Regresija i klasifikacija predstavljaju dva temeljna i ključna područja unutar mašinskog učenja.
Za početnike u mašinskom učenju, razgraničenje između algoritama regresije i klasifikacije može biti izazovno. Razumevanje načina funkcionisanja ovih algoritama i njihove primenjivosti od suštinskog je značaja za postizanje preciznih predviđanja i efikasno donošenje odluka.
Najpre, osvrnućemo se na sam koncept mašinskog učenja.
Šta je mašinsko učenje?
Mašinsko učenje je pristup koji omogućava računarima da stiču znanja i donose odluke bez eksplicitnog programiranja. Ovaj proces uključuje obučavanje kompjuterskog modela na određenom skupu podataka, što mu omogućava da predviđa ili donosi odluke na temelju prepoznatih obrazaca i odnosa unutar tih podataka.
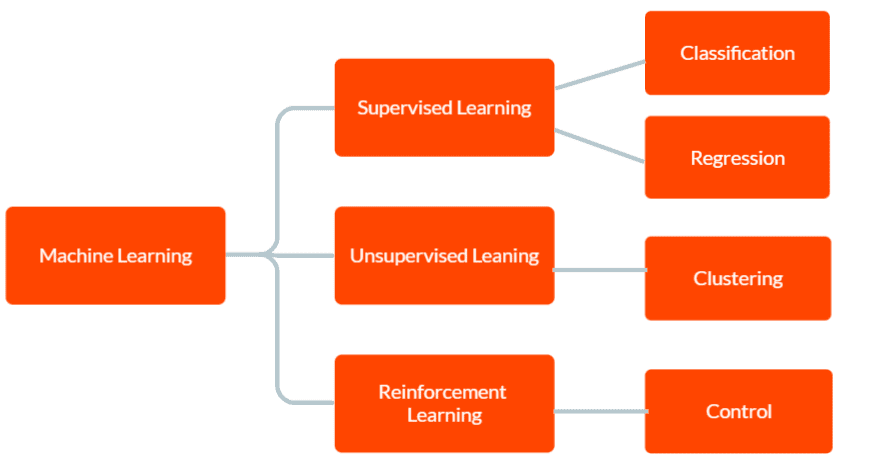
Postoje tri osnovna tipa mašinskog učenja: nadgledano učenje, nenadgledano učenje i učenje putem potkrepljenja.
U nadgledanom učenju, model se obučava na označenim podacima, koji uključuju ulazne podatke i odgovarajuće izlazne rezultate. Cilj je da model stekne sposobnost predviđanja izlaza za nove, nepoznate podatke, oslanjajući se na obrasce naučene iz podataka za obuku.
Nenadgledano učenje, s druge strane, ne koristi označene podatke za obuku. Umesto toga, model samostalno otkriva obrasce i odnose unutar podataka. Ovo se može koristiti za identifikovanje grupa ili klastera u podacima, kao i za pronalaženje anomalija ili neuobičajenih obrazaca.
U učenju putem potkrepljenja, agent uči kako da interaguje sa okolinom s ciljem maksimiziranja nagrade. To uključuje obučavanje modela da donosi odluke na temelju povratnih informacija koje dobija iz okruženja.
Mašinsko učenje se primenjuje u raznovrsnim oblastima, uključujući prepoznavanje slika i govora, obradu prirodnog jezika, detekciju prevara i razvoj autonomnih vozila. Njegov potencijal za automatizaciju različitih zadataka i unapređenje procesa odlučivanja u različitim industrijama je izuzetan.
Ovaj članak će se prvenstveno fokusirati na koncepte klasifikacije i regresije, koji spadaju pod nadgledano mašinsko učenje. Započnimo!
Klasifikacija u mašinskom učenju

Klasifikacija je tehnika mašinskog učenja koja podrazumeva obučavanje modela da dodeli određenu klasu datom ulazu. Ona spada u nadgledano učenje, gde se model obučava na označenom skupu podataka, koji sadrži primere ulaznih podataka i njihove odgovarajuće oznake klase.
Cilj modela je da nauči vezu između ulaznih podataka i oznaka klase kako bi mogao predvideti klasu za nove, neviđene ulazne podatke.
Postoji mnogo različitih algoritama koji se mogu koristiti za klasifikaciju, uključujući logističku regresiju, stabla odlučivanja i mašine sa vektorima podrške. Izbor algoritma zavisi od karakteristika podataka i željenih performansi modela.
Neke od čestih primena klasifikacije uključuju detekciju neželjene pošte, analizu sentimenata i otkrivanje prevara. U svakom od ovih slučajeva, ulazni podaci mogu biti tekst, numeričke vrednosti ili njihova kombinacija. Oznake klase mogu biti binarne (npr. neželjena pošta ili nije neželjena pošta) ili višeklasne (npr. pozitivan, neutralan, negativan sentiment).
Na primer, uzmimo u obzir skup podataka koji sadrži recenzije korisnika o nekom proizvodu. Ulazni podaci mogu biti tekst recenzije, a oznaka klase može predstavljati ocenu (npr. pozitivna, neutralna, negativna). Model bi se obučavao na skupu podataka označenih recenzija, a zatim bi mogao predvideti ocenu za novu, neviđenu recenziju.
Tipovi algoritama ML klasifikacije
Postoji nekoliko vrsta algoritama klasifikacije u mašinskom učenju:
Logistička regresija
Ovo je linearni model koji se koristi za binarnu klasifikaciju. Koristi se za predviđanje verovatnoće da će se određeni događaj desiti. Cilj logističke regresije je pronalaženje najboljih koeficijenata (težina) koji minimiziraju razliku između predviđene verovatnoće i posmatranog ishoda.
Ovo se postiže korišćenjem algoritma optimizacije, kao što je gradijentni spust, za podešavanje koeficijenata dok model što bolje ne odgovara podacima za obuku.
Stabla odlučivanja
Ovo su modeli koji podsećaju na stabla, a odluke donose na temelju vrednosti karakteristika. Mogu se koristiti i za binarnu i za višeklasnu klasifikaciju. Stabla odlučivanja imaju nekoliko prednosti, uključujući jednostavnost i lakoću interpretacije.
Takođe, brzo se obučavaju i predviđaju, a mogu da rade i sa numeričkim i sa kategoričkim podacima. Međutim, mogu biti skloni preprilagođavanju, posebno ako je stablo duboko i ima mnogo grana.
Klasifikacija nasumičnih šuma
Klasifikacija nasumičnih šuma je metoda ansambla koja kombinuje predviđanja više stabala odlučivanja kako bi se dobila preciznija i stabilnija predviđanja. Manje je sklona preprilagođavanju nego jedno stablo odlučivanja jer su predviđanja pojedinačnih stabala prosečna, što smanjuje varijansu u modelu.
AdaBoost
Ovo je algoritam za pojačavanje koji adaptivno menja težinu pogrešno klasifikovanih primera u skupu za obuku. Često se koristi za binarnu klasifikaciju.
Naivni Bajes
Naivni Bajes se temelji na Bajesovoj teoremi, koja predstavlja način ažuriranja verovatnoće događaja na temelju novih dokaza. To je probabilistički klasifikator koji se često koristi za klasifikaciju teksta i filtriranje neželjene pošte.
K-najbliži sused
K-Nearest Neighbors (KNN) se koristi za zadatke klasifikacije i regresije. To je neparametarska metoda koja klasifikuje tačku podataka na temelju klase njenih najbližih suseda. KNN ima nekoliko prednosti, uključujući njegovu jednostavnost i lakoću implementacije. Takođe može da obrađuje i numeričke i kategoričke podatke i ne pravi nikakve pretpostavke o osnovnoj distribuciji podataka.
Gradijentno pojačavanje
Ovo su ansambli slabih učenika koji se obučavaju uzastopno, pri čemu svaki model pokušava da ispravi greške prethodnog modela. Mogu se koristiti i za klasifikaciju i za regresiju.
Regresija u mašinskom učenju
U mašinskom učenju, regresija je tip nadgledanog učenja gde je cilj predviđanje zavisne promenljive na osnovu jedne ili više ulaznih karakteristika (koje se takođe nazivaju prediktori ili nezavisne varijable).
Algoritmi regresije se koriste za modeliranje odnosa između ulaza i izlaza i za predviđanje na osnovu tog odnosa. Regresija se može koristiti i za kontinuirane i za kategoričke zavisne varijable.
Opšti cilj regresije je izgradnja modela koji može precizno predvideti izlaz na temelju ulaznih karakteristika i razumeti osnovni odnos između ulaznih karakteristika i izlaza.
Regresiona analiza se koristi u raznim oblastima, uključujući ekonomiju, finansije, marketing i psihologiju, za razumevanje i predviđanje veza između različitih varijabli. To je ključan alat u analizi podataka i mašinskom učenju, a koristi se za predviđanje, identifikaciju trendova i razumevanje osnovnih mehanizama koji pokreću podatke.
Na primer, u jednostavnom modelu linearne regresije, cilj može biti predviđanje cene kuće na temelju njene veličine, lokacije i drugih karakteristika. Veličina kuće i njena lokacija bi bile nezavisne varijable, a cena kuće bi bila zavisna varijabla.
Model bi se obučavao na ulaznim podacima koji uključuju veličinu i lokaciju nekoliko kuća, zajedno sa njihovim odgovarajućim cenama. Kada se model obuči, može se koristiti za predviđanje cene kuće, s obzirom na njenu veličinu i lokaciju.
Tipovi algoritama regresije ML
Algoritmi regresije su dostupni u različitim oblicima, a izbor svakog algoritma zavisi od broja parametara, kao što su vrsta vrednosti atributa, obrazac linije trenda i broj nezavisnih promenljivih. Tehnike regresije koje se često koriste uključuju:
Linearna regresija
Ovaj jednostavni linearni model se koristi za predviđanje kontinuirane vrednosti na osnovu skupa karakteristika. Koristi se za modeliranje odnosa između karakteristika i ciljne promenljive tako što se povlači linija kroz podatke.
Polinomna regresija
Ovo je nelinearni model koji se koristi za uklapanje krivulje u podatke. Koristi se za modeliranje odnosa između karakteristika i ciljne promenljive kada odnos nije linearan. Zasnovan je na ideji dodavanja termina višeg reda u linearni model kako bi se uhvatile nelinearne veze između zavisnih i nezavisnih varijabli.
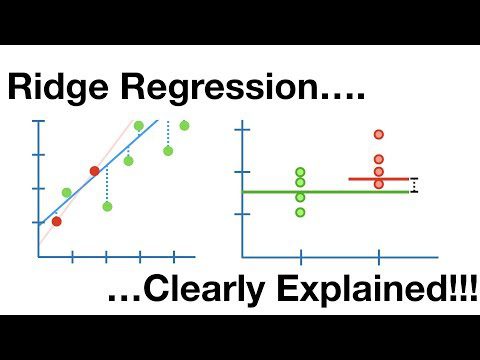
Ridge Regresija
Ovo je linearni model koji se bavi preprilagođavanjem u linearnoj regresiji. To je regularizovana verzija linearne regresije koja dodaje kazneni termin funkciji troškova kako bi se smanjila složenost modela.
Podrška regresiji vektora
Kao i SVM, Regresija vektora podrške je linearni model koji pokušava da uklopi podatke pronalaženjem hiperravnine koja maksimizira marginu između zavisnih i nezavisnih promenljivih.
Međutim, za razliku od SVM-a, koji se koriste za klasifikaciju, SVR se koristi za zadatke regresije, gde je cilj predviđanje kontinuirane vrednosti, a ne oznake klase.
Lasso Regresija
Ovo je još jedan regularizovani linearni model koji se koristi za sprečavanje preprilagođavanja u linearnoj regresiji. Dodaje kazneni termin funkciji troškova na temelju apsolutne vrednosti koeficijenata.
Bajesova linearna regresija
Bajesova linearna regresija je probabilistički pristup linearnoj regresiji zasnovan na Bajesovoj teoremi, koja predstavlja način ažuriranja verovatnoće događaja na temelju novih dokaza.
Ovaj regresioni model ima za cilj da proceni posteriornu distribuciju parametara modela prema podacima. Ovo se radi definisanjem prethodne distribucije preko parametara, a zatim korišćenjem Bajesove teoreme za ažuriranje distribucije na temelju posmatranih podataka.
Regresija naspram klasifikacije
Regresija i klasifikacija su dva tipa nadgledanog učenja, što znači da se koriste za predviđanje rezultata na osnovu skupa ulaznih karakteristika. Međutim, postoje neke ključne razlike između njih:
| Regresija | Klasifikacija | |
| Definicija | Tip nadgledanog učenja koji predviđa kontinuiranu vrednost | Tip nadgledanog učenja koji predviđa kategoričku vrednost |
| Tip izlaza | Kontinuiran | Diskretan |
| Evaluacione metrike | Srednja kvadratna greška (MSE), srednja kvadratna greška (RMSE) | Preciznost, odziv, F1 rezultat, ROC AUC |
| Algoritmi | Linearna regresija, polinomska regresija, SVR, stabla odlučivanja | Logistička regresija, SVM, Naivni Bajes, KNN, stabla odlučivanja |
| Složenost modela | Manje složeni modeli | Složeniji modeli |
| Pretpostavke | Linearni odnos između karakteristika i cilja | Nema specifičnih pretpostavki o odnosu između karakteristika i cilja |
| Neravnoteža klasa | Nije primenljiva | Može biti problem |
| Primena | Predviđanje cena, temperature, količine | Predviđanje da li će email biti neželjena pošta, predviđanje odliv kupaca |
Resursi za učenje
Izbor najboljih onlajn resursa za razumevanje koncepata mašinskog učenja može biti izazov. Istražili smo popularne kurseve koje pružaju pouzdane platforme kako bismo vam predstavili naše preporuke za najbolje ML kurseve o regresiji i klasifikaciji.
#1. Mašinsko učenje Classification Bootcamp u Python-u
Ovo je kurs koji se nudi na Udemy platformi. Pokriva različite algoritme i tehnike klasifikacije, uključujući stabla odlučivanja, logističku regresiju i mašine sa vektorima podrške.

Takođe, možete saznati više o temama kao što su preprilagođavanje, kompromis pristranosti i varijanse, kao i evaluacija modela. Kurs koristi Python biblioteke kao što su scikit-learn i pandas za implementaciju i procenu modela mašinskog učenja. Dakle, potrebno je osnovno znanje o Pythonu da biste započeli ovaj kurs.
#2. Masterclass regresije mašinskog učenja u Python-u
U ovom Udemy kursu, instruktor pokriva osnove i osnovnu teoriju različitih algoritama regresije, uključujući linearnu regresiju, polinomsku regresiju i tehnike Lasso & Ridge regresije.
Do kraja ovog kursa, moći ćete da primenite algoritme regresije i procenite učinak obučenih modela mašinskog učenja koristeći različite ključne indikatore učinka.
Zaključak
Algoritmi mašinskog učenja mogu biti veoma korisni u mnogim aplikacijama i mogu pomoći u automatizaciji i pojednostavljenju mnogih procesa. ML algoritmi koriste statističke tehnike da nauče obrasce u podacima i donose predviđanja ili odluke na temelju tih obrazaca.
Mogu se obučavati na velikim količinama podataka i mogu se koristiti za obavljanje zadataka koje bi ljudima bilo teško ili dugotrajno da ih rade ručno.
Svaki ML algoritam ima svoje prednosti i slabosti, a izbor algoritma zavisi od prirode podataka i zahteva zadatka. Važno je odabrati odgovarajući algoritam ili kombinaciju algoritama za određeni problem koji pokušavate da rešite.
Odabir pravog tipa algoritma za vaš problem je od ključne važnosti, jer korišćenje pogrešnog tipa algoritma može dovesti do loših performansi i netačnih predviđanja. Ako niste sigurni koji algoritam da koristite, može biti od pomoći da isprobate algoritme regresije i klasifikacije i uporedite njihov učinak na vašem skupu podataka.
Nadam se da vam je ovaj članak bio od pomoći u razumevanju razlike između regresije i klasifikacije u mašinskom učenju. Možda ćete biti zainteresovani da saznate više o vrhunskim modelima mašinskog učenja.