Federativno učenje predstavlja odmak od tradicionalnog načina prikupljanja podataka i obuke modela mašinskog učenja.
Zahvaljujući federativnom učenju, razvoj mašinskog učenja profitira od jeftinije obuke koja istovremeno štiti privatnost podataka. Ovaj članak detaljno objašnjava šta je federativno učenje, kako funkcioniše, njegove primene i okvire.
Šta je federativno učenje?
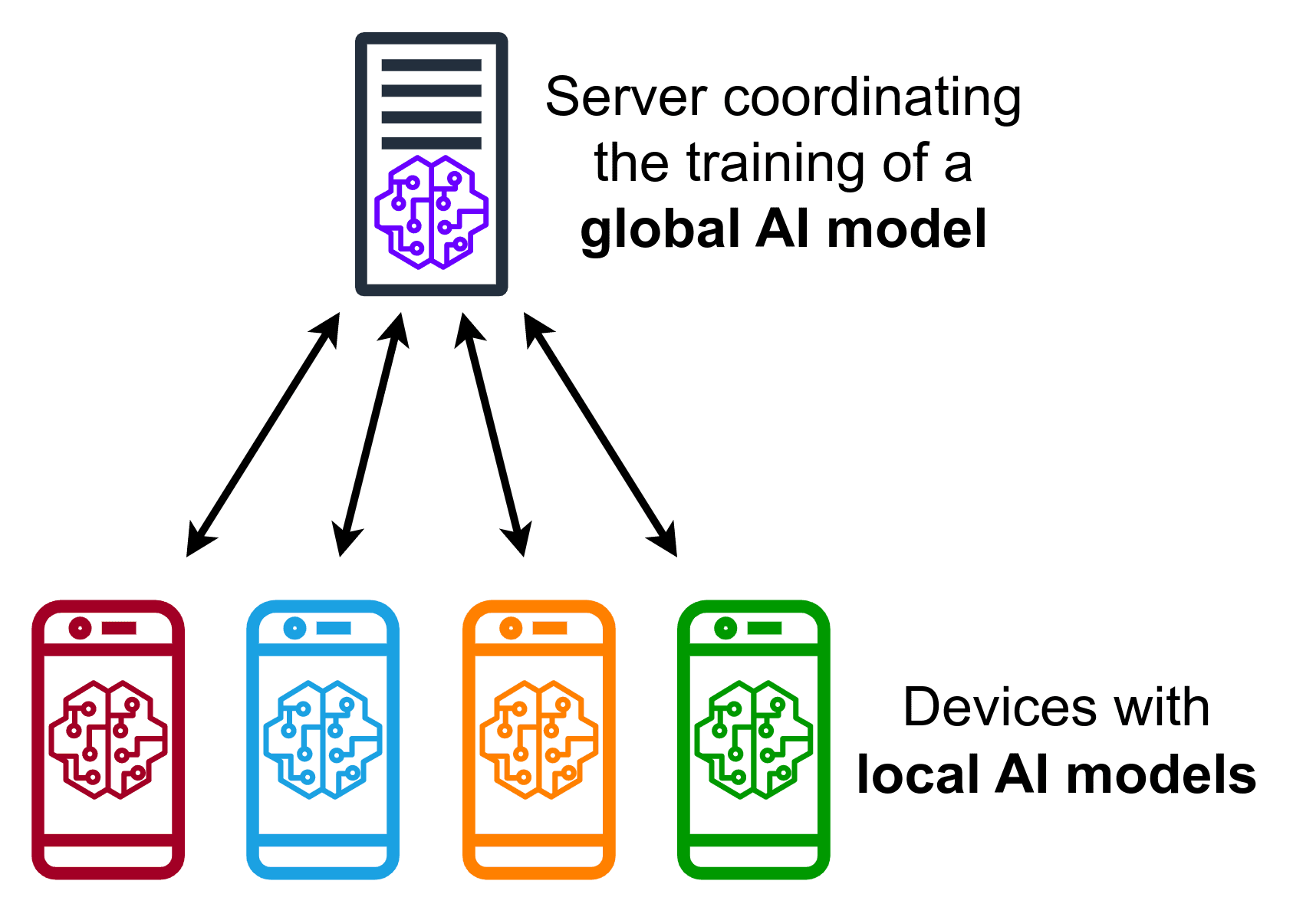 Izvor: Vikipedija
Izvor: Vikipedija
Federativno učenje predstavlja revoluciju u načinu na koji se obučavaju modeli mašinskog učenja. U većini modela mašinskog učenja, podaci se sakupljaju u centralnom skladištu od različitih klijenata. Iz tog centralnog skladišta, modeli mašinskog učenja se treniraju i potom koriste za predviđanje. Federativno učenje radi upravo suprotno. Umesto slanja podataka u centralno skladište, klijenti obučavaju modele na sopstvenim podacima. Na taj način, oni zadržavaju kontrolu nad svojim privatnim podacima.
Pročitajte i: Objašnjeni vrhunski modeli mašinskog učenja
Kako funkcioniše federativno učenje?
Proces učenja u federativnom učenju se sastoji od niza atomskih koraka koji rezultiraju modelom. Ovi koraci se nazivaju krugovi učenja. Tipičan proces učenja prolazi kroz ove krugove, usavršavajući model u svakom koraku. Svaki krug učenja uključuje sledeće korake.
Tipičan krug učenja
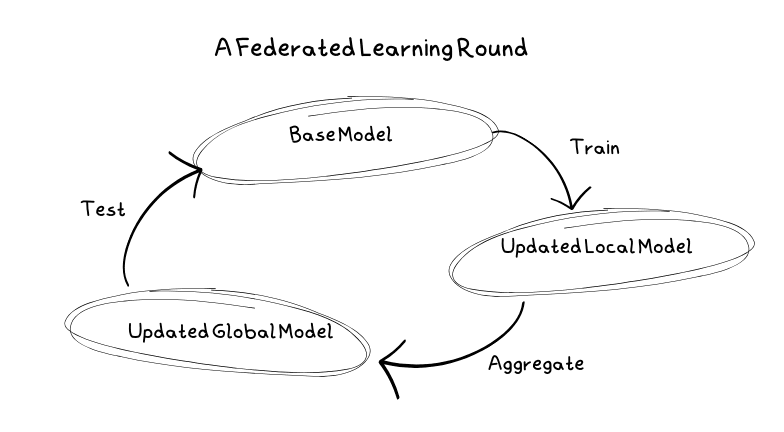
Prvo, server bira model za obuku i hiperparametre, kao što su broj krugova, klijentski čvorovi koji će se koristiti i udeo čvorova koji se koriste u svakom krugu. U ovom trenutku, model se takođe inicijalizuje sa početnim parametrima da bi se formirao osnovni model.
Zatim, klijenti dobijaju kopije osnovnog modela za obuku. Ovi klijenti mogu biti mobilni uređaji, lični računari ili serveri. Oni treniraju model na svojim lokalnim podacima, izbegavajući tako deljenje osetljivih podataka sa serverima.
Kada klijenti obuče model na svojim lokalnim podacima, šalju ga nazad na server kao ažuriranje. Kada server primi, ažuriranja se kombinuju sa ažuriranjima od drugih klijenata kako bi se kreirao novi osnovni model. S obzirom na to da klijenti mogu biti nepouzdani, neki možda neće poslati svoja ažuriranja. U tom slučaju, server će obraditi sve greške.
Pre nego što se osnovni model ponovo upotrebi, mora se testirati. Međutim, server ne čuva podatke. Stoga, radi testiranja modela, on se šalje nazad klijentima, gde se testira na njihovim lokalnim podacima. Ako je bolji od prethodnog osnovnog modela, on se usvaja i koristi umesto njega.
Evo koristan vodič o tome kako funkcioniše federativno učenje od tima za federativno učenje u Google AI.
Centralizovano naspram federativnog naspram heterogenog
U ovoj postavci postoji centralni server odgovoran za kontrolu učenja. Ova vrsta podešavanja je poznata kao centralizovano federativno učenje.
Suprotno centralizovanom učenju bilo bi decentralizovano federativno učenje, u kojem se klijenti međusobno koordiniraju.
Druga postavka se zove Heterogeno učenje. U ovoj postavci, klijenti ne moraju nužno imati istu arhitekturu globalnog modela.
Prednosti federativnog učenja
- Najveća prednost korišćenja federativnog učenja je to što pomaže da privatni podaci ostanu privatni. Klijenti dele rezultate obuke, a ne podatke koji se koriste u obuci. Protokoli se takođe mogu uspostaviti za agregiranje rezultata tako da se ne mogu povezati sa određenim klijentom.
- Takođe smanjuje opterećenje mreže, jer se nikakvi podaci ne dele između klijenta i servera. Umesto toga, modeli se razmenjuju između klijenta i servera.
- Takođe smanjuje troškove modela za obuku, jer nema potrebe za kupovinom skupog hardvera za obuku. Umesto toga, programeri koriste hardver klijenta za obuku modela. Zbog malog obima podataka, ovo ne opterećuje uređaj klijenta.
Nedostaci federativnog učenja
- Ovaj model zavisi od učešća mnogih različitih čvorova. Neki od njih nisu pod kontrolom programera. Stoga, njihova dostupnost nije zagarantovana. Ovo čini hardver za obuku nepouzdanim.
- Klijenti na kojima su modeli obučeni nisu moćni GPU-ovi. Umesto toga, to su standardni uređaji, kao što su telefoni. Ovi uređaji, čak i ukupno, možda neće biti dovoljno moćni u poređenju sa GPU klasterima.
- Federativno učenje takođe pretpostavlja da su svi klijentski čvorovi pouzdani i da rade za opšte dobro. Međutim, neki možda neće i mogu izdati loša ažuriranja da bi poremetili model.
Primene federativnog učenja
Federativno učenje omogućava učenje uz očuvanje privatnosti. Ovo je korisno u mnogim situacijama, kao što su:
- Predviđanja sledeće reči na tastaturi pametnog telefona.
- IoT uređaji koji mogu lokalno da obučavaju modele prema specifičnim zahtevima situacije u kojoj se nalaze.
- Farmaceutska i zdravstvena industrija.
- Odbrambene industrije bi takođe imale koristi od modela obuke bez deljenja osetljivih podataka.
Okviri za federativno učenje
Postoji mnogo okvira za implementaciju obrazaca federativnog učenja. Neki od najboljih uključuju NVFlare, FATE, Flower i PySyft. Pročitajte ovaj vodič za detaljno poređenje različitih okvira koje možete da koristite.
Zaključak
Ovaj članak je bio uvod u federativno učenje, kako ono funkcioniše, kao i prednosti i mane njegove primene. Pored toga, obuhvatili smo i popularne aplikacije i okvire koji se koriste za implementaciju federativnog učenja u proizvodnji.
Zatim pročitajte članak o najboljim MLOps platformama da biste obučili svoje modele mašinskog učenja.