Компанија Мета је током лета 2023. године представила Llama 2, нову верзију језичког модела. Ова унапређена верзија тренирана је на 40% више токена у поређењу са оригиналним Llama моделом, што је резултирало двоструко дужим контекстом и значајним побољшањем у односу на друге моделе отвореног кода. Најједноставнији и најбржи начин приступа моделу Llama 2 је путем API-ја преко онлајн платформи. Међутим, за најбоље корисничко искуство, препоручује се инсталација и покретање Llama 2 директно на вашем рачунару.
Имајући ово у виду, припремили смо детаљан водич који објашњава како користити Text-Generation-WebUI за локално учитавање квантизованог језичког модела Llama 2 на вашем рачунару.
Зашто инсталирати Llama 2 локално
Постоји више разлога зашто корисници бирају директно покретање Llama 2 модела. Неки то чине због приватности, други због могућности прилагођавања, а трећи због рада ван мреже. Ако се бавите истраживањем, финим подешавањем или интеграцијом Llama 2 модела у ваше пројекте, приступ преко API-ја можда није најефикасније решење. Поента локалног покретања језичког модела на вашем рачунару је смањење зависности од спољних АИ алата и могућност коришћења вештачке интелигенције било када и било где, без бриге о могућем цурењу осетљивих података трећим лицима.
Сада, кренимо са детаљним упутством за локалну инсталацију модела Llama 2.
За потребе једноставности, користићемо инсталациони програм једним кликом за Text-Generation-WebUI, алатку која се користи за учитавање Llama 2 модела помоћу графичког корисничког интерфејса (GUI). Међутим, да би овај инсталациони програм функционисао, неопходно је преузети и инсталирати Visual Studio 2019 са потребним ресурсима.
Преузимање: Visual Studio 2019 (бесплатно)
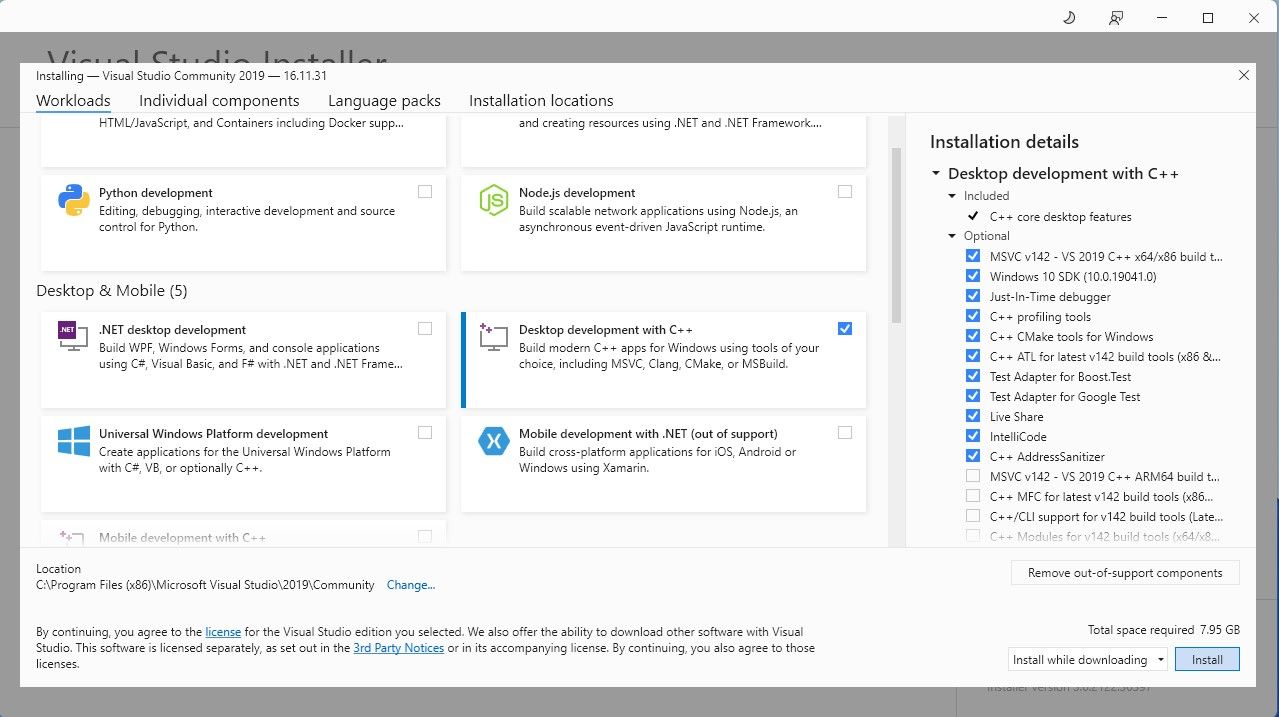
Сада када је развој радне површине са C++ инсталиран, следећи корак је преузимање инсталационог програма Text-Generation-WebUI једним кликом.
Корак 2: Инсталирајте Text-Generation-WebUI
Инсталациони програм Text-Generation-WebUI једним кликом је скрипта која аутоматски креира потребне фасцикле и подешава conda окружење, укључујући све неопходне захтеве за покретање AI модела.
За инсталацију скрипте, преузмите програм једним кликом кликом на Code > Download ZIP.
Преузимање: Text-Generation-WebUI Installer (бесплатно)
- За Windows кориснике, одаберите start_windows batch file.
- За macOS, одаберите start_macos shell script.
- За Linux, start_linux shell script.
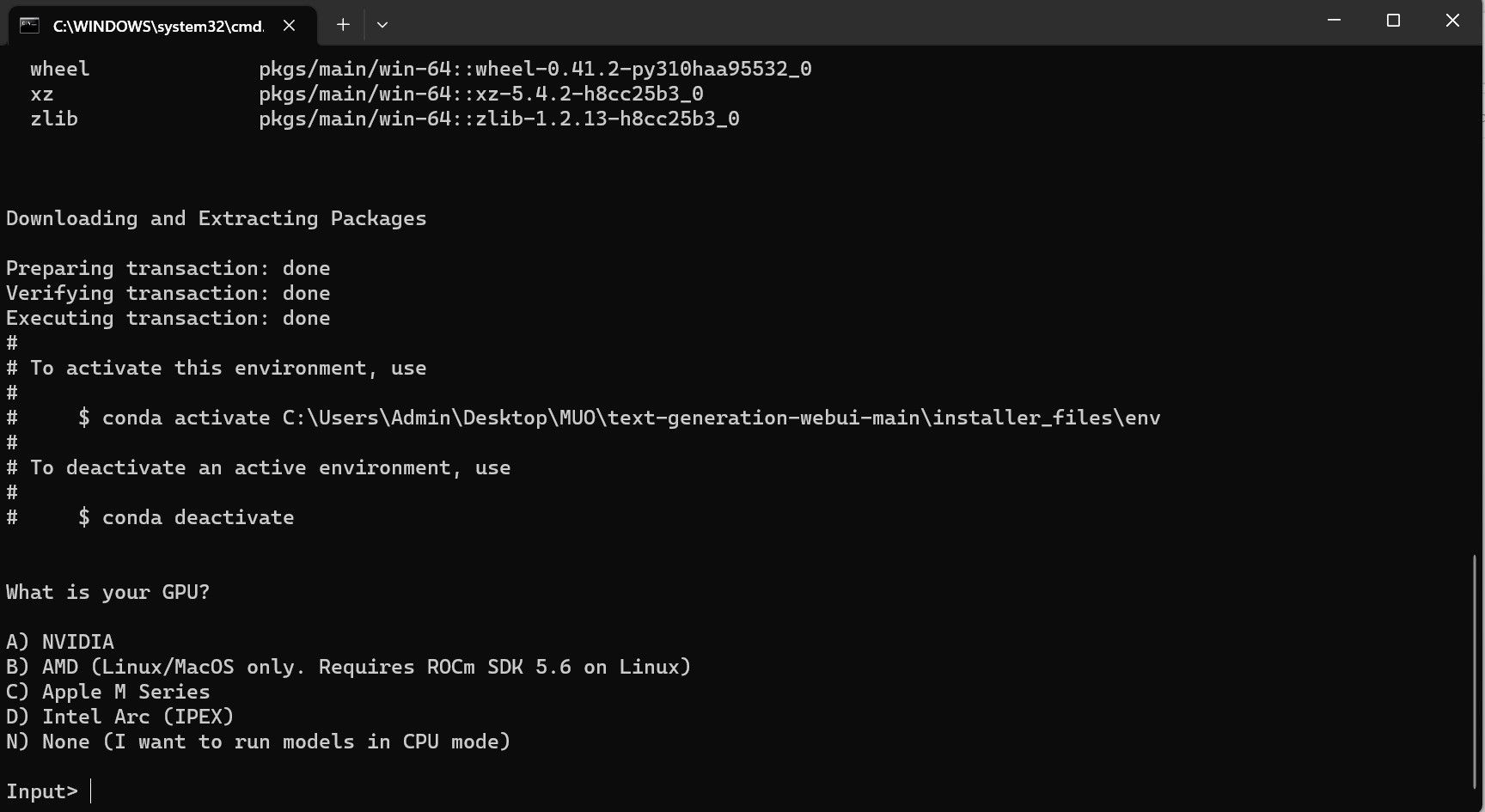
Међутим, програм је само учитавач модела. Преузмимо Llama 2 модел за коришћење у учитавачу.
Корак 3: Преузмите Llama 2 модел
Постоји неколико фактора које треба узети у обзир при одабиру одговарајуће итерације Llama 2 модела, укључујући параметре, квантизацију, хардверску оптимизацију, величину и намену. Сви ови подаци биће наведени у називу модела.
- Параметри: Број параметара коришћених за тренирање модела. Већи број параметара омогућава моделу да буде способнији, али уз цену перформанси.
- Намена: Може бити стандардна или за ћаскање. Модел за ћаскање је оптимизован за употребу као четбот, попут ChatGPT-а, док је стандардни модел основни модел.
- Хардверска оптимизација: Односи се на хардвер на којем модел најбоље ради. GPTQ означава да је модел оптимизован за рад на наменском GPU-у, док је GGML оптимизован за рад на CPU-у.
- Квантизација: Означава прецизност тежина и активација у моделу. За закључивање, прецизност k4 је оптимална.
- Величина: Односи се на величину конкретног модела.
Треба имати на уму да нека имена модела могу бити другачије структурирана и можда неће садржавати све исте информације. Међутим, ова конвенција именовања је прилично честа у библиотеци модела HuggingFace, па је вредно разумети.

У овом примеру, модел се може идентификовати као Llama 2 модел средње величине, трениран на 13 милијарди параметара, оптимизован за закључивање ћаскања помоћу наменског CPU-а.
За кориснике са наменским GPU-ом, одаберите GPTQ модел, док за кориснике са CPU-ом, одаберите GGML. Ако желите да комуницирате са моделом као са ChatGPT-ом, одаберите верзију за ћаскање, а ако желите да експериментишете са моделим у његовом пуном капацитету, користите стандардни модел. Што се тиче параметара, треба знати да већи модели пружају боље резултате, али уз слабије перформансе. Препоручљиво је почети са 7B моделом. Што се тиче квантизације, користите k4 јер је погодна за закључивање.
Преузимање: GGML (бесплатно)
Преузимање: GPTQ (бесплатно)
Сада када знате која итерација Llama 2 вам је потребна, преузмите жељени модел.
У овом случају, пошто се користи ултрабоок, користиће се GGML модел фино подешен за ћаскање, llama-2-7b-chat-ggmlv3.k4_K_S.bin.
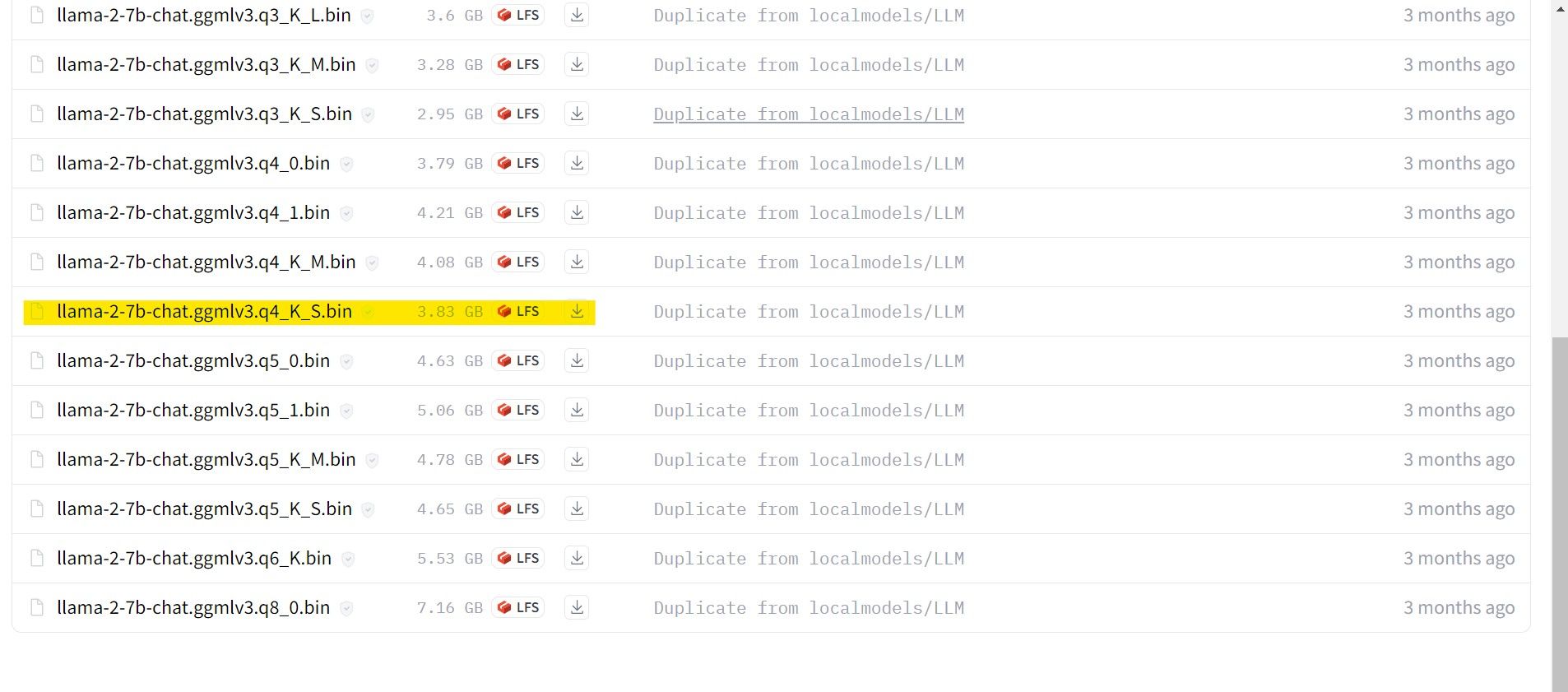
Када је преузимање завршено, преместите модел у фасциклу text-generation-webui-main > models.
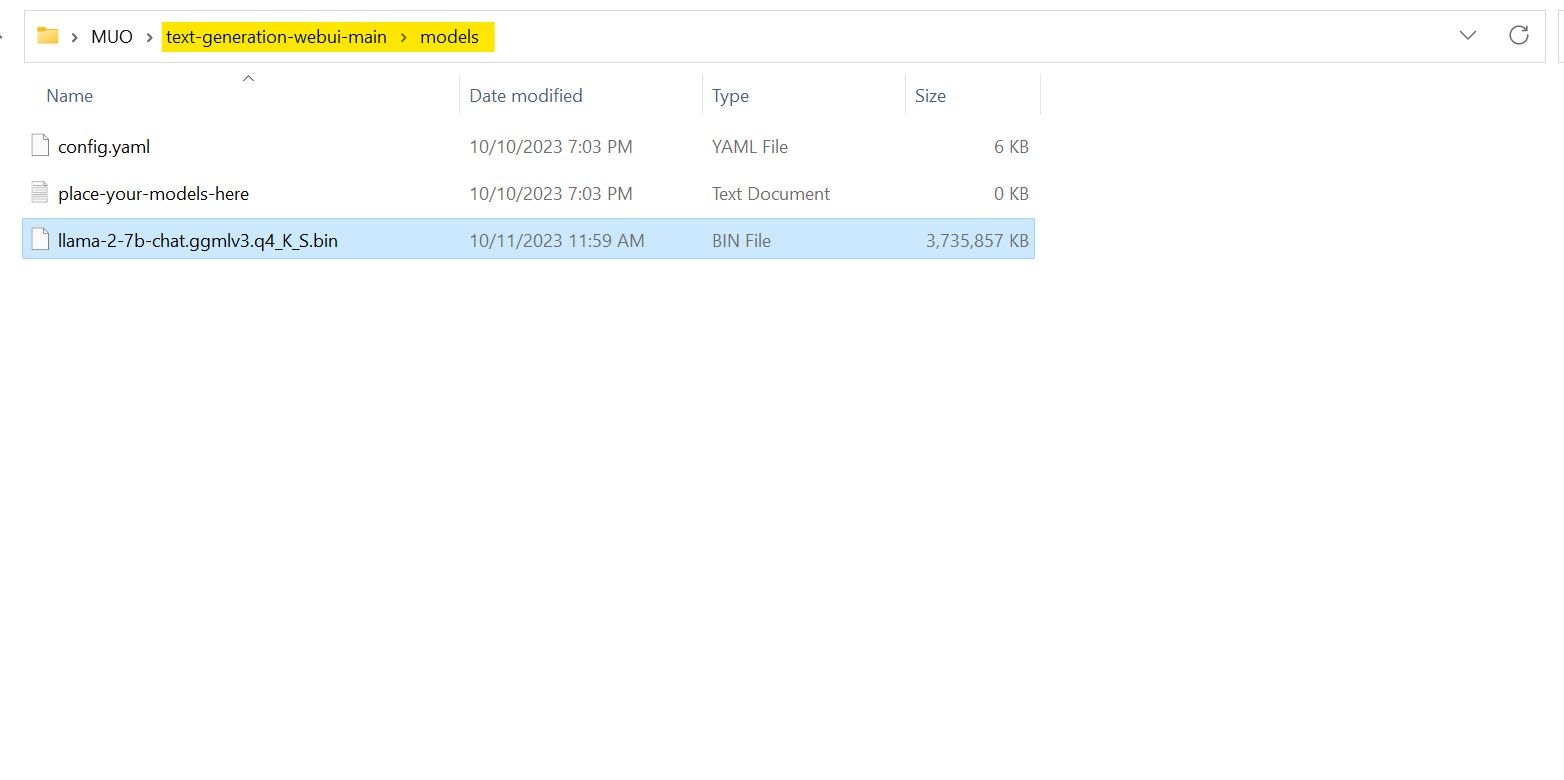
Сада када сте преузели модел и сместили га у фасциклу models, време је да конфигуришете учитавач модела.
Корак 4: Конфигуришите Text-Generation-WebUI
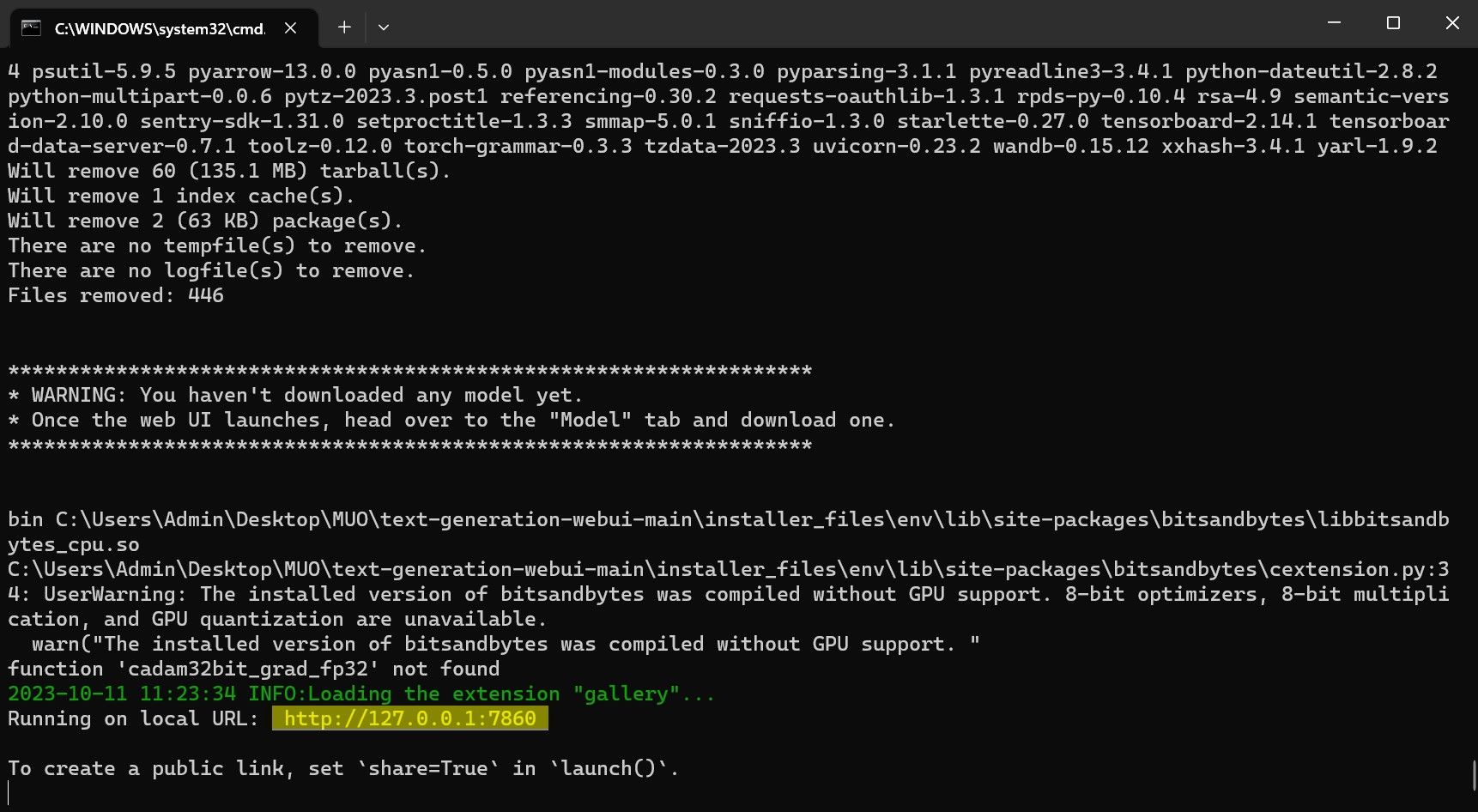
Сада, пређимо на фазу конфигурације.
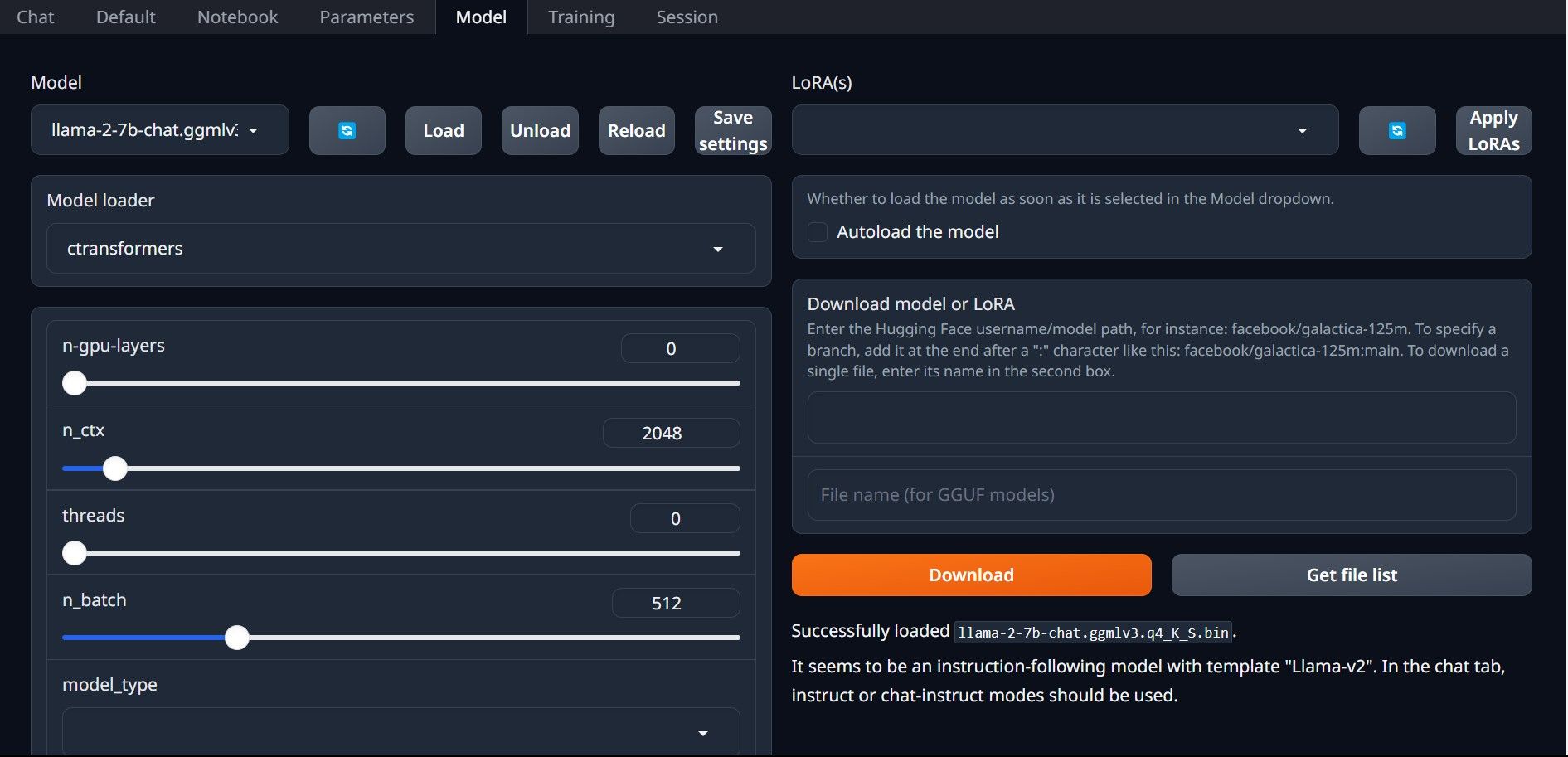
Честитамо, успешно сте учитали Llama 2 на свој локални рачунар!
Испробајте и друге језичке моделе
Сада када знате како да покренете Llama 2 директно на рачунару користећи Text-Generation-WebUI, требало би да можете покренути и друге језичке моделе осим Llama. Важно је запамтити конвенције именовања модела и да само квантизоване верзије (обично k4 прецизности) могу да се учитају на обичним рачунарима. Многи квантизовани језички модели доступни су на HuggingFace-у. Ако желите да истражите и друге моделе, потражите TheBloke у библиотеци модела HuggingFace-а и пронаћи ћете много доступних модела.