U današnjem poslovnom okruženju, gde preduzeća generišu sve veću količinu podataka, tradicionalni pristupi skladištenju informacija postaju sve kompleksniji i skuplji za održavanje. Data vault, kao relativno nova metodologija u oblasti skladištenja podataka, pruža efikasno rešenje za ovaj izazov. Nudi skalabilan, fleksibilan i ekonomičan način upravljanja obimnim količinama informacija.
U ovom tekstu istražićemo kako data vault predstavlja budućnost skladištenja podataka i zašto sve veći broj kompanija prelazi na ovaj pristup. Takođe, obezbedićemo resurse za učenje onima koji su zainteresovani za detaljnije upoznavanje sa ovom temom.
Šta je to Data Vault?
Data vault je tehnika modeliranja skladišta podataka, posebno prilagođena agilnim okruženjima. Ona omogućava visok stepen fleksibilnosti pri proširenjima, potpunu istorizaciju podataka po vremenskim jedinicama i snažnu paralelzaciju procesa učitavanja podataka. Modeliranje Data Vault-a razvio je Dan Linstedt tokom devedesetih godina.
Nakon prvog objavljivanja 2000. godine, ova metodologija je privukla veću pažnju 2002. godine kroz seriju članaka. Godine 2007. Linstedt je dobio podršku Billa Inmona, koji je ovu tehniku opisao kao „optimalan izbor“ za svoju Data Vault 2.0 arhitekturu.
Svako ko se bavi temom agilnog skladištenja podataka, ubrzo će doći do Data Vault-a. Posebnost ove tehnologije leži u njenoj usredsređenosti na potrebe kompanija, omogućavajući fleksibilna prilagođavanja skladišta podataka uz minimalan napor.
Data Vault 2.0 razmatra celokupan proces razvoja i arhitekturu, sastojeći se od metoda komponenti (implementacija), arhitekture i modela. Prednost ovog pristupa je što tokom razvoja uzima u obzir sve aspekte poslovne inteligencije sa centralnim skladištem podataka.
Data Vault model nudi savremeno rešenje za prevazilaženje ograničenja tradicionalnih pristupa modeliranju podataka. Svojom skalabilnošću, fleksibilnošću i agilnošću, pruža solidnu osnovu za izgradnju platforme podataka koja se može prilagoditi složenosti i raznolikosti savremenih okruženja podataka.
Hub-and-spoke arhitektura Data Vault-a i razdvajanje entiteta i atributa omogućavaju integraciju i harmonizaciju podataka u više sistema i domena, olakšavajući inkrementalni i agilan razvoj.
Ključna uloga Data Vault-a u izgradnji platforme podataka je uspostavljanje jedinstvenog izvora istine za sve podatke. Njegov jedinstveni pogled na podatke i podrška za hvatanje i praćenje istorijskih promena podataka putem satelitskih tabela omogućavaju usklađenost, reviziju, regulatorne zahteve i sveobuhvatnu analizu i izveštavanje.
Mogućnosti Data Vault-a za integraciju podataka u skoro realnom vremenu putem delta učitavanja olakšavaju rukovanje velikim količinama podataka u okruženjima koja se brzo menjaju, kao što su Big Data i IoT aplikacije.
Data Vault naspram tradicionalnih modela skladišta podataka
Treća normalna forma (3NF) je jedan od najpoznatijih tradicionalnih modela skladišta podataka, koji se često preferira u mnogim velikim implementacijama. Ovo odgovara idejama Billa Inmona, jednog od pionira koncepta skladišta podataka.
Inmon arhitektura se zasniva na modelu relacione baze podataka i eliminiše redundantnost podataka razbijanjem izvora podataka u manje tabele koje se čuvaju u bazama podataka i međusobno su povezane korišćenjem primarnih i stranih ključeva. Ona obezbeđuje da su podaci dosledni i tačni primenom pravila o referentnom integritetu.
Cilj normalnog oblika bio je da se izgradi sveobuhvatan model podataka za celu kompaniju za centralno skladište podataka. Međutim, ima problema sa skalabilnošću i fleksibilnošću zbog veoma povezanih prodajnih mesta, poteškoća sa učitavanjem u režimu skoro u realnom vremenu, zahtevnih zahteva i dizajna odozgo nadole i implementacije.
Kimball model, koji se koristi za OLAP (online analitičku obradu) i vitrine podataka, je još jedan poznati model skladišta podataka u kojem tabele činjenica sadrže agregirane podatke, a tabele dimenzija opisuju uskladištene podatke u šemi zvezda ili pahuljica. U ovoj arhitekturi, podaci su organizovani u tabele činjenica i dimenzija koje su denormalizovane da pojednostave upite i analizu.
Kimball je zasnovan na dimenzionalnom modelu koji je optimizovan za upite i izveštavanje, što ga čini idealnim za aplikacije poslovne inteligencije. Međutim, imao je problema sa izolacijom informacija orijentisanih na predmet, redundantnošću podataka, nekompatibilnim strukturama upita, poteškoćama u skalabilnosti, nedoslednom granularnošću tabela činjenica, problemima sinhronizacije i potrebom za dizajnom odozgo nadole sa implementacijom odozdo prema gore.
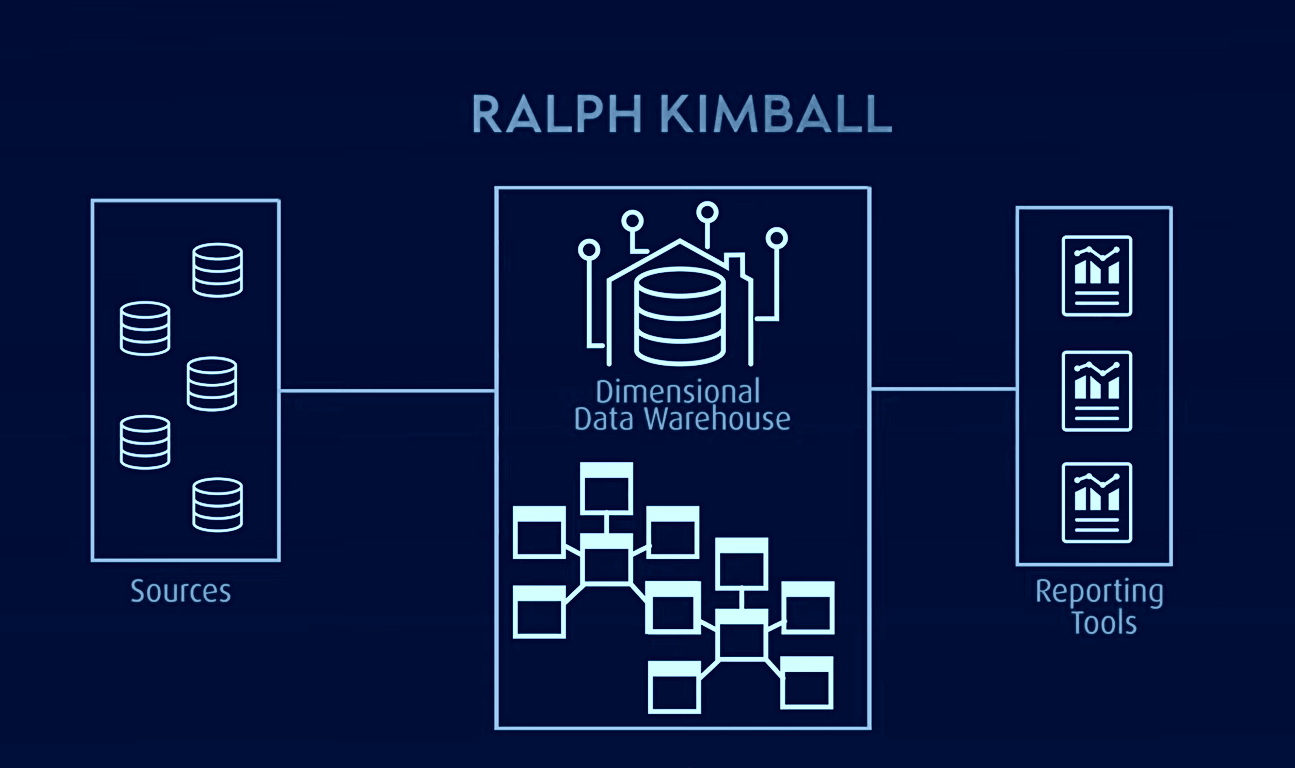
Nasuprot tome, arhitektura data vault-a je hibridni pristup koji kombinuje aspekte 3NF i Kimball arhitekture. To je model zasnovan na relacionim principima, normalizaciji podataka i matematici redukcije koji drugačije predstavlja odnose između entiteta i drugačije strukturira polja tabele i vremenske oznake.
U ovoj arhitekturi, svi podaci se čuvaju u trezoru sirovih podataka ili jezeru podataka, dok se obično korišćeni podaci čuvaju u normalizovanom formatu u poslovnom trezoru koji sadrži istorijske podatke i podatke specifične za kontekst koji se mogu koristiti za izveštavanje.
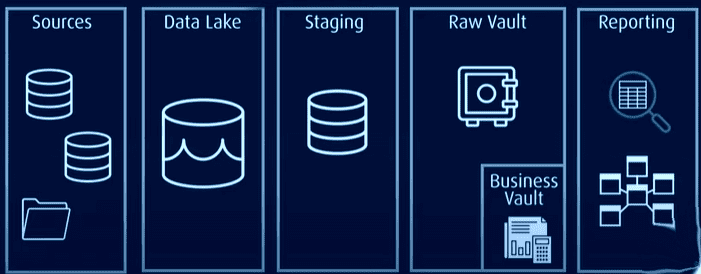
Data Vault rešava probleme tradicionalnih modela tako što je efikasniji, skalabilniji i fleksibilniji. Omogućava učitavanje skoro u realnom vremenu, bolji integritet podataka i lako proširenje bez uticaja na postojeće strukture. Model se takođe može proširiti bez migracije postojećih tabela.
| Pristup modeliranju | Struktura podataka | Pristup dizajnu |
| 3NF modeliranje | Tabele u 3NF | Modeliranje odozdo nagore |
| Kimball modeliranje | Star šema ili šema pahuljica | Odozgo nadole |
| Data Vault | Hub-and-Spoke | Odozdo nagore |
Arhitektura Data Vault-a
Data Vault ima arhitekturu čvorišta i krakova i u osnovi se sastoji od tri sloja:
Sloj za postavljanje: Prikuplja neobrađene podatke iz izvornih sistema, kao što su CRM ili ERP.
Sloj skladišta podataka: Kada je modeliran kao Data Vault model, ovaj sloj uključuje:
- Trezor sirovih podataka: čuva neobrađene podatke.
- Trezor poslovnih podataka: uključuje usklađene i transformisane podatke zasnovane na poslovnim pravilima (opciono).
- Trezor metrika: čuva informacije o vremenu izvršavanja (opciono).
- Operativni trezor: skladišti podatke koji teku direktno iz operativnih sistema u skladište podataka (opciono).
Data Mart sloj: Ovaj sloj modelira podatke kao zvezdaste šeme i/ili druge tehnike modeliranja. Pruža informacije za analizu i izveštavanje.
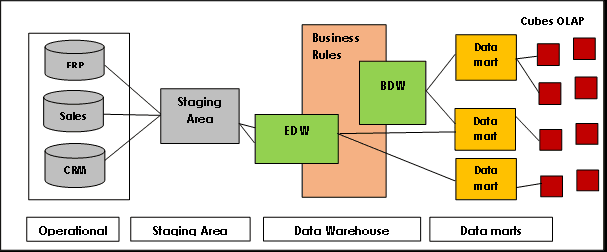 Izvor slike: Lamia Yessad
Izvor slike: Lamia Yessad
Data Vault ne zahteva re-arhitekturu. Nove funkcije se mogu graditi paralelno direktno koristeći koncepte i metode Data Vault-a, a postojeće komponente se ne gube. Okviri mogu znatno olakšati rad: stvaraju sloj između skladišta podataka i programera i na taj način smanjuju složenost implementacije.
Komponente Data Vault-a
Tokom modeliranja, Data Vault deli sve informacije koje pripadaju objektu u tri kategorije – za razliku od klasičnog modeliranja treće normalne forme. Ove informacije se zatim čuvaju strogo odvojene jedna od druge. Funkcionalne oblasti se mogu mapirati u Data Vault u takozvanim čvorištima, vezama i satelitima:
#1. Čvorišta
Čvorišta su srž osnovnog poslovnog koncepta, kao što su kupac, prodavac, prodaja ili proizvod. Tabela čvorišta se formira oko poslovnog ključa (naziv prodavnice ili lokacija) kada se nova instanca tog poslovnog ključa prvi put uvede u skladište podataka.
Čvorište ne sadrži opisne informacije i FK-ove. Sastoji se samo od poslovnog ključa, sa sekvencom ID ili heš ključeva generisanom u skladištu, datumom/vremenom učitavanja i izvorom zapisa.
#2. Linkovi
Veze uspostavljaju odnose između poslovnih ključeva. Svaki unos u vezi modelira nm odnosa bilo kog broja čvorišta. Omogućava Data Vault-u da fleksibilno reaguje na promene u poslovnoj logici izvornih sistema, kao što su promene u kardinalnosti odnosa. Baš kao i čvorište, veza ne sadrži nikakve opisne informacije. Sastoji se od ID-ova sekvence čvorišta na koje upućuje, ID-a sekvence generisanog u skladištu, oznake datuma/vremena učitavanja i izvora zapisa.
#3. Sateliti
Sateliti sadrže deskriptivne informacije (kontekst) za poslovni ključ koji se čuva u čvorištu ili odnos sačuvan u vezi. Sateliti rade „samo za umetanje“, što znači da se kompletna istorija podataka čuva u satelitu. Više satelita može opisati jedan poslovni ključ (ili odnos). Međutim, satelit može opisati samo jedan ključ (čvorište ili vezu).
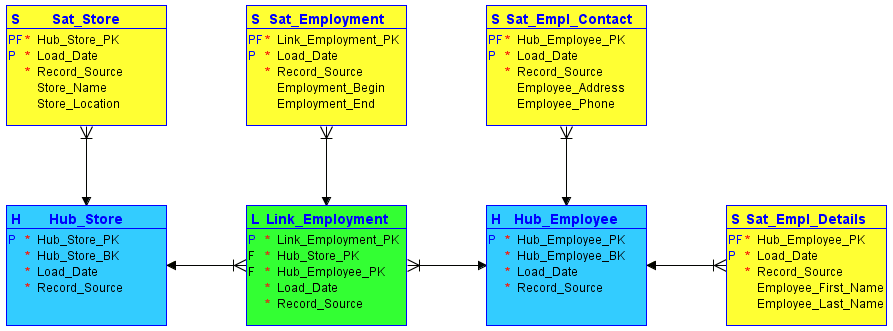 Izvor slike: Carbidfischer
Izvor slike: Carbidfischer
Kako napraviti Data Vault model
Izgradnja Data Vault modela uključuje nekoliko koraka, od kojih je svaki ključan za osiguravanje da je model skalabilan, fleksibilan i da može da zadovolji potrebe poslovanja:
#1. Identifikujte entitete i atribute
Identifikujte poslovne subjekte i njihove odgovarajuće atribute. To uključuje blisku saradnju sa poslovnim akterima kako bi se razumeli njihovi zahtevi i podaci koje treba da sakupe. Kada su ovi entiteti i atributi identifikovani, razdvojite ih na čvorišta, veze i satelite.
#2. Definišite odnose entiteta i kreirajte veze
Kada ste identifikovali entitete i atribute, odnosi između entiteta su definisani, a veze se kreiraju da predstavljaju ove odnose. Svakoj vezi je dodeljen poslovni ključ koji identifikuje odnos između entiteta. Sateliti se zatim dodaju da bi se uhvatili atributi i odnosi entiteta.
#3. Uspostaviti pravila i standarde
Nakon kreiranja veza, treba uspostaviti skup pravila i standarda za modeliranje data vault kako bi se osiguralo da je model fleksibilan i da može da podnese promene tokom vremena. Ova pravila i standarde treba redovno revidirati i ažurirati kako bi se osiguralo da ostaju relevantni i usklađeni sa poslovnim potrebama.
#4. Popunite model
Kada je model kreiran, treba ga popuniti podacima koristeći pristup inkrementalnog učitavanja. To uključuje učitavanje podataka u čvorišta, veze i satelite pomoću delta opterećenja. Delta se učitava kako bi se osiguralo da se učitavaju samo promene napravljene u podacima, smanjujući vreme i resurse potrebne za integraciju podataka.
#5. Testirajte i potvrdite model
Konačno, model treba testirati i validirati kako bi se osiguralo da ispunjava poslovne zahteve i da je dovoljno skalabilan i fleksibilan da se nosi sa budućim promenama. Redovno održavanje i ažuriranja treba da se obavljaju kako bi se osiguralo da model ostaje usklađen sa poslovnim potrebama i da nastavi da pruža jedinstven pogled na podatke.
Resursi za učenje Data Vault-a
Ovladavanje Data Vault-om može obezbediti vredne veštine i znanja koja su veoma tražena u današnjim industrijama zasnovanim na podacima. Evo sveobuhvatne liste resursa, uključujući kurseve i knjige, koji mogu pomoći u učenju zamršenosti Data Vault-a:
#1. Modeliranje skladišta podataka sa Data Vault 2.0

Ovaj Udemy kurs je sveobuhvatan uvod u pristup modeliranju Data Vault 2.0, Agile upravljanje projektima i integraciju velikih podataka. Kurs pokriva osnove Data Vault-a 2.0, uključujući njegovu arhitekturu i slojeve, poslovne i informacione trezore i napredne tehnike modeliranja.
Uči vas kako da dizajnirate model Data Vault-a od nule, konvertujete tradicionalne modele kao što su 3NF i dimenzionalni modeli u Data Vault i razumete principe dimenzionalnog modeliranja u Data Vault-u. Kurs zahteva osnovno poznavanje baza podataka i osnove SQL-a.
Sa visokom ocenom od 4,4 od 5 i preko 1.700 recenzija, ovaj najprodavaniji kurs je pogodan za sve koji žele da izgrade jaku osnovu u Data Vault 2.0 i integraciji velikih podataka.
#2. Modeliranje Data Vault-a objašnjeno sa slučajem upotrebe

Ovaj Udemy kurs ima za cilj da vas vodi u izgradnji modela data vault koristeći praktičan poslovni primer. Služi kao vodič za početnike za modeliranje Data Vault-a, pokrivajući ključne koncepte kao što su odgovarajući scenariji za korišćenje modela Data Vault-a, ograničenja konvencionalnog OLAP modeliranja i sistematski pristup konstruisanju modela Data Vault-a. Kurs je dostupan pojedincima sa minimalnim znanjem baze podataka.
#3. Data Vault Guru: pragmatičan vodič
Data Vault Guru gospodina Patrika Kube je sveobuhvatan vodič za metodologiju Data Vault-a, koji nudi jedinstvenu priliku za modeliranje skladišta podataka preduzeća koristeći principe automatizacije slične onima koji se koriste u isporuci softvera.
Knjiga pruža pregled moderne arhitekture, a zatim nudi detaljan vodič o tome kako da se isporuči fleksibilan model podataka koji se prilagođava promenama u preduzeću, Data Vault.
Pored toga, knjiga proširuje metodologiju data vault obezbeđujući automatizovanu korekciju vremenske linije, revizijske tragove, kontrolu metapodataka i integraciju sa agilnim alatima za isporuku.
#4. Izgradnja skalabilnog skladišta podataka sa Data Vault 2.0
Ova knjiga pruža čitaocima sveobuhvatan vodič za kreiranje skalabilnog skladišta podataka od početka do kraja koristeći Data Vault 2.0 metodologiju.
Ova knjiga pokriva sve bitne aspekte izgradnje skalabilnog skladišta podataka, uključujući tehniku modeliranja Data Vault, koja je dizajnirana da spreči tipične greške u skladištu podataka.
Knjiga sadrži brojne primere koji pomažu čitaocima da jasno razumeju koncepte. Sa svojim praktičnim uvidima i primerima iz stvarnog sveta, ova knjiga je suštinski resurs za sve koji su zainteresovani za skladištenje podataka.
#5. Slon u frižideru: vođeni koraci do uspeha u Data Vault-u
Slon u frižideru Džona Džajlsa je praktičan vodič koji ima za cilj da pomogne čitaocima da postignu uspeh u Data Vault-u tako što će početi sa poslom i završiti sa poslom.
Knjiga se fokusira na važnost ontologije preduzeća i modeliranja poslovnog koncepta i pruža uputstva korak po korak o tome kako primeniti ove koncepte za kreiranje solidnog modela podataka.
Kroz praktične savete i uzorke obrazaca, autor nudi jasno i nekomplikovano objašnjenje komplikovanih tema, čineći knjigu odličnim vodičem za one koji tek počinju sa Data Vault-om.
Završne reči
Data Vault predstavlja budućnost skladištenja podataka, nudeći kompanijama značajne prednosti u pogledu agilnosti, skalabilnosti i efikasnosti. Posebno je pogodan za preduzeća koja moraju brzo da učitavaju velike količine podataka i za one koji žele da razviju svoje aplikacije poslovne inteligencije na agilan način.
Štaviše, kompanije koje imaju postojeću silos arhitekturu mogu imati velike koristi od implementacije uzvodnog centralnog skladišta podataka koristeći Data Vault.
Možda ćete biti zainteresovani da saznate više o liniji podataka.