Scikit-LLM je Python paket koji olakšava integraciju naprednih jezičkih modela (LLM) u okvir scikit-learn. Njegova svrha je pomoć pri obavljanju različitih zadataka analize teksta. Ako vam je scikit-learn poznat, rad sa Scikit-LLM-om će biti znatno jednostavniji.
Važno je napomenuti da Scikit-LLM ne zamenjuje scikit-learn. Dok je scikit-learn biblioteka za mašinsko učenje opšte namene, Scikit-LLM je specijalizovan za zadatke obrade i analize teksta.
Početak rada sa Scikit-LLM
Da biste započeli sa Scikit-LLM, potrebno je instalirati biblioteku i konfigurisati vaš API ključ. Prvo, otvorite svoj IDE i napravite novo virtuelno okruženje kako biste izbegli potencijalne sukobe verzija biblioteka. Zatim, u terminalu pokrenite sledeću naredbu:
pip install scikit-llm
Ova komanda će instalirati Scikit-LLM i sve potrebne zavisnosti.
Da biste konfigurisali svoj API ključ, morate ga pribaviti od vašeg LLM provajdera. Za OpenAI API ključ, pratite ove korake:
Idite na OpenAI API stranicu. Zatim kliknite na vaš profil koji se nalazi u gornjem desnom uglu prozora. Izaberite „View API keys“ (Prikaži API ključeve). Ovo će vas odvesti na stranicu sa API ključevima.
Na stranici sa API ključevima kliknite na dugme „Create new secret key“ (Kreiraj novi tajni ključ).
Dajte ime svom API ključu i kliknite na „Create secret key“ (Kreiraj tajni ključ) da biste ga generisali. Nakon generisanja, obavezno kopirajte ključ i sačuvajte ga na sigurnom mestu, jer OpenAI neće ponovo prikazati taj ključ. Ako ga izgubite, moraćete da generišete novi.
Sada kada imate svoj API ključ, otvorite svoj IDE i uvezite klasu `SKLLMConfig` iz biblioteke Scikit-LLM. Ova klasa omogućava podešavanje konfiguracionih opcija koje se tiču upotrebe velikih jezičkih modela.
from skllm.config import SKLLMConfig
Ova klasa očekuje da podesite svoj OpenAI API ključ i detalje organizacije.
SKLLMConfig.set_openai_key("Your API key")
SKLLMConfig.set_openai_org("Your organization ID")
ID organizacije i naziv nisu isto. ID organizacije je jedinstveni identifikator vaše organizacije. Da biste pronašli ID svoje organizacije, idite na OpenAI stranicu podešavanja organizacije i kopirajte ga. Sada ste uspostavili vezu između Scikit-LLM-a i velikog jezičkog modela.
Scikit-LLM zahteva od vas da imate plaćeni plan. To je zato što besplatni probni OpenAI nalog ima ograničenje brzine od tri zahteva u minuti, što nije dovoljno za Scikit-LLM.
Pokušaj korišćenja besplatnog probnog naloga će rezultirati greškom sličnoj onoj ispod tokom analize teksta.

Da biste saznali više o ograničenjima brzine, posetite OpenAI stranicu o ograničenjima brzine.
LLM provajder nije ograničen samo na OpenAI, možete koristiti i druge LLM provajdere.
Uvoz potrebnih biblioteka i učitavanje skupa podataka
Uvezite pandas, koji ćete koristiti za učitavanje skupa podataka. Takođe, iz Scikit-LLM i scikit-learn, uvezite potrebne klase.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Zatim, učitajte skup podataka na kojem želite da izvršite analizu teksta. Ovaj kod koristi IMDB skup podataka filmova, ali ga možete prilagoditi za korišćenje sopstvenog skupa podataka.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Korišćenje samo prvih 100 redova skupa podataka nije obavezno, možete koristiti ceo skup podataka.
Zatim, izdvojite kolone sa karakteristikama i oznakama. Na kraju, podelite svoj skup podataka na skupove za obuku i testiranje.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Kolona „Žanr“ sadrži oznake koje želite da predvidite.
Klasifikacija teksta nultog snimka sa Scikit-LLM
Klasifikacija teksta nultog snimka je mogućnost koju nude veliki jezički modeli. Omogućava klasifikaciju teksta u unapred definisane kategorije bez potrebe za eksplicitnom obukom na označenim podacima. Ova mogućnost je veoma korisna kada se radi sa zadacima gde je potrebno klasifikovati tekst u kategorije koje nisu bile predviđene tokom obuke modela.
Da biste izvršili klasifikaciju teksta nultog snimka koristeći Scikit-LLM, koristite klasu `ZeroShotGPTClassifier`.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
Izlaz je sledeći:
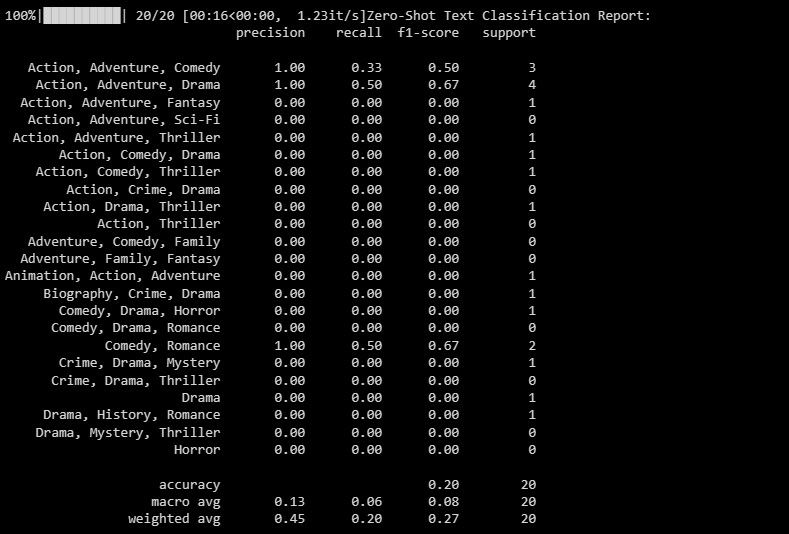
Izveštaj o klasifikaciji pruža metrike za svaku oznaku koju model pokušava da predvidi.
Multi-Label Zero-Shot klasifikacija teksta sa Scikit-LLM
U određenim situacijama, jedan tekst može pripadati više kategorija istovremeno. Tradicionalni modeli klasifikacije imaju problema sa ovim. Scikit-LLM, sa druge strane, omogućava ovu vrstu klasifikacije. Klasifikacija teksta sa više oznaka je ključna za dodeljivanje više opisnih oznaka jednom uzorku teksta.
Koristite `MultiLabelZeroShotGPTClassifier` da predvidite koje su oznake najprikladnije za svaki uzorak teksta.
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
U gore navedenom kodu, definišete oznake kandidata kojima vaš tekst može pripadati.
Izlaz je prikazan ispod:
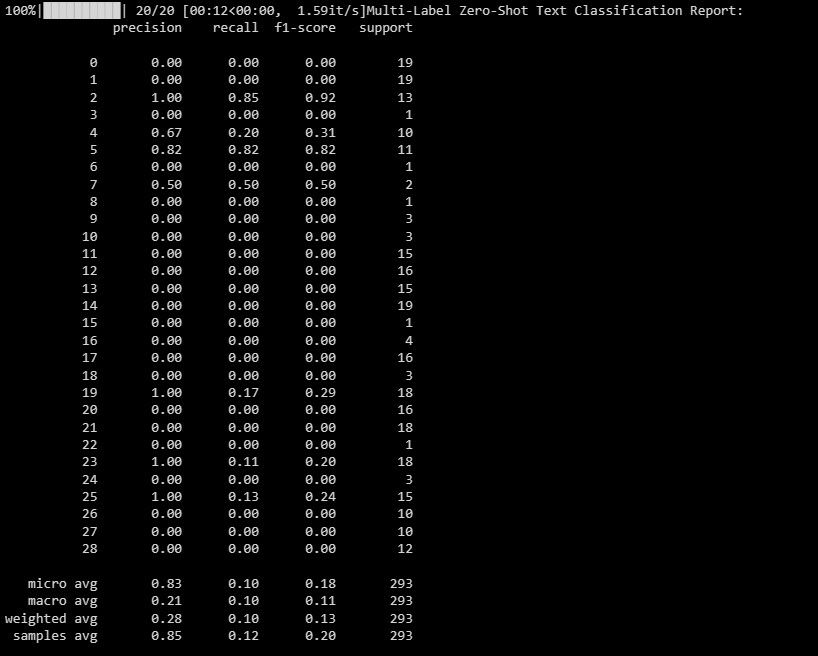
Ovaj izveštaj vam pomaže da razumete koliko dobro funkcioniše vaš model za svaku oznaku u multi-label klasifikaciji.
Vektorizacija teksta sa Scikit-LLM
U vektorizaciji teksta, tekstualni podaci se konvertuju u numerički format koji modeli mašinskog učenja mogu da razumeju. Scikit-LLM nudi `GPTVectorizer` za ovo. Omogućava vam da transformišete tekst u vektore fiksne dimenzije korišćenjem GPT modela.
Ovo možete postići korišćenjem frekvencije termina – inverzne frekvencije dokumenta (TF-IDF).
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5])
Evo izlaza:
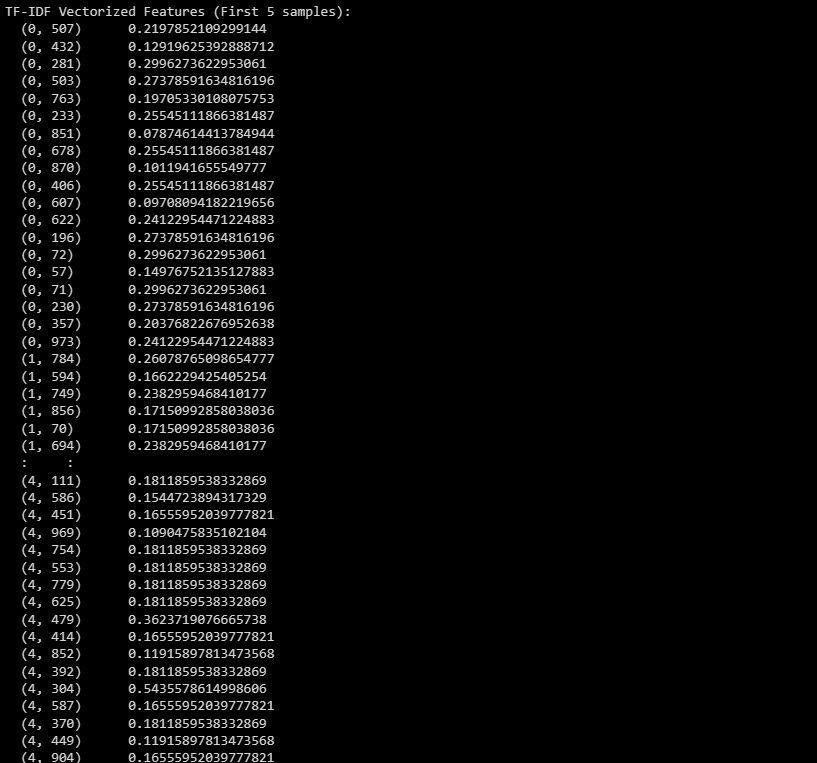
Izlaz predstavlja vektorizovane TF-IDF karakteristike za prvih 5 uzoraka u skupu podataka.
Rezime teksta sa Scikit-LLM
Sažimanje teksta pomaže u komprimovanju teksta uz zadržavanje najvažnijih informacija. Scikit-LLM nudi `GPTSummarizer`, koji koristi GPT modele za generisanje sažetih rezimea teksta.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Izlaz je sledeći:
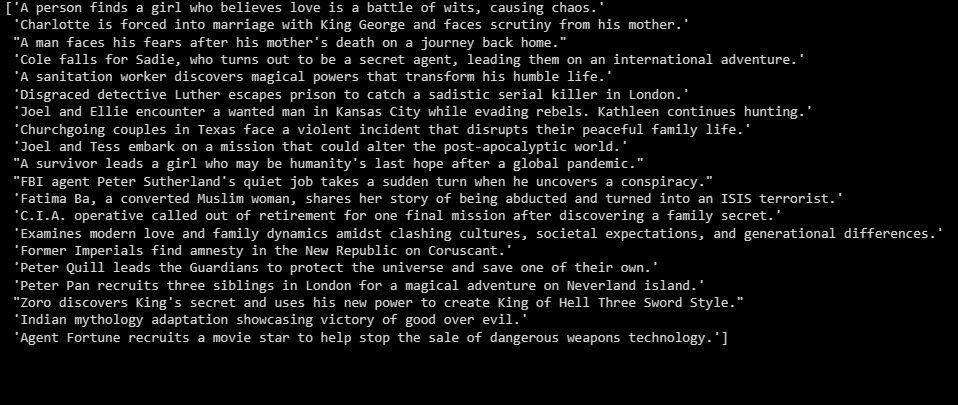
Gore navedeno je rezime testnih podataka.
Izgradnja aplikacija pomoću LLM-a
Scikit-LLM otvara široke mogućnosti za analizu teksta sa velikim jezičkim modelima. Razumevanje tehnologije koja stoji iza velikih jezičkih modela je ključno. To će vam pomoći da razumete njihove prednosti i slabosti, što će vam omogućiti da gradite efikasne aplikacije na osnovu ove napredne tehnologije.