Prikupljanje podataka sa veb stranica, poznato i kao ekstrakcija podataka, podrazumeva izdvajanje specifičnih informacija. Korisnici mogu izvući različite elemente, uključujući tekst, slike, video materijale, recenzije, detalje o proizvodima i slično. Ova aktivnost je korisna za istraživanje tržišta, analizu sentimenta, praćenje konkurencije, i prikupljanje podataka za dalju obradu.
Za manje količine podataka, ručno izdvajanje, odnosno kopiranje i lepljenje željenih informacija sa veb stranica u tabele ili druge dokumente, može biti praktično. Na primer, kupac koji traži recenzije proizvoda na internetu može to učiniti ručno, selektujući i kopirajući relevantne komentare.
Međutim, kod obrade velikih skupova podataka, neophodno je koristiti automatske tehnike ekstrakcije. Moguće je razviti sopstveno rešenje ili koristiti gotove API-je, kao što su Proxy API ili Scraping API, za automatizaciju ovog procesa.
Ipak, te tehnike mogu biti neefikasne jer neke web stranice koriste zaštitne mehanizme poput captcha testova. Dodatno, potrebno je upravljati botovima i proxy serverima, što može oduzimati vreme i ograničavati obim podataka koji se mogu izvući.
Rešenje: Scraping pretraživač
Sve navedene izazove moguće je prevazići korišćenjem specijalizovanog pretraživača za web scraping, poput Bright Data Scraping Browser-a. Ovaj pretraživač, sve-u-jednom rešenje, olakšava prikupljanje podataka sa stranica koje je teško obići. Koristi grafički korisnički interfejs (GUI) i upravlja se putem Puppeteer ili Playwright API-ja, što ga čini nevidljivim za anti-bot sisteme.
Scraping Browser ima integrisane funkcije za automatsko otključavanje, koje efikasno rešavaju sve blokade. Pretraživač radi na serverima kompanije Bright Data, što eliminiše potrebu za skupom internom infrastrukturom za obradu velikih projekata.
Karakteristike Bright Data Scraping Browser-a
- Automatsko otključavanje veb stranica: Ne zahteva ručno osvežavanje jer se samostalno prilagođava rešavanju CAPTCHA, novim blokadama, prepoznavanju otiska prsta i ponovnim pokušajima. Scraping Browser se ponaša kao pravi korisnik.
- Obimna mreža proxy servera: Omogućava ciljanje bilo koje zemlje, zahvaljujući mreži od preko 72 miliona IP adresa. Može se ciljati gradove ili čak operatere, uz korišćenje najbolje tehnologije.
- Skalabilnost: Istovremeno se može otvoriti na hiljade sesija, jer pretraživač koristi Bright Data infrastrukturu za obradu svih zahteva.
- Kompatibilnost sa Puppeteer-om i Playwright-om: Omogućava upućivanje API poziva i preuzimanje proizvoljnog broja sesija pretraživača koristeći Puppeteer (Python) ili Playwright (Node.js).
- Ušteda vremena i resursa: Umesto ručnog postavljanja proxy servera, Scraping Browser sve obavlja u pozadini. Takođe, eliminiše potrebu za internom infrastrukturom, jer je alat zasnovan na cloud tehnologiji.
Kako podesiti Scraping pretraživač
- Posetite veb stranicu Bright Data i odaberite Scraping Browser pod karticom „Rešenja za scraping“.
- Kreirajte nalog. Na raspolaganju su dve opcije: „Započnite besplatnu probnu verziju“ i „Započnite besplatno sa Google-om“. Za početak, odaberite „Započni besplatnu probnu verziju“ i nastavite sa sledećim korakom. Nalog se može kreirati ručno ili pomoću Google naloga.
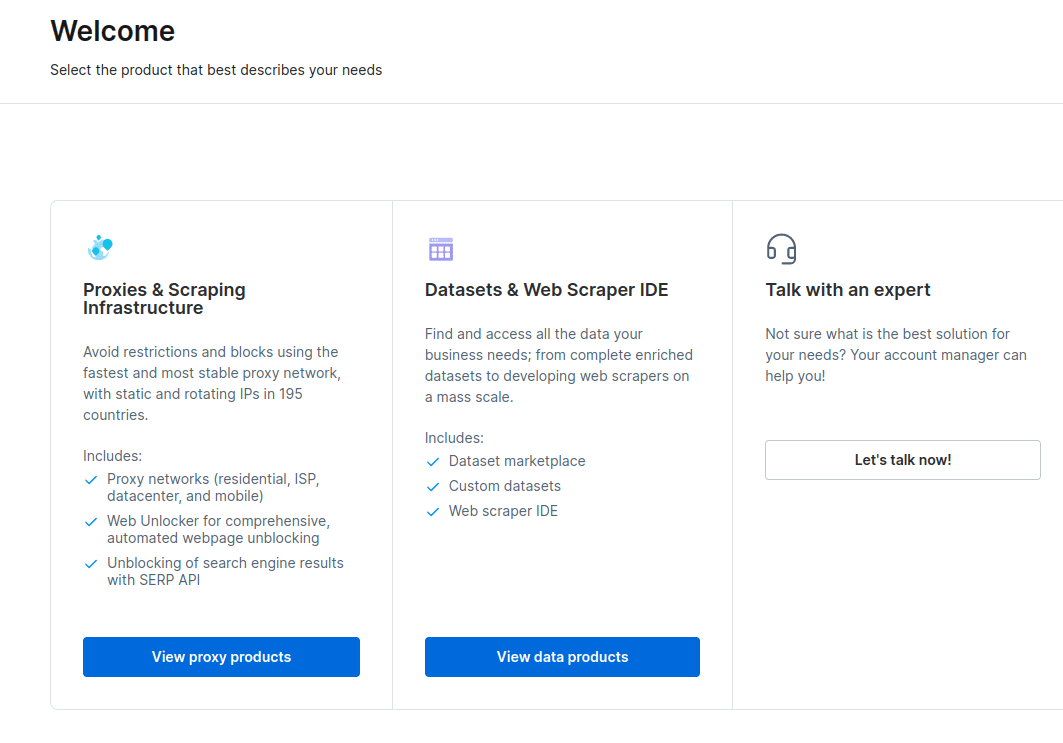
- Nakon kreiranja naloga, na kontrolnoj tabli se prikazuje nekoliko opcija. Odaberite „Proksi i infrastruktura za scraping“.
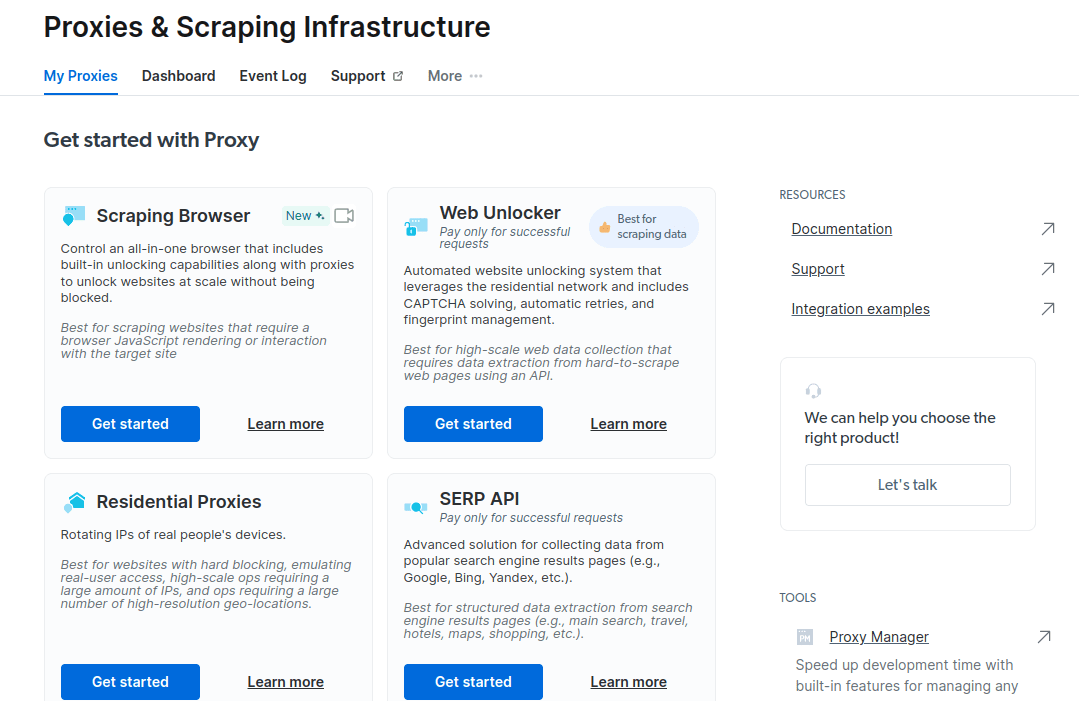
- U novom prozoru odaberite Scraping Browser i kliknite na „Započnite“.
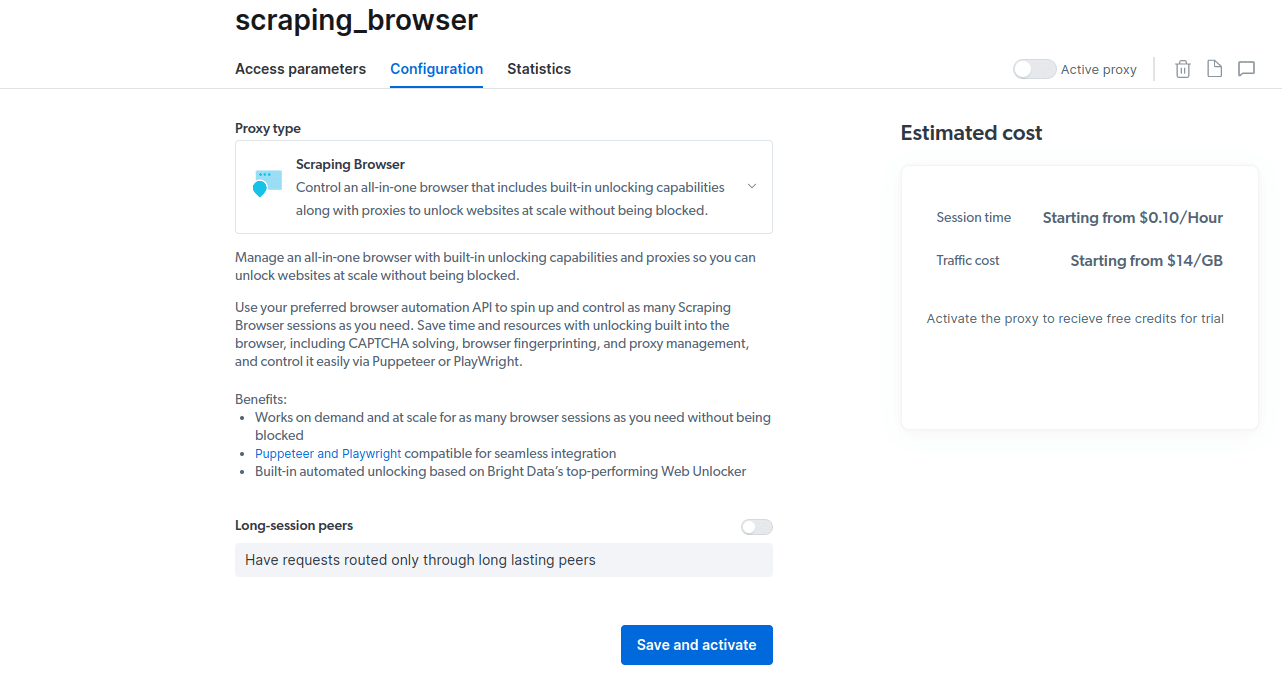
- Sačuvajte i aktivirajte konfiguracije.
- Aktivirajte besplatnu probnu verziju. Prva opcija daje 5 USD kredita za korišćenje proxy servera. Odaberite ovu opciju da isprobate proizvod. Ako ste veliki korisnik, druga opcija daje 50 USD besplatno ako dodate 50 USD ili više na nalog.
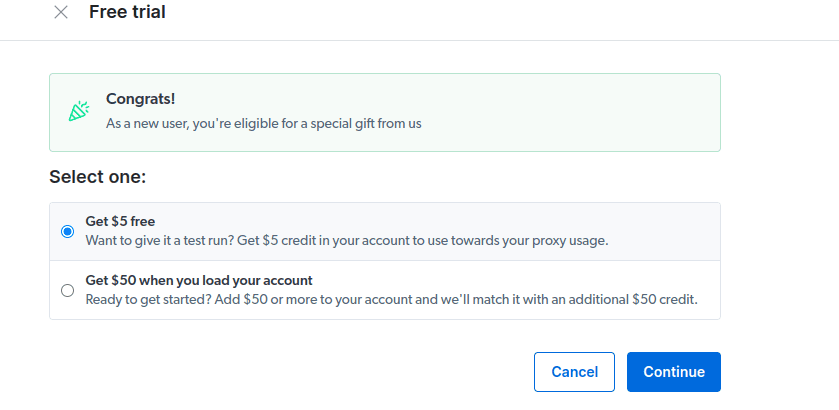
- Unesite podatke o plaćanju. Platforma neće naplatiti odmah. Ovi podaci služe za potvrdu da ste novi korisnik i sprečavaju zloupotrebu besplatnih probnih verzija putem višestrukih naloga.
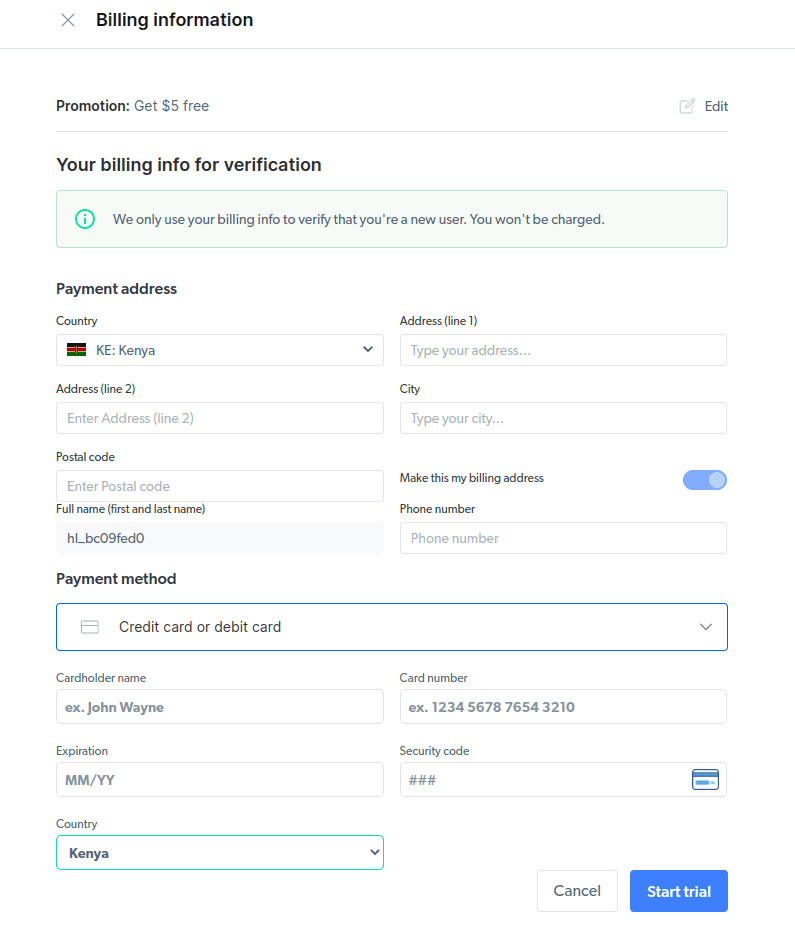
- Kreirajte novi proxy. Nakon unosa podataka o plaćanju, možete kreirati novi proxy. Kliknite na ikonicu „dodaj“ i odaberite Scraping Browser kao „Tip proxy-a“. Zatim kliknite na „Dodaj proxy” i nastavite sa daljim koracima.
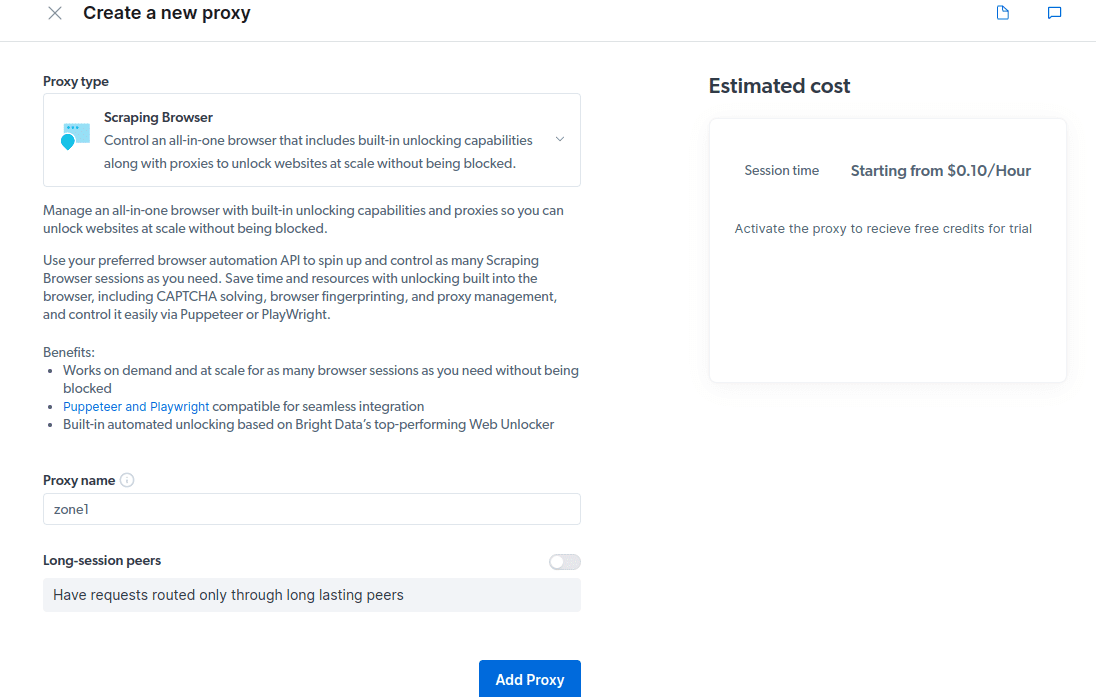
- Kreirajte novu „zonu“. Pojaviće se prozor sa pitanjem da li želite da kreirate novu zonu; kliknite na „Da“ i nastavite.
- Kliknite na „Proveri kod i primere integracije“. Dobićete primere integracije proxy servera koje možete koristiti za preuzimanje podataka sa ciljane veb stranice. Možete koristiti Node.js ili Python za izdvajanje podataka.
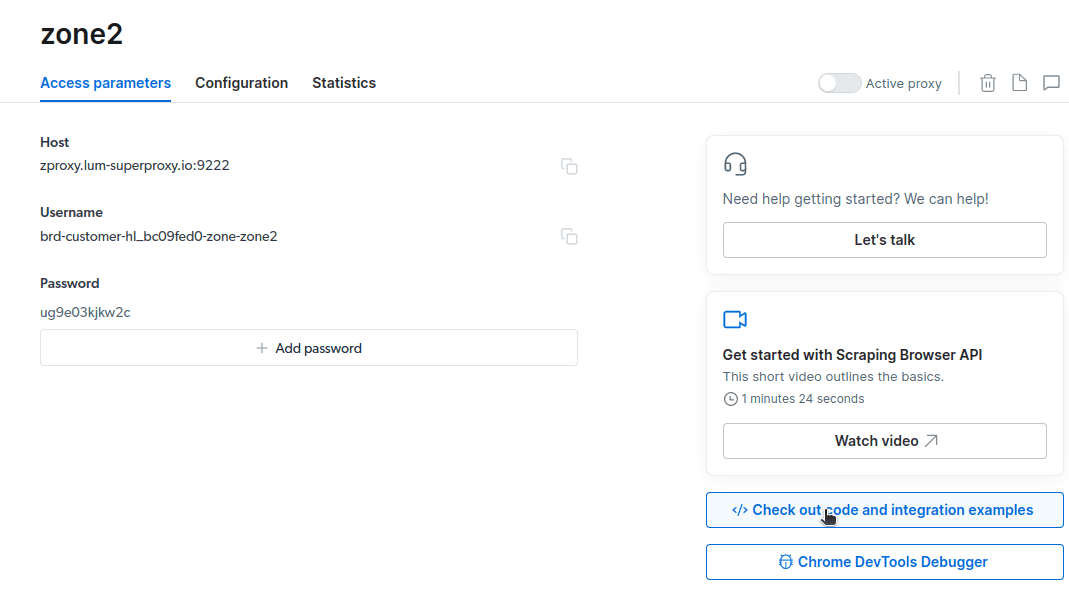
Sada imate sve što vam je potrebno za izdvajanje podataka sa veb stranice. Kao demonstraciju, koristićemo veb stranicu vdzvzd.com. U ovoj demonstraciji koristićemo node.js. Možete pratiti ove korake ako imate instaliran node.js.
Sledite ove korake:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Promenićemo kod u liniji 10 da bude sledeći:
await page.goto(‘https://vdzvzd.com/authors/‘);
Konačni kod sada izgleda ovako:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://techblog.co.rs.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
U terminalu će se pojaviti rezultat poput sledećeg:
Kako izvesti podatke
Postoji nekoliko načina za izvoz podataka, u zavisnosti od toga kako planirate da ih koristite. Danas ćemo izvesti podatke u HTML datoteku. Umesto da se rezultat štampa u konzoli, izmenićemo skriptu da kreira novu datoteku pod imenom data.html.
Promenite sadržaj koda na sledeći način:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://techblog.co.rs.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Sada možete pokrenuti kod pomoću naredbe:
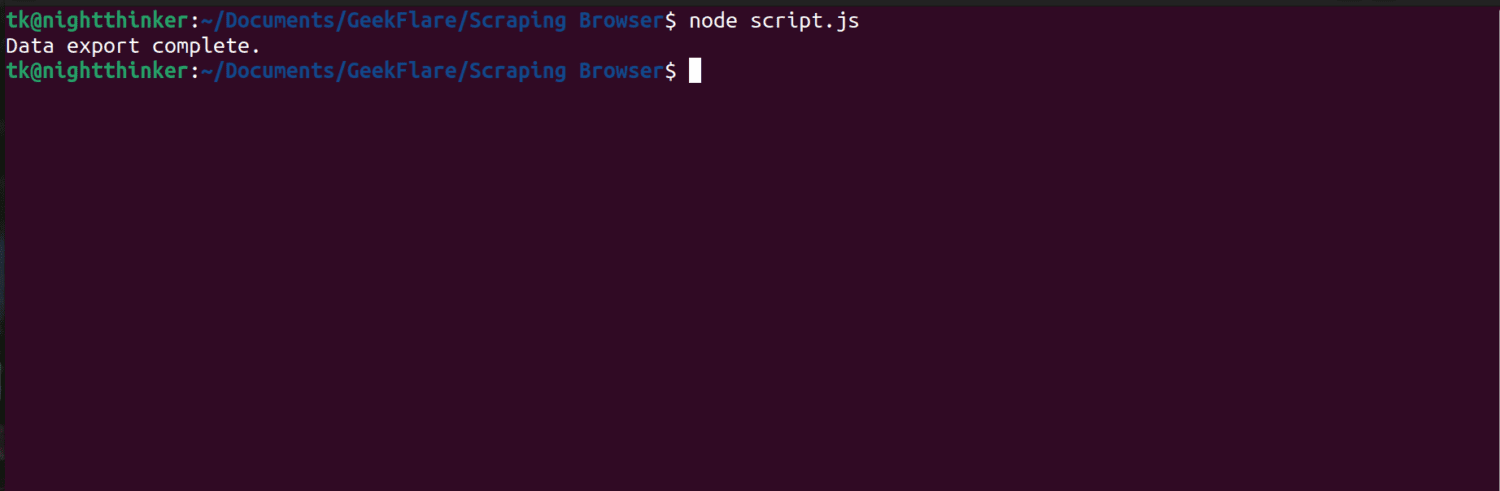
node script.js
Kao što možete videti na sledećoj slici, terminal prikazuje poruku „Izvoz podataka je završen“.
Ako pogledamo direktorijum projekta, sada možemo videti datoteku pod nazivom data.html sa hiljadama linija koda.
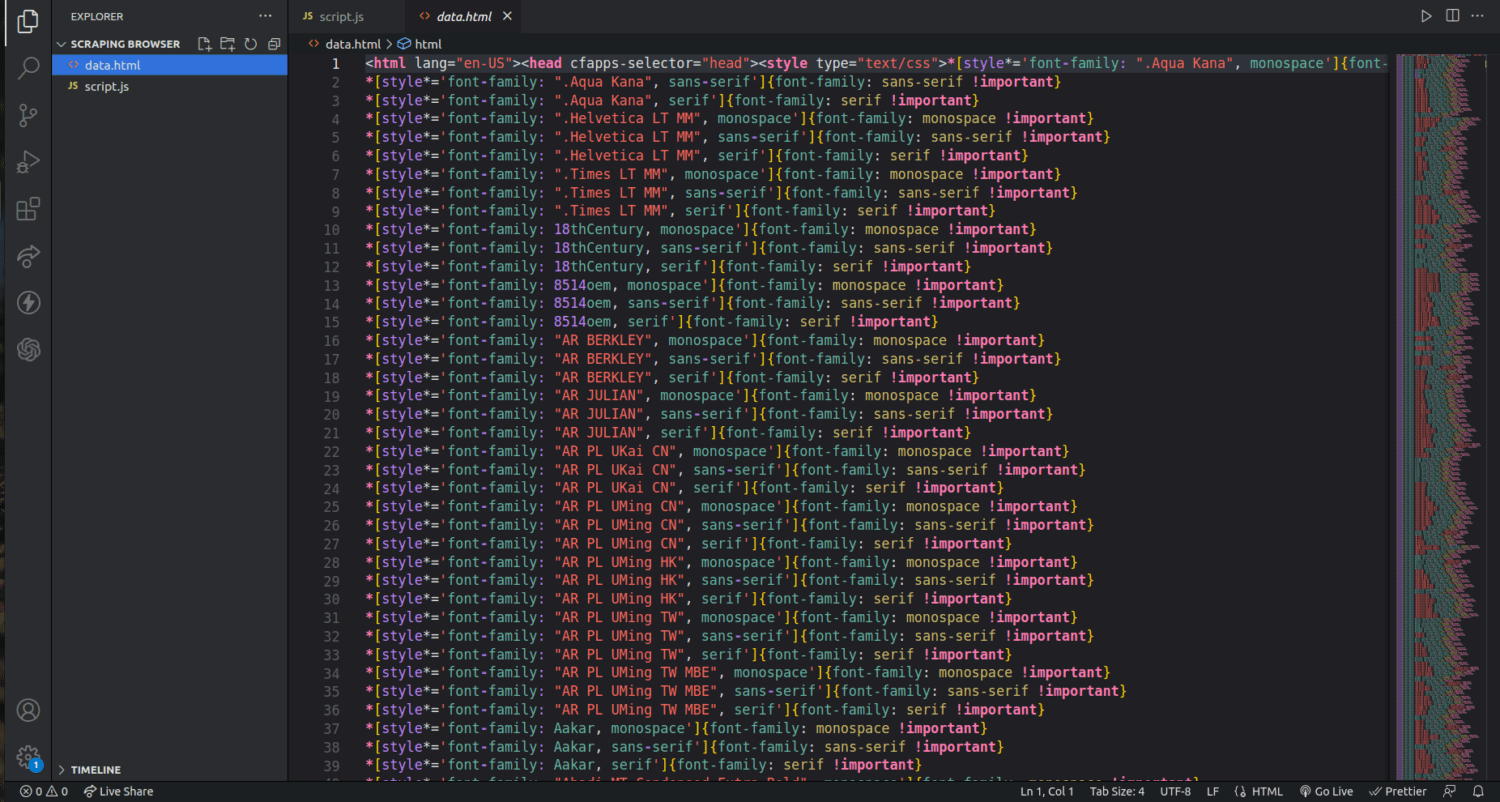
Ovo je osnovni prikaz kako se podaci izdvajaju pomoću Scraping Browser-a. Moguće je dodatno suziti izbor i izvući samo imena autora i njihove opise.
Ako planirate koristiti Scraping Browser, identifikujte skupove podataka koje želite izvući i prilagodite kod u skladu sa tim. Možete izdvajati tekst, slike, video materijale, metapodatke i linkove, zavisno od veb stranice koju ciljate i strukture HTML datoteke.
FAQ
Da li su ekstrakcija podataka i web scraping legalni?
Web scraping je kontroverzna tema. Neki smatraju da je neetičan, dok drugi misle da je prihvatljiv. Legalnost scraping-a zavisi od sadržaja koji se skuplja i politike ciljane veb stranice. Prikupljanje ličnih podataka, kao što su adrese i finansijski podaci, smatra se nezakonitim. Pre scraping-a, proverite da li veb stranica ima propisane smernice. Pazite da ne prikupljate podatke koji nisu javno dostupni.
Da li je Scraping Browser besplatan alat?
Ne. Scraping Browser je plaćena usluga. Besplatna probna verzija vam daje kredit od 5 USD. Plaćeni paketi startuju od 15 USD/GB + 0.1 USD/h. Takođe, možete odabrati opciju plaćanja po korišćenju, koja startuje od 20 USD/GB + 0.1 USD/h.
Koja je razlika između Scraping Browser-a i headless pretraživača?
Scraping Browser je pretraživač sa grafičkim korisničkim interfejsom (GUI). Sa druge strane, headless pretraživači nemaju grafički interfejs. Headless pretraživači, kao što je Selenium, koriste se za automatizaciju web scraping-a, ali mogu biti ograničeni pri rešavanju CAPTCHA i anti-bot mehanizama.
Zaključak
Scraping Browser pojednostavljuje proces izdvajanja podataka sa veb stranica. Jednostavan je za korišćenje u poređenju sa alatima kao što je Selenium. Čak i korisnici koji nisu programeri mogu ga koristiti zahvaljujući dobro dizajniranom korisničkom interfejsu i dokumentaciji. Alat ima napredne funkcije za otključavanje veb stranica, što ga čini efikasnim za automatizaciju ovih procesa.
Takođe, možete istražiti kako da sprečite da ChatGPT dodaci skraćuju sadržaj vaše veb stranice.