Употреба `grep` команде са регуларним изразима (Regex)
Ако сте већ неко време у свету Линукса, вероватно сте се сусрели са командом `grep`. `grep` (Global Regular Expression Print) је моћан алат за претрагу текста који вам омогућава да претражујете датотеке и директоријуме. Искусни Линукс корисници га сматрају незаменљивим, али његова пуна снага долази до изражаја када се користи са регуларним изразима.
Шта су заправо регуларни изрази (Regex)?
Регуларни изрази су напредни обрасци за филтрирање података, који проширују могућности `grep` претраге. Уз вежбу, можете савладати њихову употребу и применити их на разне Линукс команде.
У овом водичу ћемо детаљно објаснити како ефикасно користити `grep` у комбинацији са регуларним изразима.
Предуслови
Да бисте успешно користили `grep` са регуларним изразима, потребно је основно познавање Линукс система. Уколико сте почетник, препоручујемо да прво погледате наше уводне водиче за Линукс.
Такође, потребан вам је рачунар са инсталираним Линукс оперативним системом. Можете користити било коју дистрибуцију коју преферирате. Ако користите Windows, можете инсталирати WSL2 за покретање Линукса. Више детаља о томе можете пронаћи у нашем прегледу.
Приступ командној линији/терминалу је кључан за извршавање свих команди наведених у овом водичу.
Поред тога, требаће вам и текстуалне датотеке за тестирање примера. У овом случају, користили смо ChatGpt да генеришемо текст о технологији и сачували га у датотеци `tech.txt`. Упит је био следећи:
„Генериши текст од 400 речи о технологији. Текст треба да укључује већину технологија и да понавља њихова имена.“
На крају, важно је разумети основну функционалност `grep` команде. Можете погледати наше примере `grep` команди да бисте освежили своје знање, а ми ћемо укратко представити команду у наставку.
Синтакса и примери `grep` команде
Синтакса команде `grep` је прилично једноставна:
$ grep -options [regex/pattern] [files]
Као што видите, потребан јој је образац (pattern) и листа датотека у којима желите да претражујете.
Постоји мноштво `grep` опција које модификују његову функционалност. Најчешће коришћене укључују:
- `-i`: игнорисање величине слова
- `-r`: рекурзивна претрага
- `-w`: претрага само целих речи
- `-v`: приказивање линија које се не подударају
- `-n`: приказивање бројева линија
- `-l`: приказивање имена датотека
- `–color`: бојење резултата
- `-c`: приказивање броја пронађених подударања
#1. Претрага целих речи
За претрагу целих речи користите аргумент `-w` уз `grep`. Ово спречава да се пронађу низови који су део других речи.
$ grep -w 'tech\|5G' tech.txt
Ова команда ће пронаћи све појаве речи „5G“ и „tech“ у тексту и обележити их црвеном бојом. Симбол `|` (цев) је ескејпован да га `grep` не тумачи као метазнак.
#2. Претрага без обзира на величину слова
За претрагу без обзира на величину слова користите опцију `-i`.
$ grep -i 'tech' tech.txt
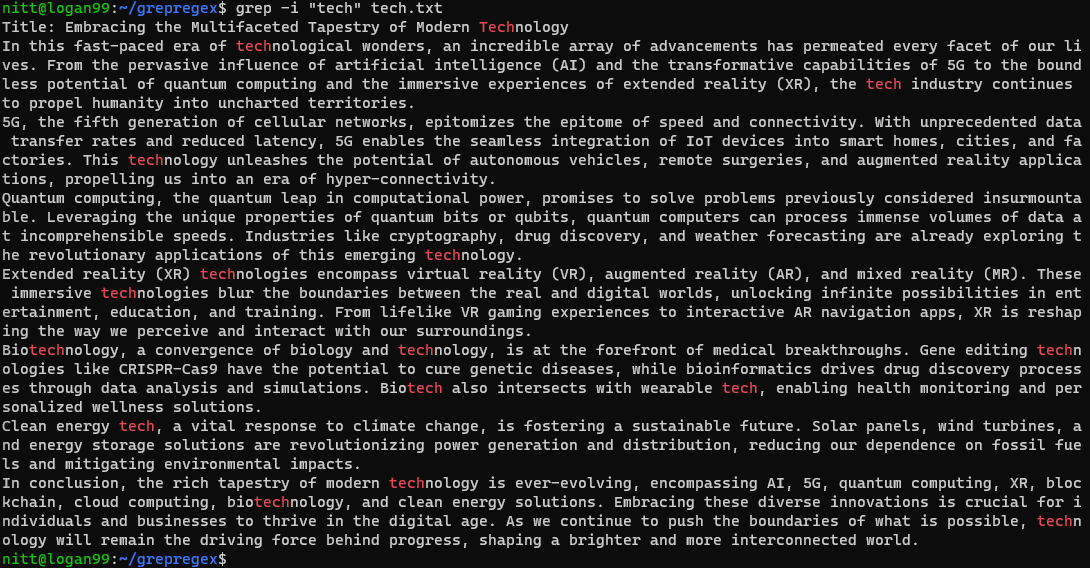
Команда ће пронаћи сва појављивања низа „tech“, без обзира на то да ли је написан великим или малим словима.
#3. Претрага линија које се не подударају
Да бисте приказали све линије које не садрже дати образац, користите аргумент `-v`.
$ grep -v 'tech' tech.txt

Излаз ће приказати све линије које не садрже реч „tech“, као и празне линије.
#4. Рекурзивна претрага
За рекурзивну претрагу, користите аргумент `-r` са `grep`.
$ grep -R 'error\|warning' /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
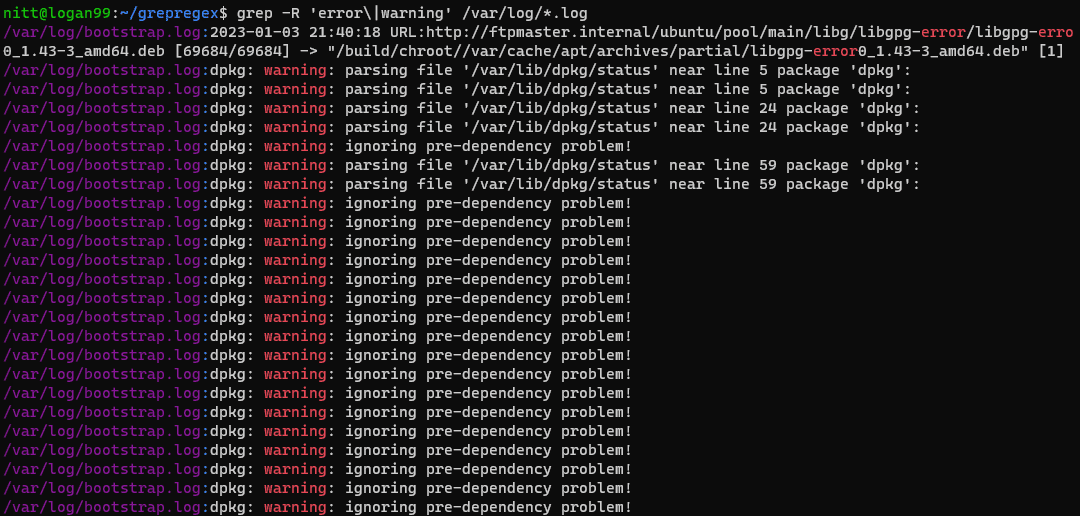
Ова команда ће рекурзивно претражити директоријум `/var/log` за речи „грешка“ и „упозорење“. Ово је посебно корисно за анализу log датотека.
`grep` и Regex: шта су и примери
Када говоримо о регуларним изразима, треба напоменути да постоје три опције синтаксе:
- Основни регуларни изрази (BRE)
- Проширени регуларни изрази (ERE)
- Перл компатибилни регуларни изрази (PCRE)
Команда `grep` подразумевано користи BRE. Да бисте користили друге режиме, морате их експлицитно навести. Такође, `grep` третира метакарактере онако како јесу, па их морате ескејповати са `\` (обрнутом косом цртом) ако их користите у регуларним изразима.
Синтакса `grep` са регуларним изразима је:
$ grep [regex] [filenames]
Погледајмо како `grep` и регуларни изрази функционишу у пракси са следећим примерима.
#1. Дословно подударање речи
За дословно подударање речи, наведите низ као регуларни израз, јер је реч сама по себи регуларни израз.
$ grep "technologies" tech.txt

Слично, можете тражити и тренутне кориснике:
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
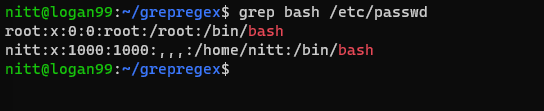
Ово приказује кориснике који могу приступити `bash` шкољки.
#2. Усклађивање сидра
Усклађивање сидра је корисна техника за напредне претраге. У регуларним изразима, постоје посебни знакови за представљање одређених позиција у тексту. Ови знакови укључују:
- `^`: Симбол за почетак реда/низа.
- `$`: Симбол за крај реда/низа.
Постоје и сидра за границу речи (`\b`) и границу која није реч (`\B`).
- `\b`: Потврђује позицију између речи и знака који није реч, омогућавајући вам да пронађете целе речи.
- `\B`: Супротно од `\b`, потврђује позицију која није између знакова речи или знакова који нису речи.
Погледајмо примере:
$ grep '^From' tech.txt

Коришћење симбола `^` захтева унос речи или обрасца са тачном великом и малом словима, јер се разликују велика и мала слова. Ако унесете следећу команду, неће се вратити ништа:
$ grep '^from' tech.txt
Слично, можете користити симбол `$` за проналажење реченице која одговара датом шаблону:
$ grep 'technology.$' tech.txt

Можете комбиновати и симболе `^` и `$`:
$ grep "^From \| technology.$" tech.txt
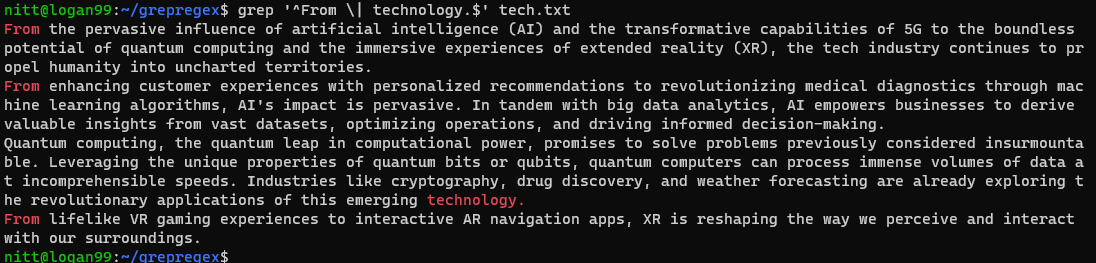
Излаз ће садржати реченице које почињу са „From“ и завршавају се са „technology“.
#3. Груписање
За претрагу више образаца истовремено, користите груписање. Омогућава вам креирање група знакова и образаца које можете третирати као једну целину. На пример, можете направити групу `(техника)` која укључује знакове ‘т’, ‘е’, ‘х’, ‘н’, ‘и’, ‘к’, ‘а’.
Погледајмо пример:
$ grep 'technol\(ogy\)\?' tech.txt

Груписањем можете упарити поновљене обрасце, хватати групе и тражити алтернативе.
Алтернативна претрага са груписањем
Пример алтернативне претраге:
$ grep "\(tech\|technology\)" tech.txt
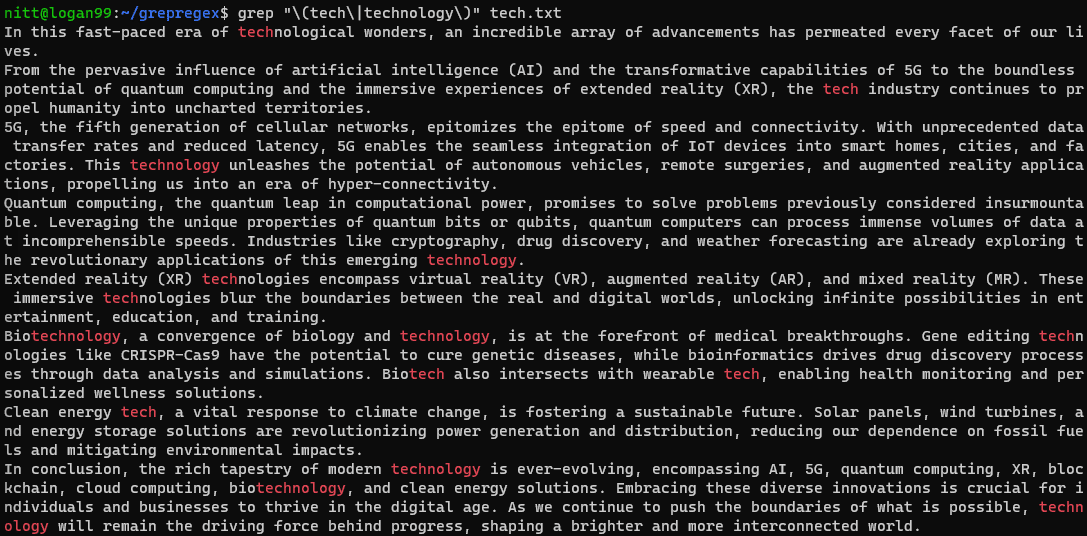
За претрагу низа, морате га проследити са симболом цеви:
$ echo "tech technological technologies technical" | grep "\(tech\|technology\)"
#output "tech technological technologies technical"

Снимање група, група без снимања и поновљени обрасци
Код снимања група, треба креирати групу у регуларном изразу и проследити је стрингу или датотеци:
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

За групе које не хватају, користите `?:` унутар заграда.
На крају, за поновљене обрасце, модификујте регуларни израз:
$ echo 'teach tech ttrial tttechno attest' | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Регуларни израз тражи једну или више инстанци знака `t`.
#4. Класе знакова
Класе знакова олакшавају писање регуларних израза. Користе се угласте заграде. Неке од познатих класа знакова:
- `[:digit:]` – цифре од 0 до 9
- `[:alpha:]` – абецедни знакови
- `[:alnum:]` – алфанумерички знакови
- `[:lower:]` – мала слова
- `[:upper:]` – велика слова
- `[:xdigit:]` – хексадецималне цифре (0-9, A-F, a-f)
- `[:blank:]` – празни знакови (таб, размак)
Погледајмо их на делу:
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
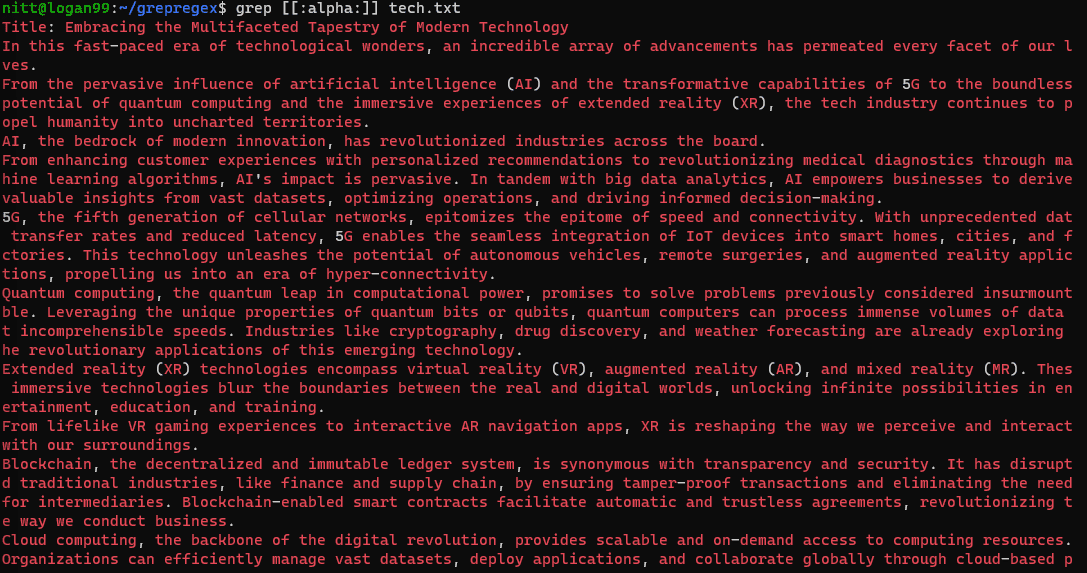
$ grep [[:xdigit:]] tech.txt
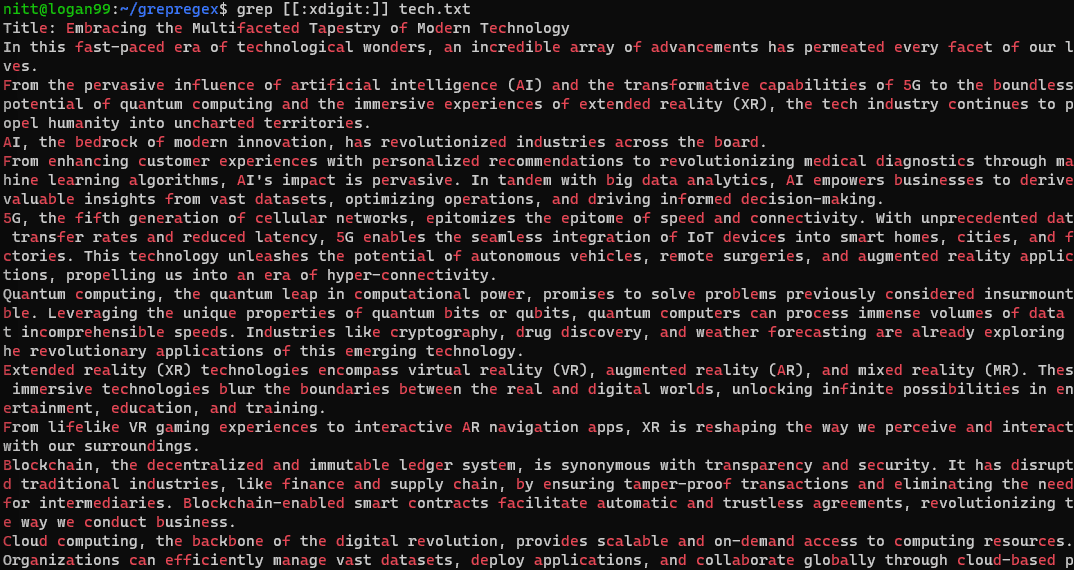
#5. Квантификатори
Квантификатори су метазнаци који вам омогућавају тачно подешавање претраге. Најчешће коришћени квантификатори:
- `*` → нула или више подударања
- `+` → једно или више подударања
- `?` → нула или једно подударање
- `{x}` → тачно `x` подударања
- `{x,}` → `x` или више подударања
- `{x,z}` → од `x` до `z` подударања
- `{,z}` → до `z` подударања
$ echo 'teach tech ttrial tttechno attest' | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Ова команда тражи једну или више инстанци знака ‘t’. Аргумент `-E` означава проширени регуларни израз (о коме ће бити више речи у наставку.)

#6. Проширени регуларни изрази
Ако желите да избегнете додавање ескејп знакова у образац регуларног израза, користите проширени регуларни израз, који елиминише потребу за ескејповањем. Користите ознаку `-E`:
$ grep -E 'in+ovation' tech.txt

#7. Коришћење PCRE за сложене претраге
PCRE (Perl Compatible Regular Expression) омогућава више од писања основних израза. На пример, можете користити `\d` да представљате `[0-9]`.
PCRE је користан за тражење адреса е-поште:
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

PCRE обезбеђује да се образац подудара. Такође, може се користити за проверу постојања шаблона датума:
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Ова команда проналази датум у формату `ГГГГ-ММ-ДД`, али се може модификовати за друге формате.
#8. Алтернација
За алтернативна подударања, користите ескејповане знакове `\|`:
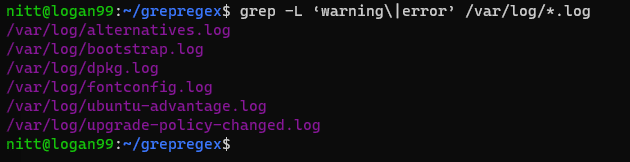
$ grep -L 'warning\|error' /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Излаз наводи имена датотека које садрже „упозорење“ или „грешку“.
Закључне речи
Овим се завршава наш водич о употреби `grep` и регуларних израза. Комбиновање ових алата вам омогућава прецизније претраге. Правилном употребом, можете уштедети време и аутоматизовати многе задатке, нарочито при писању скрипти и обради текста.
Затим погледајте често постављана питања о Линук-у и припремите се за интервју.