Кључне ствари за разумевање
- Платформе друштвених медија продају корисничке податке компанијама које се баве вештачком интелигенцијом како би тренирале њихове моделе, упркос забринутости за приватност.
- Многе познате платформе, укључујући Мета, Реддит, Тумблр и ВордПресс.цом, активно склапају уговоре о лиценцирању података у сврху обуке вештачке интелигенције.
- Корисници могу предузети одређене кораке за заштиту својих података, као што су прилагођавање подешавања приватности, одбијање дељења података и опрез при објављивању садржаја на интернету.
Један од нових начина на који компаније друштвених медија монетизују корисничке податке је кроз сарадњу са фирмама за вештачку интелигенцију. Међутим, поставља се питање да ли обични корисници могу нешто учинити како би заштитили своје податке и садржај.
Коришћење података са друштвених медија за обучавање генеративних модела вештачке интелигенције изазвало је контроверзе, али то очигледно не спречава компаније да деле корисничке информације.
Мета већ користи податке са друштвених мрежа за обучавање генеративних функција вештачке интелигенције које су представљене на Мета Цоннецт-у 2023. Ово укључује Мета АИ и функције као што је креирање налепница помоћу вештачке интелигенције на ВхатсАпп-у.
Мајк Кларк, директор за управљање производима у компанији Мета, је изјавио у објави на Мета Невсроом-у:
„Јавне објаве са Инстаграма и Фејсбука, укључујући фотографије и текст, коришћене су за обучавање генеративних АИ модела који стоје иза функција које смо најавили на Цоннецт-у.”
Чини се да се овај тренд наставља и у 2024. години. Према извештају Ројтерса, Реддит је склопио договор са Гуглом о стављању садржаја платформе на располагање за обуку модела вештачке интелигенције.
Реддитова С-1 пријава за ИПО, поднета 22. фебруара 2024, потврђује да компанија разматра уговоре о лиценцирању. У пријави се наводи:
„Подаци са Реддита су од фундаменталне важности за развој тренутне АИ технологије и многих великих језичких модела (ЛЛМ). Верујемо да ће Реддитова огромна база конверзацијских података и знања наставити да игра важну улогу у обуци и унапређењу ЛЛМ-ова.”
Наводи се да је Реддит „у раној фази омогућавања трећим странама да лиценцирају приступ историјским и подацима у реалном времену са наше платформе за претрагу, анализу и приказ“, у сврху обуке ЛЛМ-ова.
Иако су Мета и Реддит међу највећим именима у свету друштвених медија, они нису једине платформе укључене у коришћење података за обуку вештачке интелигенције. Према извештају 404 Медиа, Тумблр и ВордПресс.цом се спремају да продају корисничке податке компанијама Мидјоурнеи и ОпенАИ.
Ако користите Фацебоок, Инстаграм, Реддит, Тумблр или ВордПресс.цом, велика је вероватноћа да се ваш јавно доступан садржај већ користи за обуку ЛЛМ-ова.
На пример, ако користите алатку за претрагу Вашингтон поста да бисте проверили које су локације укључене у Гуглов скуп података Ц4, који је коришћен за обуку Барда, видећете да Реддит.цом чини 7,9 милиона токена.

Тумблр.цом има 1,6 милиона токена. Моја мала веб локација, која користи ВордПресс.цом, чинила је 14.000 токена – што значи да су можда и мали лични блогови укључени у овај скуп података.
Са актуелним уговорима између компанија које се баве вештачком интелигенцијом и друштвеним мрежама, уговори о лиценцирању ће значити да ће се ови подаци активно продавати, а не само „гребати“ са веба.
Међутим, шта можете да учините у вези с тим? Мета је увела формулар за захтеве у вези са генеративном вештачком интелигенцијом који вам омогућава да уложите приговор или ограничите обраду ваших личних података од стране трећих страна у сврху обуке Мета-иних генеративних модела вештачке интелигенције.
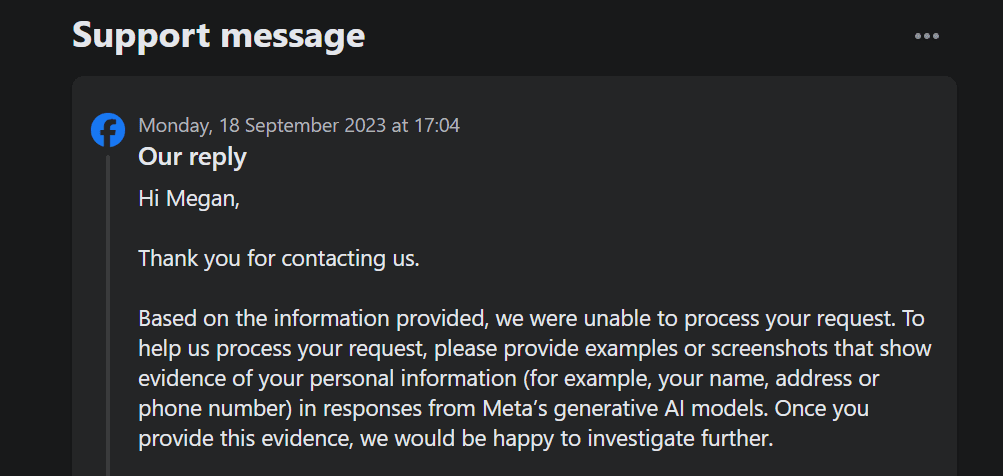
Међутим, ова опција вам не омогућава да оспорите Мета-ину сопствену обраду ваших података за обуку генеративне вештачке интелигенције. Штавише, када сам поднео захтев за приговор на коришћење мојих личних података путем овог формулара, корисничка подршка је тражила од мене доказ да се моји лични подаци већ појављују у резултатима генерисаним Мета-ином вештачком интелигенцијом.
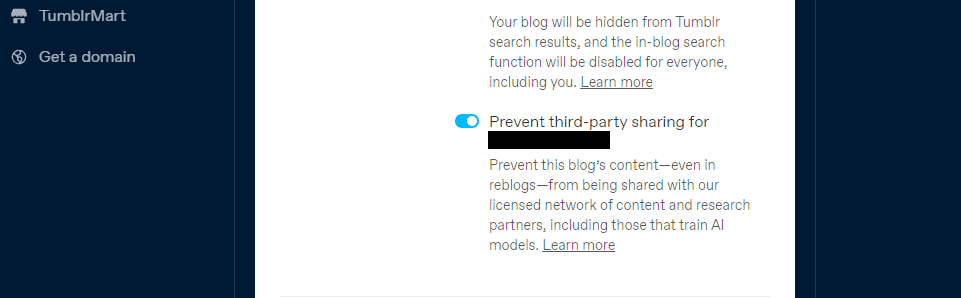
Тумблр је такође увео могућност да спречите дељење садржаја са ваших јавних блогова са трећим странама у подешавањима вашег блога. Ову опцију можете пронаћи тако што ћете кликнути на свој блог и скроловати надоле до подешавања видљивости. Затим одаберите да онемогућите дељење са трећим странама за свој блог.
Када је у питању платформа као што је Инстаграм, можете покушати да подесите свој налог на приватан како бисте спречили употребу ваших података. Ово не гарантује да се ваши подаци неће користити, али пошто се чини да је прикупљање података за ЛЛМ-ове фокусирано на јавне податке, то би могла бити потенцијална заштита.
Такође можете да подесите свој X (Твитер) налог на приватан, али још једном, то је само потенцијална мера заштите и не гарантује да ваши подаци неће бити коришћени.
Заједничка изјава коју су издали разни национални комесари за информације и експерти широм света, такође је предложила одређене мере за појединце који желе да минимизирају ризик по приватност од стране компанија које се баве вештачком интелигенцијом. Савет укључује:
- Прочитајте услове коришћења и политику приватности веб локације да бисте сазнали како се деле ваши лични подаци.
- Ограничите информације које објављујете на интернету, посебно осетљиве податке.
- Управљајте подешавањима приватности.
- Размишљајте о дугорочним последицама информација које делите на мрежи.
- Контактирајте компанију или веб локацију ако сматрате да су ваши подаци злоупотребљени. Ако нисте задовољни њиховим одговором, поднесите жалбу надлежном органу за заштиту података.
Такође можете да избришете одређене информације са интернета ако не желите да им трећа лица имају приступ, иако је могуће да су јавно доступне информације на вашим профилима већ искоришћене.
Нажалост, ми као обични корисници можемо учинити само толико да заштитимо своје податке од компанија за вештачку интелигенцију. Права контрола над овим информацијама вероватно ће доћи само уз помоћ регулаторних тела.