Ključni zaključci
- Generalizacija je ključna u dubokom učenju kako bi se osigurala precizna predviđanja sa novim podacima. Učenje sa nula snimaka (zero-shot learning) pomaže u tome, omogućavajući veštačkoj inteligenciji (AI) da koristi postojeće znanje za tačna predviđanja o novim ili neviđenim kategorijama bez označenih podataka.
- Učenje sa nula snimaka oponaša način na koji ljudi uče i obrađuju informacije. Pružajući dodatne semantičke podatke, unapred istrenirani model može precizno identifikovati nove kategorije, slično kao što čovek može naučiti da prepozna gitaru sa šupljim telom razumevanjem njenih karakteristika.
- Učenje sa nula snimaka poboljšava veštačku inteligenciju unapređujući generalizaciju, skalabilnost, smanjujući preopterećenje i povećavajući efikasnost troškova. Omogućava treniranje modela na većim skupovima podataka, sticanje više znanja kroz prenos učenja, bolje razumevanje konteksta i smanjenje potrebe za obimnim označenim podacima. Kako veštačka inteligencija napreduje, učenje sa nula snimaka postaće još važnije u rešavanju kompleksnih izazova u različitim oblastima.
Jedan od glavnih ciljeva dubokog učenja jeste razvijanje modela sa opštim znanjem. Generalizacija je od vitalnog značaja, jer osigurava da je model naučio značajne obrasce i da može donositi tačna predviđanja ili odluke kada se suoči sa novim ili nepoznatim podacima. Obučavanje takvih modela često zahteva velike količine označenih podataka. Međutim, takvi podaci mogu biti skupi, zahtevati mnogo rada i ponekad biti nedostupni.
Učenje sa nula snimaka je implementirano kako bi se premostio ovaj jaz, omogućavajući AI da koristi svoje postojeće znanje za donošenje prilično tačnih predviđanja uprkos nedostatku označenih podataka.
Šta je Učenje sa Nula Snimaka?
Učenje sa nula snimaka je poseban tip tehnike prenosnog učenja. Fokusira se na upotrebu unapred obučenog modela za identifikaciju novih, nikad pre viđenih kategorija, jednostavnim pružanjem dodatnih informacija koje opisuju detalje nove kategorije.
Koristeći opšte znanje modela o određenim temama i dajući mu dodatne semantičke informacije o tome šta da traži, model bi trebao biti u stanju da prilično precizno odredi koji predmet ima zadatak da identifikuje.
Recimo da treba da identifikujemo zebru. Međutim, nemamo model koji može identifikovati takve životinje. Dakle, koristimo već postojeći model, obučen da identifikuje konje, i kažemo modelu da su konji sa crno-belim prugama zebre. Kada počnemo da testiramo model slikama zebri i konja, velike su šanse da će model tačno identifikovati svaku životinju.
Slično mnogim drugim tehnikama dubokog učenja, učenje sa nula snimaka imitira način na koji ljudi uče i obrađuju informacije. Ljudi su poznati kao prirodni učenici. Ako biste dobili zadatak da pronađete gitaru sa šupljim telom u muzičkoj radnji, možda biste imali problema da je nađete. Ali ako vam kažem da je šuplje telo u osnovi gitara sa rupom u obliku slova f na jednoj ili obe strane, verovatno biste je odmah pronašli.

Kao primer iz stvarnog sveta, koristićemo aplikaciju za klasifikaciju sa nula snimaka, koju nudi open source LLM hosting sajt Hugging Face, koristeći model clip-vit-large.
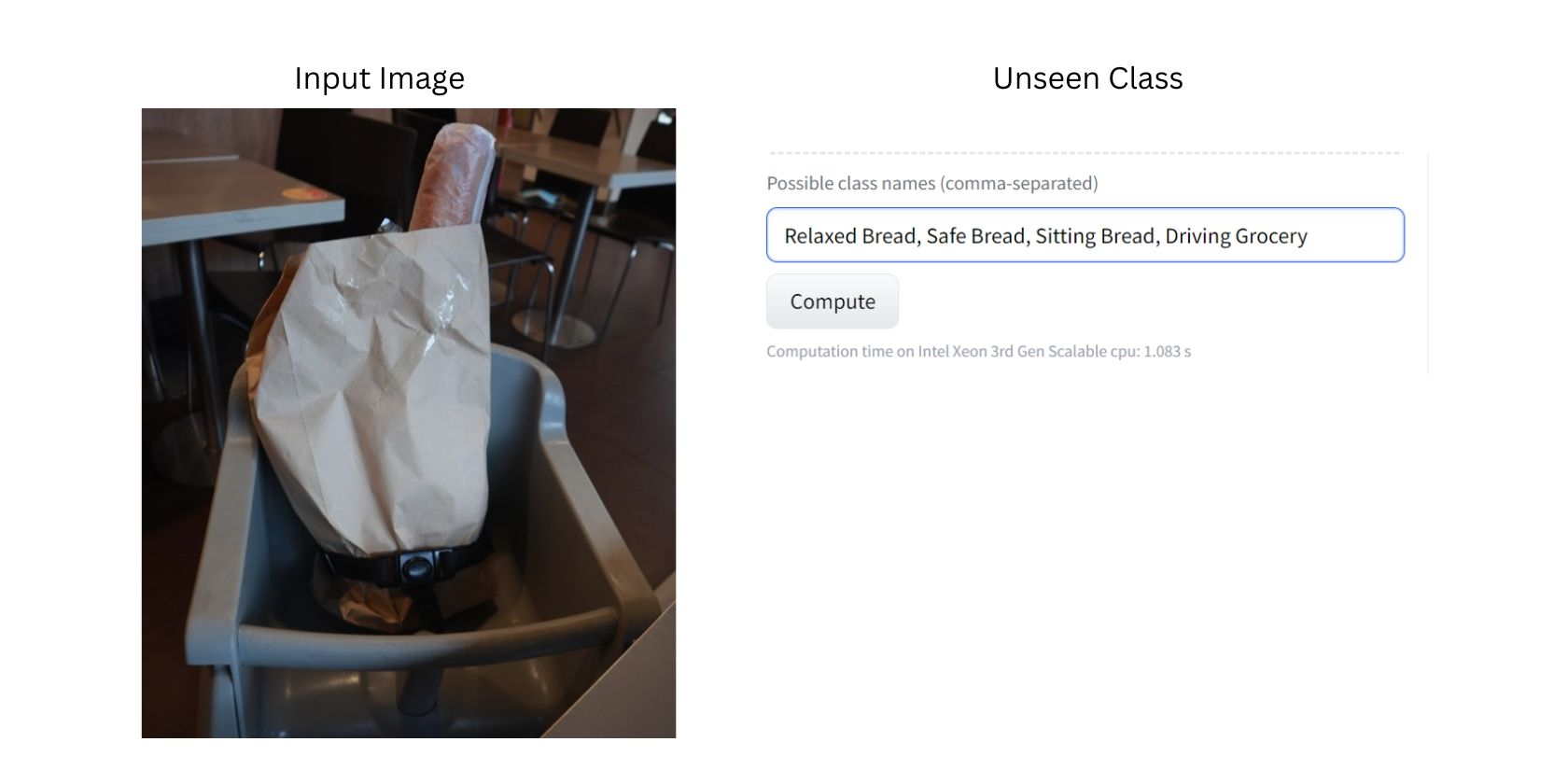
Ova fotografija prikazuje sliku hleba u torbi za kupovinu, koja je pričvršćena na stolicu za hranjenje. Budući da je model treniran na velikom broju slika, on verovatno može da identifikuje svaki predmet na fotografiji, kao što su hleb, namirnice, stolice i sigurnosni pojasevi.
Sada želimo da model klasifikuje sliku koristeći prethodno neviđene kategorije. U ovom slučaju, nove ili neviđene kategorije bi bile „Opušten hleb“, „Bezbedan hleb“, „Sedeći hleb“, „Vožnja namirnicama“ i „Sigurne namirnice“.
Važno je napomenuti da smo namerno koristili neobične, neviđene kategorije i slike kako bismo demonstrirali efikasnost klasifikacije sa nula snimaka na slici.
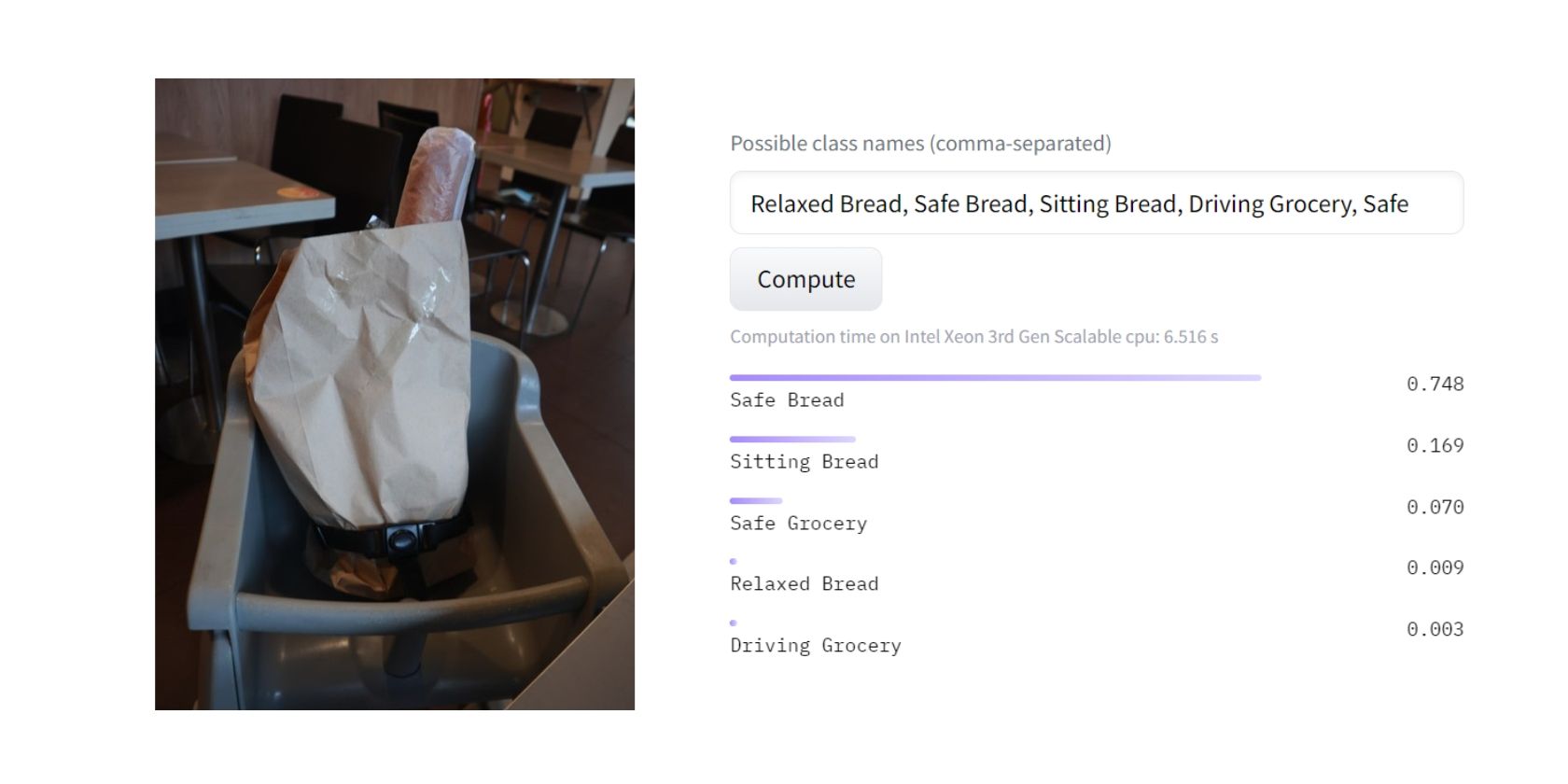
Nakon testiranja modela, on je uspeo da klasifikuje sa oko 80% sigurnosti da je najprikladnija klasifikacija za sliku „Bezbedan hleb“. To je verovatno zato što model pretpostavlja da je stolica za hranjenje više u funkciji sigurnosti, nego za sedenje, opuštanje ili vožnju.
Odlično! Lično bih se složio sa rezultatom modela. Ali kako je tačno model došao do takvog rezultata? Evo opšteg pregleda načina na koji funkcioniše učenje sa nula snimaka.
Kako Funkcioniše Učenje sa Nula Snimaka
Učenje sa nula snimaka može pomoći unapred obučenom modelu da identifikuje nove kategorije bez pružanja označenih podataka. U svom najjednostavnijem obliku, učenje sa nula snimaka se odvija u tri koraka:
1. Priprema
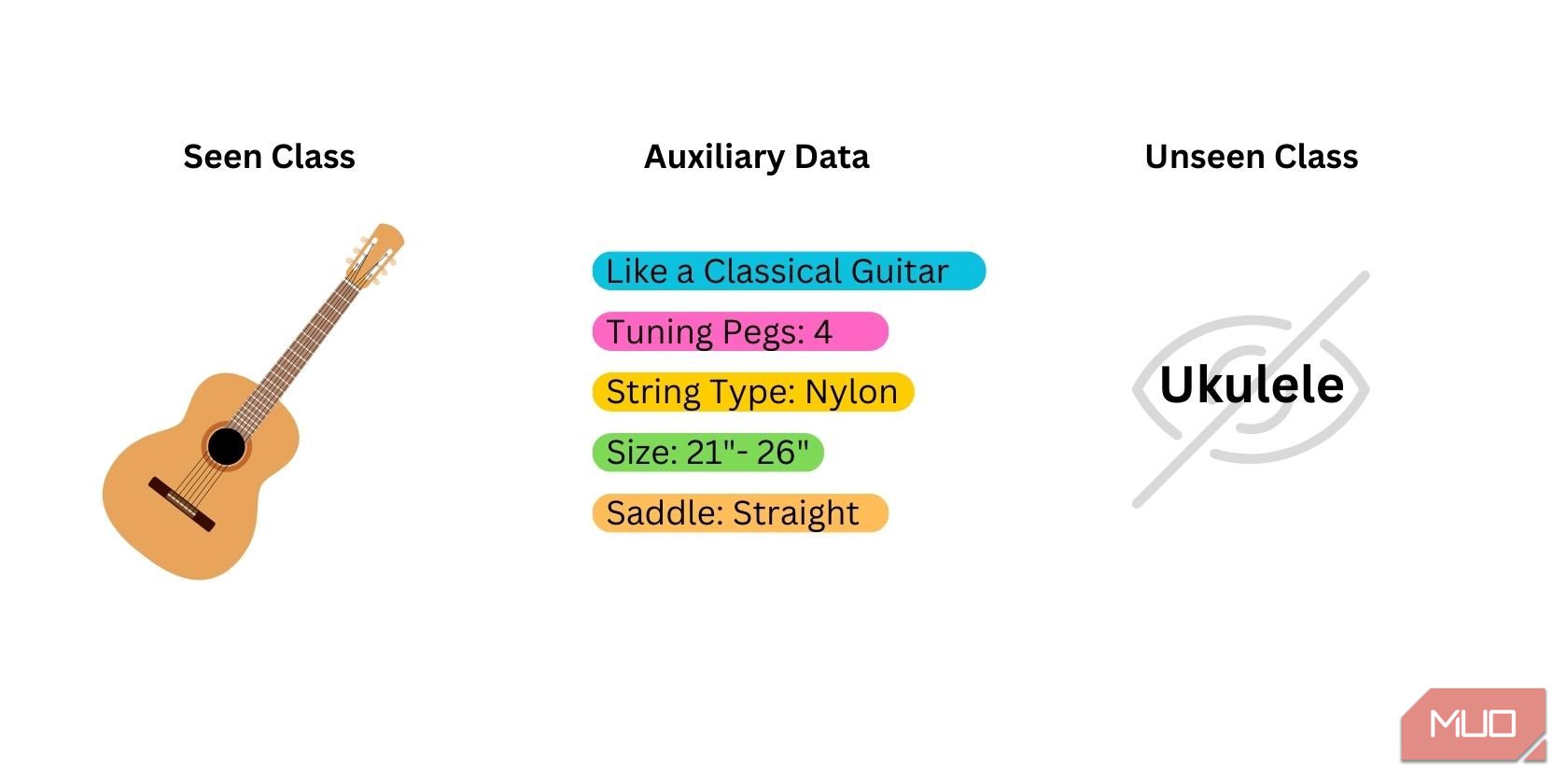
Učenje sa nula snimaka počinje pripremom tri vrste podataka:
- Viđena kategorija: Podaci korišćeni tokom obuke unapred obučenog modela. Model već ima ove viđene kategorije. Najbolji modeli za učenje sa nula snimaka su oni koji su obučeni na kategorijama koje su usko povezane sa novom kategorijom koju želite da model identifikuje.
- Neviđena/Nova kategorija: Podaci koji nikada nisu korišćeni tokom obuke modela. Ove podatke ćete morati sami da pripremite, jer ih ne možete dobiti od modela.
- Semantički/pomoćni podaci: Dodatni delovi informacija koji mogu pomoći modelu da identifikuje novu kategoriju. To mogu biti reči, fraze, vektorske reprezentacije reči ili nazivi kategorija.
2. Semantičko Mapiranje
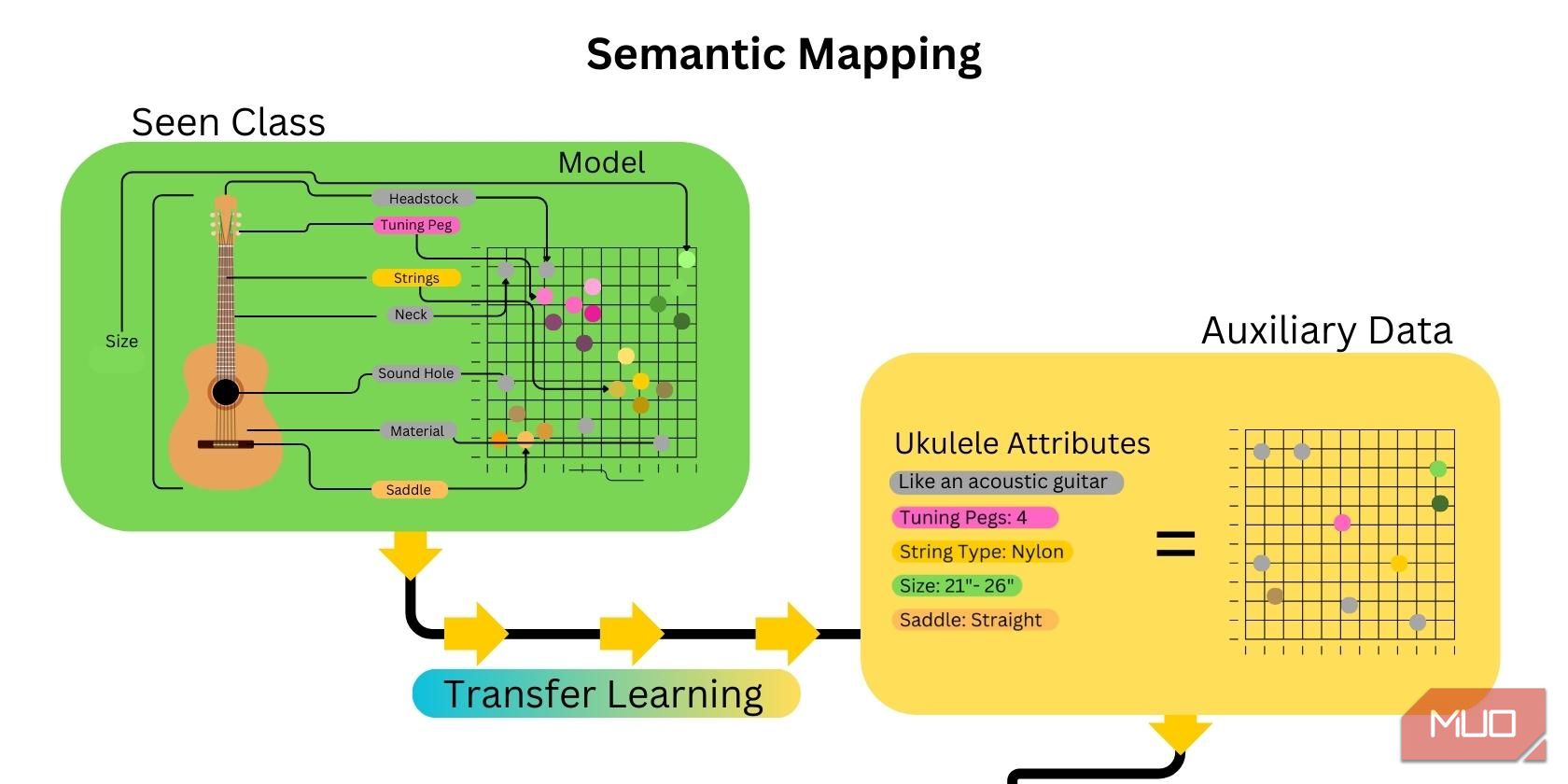
Sledeći korak je mapiranje karakteristika neviđene kategorije. Ovo se postiže kreiranjem vektorske reprezentacije reči i pravljenjem semantičke mape koja povezuje atribute ili karakteristike neviđene kategorije sa datim pomoćnim podacima. Korišćenje AI transfernog učenja ubrzava proces, jer su mnogi atributi koji se odnose na neviđenu kategoriju već mapirani.
3. Zaključivanje
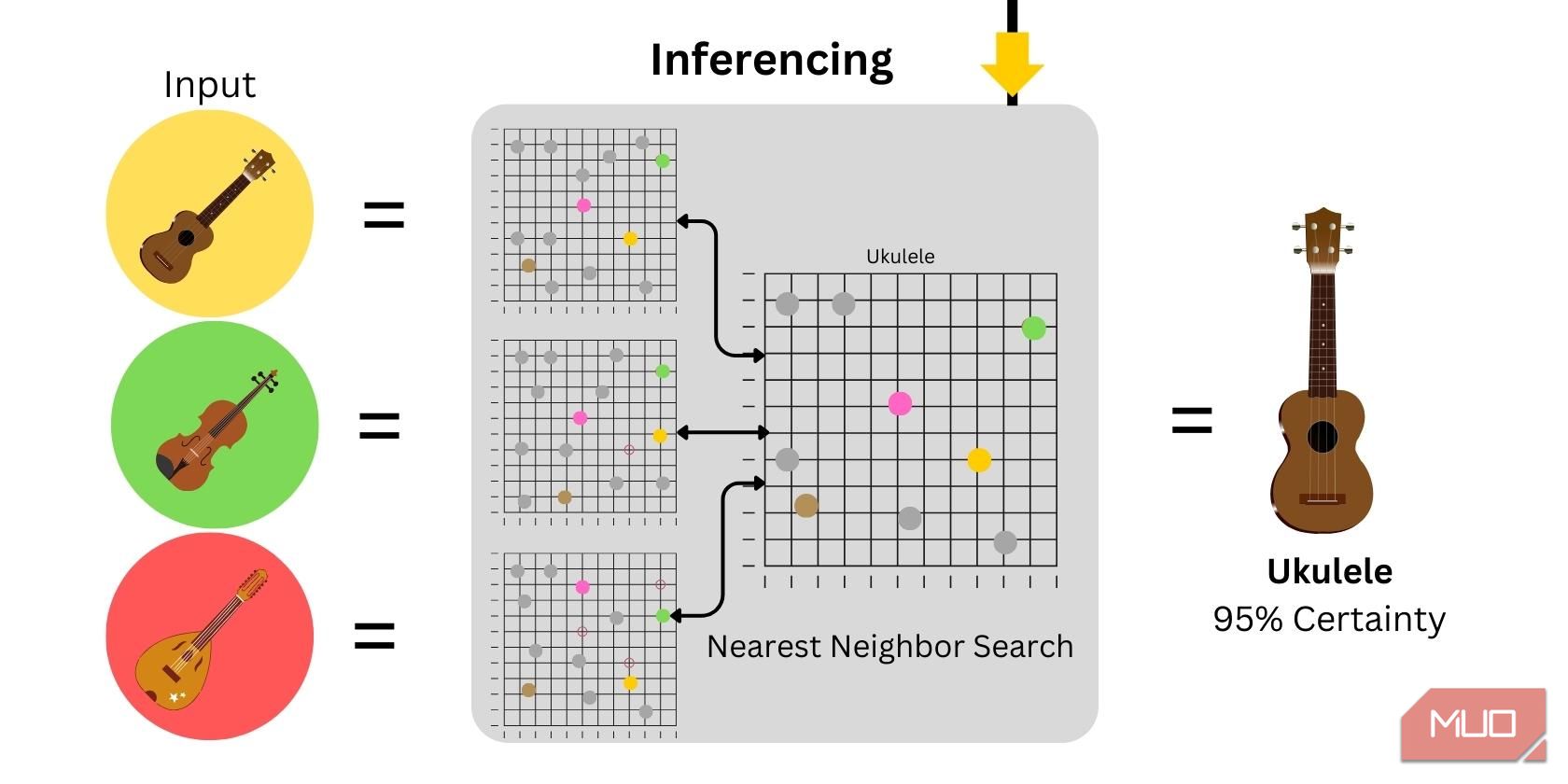
Izvođenje zaključaka predstavlja korišćenje modela za generisanje predviđanja ili rezultata. U klasifikaciji slika sa nula snimaka, vektorska reprezentacija reči se generiše na osnovu date ulazne slike, a zatim se crta i upoređuje sa pomoćnim podacima. Stepen pouzdanosti zavisiće od sličnosti između ulaznih i dostavljenih pomoćnih podataka.
Kako Učenje sa Nula Snimaka Unapređuje AI
Učenje sa nula snimaka unapređuje AI modele rešavanjem nekoliko izazova u mašinskom učenju, uključujući:
- Poboljšana generalizacija: Smanjenje zavisnosti od označenih podataka omogućava da se modeli treniraju na većim skupovima podataka, poboljšavajući generalizaciju i čineći model robusnijim i pouzdanijim. Kako modeli postaju iskusniji i više generalizovani, možda će biti moguće da modeli uče zdrav razum, umesto tipičnog načina analize informacija.
- Skalabilnost: Modeli se mogu kontinuirano obučavati i sticati više znanja kroz prenos učenja. Kompanije i nezavisni istraživači mogu konstantno poboljšavati svoje modele kako bi bili sposobniji u budućnosti.
- Smanjena mogućnost prekomernog prilagođavanja: Prekomerno prilagođavanje se može dogoditi zbog činjenice da je model treniran na malom skupu podataka koji ne sadrži dovoljno raznolikosti da bi predstavio sve moguće ulazne podatke. Obučavanje modela kroz učenje sa nula snimaka smanjuje šanse za prekomerno prilagođavanje, time što se model uči da bolje razume kontekst predmeta.
- Isplativost: Obezbeđivanje velikih količina označenih podataka može zahtevati vreme i resurse. Korišćenjem transfernog učenja sa nula snimaka, treniranje robusnog modela se može obaviti uz mnogo manje vremena i označenih podataka.
Kako veštačka inteligencija bude napredovala, tehnike kao što je učenje sa nula snimaka postaće još važnije.
Budućnost Učenja sa Nula Snimaka
Učenje sa nula snimaka je postalo suštinski deo mašinskog učenja. Omogućava modelima da prepoznaju i klasifikuju nove kategorije bez eksplicitne obuke. Sa stalnim napretkom u arhitekturi modela, pristupima zasnovanim na atributima i multimodalnoj integraciji, učenje sa nula snimaka može značajno pomoći da modeli budu mnogo prilagodljiviji u rešavanju složenih izazova u robotici, zdravstvu i kompjuterskom vidu.