Razumevanje istraživačke analize podataka (EDA)
Saznajte sve o istraživačkoj analizi podataka, ključnom procesu koji se koristi za otkrivanje trendova, obrazaca i sumiranje skupova podataka uz pomoć statističkih prikaza i grafičkih ilustracija.
Kao i svaki drugi projekat, i projekat u nauci o podacima je dug proces koji iziskuje vreme, organizaciju i savesno praćenje koraka. Istraživačka analiza podataka (EDA) predstavlja jedan od najvažnijih koraka u ovom procesu.
U ovom članku ćemo ukratko objasniti šta je istraživačka analiza podataka i kako se ona može sprovesti pomoću R programskog jezika!
Šta je istraživačka analiza podataka?
Istraživačka analiza podataka (EDA) je proces ispitivanja i proučavanja karakteristika skupa podataka pre nego što se primeni na neku aplikaciju, bilo da je reč o poslovnoj, statističkoj ili mašinskom učenju.
Ovaj sažeti pregled prirode podataka i njihovih ključnih karakteristika obično se obavlja putem vizuelnih metoda, kao što su grafikoni i tabele. Praksa se primenjuje unapred kako bi se procenio potencijal podataka, koji će se u budućnosti koristiti u složenijim procesima.
EDA, stoga, omogućava:
- Formulisanje hipoteza za korišćenje tih informacija;
- Istraživanje skrivenih detalja u strukturi podataka;
- Identifikovanje nedostajućih vrednosti, odstupanja ili neuobičajenog ponašanja;
- Otkrivanje trendova i relevantnih varijabli;
- Odbacivanje irelevantnih varijabli ili varijabli koje su u korelaciji sa drugim;
- Određivanje formalnog modeliranja koje će se koristiti.
Koja je razlika između deskriptivne i istraživačke analize podataka?
Postoje dve glavne vrste analize podataka, deskriptivna analiza i istraživačka analiza podataka, koje se međusobno dopunjuju, uprkos različitim ciljevima.
Dok se prva fokusira na opisivanje ponašanja varijabli, na primer, srednje vrednosti, medijane, moda, itd.
Istraživačka analiza ima za cilj da identifikuje odnose između varijabli, izvuče preliminarne zaključke i usmeri modeliranje prema najčešćim paradigmama mašinskog učenja: klasifikaciji, regresiji i grupisanju.
Obe analize se mogu baviti grafičkim predstavljanjem, međutim, samo istraživačka analiza nastoji da pruži zaključke koji se mogu primeniti, odnosno one koji motivišu na akciju donosioce odluka.
Konačno, dok istraživačka analiza podataka nastoji da reši probleme i pruži rešenja koja će voditi korake modeliranja, deskriptivna analiza, kao što joj ime sugeriše, ima za cilj samo da proizvede detaljan opis skupa podataka u pitanju.
| Deskriptivna analiza | Istraživačka analiza podataka | |
| Fokus | Analizira ponašanje | Analizira ponašanje i odnose |
| Cilj | Pruža rezime | Vodi ka specifikacijama i akcijama |
| Prezentacija | Organizuje podatke u tabele i grafikone | Organizuje podatke u tabele i grafikone |
| Moć objašnjenja | Nema značajnu moć objašnjenja | Ima značajnu moć objašnjenja |
Neki primeri praktične primene EDA
#1. Digitalni marketing
Digitalni marketing je evoluirao od kreativnog procesa do procesa vođenog podacima. Marketinške organizacije koriste istraživačku analizu podataka kako bi procenile rezultate kampanja i usmerile potrošačka ulaganja i odluke o ciljanju.
Demografske studije, segmentacija kupaca i druge tehnike omogućavaju trgovcima da koriste velike količine podataka o kupovini potrošača, anketama i panel podacima kako bi razumeli i unapredili marketinšku strategiju.
Analitika veb istraživanja omogućava trgovcima da prikupljaju informacije na nivou sesije o interakcijama na veb lokaciji. Google analitika je primer besplatnog i popularnog alata za analitiku koji trgovci koriste u tu svrhu.
Istraživačke tehnike koje se često koriste u marketingu uključuju modeliranje marketinškog miksa, analize cena i promocija, optimizaciju prodaje i analizu kupaca, na primer, segmentaciju.
#2. Istraživačka analiza portfolija
Uobičajena primena istraživačke analize podataka je analiza portfolija. Banka ili agencija za kreditiranje poseduje zbirku računa različite vrednosti i rizika.
Računi se mogu razlikovati u zavisnosti od društvenog statusa vlasnika (bogat, srednja klasa, siromašan, itd.), geografske lokacije, neto vrednosti i mnogih drugih faktora. Zajmodavac mora da uravnoteži prinos na kredit sa rizikom neispunjenja obaveza za svaki zajam. Postavlja se pitanje kako vrednovati portfolio u celini.
Zajam sa najnižim rizikom može biti za veoma bogate ljude, ali je broj bogatih ljudi ograničen. S druge strane, mnogi siromašni ljudi mogu da pozajmljuju, ali uz veći rizik.
Rešenje za istraživačku analizu podataka može kombinovati analizu vremenskih serija sa drugim faktorima kako bi se odlučilo kada odobriti novac različitim segmentima zajmoprimaca ili kolike kamatne stope naplatiti. Kamata se naplaćuje članovima segmenta portfolija kako bi se pokrili gubici.
#3. Istraživačka analiza rizika
Prediktivni modeli u bankarstvu se razvijaju kako bi se osigurala sigurnost u proceni rizika pojedinačnih klijenata. Kreditni rezultati su osmišljeni da predvide neispunjavanje obaveza pojedinca i koriste se za procenu kreditne sposobnosti svakog kandidata.
Pored toga, analiza rizika se sprovodi u naučnim krugovima i u industriji osiguranja. Takođe se široko primenjuje u finansijskim institucijama, kao što su kompanije za online plaćanja, kako bi se procenilo da li je transakcija originalna ili lažna.
U tu svrhu koristi se istorija transakcija klijenta. Ovo se češće koristi prilikom kupovine kreditnom karticom; kada dođe do naglog povećanja broja klijentskih transakcija, klijent dobija poziv za potvrdu da li je on izvršio transakciju. Ovo pomaže u smanjenju gubitaka usled takvih okolnosti.
Istraživačka analiza podataka sa R
Prvi korak za sprovođenje EDA sa R je preuzimanje R baze i R Studio (IDE), zatim instaliranje i učitavanje sledećih paketa:
#Instaliranje paketa
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Učitavanje paketa
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
U ovom vodiču koristićemo skup ekonomskih podataka koji dolazi sa R, a koji sadrži godišnje podatke o ekonomskim pokazateljima američke ekonomije, i promenićemo mu ime u „econ“ radi jednostavnosti:
econ <- ggplot2::economics
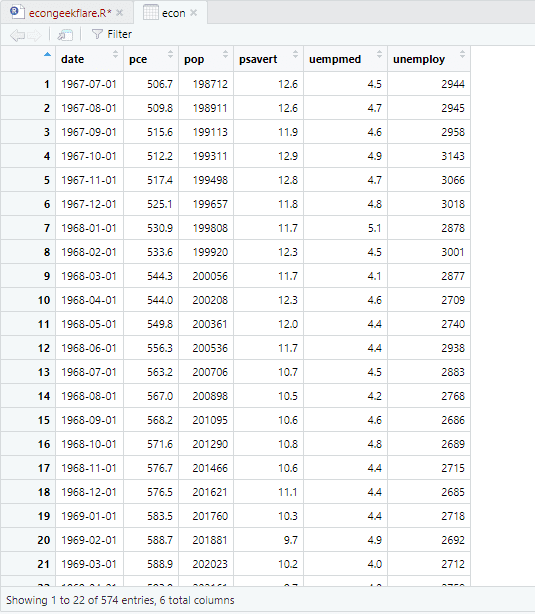
Za deskriptivnu analizu koristićemo paket skimr, koji izračunava statistiku na jednostavan i pregledan način:
#Deskriptivna analiza skimr::skim(econ)

Takođe, za deskriptivnu analizu možete koristiti i funkciju sažetka:
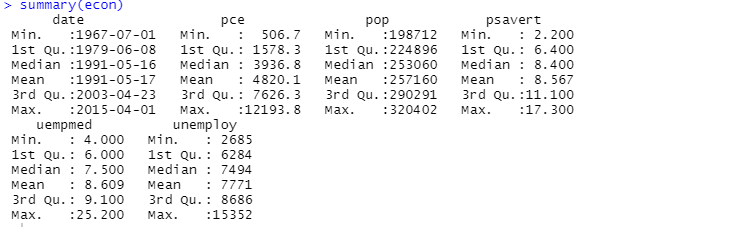
Ovde deskriptivna analiza pokazuje 547 redova i 6 kolona u skupu podataka. Minimalna vrednost je za 1967-07-01, a maksimalna za 2015-04-01. Takođe, prikazuje srednju vrednost i standardnu devijaciju.
Sada imate osnovnu ideju o tome šta se nalazi u skupu podataka „econ“. Nacrtajmo histogram promenljive „uempmed“ da bismo bolje pogledali podatke:
#Histogram nezaposlenosti econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Nezaposlenost", title = "Mesečna stopa nezaposlenosti u SAD od 1967. do 2015. godine")
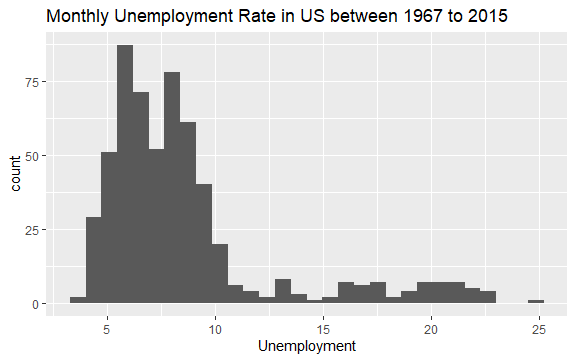
Distribucija histograma pokazuje da postoji izdužen rep na desnoj strani, odnosno da je moguće da postoji nekoliko opservacija ove varijable sa „ekstremnijim“ vrednostima. Postavlja se pitanje: u kom periodu su se ove vrednosti dogodile i kakav je trend varijable?
Najdirektniji način da se identifikuje trend varijable je preko linijskog grafikona. U nastavku generišemo linijski grafikon i dodajemo liniju za izglađivanje:
#Linijski grafikon nezaposlenosti econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
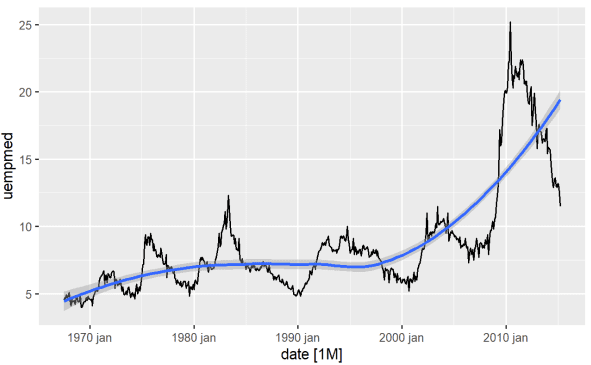
Koristeći ovaj grafikon, možemo identifikovati da u poslednjem periodu, u poslednjim opservacijama iz 2010. godine, postoji tendencija rasta nezaposlenosti, koja prevazilazi istoriju zabeleženu prethodnih decenija.
Druga važna tačka, posebno u kontekstu ekonometrijskog modeliranja, je stacionarnost serije, odnosno da li su srednja vrednost i varijansa konstantne tokom vremena?
Kada ove pretpostavke nisu tačne u varijabli, kažemo da serija ima jedinični koren (nestacionarna) tako da šokovi koje varijabla trpi stvaraju trajni efekat.
Čini se da je to slučaj sa posmatranom varijablom, trajanjem nezaposlenosti. Videli smo da su se fluktuacije varijable značajno promenile, što ima snažne implikacije u vezi sa ekonomskim teorijama koje se bave ciklusima. Ali, ostavljajući teoriju po strani, kako da praktično proverimo da li je varijabla stacionarna?
Paket „forecast“ ima odličnu funkciju koja omogućava primenu testova, kao što su ADF, KPSS i drugi, koji vraćaju broj razlika neophodnih da serija bude stacionarna:
#Korišćenje ADF testa za proveru stacionarnosti forecast::ndiffs( x = econ$uempmed, test = "adf")

Ovde p-vrednost veća od 0.05 ukazuje da podaci nisu stacionarni.
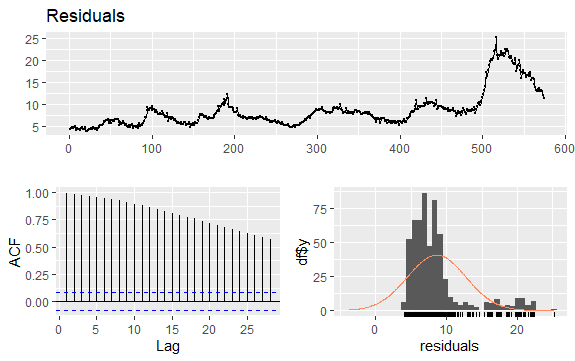
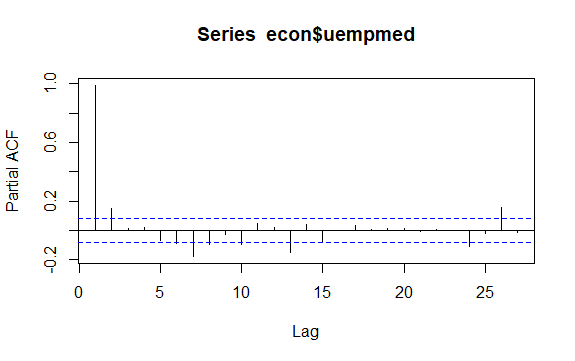
Još jedno važno pitanje kod vremenskih serija je identifikacija mogućih korelacija (linearni odnos) između zaostalih vrednosti serije. Korelogrami ACF i PACF pomažu u identifikaciji.
Kako serija nema sezonalnost, već ima određeni trend, početne autokorelacije imaju tendenciju da budu velike i pozitivne, jer su opservacije bliske u vremenu takođe bliske po vrednosti.
Dakle, funkcija autokorelacije (ACF) vremenske serije u trendu ima tendenciju da ima pozitivne vrednosti koje se polako smanjuju kako se kašnjenje povećava.
#Reziduali nezaposlenosti checkresiduals(econ$uempmed) pacf(econ$uempmed)
Zaključak
Kada se domognemo podataka koji su manje-više čisti, odnosno već sređeni, odmah smo u iskušenju da uronimo u fazu izgradnje modela kako bismo dobili prve rezultate. Moramo se odupreti ovom iskušenju i započeti sa istraživačkom analizom podataka, koja je jednostavna, ali nam pomaže da izvučemo važne uvide iz podataka.
Takođe, možete istražiti i neke od najboljih resursa za učenje statistike u nauci o podacima.