Да ли сте заинтересовани да анализирате своје податке користећи природни језик? Научите како да то урадите користећи Питхон библиотеку ПандасАИ.
У свету у коме су подаци кључни, њихово разумевање и анализа су од суштинског значаја. Међутим, традиционална анализа података може бити сложена. Ту долази ПандасАИ. Он поједностављује анализу података тако што вам омогућава да разговарате са својим подацима користећи природни језик.
Пандас АИ ради тако што ваша питања претвара у код за анализу података. Заснован је на популарној Питхон библиотеци пандас. ПандасАИ је Питхон библиотека која проширује панде, добро познату алатку за анализу и манипулацију података, са генеративним АИ функцијама. Намењен је да допуни панде, а не да их замени.
ПандасАИ уводи аспект разговора у панде (као и друге широко коришћене библиотеке за анализу података), омогућавајући вам да комуницирате са својим подацима помоћу упита природног језика.
Овај водич ће вас провести кроз кораке подешавања Пандас АИ, користећи га са скупом података из стварног света, креирање дијаграма, истраживање пречица и истраживање предности и ограничења овог моћног алата.
Након што га завршите, моћи ћете лакше и интуитивније да обављате анализу података користећи природни језик.
Дакле, хајде да истражимо фасцинантан свет анализе података на природном језику са Пандас АИ!
Подешавање вашег окружења
Да бисте започели са ПандасАИ, требало би да почнете са инсталирањем ПандасАИ библиотеке.
Користим Јупитер Нотебоок за овај пројекат. Али можете користити Гоогле Цоллаб или ВС Цоде према вашим захтевима.
Ако планирате да користите Опен АИ велике језичке моделе (ЛЛМ), такође је важно да инсталирате Опен АИ Питхон СДК за глатко искуство.
# Installing Pandas AI !pip install pandas-ai # Pandas AI uses OpenAI's language models, so you need to install the OpenAI Python SDK !pip install openai
Сада, хајде да увеземо све потребне библиотеке:
# Importing necessary libraries import pandas as pd import numpy as np # Importing PandasAI and its components from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
Кључни аспект анализе података помоћу ПандасАИ-а је АПИ кључ. Овај алат подржава неколико модела великих језика (ЛЛМ) и ЛангЦхаинс модела, који се користе за генерисање кода из упита природног језика. Ово чини анализу података приступачнијом и једноставнијом за корисника.
ПандасАИ је свестран и може да ради са различитим типовима модела. То укључује моделе Хуггинг Фаце, Азуре ОпенАИ, Гоогле ПАЛМ и Гоогле ВертекАИ. Сваки од ових модела доноси своје предности на столу, побољшавајући могућности ПандасАИ-а.
Запамтите, да бисте користили ове моделе, биће вам потребни одговарајући АПИ кључеви. Ови кључеви потврђују аутентичност ваших захтева и омогућавају вам да искористите моћ ових напредних језичких модела у вашим задацима анализе података. Дакле, уверите се да имате при руци своје АПИ кључеве када подешавате ПандасАИ за своје пројекте.
Можете преузети АПИ кључ и извести га као променљиву окружења.
У следећем кораку ћете научити како да користите ПандасАИ са различитим типовима великих језичких модела (ЛЛМ) из ОпенАИ-а и Хуггинг Фаце Хуб-а.
Коришћење великих језичких модела
Можете одабрати ЛЛМ тако што ћете га инстанцирати и прослиједити га у СмартДатаФраме или СмартДаталаке конструктор, или га можете навести у датотеци пандасаи.јсон.
Ако модел очекује један или више параметара, можете их проследити конструктору или их навести у датотеци пандасаи.јсон у параметру ллм_оптионс, на следећи начин:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Како користити ОпенАИ моделе?
Да бисте користили ОпенАИ моделе, потребно је да имате ОпенАИ АПИ кључ. Можете добити један овде.
Када имате АПИ кључ, можете га користити за инстанцирање ОпенАИ објекта:
#We have imported all necessary libraries in privious step
llm = OpenAI(api_token="my-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Не заборавите да замените „ми-апи-кеи“ оригиналним АПИ кључем
Као алтернативу, можете поставити променљиву окружења ОПЕНАИ_АПИ_КЕИ и инстанцирати ОпенАИ објекат без прослеђивања АПИ кључа:
# Set the OPENAI_API_KEY environment variable
llm = OpenAI() # no need to pass the API key, it will be read from the environment variable
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Ако се налазите иза експлицитног проксија, можете навести опенаи_проки приликом инстанцирања ОпенАИ објекта или подесити променљиву окружења ОПЕНАИ_ПРОКСИ да прође.
Важна напомена: Када користите ПандасАИ библиотеку за анализу података са вашим АПИ кључем, важно је да пратите коришћење токена да бисте управљали трошковима.
Питате се како то да урадите? Једноставно покрените следећи код бројача токена да бисте добили јасну слику о коришћењу токена и одговарајућим трошковима. На овај начин можете ефикасно управљати својим ресурсима и избећи било каква изненађења у наплати.
Можете пребројати број токена које промпт користи на следећи начин:
"""Example of using PandasAI with a pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False is supposed to display lower usage and cost
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
print(cb)
Добићете овакве резултате:
# The sum of the GDP of North American countries is 19,294,482,071,552. # Tokens Used: 375 # Prompt Tokens: 210 # Completion Tokens: 165 # Total Cost (USD): $ 0.000750
Не заборавите да водите евиденцију о укупним трошковима ако имате ограничен кредит!
Како користити моделе за грљење лица?
Да бисте користили ХуггингФаце моделе, морате да имате ХуггингФаце АПИ кључ. Можете креирати ХуггингФаце налог овде и добијете АПИ кључ овде.
Када имате АПИ кључ, можете га користити за инстанцирање једног од ХуггингФаце модела.
Тренутно ПандасАИ подржава следеће ХуггингФаце моделе:
- Старцодер: бигцоде/старцодер
- Фалцон: тииуае/фалцон-7б-инструцт
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="my-huggingface-api-key")
# or
llm = Falcon(api_token="my-huggingface-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
Као алтернативу, можете поставити променљиву окружења ХУГГИНГФАЦЕ_АПИ_КЕИ и инстанцирати ХуггингФаце објекат без прослеђивања АПИ кључа:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # no need to pass the API key, it will be read from the environment variable
# or
llm = Falcon() # no need to pass the API key, it will be read from the environment variable
df = SmartDataframe("data.csv", config={"llm": llm})
Старцодер и Фалцон су оба ЛЛМ модели доступни на Хуггинг Фаце-у.
Успешно смо поставили наше окружење и истражили како да користимо ОпенАИ и Хуггинг Фаце ЛЛМ моделе. Сада, идемо даље са нашим путовањем анализе података.
Користићемо скуп података Биг Март Салес дата, који садржи информације о продаји различитих производа на различитим продајним местима Биг Март-а. Скуп података има 12 колона и 8524 реда. Добићете везу на крају чланка.
Анализа података са ПандасАИ
Сада када смо успешно инсталирали и увезли све потребне библиотеке, хајде да наставимо са учитавањем нашег скупа података.
Учитајте скуп података
Можете изабрати ЛЛМ тако што ћете га инстанцирати и проследити га у СмартДатаФраме. Добићете везу до скупа података на крају чланка.
#Load the dataset from device path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Користите ОпенАИ ЛЛМ модел
Након учитавања наших података. Користићу ОпенАИ ЛЛМ модел да користим ПандасАИ
llm = OpenAI(api_token="API_Key") pandas_ai = PandasAI(llm, conversational=False)
Све у реду! Сада, хајде да покушамо да користимо упите.
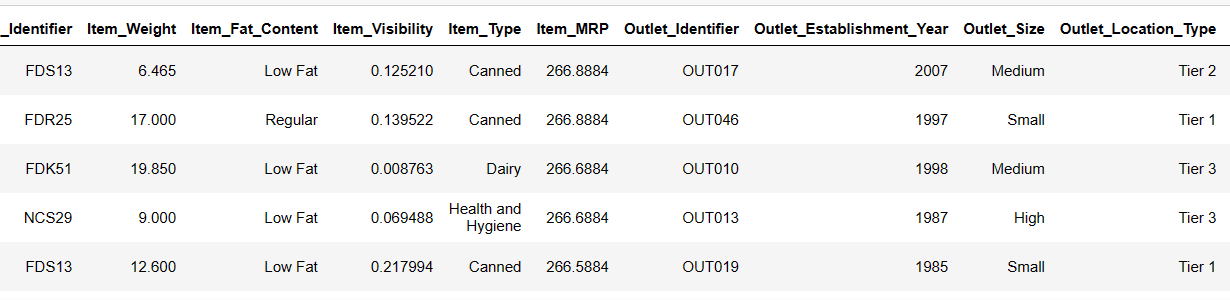
Одштампајте првих 6 редова нашег скупа података
Покушајмо да учитамо првих 6 редова дајући упутства:
Result = pandas_ai(df, "Show the first 6 rows of data in tabular form") Result
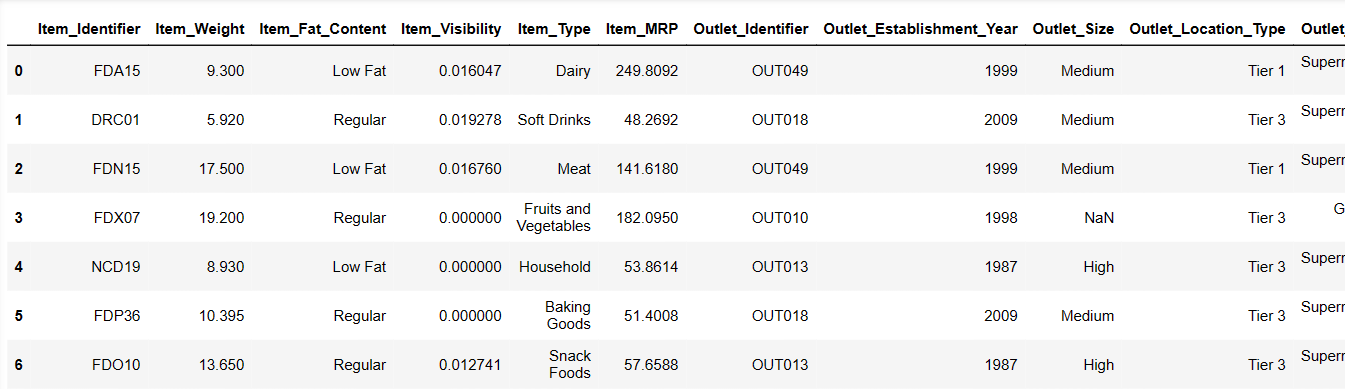 Првих 6 редова из скупа података
Првих 6 редова из скупа података
То је било стварно брзо! Хајде да разумемо наш скуп података.
Генерисање дескриптивне статистике за ДатаФраме
# To get descriptive statistics Result = pandas_ai(df, "Show the description of data in tabular form") Result
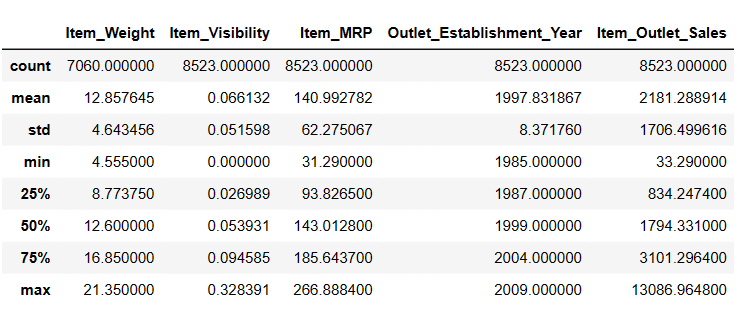 Опис
Опис
Постоји 7060 вредности у Итем_Веигтх; можда постоје неке вредности које недостају.
Пронађите недостајуће вредности
Постоје два начина да пронађете вредности које недостају користећи пандас аи.
#Find missing values Result = pandas_ai(df, "Show the missing values of data in tabular form") Result
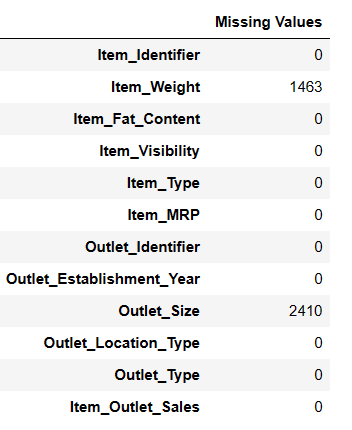 Проналажење вредности које недостају
Проналажење вредности које недостају
# Пречица за чишћење података
df = SmartDataframe('data.csv')
df.clean_data()
Ова пречица ће извршити чишћење података у оквиру података.
Сада, хајде да попунимо нулте вредности које недостају.
Попуните недостајуће вредности
#Fill Missing values result = pandas_ai(df, "Fill Item Weight with median and Item outlet size null values with mode and Show the missing values of data in tabular form") result
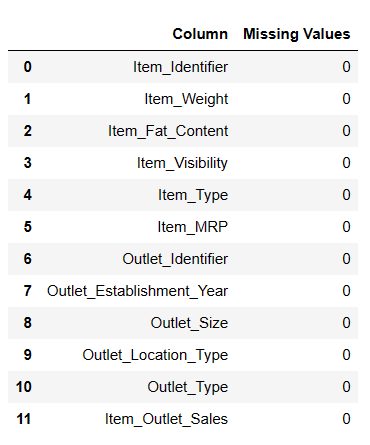 Попуњене нулте вредности
Попуњене нулте вредности
То је корисна метода за попуњавање нул вредности, али сам се суочио са неким проблемима приликом попуњавања нул вредности.
# Пречица за попуњавање нултим вредностима
df = SmartDataframe('data.csv')
df.impute_missing_values()
Ова пречица ће импутирати недостајуће вредности у оквиру података.
Испустите нулте вредности
Ако желите да избаците све нул вредности из вашег дф-а, можете испробати овај метод.
result = pandas_ai(df, "Drop the row with missing values with inplace=True") result
Анализа података је од суштинског значаја за идентификацију трендова, како краткорочних тако и дугорочних, који могу бити од непроцењиве вредности за предузећа, владе, истраживаче и појединце.
Хајде да покушамо да пронађемо општи тренд продаје током година од његовог оснивања.
Проналажење тренда продаје
# finding trend in sales result = pandas_ai(df, "What is the overall trend in sales over the years since outlet establishment?") result
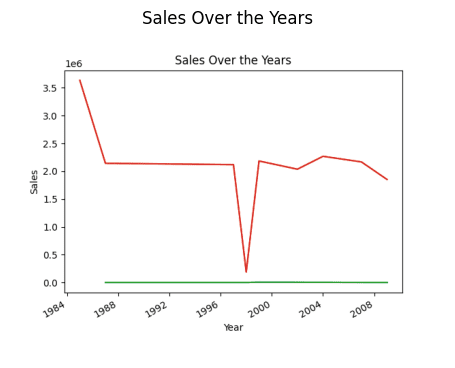 Продаја током године (линијски приказ)
Продаја током године (линијски приказ)
Почетни процес креирања заплета био је мало спор, али након поновног покретања кернела и покретања свега, ишао је брже.
# Пречица за цртање линија
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Ова пречица ће исцртати линијски графикон оквира података.
Можда се питате зашто постоји пад тренда. То је због тога што немамо податке од 1989. до 1994. године.
Проналажење године највеће продаје
Сада, хајде да сазнамо која година има највећу продају.
# finding year of highest sales result = pandas_ai(df, "Explain which years have highest sales") result

Дакле, година са највећом продајом је 1985.
Али, желим да сазнам који тип артикла генерише највећу просечну продају, а који тип генерише најнижу просечну продају.
Највећа и најнижа просечна продаја
# finding highest and lowest average sale result = pandas_ai(df, "Which item type generates the highest average sales, and which one generates the lowest?") result

Шкробна храна има највећу просечну продају, а друга имају најнижу просечну продају. Ако не желите да други буду са најнижом продајом, можете побољшати брзину према вашим потребама.
Диван! Сада желим да сазнам дистрибуцију продаје на различитим продајним местима.
Дистрибуција продаје у различитим продајним местима
Постоје четири типа локала: Супермаркет Тип 1/2/3 и Продавнице прехрамбених производа.
# distribution of sales across different outlet types since establishment response = pandas_ai(df, "Visualize the distribution of sales across different outlet types since establishment using bar plot, plot size=(13,10)") response
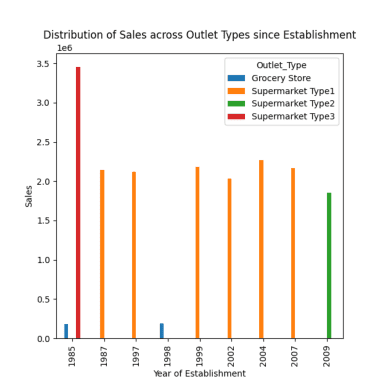 Дистрибуција продаје на различитим продајним местима
Дистрибуција продаје на различитим продајним местима
Као што је примећено у претходним упутствима, врхунац продаје се догодио 1985. године, а ова графика истиче највећу продају у 1985. у супермаркетима типа 3.
# Пречица за цртање тракастог графикона
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Ова пречица ће исцртати тракасти графикон оквира података.
# Пречица за исцртавање хистограма
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Ова пречица ће исцртати хистограм оквира података.
Сада, хајде да сазнамо колика је просечна продаја артикала са садржајем масти „мало масти“ и „редовно“.
Пронађите просечну продају за артикле са масним садржајем
# finding index of a row using value of a column result = pandas_ai(df, "What is the average sales for the items with 'Low Fat' and 'Regular' item fat content?") result
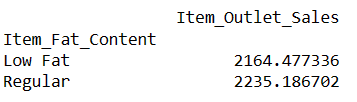
Овакво писање упутстава вам омогућава да упоредите два или више производа.
Просечна продаја за сваку врсту артикла
Желим да упоредим све производе са њиховом просечном продајом.
#Average Sales for Each Item Type result = pandas_ai(df, "What are the average sales for each item type over the past 5 years?, use pie plot, size=(6,6)") result
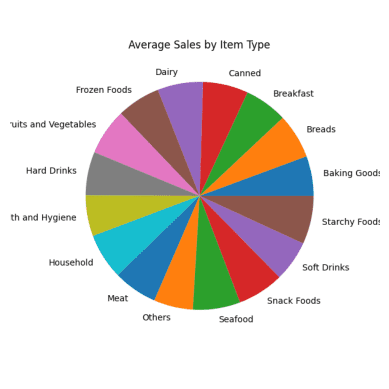 Кружни дијаграм просечне продаје
Кружни дијаграм просечне продаје
Сви делови тортног графикона изгледају слично јер имају скоро исте бројке о продаји.
# Пречица за исцртавање тортног графикона
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Ова пречица ће исцртати кружни графикон оквира података.
Топ 5 најпродаванијих врста артикала
Иако смо већ упоредили све производе на основу просечне продаје, сада бих желео да идентификујем првих 5 артикала са највећом продајом.
#Finding top 5 highest selling items result = pandas_ai(df, "What are the top 5 highest selling item type based on average sells? Write in tablular form") result
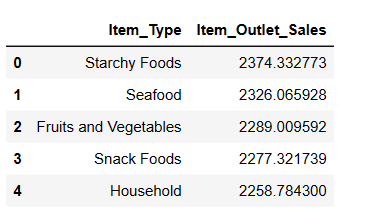
Као што се и очекивало, Старцхи Фоодс је најпродаванији артикл на основу просечне продаје.
5 најпродаванијих врста артикала
result = pandas_ai(df, "What are the top 5 lowest selling item type based on average sells?") result
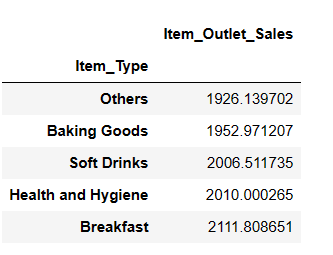
Можда ћете бити изненађени када видите безалкохолна пића у најниже продаваној категорији. Међутим, битно је напоменути да ови подаци иду само до 2008. године, а тренд за безалкохолна пића је кренуо неколико година касније.
Продаја категорија производа
Овде сам користио реч „категорија производа“ уместо „тип артикла“, а ПандасАИ је и даље креирао дијаграме, показујући своје разумевање сличних речи.
result = pandas_ai(df, "Give a stacked large size bar chart of the sales of the various product categories for the last FY") result
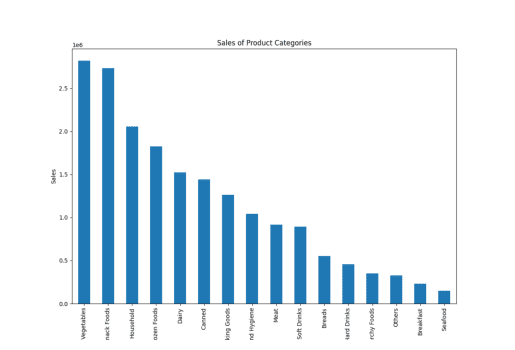 Продаја типа артикла
Продаја типа артикла
Можете пронаћи наше преостале пречице Ево.
Можда ћете приметити да када напишемо промпт и пружимо упутства ПандасАИ-у, он даје резултате засноване искључиво на том специфичном одзиву. Не анализира ваше претходне упите да би понудио тачније одговоре.
Међутим, уз помоћ агента за ћаскање, можете постићи и ову функционалност.
Цхат Агент
Са агентом за ћаскање, можете се укључити у динамичне разговоре у којима агент задржава контекст током дискусије. Ово вам омогућава да имате интерактивније и садржајније размене.
Кључне карактеристике које омогућавају ову интеракцију укључују задржавање контекста, где агент памти историју разговора, омогућавајући беспрекорне интеракције које су свесне контекста. Можете да користите метод Питања за појашњење да бисте затражили појашњење било ког аспекта разговора, обезбеђујући да у потпуности разумете дате информације.
Штавише, метода Екплаин је доступна за добијање детаљних објашњења о томе како је агент дошао до одређеног решења или одговора, нудећи транспарентност и увид у агентов процес доношења одлука.
Слободно започните разговоре, тражите појашњења и истражите објашњења како бисте побољшали своју интеракцију са агентом за ћаскање!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Which are top 5 items with highest MRP")
result
За разлику од СмартДатафраме-а или СмартДаталаке-а, агент ће пратити стање разговора и моћи ће да одговори на разговоре у више кругова.
Идемо према предностима и ограничењима ПандасАИ-а
Предности ПандасАИ
Коришћење Пандас АИ нуди неколико предности које га чине вредним алатом за анализу података, као што су:
- Приступачност: ПандасАИ поједностављује анализу података, чинећи их доступним широком спектру корисника. Свако, без обзира на техничку позадину, може да га користи да извуче увид из података и одговори на пословна питања.
- Упити природног језика: Могућност директног постављања питања и добијања одговора из података помоћу упита природног језика чини истраживање и анализу података лакшим за корисника. Ова функција омогућава чак и нетехничким корисницима да ефикасно комуницирају са подацима.
- Функционалност ћаскања са агентима: Функција ћаскања омогућава корисницима да интерактивно комуницирају са подацима, док функција ћаскања са агентима користи претходну историју ћаскања да би пружила одговоре који су свесни контекста. Ово промовише динамичан и разговорни приступ анализи података.
- Визуелизација података: ПандасАИ пружа низ опција за визуелизацију података, укључујући топлотну мапу, дијаграме расејања, тракасте графиконе, кружне графиконе, линијске графиконе и још много тога. Ове визуелизације помажу у разумевању и представљању образаца података и трендова.
- Пречице које штеде време: Доступност пречица и функција које штеде време поједностављују процес анализе података, помажући корисницима да раде ефикасније и ефективније.
- Компатибилност датотека: ПандасАИ подржава различите формате датотека, укључујући ЦСВ, Екцел, Гоогле табеле и још много тога. Ова флексибилност омогућава корисницима да раде са подацима из различитих извора и формата.
- Прилагођени упити: Корисници могу да креирају прилагођене упите користећи једноставна упутства и Питхон код. Ова функција омогућава корисницима да прилагоде своју интеракцију са подацима тако да одговарају специфичним потребама и упитима.
- Сачувај промене: Могућност чувања промена унесених у оквире података обезбеђује очување вашег рада и можете поново да посетите и поделите своју анализу у било ком тренутку.
- Прилагођени одговори: Опција за креирање прилагођених одговора омогућава корисницима да дефинишу специфична понашања или интеракције, чинећи алат још разноврснијим.
- Интеграција модела: ПандасАИ подржава различите језичке моделе, укључујући моделе Хуггинг Фаце, Азуре, Гоогле Палм, Гоогле ВертекАИ и ЛангЦхаин. Ова интеграција побољшава могућности алата и омогућава напредну обраду и разумевање природног језика.
- Уграђена подршка за ЛангЦхаин: Уграђена подршка за ЛангЦхаин моделе додатно проширује опсег доступних модела и функционалности, побољшавајући дубину анализе и увида који се могу извести из података.
- Разумевање имена: ПандасАИ показује способност разумевања корелације између назива колона и терминологије из стварног живота. На пример, чак и ако користите термине као што је „категорија производа“ уместо „тип ставке“ у својим упитима, алатка и даље може да пружи релевантне и тачне резултате. Ова флексибилност у препознавању синонима и њиховом мапирању у одговарајуће колоне података побољшава удобност корисника и прилагодљивост алата упитима природног језика.
Иако ПандасАИ нуди неколико предности, такође долази са неким ограничењима и изазовима којих би корисници требали бити свјесни:
Ограничења ПандасАИ-а
Ево неких ограничења која сам приметио:
- Захтев АПИ кључа: Да бисте користили ПандасАИ, неопходно је имати АПИ кључ. Ако немате довољно кредита на свом ОпенАИ налогу, можда нећете моћи да користите услугу. Међутим, вреди напоменути да ОпенАИ обезбеђује кредит од 5 долара за нове кориснике, што га чини доступним онима који су нови на платформи.
- Време обраде: Понекад услуга може имати кашњења у пружању резултата, што се може приписати великој употреби или оптерећењу сервера. Корисници треба да буду спремни на потенцијална времена чекања када траже услугу.
- Тумачење упита: Иако можете постављати питања путем упита, способност система да објасни одговоре можда није у потпуности развијена, а квалитет објашњења може варирати. Овај аспект ПандасАИ-а може се побољшати у будућности даљим развојем.
- Осетљивост на брзе поруке: Корисници треба да буду опрезни када праве упите, јер чак и мале промене могу довести до различитих резултата. Ова осетљивост на фразирање и брзу структуру може утицати на конзистентност резултата, посебно када радите са графиконима података или сложенијим упитима.
- Ограничења на сложене упите: ПандасАИ можда неће управљати веома сложеним упитима или упитима тако ефикасно као једноставнијим. Корисници треба да буду свесни сложености својих питања и да се увере да је алатка погодна за њихове специфичне потребе.
- Недоследне промене оквира података: Корисници су пријавили проблеме са уношењем измена у оквире података, као што је попуњавање нул вредности или испуштање редова са нултим вредностима, чак и када су навели „Инплаце=Труе“. Ова недоследност може бити фрустрирајућа за кориснике који покушавају да измене своје податке.
- Променљиви резултати: Приликом поновног покретања кернела или поновног покретања упита, могуће је добити различите резултате или интерпретације података из претходних покретања. Ова варијабилност може бити изазовна за кориснике којима су потребни доследни и поновљиви резултати. Није применљиво на све упите.
Можете преузети скуп података овде.
Код је доступан на ГитХуб.
Закључак
ПандасАИ нуди једноставан приступ анализи података, доступан чак и онима који немају опсежне вештине кодирања.
У овом чланку сам покрио како да подесим и користим ПандасАИ за анализу података, укључујући креирање дијаграма, руковање нултим вредностима и коришћење предности функције ћаскања са агентима.
Претплатите се на наш билтен за више информативних чланака. Можда ћете бити заинтересовани да сазнате о АИ моделима за стварање генеративне АИ.
Да ли је овај чланак био од помоћи?
Хвала на повратним информацијама!