konteksta: Reči izvedene iz okolnog konteksta imaju različita značenja; na primer, „jabuka“ u tekstu zasnovanom na tehnologiji odnosi se na korporaciju, dok se u okruženju odnosi na voće. Nije lako prepoznati tačan entitet.
- Retkost podataka: Za NER metode zasnovane na ML, dostupnost označenih podataka je od suštinskog značaja. Međutim, izdvajanje takvih podataka, posebno za specijalizovane domene ili manje uobičajene jezike, može biti izazovno.
- Jezičke varijacije: Ljudski jezici imaju različite oblike u zavisnosti od njihovih dijalekata, regionalnih razlika i slenga. Otuda je teško izdvojiti tekst na stranom jeziku.
- Generalizacija modela: NER modeli mogu se istaći u klasifikovanju entiteta u jednom domenu, ali mogu zbuniti generalizaciju u drugom domenu. Dakle, NER modeli se mogu ponašati različito u različitim domenima.
Ovi izazovi se mogu rešiti ako kombinujete napredne algoritme, lingvističku stručnost i kvalitetne podatke. Pošto se NER razvija, istraživački i razvojni timovi moraju usavršiti različite tehnike kako bi se uhvatili u koštac sa ovim izazovima.
Slučajevi upotrebe NER-a
#1. Kategorizacija sadržaja

Izdavačke i novinske kuće generišu veliku količinu onlajn sadržaja. Dakle, efikasno upravljanje njima je ključno da biste izvukli maksimum iz članka ili vesti.
Prepoznavanje imenovanih entiteta automatski skenira ceo sadržaj i izdvaja podatke kao što su organizacije, mesta i imena ljudi koji se koriste u sadržaju. Poznavanje potrebnih oznaka za svaki članak pomaže vam da kategorišete članke u definisanoj hijerarhiji, poboljšavajući isporuku sadržaja.
#2. Algoritmi pretraživanja
Pretpostavimo da imate interni algoritam za pretragu za svog onlajn izdavača koji sadrži milione članaka. Za svaki upit za pretragu, vaš interni algoritam pretrage na kraju prikuplja sve reči iz tih članaka. Ovo je dugotrajan proces.
Sada, ako koristite NER za svog onlajn izdavača, on će lako dobiti bitne entitete iz svih članaka i čuvati ih odvojeno. Ovo će ubrzati vaš proces pretraživanja.
#3. Content Recommendations
Automatizacija procesa preporuka je glavni slučaj upotrebe NER-a. Sistemi preporuka vode u otkrivanju novih ideja i sadržaja.
Netflix je najbolji primer za to. To je dokaz da vam izgradnja efikasnog sistema preporuka pomaže da postanete zavisniji i privlačniji za događaje.
Za izdavače vesti, NER efikasno radi u preporuci sličnih članaka. Ovo se može uraditi prikupljanjem oznaka iz određenog članka i preporukom drugog sadržaja koji ima slične entitete.
#4. Korisnička podrška

Za svaku organizaciju, korisnička podrška je glavna stvar. Zato postoji više načina da se funkcija rukovanja povratnim informacijama korisnika učini glatkom. NER je jedan od njih. Hajde da ovo razumemo na primeru.
Pretpostavimo da kupac daje povratne informacije „Osoblju u Adidas outlet prodavnici u San Dijegu nedostaju finiji detalji o sportskoj obući.“ Ovde NER izdvaja oznake „San Dijego” (lokacija) i „sportske cipele” (proizvod).
Stoga se NER koristi za klasifikaciju svake žalbe i slanje je odgovarajućem odeljenju unutar organizacije da se bavi problemom. Možete razviti bazu podataka koja se sastoji od povratnih informacija koje su kategorisane u različita odeljenja i analizirati svaku povratnu informaciju.
#5. Istraživački radovi
Internet izdanje ili web stranica časopisa sadrži mnoštvo naučnih članaka i istraživačkih radova. Možete pronaći stotine radova sličnih tema sa malim modifikacijama. Dakle, organizovanje svih ovih podataka na strukturiran način može biti komplikovan zadatak.
Da biste preskočili dug proces, možete odvojiti ove papire na osnovu relevantnih oznaka.
Na primer, postoje hiljade radova o mašinskom učenju. Da biste pronašli onaj koji je pominjao upotrebu konvolucionih neuronskih mreža (CNN), morate na njih staviti entitete. Ovo će vam pomoći da brzo pronađete članak prema vašim zahtevima.
Zaključak
NLP tehnika, Prepoznavanje imenovanih entiteta (NER), pomaže u identifikaciji imenovanih entiteta u nestrukturiranom tekstu i kategorizaciji ovih entiteta u unapred definisane grupe kao što su lokacije, imena osoba, proizvodi i još mnogo toga.
Primarni cilj NER-a je da prikupi strukturirane informacije iz nestrukturiranog teksta i predstavi ih u čitljivom formatu. Uključuje različite modele i procese i donosi mnoge prednosti profesionalcima i preduzećima. Takođe se koristi za razne aplikacije osim za NLP.
Nadam se da razumete gorenavedeno objašnjenje o ovoj tehnici da biste mogli da je primenite u svom poslovanju i da na vreme dobijete relevantne, vredne informacije.
Takođe možete istražiti neke od najboljih NLP kurseva da biste naučili obradu prirodnog jezika