U današnje vreme, podaci su postali ključni element u razvoju modela mašinskog učenja, testiranju aplikacija i sticanju uvida u poslovanje.
Međutim, zbog usklađenosti sa brojnim propisima o zaštiti podataka, pristup tim podacima često je ograničen i strogo kontrolisan. Dobijanje neophodnog odobrenja za pristup takvim podacima može potrajati i više meseci. Kao alternativu, preduzeća sve češće koriste sintetičke podatke.
Šta su to sintetički podaci?
Foto: Twinify
Sintetički podaci predstavljaju veštački generisane informacije koje statistički imitiraju postojeći skup podataka. Mogu se koristiti zajedno sa stvarnim podacima kako bi se unapredili modeli veštačke inteligencije (AI) ili kao potpuna zamena za njih.
S obzirom na to da ne pripadaju nijednom pojedinačnom subjektu i ne sadrže lične, osetljive informacije (kao što su brojevi socijalnog osiguranja), mogu se koristiti kao alternativa pravim, proizvodnim podacima, čime se štiti privatnost korisnika.
Razlike između stvarnih i sintetičkih podataka
- Najvažnija razlika leži u načinu na koji se ove dve vrste podataka generišu. Stvarni podaci potiču od stvarnih ljudi čije su informacije prikupljene putem anketa ili tokom korišćenja aplikacije. S druge strane, sintetički podaci su veštački stvoreni, ali i dalje nalikuju originalnom skupu podataka.
- Druga razlika tiče se propisa o zaštiti podataka koji utiču na stvarne, a ne i na sintetičke podatke. Kod stvarnih podataka, subjekti treba da budu informisani o tome koji se podaci o njima prikupljaju i u koju svrhu, uz ograničenja u pogledu njihove upotrebe. Međutim, ovi propisi ne važe za sintetičke podatke jer oni ne mogu biti povezani ni sa jednim pojedincem i ne sadrže lične podatke.
- Treća razlika je količina dostupnih podataka. Kod stvarnih podataka, količina je ograničena onim što korisnici dobrovoljno daju. Sa druge strane, moguće je generisati onoliko sintetičkih podataka koliko je potrebno.
Zašto treba razmisliti o korišćenju sintetičkih podataka
- Proizvodnja je relativno jeftinija jer je moguće generisati znatno veće skupove podataka koji liče na postojeći, manji skup. To znači da će modeli mašinskog učenja imati više podataka za obuku.
- Generisani podaci se automatski označavaju i čiste, što štedi vreme na dugotrajan proces pripreme podataka za mašinsko učenje ili analitiku.
- Nema problema sa privatnošću jer podaci ne identifikuju pojedince i ne pripadaju određenom subjektu. To znači da se mogu slobodno koristiti i deliti.
- Može se prevazići pristrasnost veštačke inteligencije obezbeđivanjem dobre zastupljenosti manjinskih klasa, što doprinosi razvoju poštene i odgovorne AI.
Kako generisati sintetičke podatke
Proces generisanja se razlikuje u zavisnosti od alata, ali generalno, počinje povezivanjem generatora sa postojećim skupom podataka. Zatim se identifikuju lični podaci u tom skupu i označavaju se za izuzimanje ili zamagljivanje.
Generator dalje utvrđuje tipove podataka u preostalim kolonama i statističke obrasce u njima. Nakon toga, možete generisati onoliko sintetičkih podataka koliko vam je potrebno.
Obično se generisani podaci mogu uporediti sa originalnim kako bi se procenila njihova sličnost sa stvarnim podacima.
U nastavku, istražujemo alate za generisanje sintetičkih podataka za obuku modela mašinskog učenja.
Mostly AI

Mostly AI poseduje sintetički generator podataka koji koristi veštačku inteligenciju da uči iz statističkih šablona originalnog skupa. AI zatim generiše izmišljene podatke koji su u skladu sa naučenim obrascima.
Sa Mostly AI, mogu se generisati cele baze podataka sa referentnim integritetom, a moguće je sintetizovati različite tipove podataka koji mogu poboljšati razvoj AI modela.
Synthesized.io

Synthesized.io je popularan izbor među vodećim kompanijama za njihove AI projekte. Da biste koristili Synthesized.io, potrebno je definisati zahteve za podacima u YAML konfiguracionoj datoteci.
Nakon toga, kreira se zadatak i pokreće se kao deo procesa obrade podataka. Pored toga, ovaj alat nudi i besplatan nivo korišćenja koji omogućava eksperimentisanje i procenu da li odgovara vašim potrebama.
iData

Sa iData, moguće je generisati tabelarne podatke, podatke vremenskih serija, transakcione, višetabelarne i relacione podatke. To omogućava izbegavanje problema vezanih za prikupljanje, deljenje i kvalitet podataka.
iData dolazi sa AI i SDK-om za interakciju sa platformom. Takođe, imaju besplatan nivo za demonstraciju mogućnosti proizvoda.
Gretel AI

Gretel AI nudi API-je za generisanje neograničenih količina sintetičkih podataka. Gretel ima generator podataka otvorenog koda koji se može instalirati i koristiti.
Kao alternativa, može se koristiti i REST API ili CLI, što će se naplaćivati. Ipak, cena je razumna i zavisi od veličine preduzeća.
Copulas
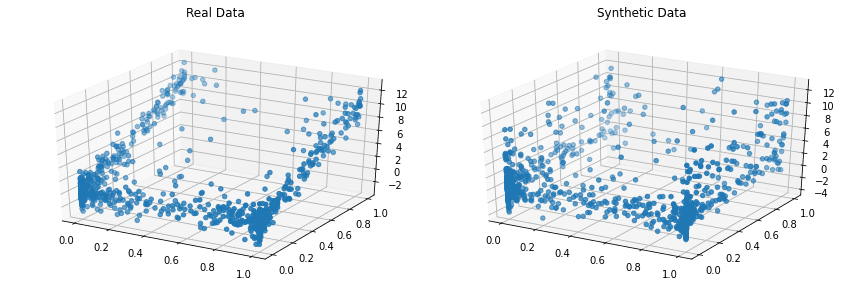
Copulas je Python biblioteka otvorenog koda za modeliranje multivarijantnih distribucija korišćenjem kopula funkcija i za generisanje sintetičkih podataka koji prate ista statistička svojstva.
Projekat je započet 2018. godine na MIT-u, kao deo projekta Synthetic Data Vault.
CTGAN
CTGAN se sastoji od generatora koji su u mogućnosti da uče iz stvarnih podataka jedne tabele i da generišu sintetičke podatke iz identifikovanih obrazaca.
Implementirana je kao Python biblioteka otvorenog koda. CTGAN, zajedno sa Copulas-om, je deo projekta Synthetic Data Vault.
Doppelganger
DoppelGANger je open-source implementacija Generative Adversarial Networks za generisanje sintetičkih podataka.
DoppelGANger je koristan za generisanje podataka o vremenskim serijama i koriste ga kompanije kao što je Gretel AI. Python biblioteka je dostupna besplatno i otvorenog je koda.
Synth

Synth je generator podataka otvorenog koda koji pomaže u kreiranju realističnih podataka prema specifikacijama, prikrivanju ličnih informacija i razvijanju testnih podataka za aplikacije.
Synth se može koristiti za generisanje serija u realnom vremenu i relacionih podataka za potrebe mašinskog učenja. Synth je takođe nezavistan od baze podataka, što znači da se može koristiti sa SQL i NoSQL bazama podataka.
SDV.dev
SDV je skraćenica od Synthetic Data Vault. SDV.dev je softverski projekat koji je započet na MIT-u 2016. godine i koji je razvio različite alate za generisanje sintetičkih podataka.
Ti alati uključuju Copulas, CTGAN, DeepEcho i RDT. Implementirani su kao Python biblioteke otvorenog koda koje su jednostavne za korišćenje.
Tofu
Tofu je Python biblioteka otvorenog koda za generisanje sintetičkih podataka na osnovu podataka iz biobanke Ujedinjenog Kraljevstva. Za razliku od prethodno pomenutih alata koji pomažu pri generisanju bilo koje vrste podataka na osnovu postojećeg skupa, Tofu generiše podatke koji nalikuju isključivo podacima iz biobanke.
UK Biobank je studija o fenotipskim i genotipskim karakteristikama 500.000 odraslih osoba srednjih godina iz Velike Britanije.
Twinify
Twinify je softverski paket koji se koristi kao biblioteka ili alat komandne linije za uparivanje osetljivih podataka tako što proizvodi sintetičke podatke sa identičnim statističkim distribucijama.

Da biste koristili Twinify, potrebno je uneti prave podatke kao CSV datoteku, a alat će iz njih naučiti da proizvede model koji se može koristiti za generisanje sintetičkih podataka. Potpuno je besplatan za korišćenje.
Datanamic
Datanamic pomaže u kreiranju testnih podataka za aplikacije zasnovane na podacima i mašinskom učenju. Generiše podatke na osnovu karakteristika kolone kao što su adrese e-pošte, imena i brojevi telefona.
Datanamic generatori podataka su prilagodljivi i podržavaju većinu baza podataka, kao što su Oracle, MySQL, MySQL Server, MS Access i Postgres. Takođe, obezbeđuje referentni integritet u generisanim podacima.
Benerator
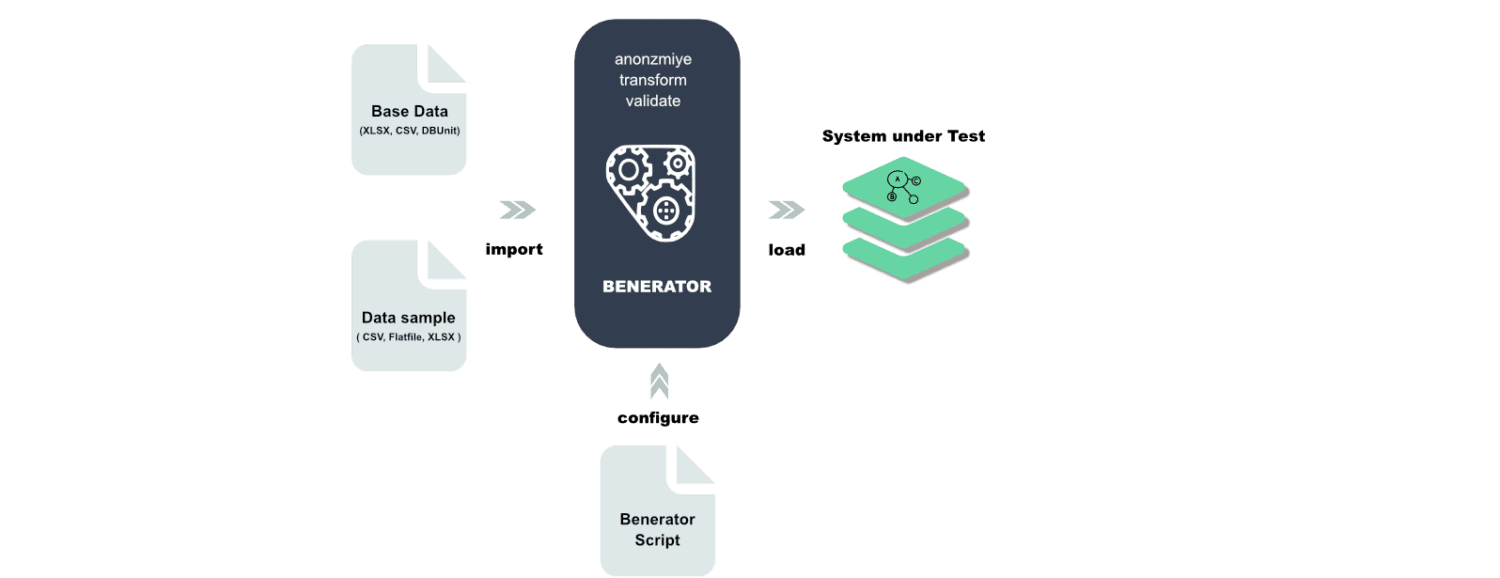
Benerator je softver za prikrivanje podataka, njihovo generisanje i migraciju u svrhe testiranja i obuke. Koristeći Benerator, podaci se opisuju pomoću XML-a (Extensible Markup Language), a zatim se generišu pomoću alata komandne linije.
Dizajniran je tako da ga mogu koristiti i oni koji nisu programeri, a omogućava generisanje milijardi redova podataka. Benerator je besplatan i otvorenog koda.
Završne reči
Gartner predviđa da će do 2030. godine biti više sintetičkih podataka korišćenih za mašinsko učenje nego pravih podataka.
To i ne iznenađuje, s obzirom na troškove i brige oko privatnosti pri korišćenju stvarnih podataka. Zato je neophodno da preduzeća steknu znanja o sintetičkim podacima i različitim alatima koji im mogu pomoći u njihovom generisanju.
Zatim pogledajte sintetičke alate za praćenje vašeg poslovanja na mreži.