Уколико сте почетник у свету анализе великих података, вероватно сте наишли на бројне Apache алате. Међутим, обиље различитих опција може бити збуњујуће и понекад чак и обесхрабрујуће.
Овај чланак има за циљ да разјасни ту конфузију и објасни шта тачно представљају Apache Hive и Impala, као и по чему се међусобно разликују!
Apache Hive
Apache Hive је SQL интерфејс који омогућава приступ подацима на Apache Hadoop платформи. Hive вам омогућава да постављате упите, обједињујете и анализирате податке користећи SQL синтаксу.
За читање података у HDFS систему датотека користи се приступ са шемом, што вам омогућава да третирате податке као обичну табелу или релациони DBMS. HiveQL упити се претварају у Java код за MapReduce послове.
Упити у Hive-у се пишу на HiveQL језику, који је базиран на SQL језику, али не подржава у потпуности SQL-92 стандард.
Ипак, овај језик омогућава програмерима да користе своје упите када је неефикасно или непогодно користити HiveQL функције. HiveQL се може проширити кориснички дефинисаним скаларним функцијама (UDF), агрегацијама (UDAF кодови) и функцијама табеле (UDTF).
Како функционише Apache Hive
Apache Hive трансформише програме написане у HiveQL (сличан SQL-у) у један или више MapReduce задатака, Apache Tez или Apache Spark задатака. Ово су три механизма за извршавање који се могу покренути на Hadoop-у. Затим, Apache Hive организује податке у низу за Hadoop Distributed File System (HDFS) ради покретања задатака на кластеру и генерисања одговора.
Apache Hive табеле су аналогне релационим базама података, а јединице података су организоване од најзначајније ка најситнијој. Базе података су низови састављени од партиција, које се даље могу поделити у „канте“.
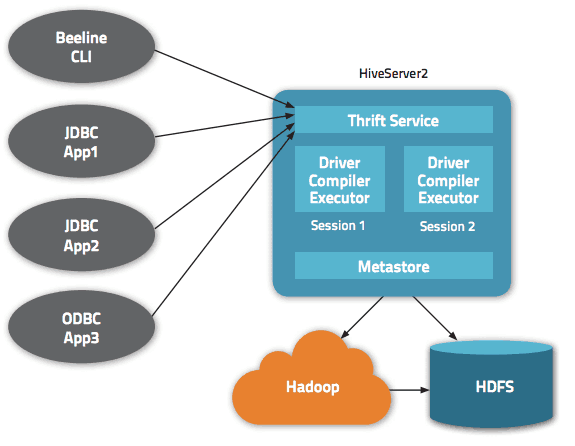
Подаци су доступни путем HiveQL-а. Унутар сваке базе података, подаци су нумерисани, а свака табела одговара HDFS директоријуму.
У архитектури Apache Hive доступни су различити интерфејси, попут веб интерфејса, CLI-а или екстерних клијената.
Сервер „Apache Hive Thrift“ омогућава удаљеним клијентима да подносе команде и захтеве Apache Hive-у користећи различите програмске језике. Централна компонента Apache Hive-а је „метасторе“ која садржи све информације.
Мотор који омогућава рад Hive-а назива се „возач“. Он обједињује компајлер и оптимизатор како би се одредио оптималан план извршења.
На крају, безбедност је обезбеђена путем Hadoop-а. Ослања се на Kerberos за међусобну аутентификацију између клијента и сервера. Дозволе за новокреиране датотеке у Apache Hive-у регулише HDFS, омогућавајући ауторизацију на нивоу корисника, групе или на друге начине.
Карактеристике Hive-а
- Подржава механизме за рачунање Hadoop и Spark
- Користи HDFS и функционише као складиште података
- Користи MapReduce и подржава ETL процесе
- Захваљујући HDFS-у, има толеранцију грешака сличну Hadoop-у
Apache Hive: Предности
Apache Hive је одлично решење за упите и анализу података. Омогућава добијање квалитативних увида, обезбеђујући конкурентску предност и олакшавајући одговор на захтеве тржишта.
Међу кључним предностима Apache Hive-а, истиче се једноставност употребе повезана са његовим „SQL-friendly“ језиком. Поред тога, убрзава се почетно уметање података јер подаци не морају да се читају или нумеришу са диска у интерном формату базе података.
С обзиром на то да се подаци складиште у HDFS-у, могуће је складиштити велике скупове података, чак до стотина петабајта, на Apache Hive-у. Ово решење је знатно скалабилније од традиционалних база података. Како је реч о услузи у облаку, Apache Hive корисницима омогућава брзо покретање виртуелних сервера на основу промена у оптерећењу (тј. задацима).
Безбедност је такође аспект у коме Hive показује боље резултате, са могућношћу реплицирања радних оптерећења критичних за опоравак у случају проблема. На крају, радна способност је изузетна јер може да обради и до 100.000 захтева на сат.
Apache Impala
Apache Impala је масивно паралелни SQL механизам за интерактивно извршавање SQL упита над подацима складиштеним у Apache Hadoop-у. Написана је у C++ и дистрибуира се под Apache 2.0 лиценцом.
Impala се такође назива MPP (масивно паралелна обрада) машина, дистрибуирани DBMS, па чак и SQL-on-Hadoop база података.

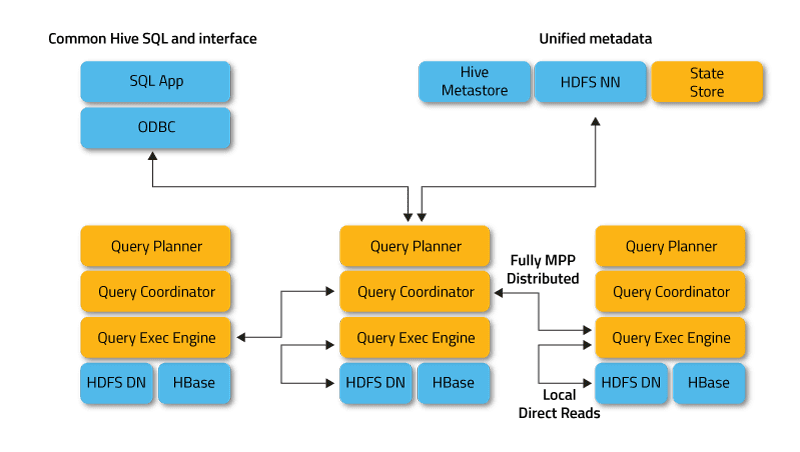
Impala ради у дистрибуираном режиму, где се инстанце процеса покрећу на различитим чворовима кластера, примајући, распоређујући и координирајући захтеве клијената. На тај начин је омогућено паралелно извршавање фрагмената SQL упита.
Клијенти су корисници и апликације које шаљу SQL упите ка подацима складиштеним у Apache Hadoop (HBase и HDFS) или Amazon S3. Интеракција са Impala-ом се одвија преко HUE (Hadoop User Experience) веб интерфејса, ODBC, JDBC и командне линије Impala Shell-а.
Impala инфраструктурно зависи од другог популарног SQL-on-Hadoop алата, Apache Hive-а, користећи његов метаподатак. Конкретно, Hive Metastore омогућава Impala-и да зна о доступности и структури база података.
Када креирате, мењате и бришете објекте шеме или учитавате податке у табеле путем SQL наредби, одговарајуће промене метаподатака аутоматски се прослеђују свим Impala чворовима користећи посебну услугу директоријума.
Кључне компоненте Impala-е су следеће извршне датотеке:
- Impalad или Impala демон је системска услуга која заказује и извршава упите за HDFS, HBase и Amazon S3 податке. Један impalad процес се покреће на сваком чвору кластера.
- Statestore је услуга именовања која прати локацију и статус свих impalad инстанци у кластеру. Једна инстанца ове системске услуге ради на сваком чвору и главном серверу (Name Node).
- Catalog је услуга координације метаподатака која прослеђује промене из Impala DDL и DML изјава свим Impala чворовима тако да су нове табеле или новоучитани подаци одмах видљиви на било ком чвору у кластеру. Препоручује се да једна инстанца Catalog-а ради на истом хосту кластера као и Statestored демон.
Како функционише Apache Impala
Impala, слично као Apache Hive, користи сличан декларативни језик упита, Hive Query Language (HiveQL), који је подскуп SQL92, уместо чистог SQL-а.
Само извршење захтева у Impala-и тече на следећи начин:
Клијентска апликација шаље SQL упит повезивањем на било који impalad путем стандардизованих ODBC или JDBC драјверских интерфејса. Повезани impalad постаје координатор тренутног захтева.
SQL упит се анализира како би се дефинисали задаци за impalad инстанце у кластеру; затим се креира оптимални план извршења упита.
Impalad директно приступа HDFS-у и HBase-у користећи локалне инстанце системских услуга за обезбеђивање података. За разлику од Apache Hive-а, оваква директна интеракција значајно уштеђује време извршења упита, јер се међурезултати не чувају.
Сваки демон враћа податке координационом impalad-у, прослеђујући резултате назад клијенту.
Карактеристике Impala-е
- Подршка за обраду меморије у реалном времену
- SQL-friendly
- Подржава системе за складиштење попут HDFS-а, Apache HBase-а и Amazon S3-а
- Подржава интеграцију са BI алатима попут Pentaho-a и Tableau-a
- Користи HiveQL синтаксу
Apache Impala: Предности
Impala избегава могуће трошкове покретања јер се сви процеси демон система покрећу директно при покретању. То значајно штеди време извршења упита. Додатно повећање брзине Impala-е је због тога што овај SQL алат за Hadoop, за разлику од Hive-а, не складишти међурезултате и директно приступа HDFS-у или HBase-у.
Поред тога, Impala генерише програмски код током извршавања, а не приликом компилације, као што то ради Hive. Међутим, нуспојава брзих перформанси Impala-е је смањена поузданост.
Конкретно, уколико се чвор података поквари током извршавања SQL упита, Impala инстанца ће се рестартовати, док ће Hive наставити да одржава везу са извором података, обезбеђујући толеранцију грешака.
Остале предности Impala-е укључују уграђену подршку за Kerberos протокол за безбедну мрежну аутентификацију, одређивање приоритета и управљање редоследом захтева, као и подршку за популарне формате великих података, као што су LZO, Avro, RCFile, Parquet и Sequence.
Hive vs Impala: Сличности
Hive и Impala се слободно дистрибуирају под лиценцом Apache Software Foundation и спадају у SQL алате за рад са подацима складиштеним у Hadoop кластеру. Поред тога, оба користе HDFS дистрибуирани систем датотека.
Impala и Hive извршавају различите задатке, са заједничким фокусом на SQL обраду великих података ускладиштених у Apache Hadoop кластеру. Impala нуди интерфејс сличан SQL-у, омогућавајући вам да читате и пишете Hive табеле, чиме се олакшава размена података.
Истовремено, Impala чини SQL операције на Hadoop-у доста брзим и ефикасним, што омогућава коришћење овог DBMS-а у истраживачким пројектима аналитике великих података. Кад год је то могуће, Impala ради са већ постојећом Apache Hive инфраструктуром која се користи за извршавање дуготрајних SQL групних упита.
Такође, Impala чува своје дефиниције табела у метастору, традиционалној MySQL или PostgreSQL бази података, тј. на истом месту где Hive складишти сличне податке. Ово омогућава Impala-и да приступи Hive табелама све док све колоне користе типове података, формате датотека и кодеке за компресију које подржава Impala.
Hive vs Impala: Разлике

Програмски језик
Hive је написан у Јави, док је Impala написана у C++. Међутим, Impala такође користи неке Hive UDF-ове засноване на Јави.
Случајеви употребе
Инжењери података користе Hive у ETL процесима (Extract, Transform, Load), на пример, за дуготрајне групне послове на великим скуповима података, као на пример, у агрегаторима путовања и аеродромским информационим системима. Заузврат, Impala је намењена углавном аналитичарима и научницима података и најчешће се користи у задацима као што је пословна интелигенција.
Перформансе
Impala извршава SQL упите у реалном времену, док Hive карактерише нижа брзина обраде података. Код једноставних SQL упита, Impala може бити 6-69 пута бржа од Hive-а. Међутим, Hive боље обрађује сложене упите.
Латенција/пропусност
Пропусност Hive-а је знатно већа од пропусности Impala-е. Llap (Live Long and Process) функција, која омогућава кеширање упита у меморији, даје Hive-у добре перформансе ниског нивоа.
Llap укључује дугорочне системске услуге (демоне), које омогућавају директну интеракцију са HDFS чворовима података и замењују чврсто интегрисану DAG структуру упита (Directed Acyclic Graph) – модел графа који се активно користи у рачунарству великих података.
Толеранција грешака
Hive је систем отпоран на грешке који чува све међурезултате. То позитивно утиче на скалабилност, али доводи до смањења брзине обраде података. Заузврат, Impala се не може сматрати платформом отпорном на грешке, јер је више везана за меморију.
Конверзија кода
Hive генерише изразе упита у време компилације, док их Impala генерише током извршавања. Hive карактерише проблем „хладног старта“ при првом покретању апликације; упити се споро конвертују због потребе за успостављањем везе са извором података.
Impala нема овакве трошкове покретања. Неопходне системске услуге (демони) за обраду SQL упита се покрећу приликом покретања система, што убрзава рад.
Подршка за складиштење
Impala подржава LZO, Avro и Parquet формате, док Hive ради са Plain Text и ORC форматима. Међутим, оба подржавају RCFile и Sequence формате.
| Apache Hive | Apache Impala | |
| Језик | Java | C++ |
| Случајеви употребе | Инжењеринг података | Анализа и аналитика |
| Перформансе | Висока за једноставне упите | Релативно ниско кашњење |
| Латенција | Више кашњења због кеширања | Мање латентно |
| Толеранција грешака | Толерантније због MapReduce | Мање толерантно због МПП |
| Покретање | Хладно покретање | МПП покретање |
Закључне речи
Hive и Impala се не такмиче, већ се ефикасно допуњују. Иако постоје значајне разлике између њих, постоји и доста заједничког, а избор једног у односу на друго зависи од података и специфичних захтева пројекта.
Такође, можете истражити директна поређења између Hadoop-а и Spark-а.