Премештање база података у облак: Изазови и решења
Током протеклих двадесет година, развој корпоративног софтвера је показао јасан тренд – миграција база података у облак. Овај помак је постао свеприсутан у последњим годинама.
Из личног искуства, учествовао сам у неколико пројеката чији је циљ био пребацивање постојећих локалних база података у AWS Cloud. Иако AWS документација често представља овај процес као једноставан, реалност је често другачија. У пракси, миграција може наићи на разне препреке и чак пропасти.
У овом чланку, поделићу искуства из стварних ситуација везаних за миграцију база података, фокусирајући се на следеће аспекте:
- Извор: Иако је у теорији изворна база података мање битна (сличан приступ се може применити на већину популарних система), Oracle је дуго био водећи избор у великим корпорацијама, и зато ћу се на њега посебно фокусирати.
- Циљ: Са циљне стране, није потребно бити прецизан. Можете одабрати било коју AWS базу података, а приступ ће и даље бити релевантан.
- Режим: Миграција може бити потпуна или постепена. Можемо изабрати скупно учитавање података (где су изворно и циљно стање одвојени) или скоро тренутно учитавање података у реалном времену. Оба приступа ће бити размотрена.
- Учесталост: Можда ћете желети једнократну миграцију уз потпуни прелазак на облак, или ћете имати прелазни период са паралелним ажурирањем података на обе стране. Ово друго захтева развој синхронизације између локалне и AWS базе података. Први приступ је једноставнији, али други је чешћи и компликованији. Размотрићемо оба приступа.
Анализа проблема
Често се захтев за миграцију једноставно формулише:
Желимо да почнемо развијати сервисе у AWS-у, па пребаците све наше податке у „XYZ“ базу. Желимо брзо и једноставно да приступимо тим подацима. Касније ћемо размотрити како да прилагодимо структуру базе података нашим потребама.
Пре него што се упустите у реализацију, размотрите следеће:
- Не прихватајте олако идеју „само ископирајте податке па ћемо после видјети“. Иако је ово најједноставније решење, оно може створити велике архитектонске проблеме које ће касније бити тешко исправити без темељног рефакторисања целе нове платформе у облаку. Имајте на уму да је екосистем у облаку другачији од локалног. Временом ће се уводити нове услуге и људи ће почети да користе податке на различите начине. Скоро никада није добра идеја да се 1:1 реплицира локално стање у облаку. У неким случајевима можда јесте, али вреди размотрити још једном.
- Преиспитајте захтев са кључним питањима:
- Ко ће бити типични корисник нове платформе? Док су на локалној платформи то можда трансакциони пословни корисници, у облаку то могу бити научници података, аналитичари или саме услуге (нпр. Databricks, Glue, модели машинског учења).
- Да ли се очекује да ће редовне дневне активности остати исте након миграције у облак? Ако не, како се очекују промене?
- Да ли планирате значајан раст података у будућности? Највероватније је одговор да, јер је то често главни разлог миграције у облак. Нови модел података треба да буде спреман за то.
- Очекујте од крајњег корисника да размисли о типичним упитима које ће нова база података примати. Ово ће помоћи да се одреди како постојећи модел података треба прилагодити ради бољих перформанси.
Подешавање процеса миграције
Након што одаберете циљну базу података и пажљиво размотрите модел података, следећи корак је упознавање са AWS алатом за конверзију шема. Овај алат може вам помоћи у следећим аспектима:
- Анализирајте и екстрахујте изворни модел података. SCT (Schema Conversion Tool) анализира локалну базу података и генерише модел података за почетак.
- Предложите структуру циљног модела података на основу циљне базе.
- Генеришите скрипте за креирање циљне базе података (на основу анализе изворне базе). Након извршавања ових скрипти, база података у облаку ће бити спремна за учитавање података са локалне базе.
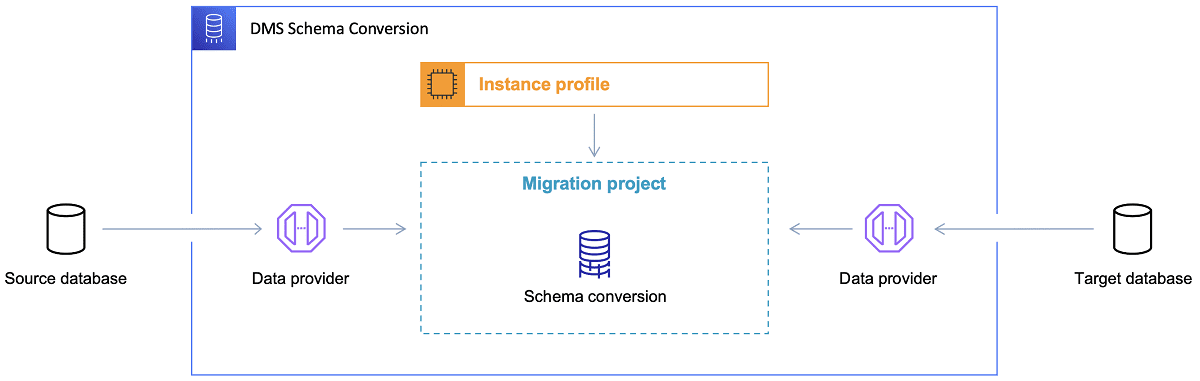 Референца: AWS документација
Референца: AWS документација
Сада, неколико савета о коришћењу алата за конверзију шема:
Прво, скоро никада не би требало директно користити генерисани излаз. Сматрајте га референцом за прилагођавање на основу вашег разумевања података и начина на који ће се подаци користити у облаку.
Друго, табеле су раније биле прилагођене брзим резултатима на основу конкретних ентитета. Сада, подаци се могу користити за аналитичке сврхе. Индекси који су били корисни на локалној бази, сада можда неће побољшати перформансе ДБ система. Можда ћете такође желети другачије партиционисање података у циљном систему.
Такође, размислите о трансформацији података током миграције, што подразумева промену циљног модела за неке табеле (да не буду 1:1 копије). Правила трансформације ће касније морати бити имплементирана у алат за миграцију.
Ако су изворна и циљна база истог типа (нпр. Oracle on-premise vs. Oracle у AWS-у), најбоље је користити алате за миграцију које подржава конкретна база (нпр. извоз и увоз пумпе података, Oracle GoldenGate).
Међутим, најчешће изворна и циљна база нису компатибилне, у том случају је AWS Database Migration Service (DMS) најбољи избор.
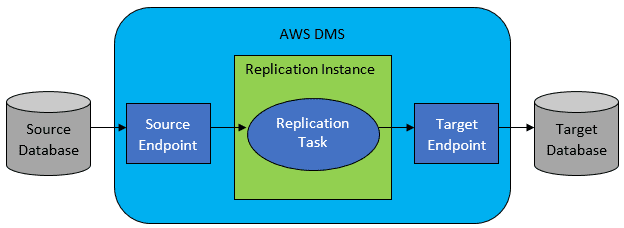 Референца: AWS документација
Референца: AWS документација
AWS DMS омогућава конфигурисање задатака на нивоу табеле који дефинишу:
- Изворну базу података и табелу за повезивање.
- Упит који ће се користити за добијање података за циљну табелу.
- Алате за трансформацију (ако их има) који дефинишу како ће се изворни подаци мапирати у циљну табелу (ако није 1:1).
- Циљну базу података и табелу за учитавање података.
Конфигурација DMS задатака се врши у корисничком формату као што је JSON.
У најједноставнијем случају, потребно је само покренути скрипте за креирање циљне базе и покренути DMS задатке. Али, ситуација је често компликованија.
Једнократна потпуна миграција података

Најједноставнији сценарио је када се цела база података премешта у циљну базу у облаку. У том случају, све што треба да урадите је:
- Дефинисати DMS задатак за сваку изворну табелу.
- Правилно конфигурисати DMS задатке, подесити паралелизам, кеширање, димензионисање DMS кластера итд. Ова фаза обично траје најдуже и захтева тестирање и фино подешавање.
- Уверити се да је свака циљна табела креирана (празна) у циљној бази, са очекиваном структуром.
- Заказати временски оквир за извршавање миграције. Претходно тестирајте да ли је време довољно. Током миграције, изворна база може бити оптерећена, и не би требало да се мења. У супротном, мигрирани подаци се могу разликовати од података у изворној бази.
Ако је DMS добро конфигурисан, не би требало да буде проблема. Свака изворна табела биће копирана у AWS циљну базу података. Једини проблем може бити праћење величине података и спречавање прекида због недостатка простора.
Инкрементална дневна синхронизација

Овде ствари постају компликованије. У идеалним условима све би функционисало савршено, али свет није идеалан.
DMS се може конфигурисати у два режима:
- Потпуно учитавање – подразумевани режим описан горе. DMS задаци се извршавају при покретању или по плану. Када заврше, задаци су готови.
- Change Data Capture (CDC) – у овом режиму, DMS задатак ради непрекидно. DMS скенира изворну базу и реагује на промене на нивоу табеле. Ако се промена догоди, она се реплицира у циљну базу, на основу конфигурације DMS задатка.
Када користите CDC, потребно је одабрати како ће CDC издвајати промене из изворне базе података.
#1. Oracle Redo Logs Reader
Једна опција је да користите читач редо дневника базе података из Oracle-а, који CDC може користити за добијање измењених података и реплицирање истих у циљну базу.
Иако је ово очигледан избор ако је Oracle извор, постоји проблем: Oracle Redo Logs читач користи изворни Oracle кластер и директно утиче на све остале активности у бази података (креира активне сесије у бази података).
Што више DMS задатака конфигуришете (или DMS кластера паралелно), већа је потреба за повећањем Oracle кластера (вертикално скалирање). Ово ће повећати трошкове решења, посебно ако дневна синхронизација остане присутна дуго времена.
#2. AWS DMS Log Miner
Ово је AWS решење за исти проблем. У овом случају, DMS не утиче на изворни Oracle DB. Уместо тога, копира Oracle redo logs у DMS кластер и тамо врши обраду. Иако штеди Oracle ресурсе, спорије је јер је укључено више операција. Такође, прилагођени читач за Oracle redo logs је спорији у односу на изворни читач из Oracle-а.
У зависности од величине изворне базе података и броја дневних промена, у најбољем случају можете добити инкременталну синхронизацију података из локалне Oracle базе података у AWS cloud базу података у скоро реалном времену.
У осталим случајевима, неће бити синхронизација у реалном времену, али се можете приближити жељеном кашњењу подешавањем перформанси изворног и циљног кластера, паралелизма и експериментисањем са бројем DMS задатака и њиховом дистрибуцијом између CDC инстанци.
Такође, потребно је знати које промене изворне табеле подржава CDC (као што је додавање колоне), јер нису све могуће промене подржане. У неким случајевима, једино решење је ручно променити циљну табелу и поново покренути CDC задатак (при томе губећи постојеће податке у циљној бази).
Када ствари крену наопако

Постоји један специфичан сценарио са DMS-ом, где је тешко постићи обећану свакодневну репликацију.
DMS може обрађивати redo logs само одређеном брзином. Није важно колико инстанци DMS-а извршава ваше задатке, свака чита redo logs само једном дефинисаном брзином и мора их прочитати у целости. Небитно је и да ли користите Oracle redo logs или AWS log miner. Оба имају ово ограничење.
Ако изворна база има велики број промена током дана, па Oracle redo logs постану велики (500GB+ сваког дана), CDC неће радити. Репликација неће бити завршена пре краја дана. Необрађени подаци ће се гомилати сваког дана.
У овом случају, CDC није био опција (након тестирања перформанси). Једини начин да се обезбеди репликација делта промена истог дана је био следећи приступ:
- Одвојити велике табеле које се не користе често и реплицирати их само једном недељно (нпр. викендом).
- Конфигурисати репликацију мањих табела између неколико DMS задатака; једна табела је мигрирана са 10+ одвојених задатака паралелно, уз различиту поделу података (коришћено је прилагођено кодирање), а сви су се извршавали свакодневно.
- Додати још (до 4) инстанце DMS-а и равномерно поделити задатке између њих, не само по броју, већ и по величини табела.
У суштини, користили смо режим потпуног учитавања DMS-а за реплицирање дневних података јер је то био једини начин да се заврши репликација истог дана.
Није савршено решење, али функционише годинама. Можда ипак није тако лоше. 😃