Различити приступи складиштењу података у облаку
База података. Језеро података. Кућа на језеру. Уколико вас бар једна од ових синтагми не асоцира ни на шта, вероватно нисте у свету података.
Ипак, такав закључак би био преурањен, јер данас је све тесно повезано са подацима. Или како то воле да кажу руководиоци у корпорацијама:
- Пословање засновано на подацима, погоњено подацима.
- Доступност података било где, било када, на било који начин.
Подаци као највреднија имовина
Чини се да подаци постају најдрагоценија имовина многих компанија. Сећам се времена када су велике компаније генерисале огромне количине података, мислим на терабајте нових података сваког месеца. То је било пре 10-15 година. Сада, међутим, ту количину података можете генерисати за свега неколико дана. Питање је да ли је то уистину неопходно, чак и ако је у питању садржај који ће неко заправо користити. И одговор је: дефинитивно није 😃.
Неће сваки садржај бити од користи, а неки делови неће бити ни једном искоришћени. Често сам био сведок ситуација када компаније креирају огромне количине података, који након успешног учитавања постају потпуно бескорисни.
Међутим, то више није од пресудног значаја. Складиштење података – које се данас углавном одвија у облаку – је јефтино, извори података расту изузетном брзином, и нико не може да предвиди шта ће бити потребно за годину дана, када се нове услуге имплементирају у систем. У таквим ситуацијама, чак и стари подаци могу постати вредни.
Стога је стратегија складиштити што више података. Али, исто тако, у што ефикаснијем формату. На тај начин, подаци не само да ће бити ефикасно сачувани, већ ће их бити лако претраживати, поново користити или трансформисати и даље дистрибуирати.
Погледајмо три основна начина за постизање овог циља у оквиру AWS-а:
- Athena Database – приступачан и ефикасан, иако једноставан начин за креирање језера података у облаку.
- Redshift Database – озбиљна верзија складишта података у облаку, са потенцијалом да замени већину постојећих локалних решења, која не могу да прате експоненцијални раст података.
- Databricks – комбинација језера података и складишта података у јединствено решење, са додатним предностима.
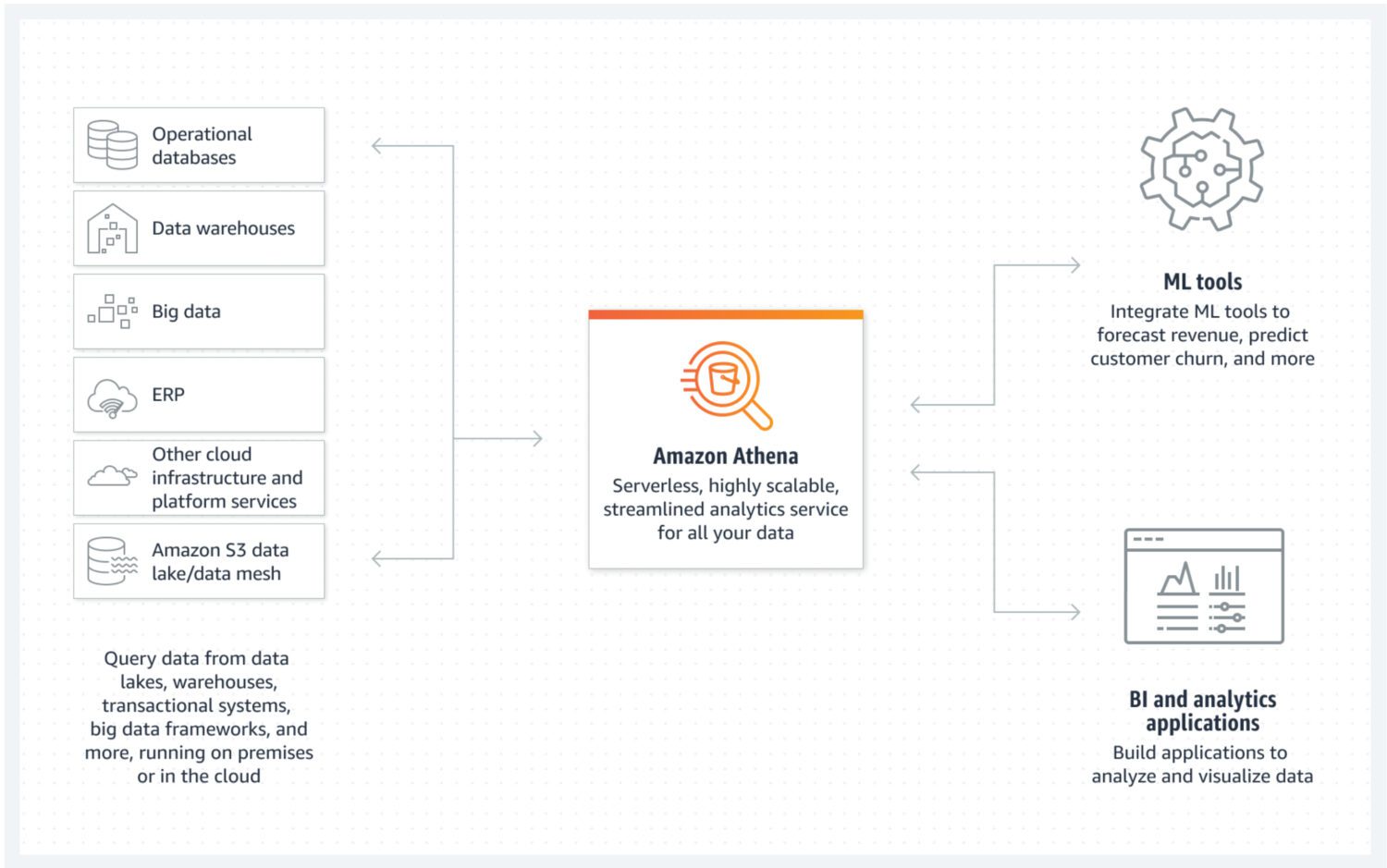
Језеро података користећи AWS Athena
 Извор: aws.amazon.com
Извор: aws.amazon.com
Језеро података је место где се пристигли подаци могу брзо складиштити у неструктурираном, полуструктурираном или структурираном облику. Не очекује се да ће се ови подаци мењати након складиштења. Напротив, циљ је да буду што је могуће више атомични и непроменљиви. Једино се на тај начин обезбеђује максимални потенцијал за поновну употребу у каснијим фазама. Ако би се ово својство података изгубило након првог учитавања у језеро података, не би било могуће повратити изгубљене информације.
AWS Athena је база података која ради директно на S3 корпама, без кластера сервера у позадини. То је заиста приступачна услуга за формирање језера података. Структурирани формати датотека као што су паркет или CSV датотеке омогућавају организовање података. S3 корпа садржи датотеке, а Athena их користи кад год процеси траже податке из базе података.
Athena не подржава одређене функције које се иначе сматрају стандардним, као што су изјаве за ажурирање. Због тога, на Атену треба гледати као на веома једноставну опцију. Са друге стране, то вам помаже да спречите модификацију вашег атомичног језера података једноставно зато што то није могуће 😐.
Подржава индексирање и партиционисање, што омогућава ефикасно извршавање наредби за одабир и креирање логички одвојених делова података (на пример, раздвојених датумом или кључним колонама). Такође, једноставно се хоризонтално скалира, јер је процедура једноставна као додавање нових корпи у инфраструктуру.

Предности и мане
Предности које треба имати у виду:
- Чињеница да је Athena приступачна (састоји се само од S3 корпи и трошкова SQL коришћења по потреби) је најзначајнија предност. Ако желите да направите приступачно језеро података на AWS-у, онда је ово права опција.
- Као изворна услуга, Athena се лако интегрише са другим AWS услугама, као што су Amazon QuickSight за визуелизацију података или AWS Glue Data Catalog за креирање трајних структурираних метаподатака.
- Најбоља је за покретање ад хок упита над великом количином структурираних или неструктурираних података, без одржавања целокупне инфраструктуре.
Недостаци које треба узети у обзир:
- Athena није нарочито ефикасна у брзом враћању сложених упита за одабир, посебно ако упити не прате модел података према коме је дизајнирано преузимање података из језера.
- Због тога је мање флексибилна у погледу потенцијалних будућих промена у моделу података.
- Athena не подржава никакве додатне напредне функције, а ако желите да нешто специфично буде део услуге, морате то да имплементирате.
- Уколико очекујете да ћете користити податке из језера података у неком напреднијем слоју презентације, често је једини избор да га комбинујете са другом базом података која је погоднија за ту намену, као што су AWS Aurora или AWS DynamoDB.
Сврха и употреба у пракси
Одаберите Athenu ако вам је циљ креирање једноставног језера података без напредних функционалности карактеристичних за складиште података. На пример, уколико не очекујете озбиљне аналитичке упите високих перформанси који се редовно покрећу преко језера. Уместо тога, приоритет је имати скуп непроменљивих података са једноставним проширењем за складиштење података.
Не морате превише да бринете о недостатку простора. Чак и трошкове S3 корпи можете додатно смањити применом политике животног циклуса података. То значи премештање података кроз различите типове S3 корпи, које су више намењене за архивирање, са споријим временима преузимања, али нижим трошковима.
Сјајна карактеристика Athenae је то што аутоматски креира датотеку која садржи податке који су резултат вашег SQL упита. Затим можете узети ову датотеку и користити је у било коју сврху. Стога је ово добра опција ако имате доста ламбда услуга које даље обрађују податке у више корака. Сваки ламбда излаз ће аутоматски бити резултат у структурираном формату датотеке, спреман за накнадну обраду.
Athena је добра опција када велика количина необрађених података доспева у вашу инфраструктуру облака и не морате да је обрађујете у тренутку учитавања. То значи да вам је само потребно брзо складиштење у облаку, у лако разумљивој структури.
Други пример би био креирање наменског простора за архивирање података за другу услугу. У том случају, Athena DB би постала јефтино резервно место за све податке који вам тренутно нису потребни, али то би се могло променити у будућности. У овом тренутку само ћете унети податке и послати их даље.
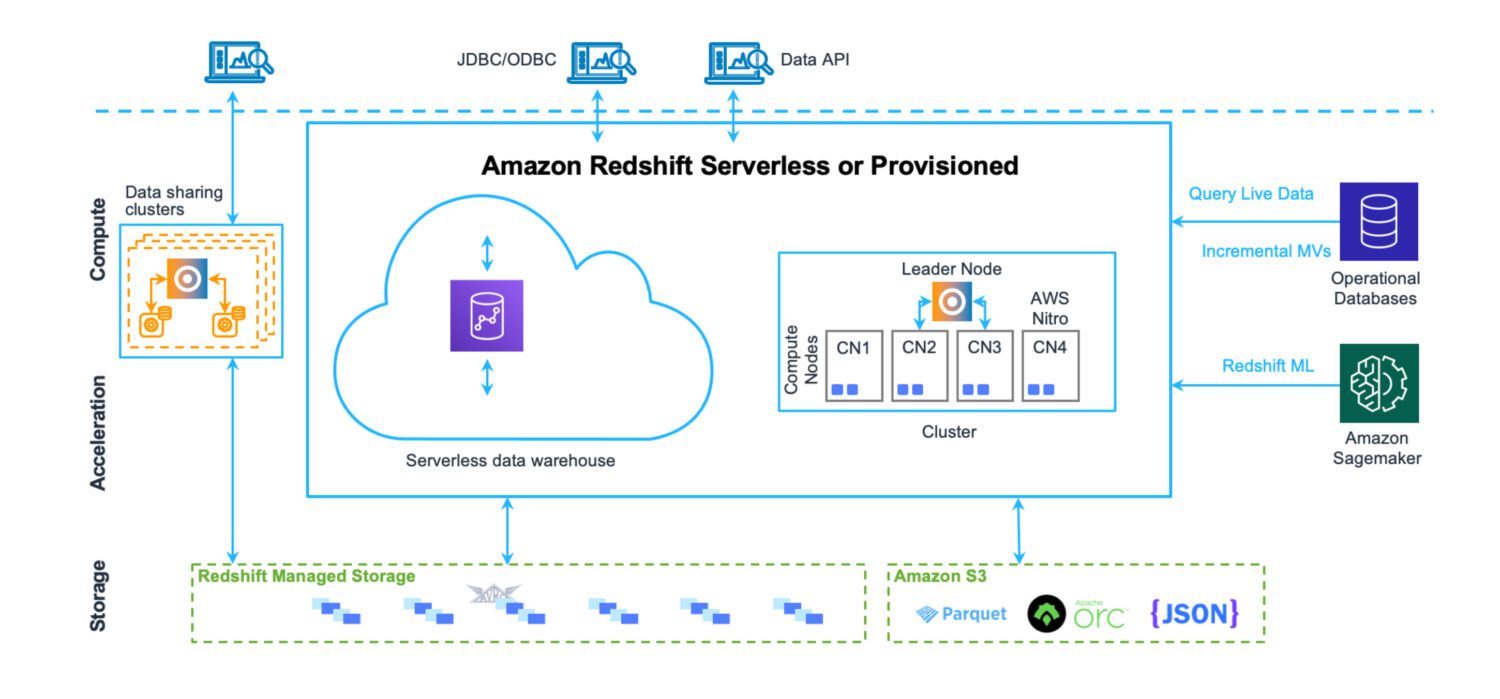
Складиште података AWS Redshift
 Извор: aws.amazon.com
Извор: aws.amazon.com
Складиште података је место где се подаци чувају на веома структурисан начин. Лако се учитавају и извлаче. Циљ је да се покрене велики број веома сложених упита, спајањем бројних табела. Постоје различите аналитичке функције за израчунавање статистике над постојећим подацима. Коначни циљ је издвајање будућих предвиђања и чињеница које ће се користити у даљем пословању, на основу постојећих података.
Redshift је комплетан систем за складиштење података. Са кластер серверима за подешавање и скалирање – хоризонтално и вертикално – и системом за складиштење базе података оптимизованим за брзо враћање сложених упита. Иако данас можете покренути Redshift и у режиму без сервера. Нема датотека на S3 или нешто слично. Ово је стандардни кластер сервера базе података са сопственим форматом складиштења.
Садржи алате за праћење перформанси који су спремни за употребу, као и прилагодљиве метрике контролне табле, које можете користити да фино подесите перформансе за своје потребе. Администрација је такође доступна преко засебних контролних табли. Потребно је мало напора да се разумеју све могуће функције и подешавања, као и њихов утицај на кластер. Ипак, није ни приближно сложено као администрација Oracle сервера у случају локалних решења.
Иако постоје одређена AWS ограничења у Redshift-у, која постављају границе начину његове свакодневне употребе (на пример, ограничења за количину истовремених активних корисника или сесија у једном кластеру), чињеница да се операције извршавају брзо помаже да се у одређеној мери заобиђу та ограничења.

Предности и мане
Предности које треба размотрити:
- Изворна AWS услуга за складиштење података у облаку, коју је лако интегрисати са другим услугама.
- Централно место за складиштење, праћење и унос различитих типова извора података из разних система.
- Уколико сте одувек желели да имате складиште података без сервера, без инфраструктуре за одржавање, сада је то могуће.
- Оптимизовано за анализу и извештавање високих перформанси. За разлику од решења језера података, постоји релациони модел за чување свих пристиглих података.
- Redshift механизам базе података потиче из PostgreSQL-а, што обезбеђује високу компатибилност са другим системима база података.
- Веома корисне изјаве COPY и UNLOAD за учитавање и преузимање података из и у S3 корпе.
Недостаци које треба узети у обзир:
- Redshift не подржава велики број истовремених активних сесија. Сесије ће бити стављене на чекање и обрађиване секвенцијално. Иако то можда није проблем у већини случајева, пошто су операције заиста брзе, то је ограничење у системима са великим бројем активних корисника.
- Иако Redshift подржава многе функционалности које су раније биле доступне у зрелим Oracle системима, још увек није на истом нивоу. Неке од очекиваних функција можда неће бити доступне (попут DB окидача). Или их Redshift подржава у прилично ограниченом облику (попут материјализованих погледа).
- Када год вам је потребан напреднији, прилагођени посао обраде података, морате га креирати од нуле. Најчешће се користи Python или Javascript. То није тако једноставно као PL/SQL код Oracle система, где чак и функције и процедуре користе језик који је веома сличан SQL упитима.
Сврха и употреба у пракси
Redshift може бити ваш централни склад за све различите изворе података, који су раније постојали ван облака. То је важећа замена за претходна Oracle решења за складиштење података. Пошто је такође релациона база података, миграција са Oracle-а је једноставна.
Уколико имате постојећа решења за складиштење података на многим локацијама, која нису јединствена у погледу приступа, структуре или унапред дефинисаног скупа уобичајених процеса који се извршавају над подацима, Redshift је одличан избор.
Пружиће вам прилику да спојите све различите системе складишта података из различитих локација и земаља под једним кровом. И даље их можете раздвојити по земљама, тако да подаци остану сигурни и доступни само онима којима су потребни. Али, истовремено, омогућиће вам да изградите јединствено решење за складиштење, које обухвата све корпоративне податке.
Други пример би могао бити изградња платформе за складиштење података са опсежном подршком за самопослуживање. Односно, као скуп обраде који корисници система могу да креирају, али који истовремено никада не постаје део заједничког решења платформе. То значи да ће такве услуге остати доступне само креатору или групи људи које је он дефинисао. И неће ни на који начин утицати на остале кориснике.
Погледајте наше поређење између језера података и складишта података.
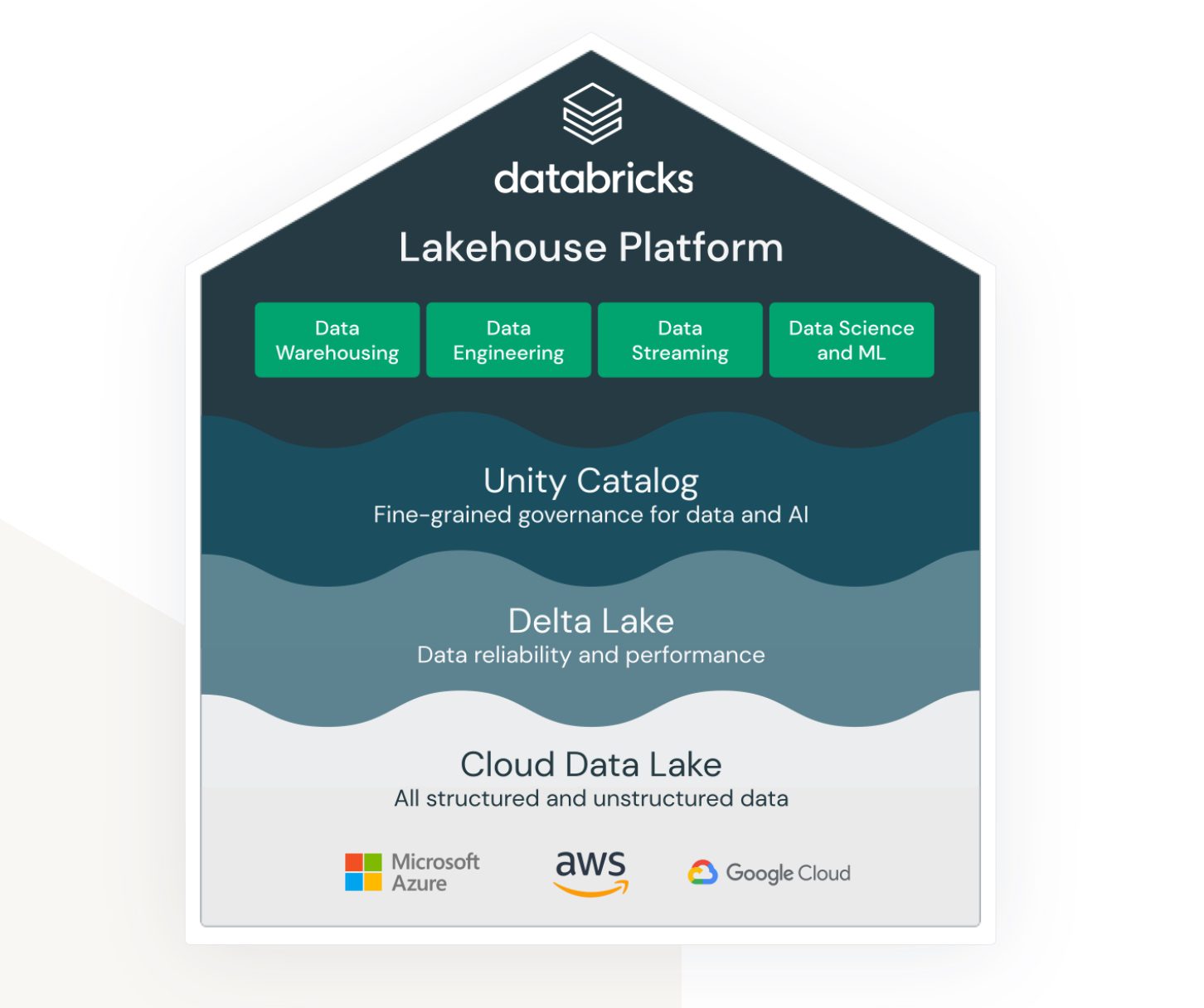
Lakehouse решење користећи Databricks на AWS-у
 Извор: databricks.com
Извор: databricks.com
Lakehouse је термин који је тесно повезан са Databricks услугом. Иако није изворна AWS услуга, она функционише у оквиру AWS екосистема и пружа различите могућности за повезивање и интеграцију са другим AWS услугама.
Databricks има за циљ да повеже (раније) веома различите области:
- Решење за складиштење неструктурираних, полуструктурираних и структурираних података у језеру података.
- Решење за структуриране и брзо доступне податке у складишту података (које се такође назива Delta Lake).
- Решење које подржава аналитику и рачунање машинског учења преко језера података.
- Управљање подацима за све наведене области, са централизованом администрацијом и готовим алатима за подршку продуктивности за различите типове програмера и корисника.
То је уобичајена платформа коју могу да користе инжењери података, SQL програмери и научници који се баве машинским учењем. Свака од група такође има скуп алата које може да користи за обављање својих задатака.
Дакле, Databricks циља на врхунско решење, покушавајући да комбинује предности језера података и складишта података у јединствено решење. Поред тога, пружа алате за тестирање и покретање модела машинског учења директно преко већ изграђених складишта података.

Предности и мане
Предности које треба узети у обзир:
- Databricks је веома скалабилна платформа за податке. Скалира се у зависности од величине радног оптерећења, а то ради чак и аутоматски.
- То је окружење за сарадњу за научнике који се баве подацима, инжењере података и пословне аналитичаре. Могућност да све ово радите у истом простору је велика предност. Не само из организационе перспективе, већ и због уштеда трошкова који су иначе потребни за одвојена окружења.
- AWS Databricks се неприметно интегрише са другим AWS услугама, као што су Amazon S3, Amazon Redshift и Amazon EMR. Ово омогућава корисницима да лако преносе податке између услуга и искористе све предности AWS услуга у облаку.
Недостаци које треба узети у обзир:
- Databricks може бити сложен за постављање и управљање, посебно за кориснике који немају искуства са обрадом великих количина података. Потребан је висок ниво техничког знања да би се максимално искористила платформа.
- Иако је Databricks исплатив у погледу модела цена „плати по потреби“, ипак може бити скуп за велике пројекте обраде података. Трошкови коришћења платформе могу брзо порасти, посебно ако корисници морају да повећају своје ресурсе.
- Databricks пружа низ готових алата и шаблона, али то такође може бити ограничавајуће за кориснике којима је потребно више опција прилагођавања. Платформа можда није погодна за кориснике којима је потребна већа флексибилност и контрола над радним токовима обраде великих количина података.
Сврха и употреба у пракси
AWS Databricks је најприкладнији за велике корпорације са огромном количином података. У том случају може да покрије захтев за учитавањем и контекстуализацијом различитих извора података из различитих спољних система.
Често се захтева да подаци буду доступни у реалном времену. То значи да ће, од тренутка када се подаци појаве у изворном систему, процеси одмах покупити, обрадити и ускладиштити податке у Databricks, одмах или са минималним кашњењем. Ако је кашњење нешто више од једног минута, сматра се обрадом у скоро реалном времену. У сваком случају, оба сценарија су остварива са Databricks платформом. Ово је углавном захваљујући великом броју адаптера и интерфејса у реалном времену који се повезују са разним другим AWS услугама.
Databricks се лако интегрише са Informatica ETL системима. Када год организација већ увелико користи Informatica екосистем, Databricks се чини као добар, компатибилан додатак платформи.
Завршна размишљања
Како обим података наставља да расте изузетном брзином, важно је знати да постоје решења која могу ефикасно да се носе са тим. Оно што је некада био кошмар за администрацију и одржавање, данас захтева веома мало административног рада. Тим може да се фокусира на креирање вредности из података.
У зависности од ваших потреба, одаберите услугу која је најприкладнија за вас. Иако је AWS Databricks нешто што ћете вероватно морати да користите након доношења одлуке, друге алтернативе су доста флексибилније, чак и ако су мање способне, посебно њихови режими без сервера. Касније је лако прећи на друго решење.