

Можете извући текст из слика на Линук командној линији користећи Тессерацт ОЦР мотор. Брз је, прецизан и ради на око 100 језика. Ево како да га користите.
Преглед садржаја
Оптичко препознавање знакова
Оптичко препознавање знакова (ОЦР) је способност да се погледају и пронађу речи на слици, а затим да се издвоје као текст који се може уређивати. Овај једноставан задатак за људе је веома тежак за рачунаре. Рани напори су били незграпни, у најмању руку. Рачунари су често били збуњени ако фонт или величина нису били по вољи ОЦР софтвера.
Ипак, пионири у овој области су и даље били веома цењени. Ако сте изгубили електронску копију документа, али сте и даље имали штампану верзију, ОЦР би могао поново да креира електронску верзију која се може уређивати. Чак и ако резултати нису били 100 посто тачни, ово је ипак била одлична уштеда времена.
Уз мало ручног сређивања, вратили бисте свој документ. Људи су праштали због грешака које је направио јер су разумели сложеност задатка са којим се суочава ОЦР пакет. Осим тога, било је боље него да прекуцате цео документ.
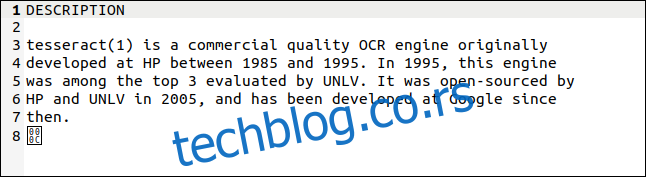
Ствари су се од тада значајно побољшале. Тессерацт ОЦР апликација, аутор Хевлетт Пацкард, започета 1980-их као комерцијална примена. Био је отвореног кода 2005. године, а сада га подржавају Гоогле. Има вишејезичне могућности, сматра се једним од најпрецизнијих доступних ОЦР система и можете га користити бесплатно.
Инсталирање Тессерацт ОЦР
Да бисте инсталирали Тессерацт ОЦР на Убунту, користите ову команду:
sudo apt-get install tesseract-ocr

На Федори, команда је:
sudo dnf install tesseract

На Мањаро, потребно је да откуцате:
sudo pacman -Syu tesseract

Коришћење Тессерацт ОЦР
Поставићемо низ изазова за Тессерацт ОЦР. Наша прва слика која садржи текст је извод из уводне изјаве 63 Општи прописи о заштити података. Хајде да видимо да ли ОЦР може ово да прочита (и да остане будан).

То је зезнута слика јер свака реченица почиње слабим наднаредним бројем, што је типично у законодавним документима.
Морамо да дамо команди тесеракта неке информације, укључујући:
Име датотеке слике коју желимо да обради.
Име текстуалне датотеке коју ће креирати да задржи екстраховани текст. Не морамо да обезбедимо екстензију датотеке (увек ће бити .ткт). Ако већ постоји датотека са истим именом, биће замењена.
Можемо користити опцију –дпи да кажемо тесеракту шта је тачака по инчу (дпи) резолуција слике је. Ако не дамо вредност дпи, тесерацт ће покушати да је схвати.
Наша датотека слике се зове „рецитал-63.пнг“, а њена резолуција је 150 дпи. Направићемо текстуалну датотеку од ње под називом „рецитал.ткт“.
Наша команда изгледа овако:
tesseract recital-63.png recital --dpi 150

Резултати су веома добри. Једини проблем су суперскрипти — били су сувише бледи да би се могли исправно прочитати. Квалитетна слика је од виталног значаја за постизање добрих резултата.

тессерацт је протумачио бројеве изнад индекса као наводнике (“) и симболе степена (°), али је стварни текст извучен савршено (десна страна слике је морала бити исечена да би стала овде).
Коначни знак је бајт са хексадецималном вредношћу 0к0Ц, што је повратни знак.
Испод је још једна слика са текстом у различитим величинама, и подебљаним и курзивом.

Назив ове датотеке је „болд-италиц.пнг“. Желимо да креирамо текстуалну датотеку под називом „болд.ткт“, тако да је наша команда:
tesseract bold-italic.png bold --dpi 150

Овај није представљао никакав проблем, а текст је извучен савршено.
Коришћење различитих језика
Тессерацт ОЦР подржава око 100 језика. Да бисте користили језик, прво га морате инсталирати. Када на листи пронађете језик који желите да користите, обратите пажњу на његову скраћеницу. Инсталираћемо подршку за велшки језик. Његова скраћеница је „цим“, што је скраћеница од „Цимру“, што значи велшки.
Инсталациони пакет се зове „тессерацт-оцр-“ са скраћеницом језика означеном на крају. Да бисмо инсталирали датотеку велшког језика у Убунту, користићемо:
sudo apt-get install tesseract-ocr-cym

Слика са текстом је испод. То је први стих велшке химне.

Хајде да видимо да ли је Тессерацт ОЦР дорастао изазову. Користићемо опцију -л (језик) да тесеракту омогућимо да зна језик на којем желимо да радимо:
tesseract hen-wlad-fy-nhadau.png anthem -l cym --dpi 150

тессерацт се савршено сналази, као што је приказано у извученом тексту испод. Да Иавн, Тессерацт ОЦР.

Ако ваш документ садржи два или више језика (као што је речник велшко-енглеског, на пример), можете да користите знак плус (+) да кажете тесеракту да дода још један језик, на пример:
tesseract image.png textfile -l eng+cym+fra
Коришћење Тессерацт ОЦР-а са ПДФ-овима
Команда тесерацт је дизајнирана да ради са датотекама слика, али не може да чита ПДФ-ове. Међутим, ако треба да издвојите текст из ПДФ-а, можете прво користити други услужни програм да бисте генерисали скуп слика. Једна слика ће представљати једну страницу ПДФ-а.
пдфтппм услужни програм који вам је потребан већ треба да буде инсталиран на вашем Линук рачунару. ПДФ који ћемо користити за наш пример је копија основног рада Алана Туринга о вештачкој интелигенцији, „Рачунарска машина и интелигенција“.

Користимо опцију -пнг да наведемо да желимо да креирамо ПНГ датотеке. Назив датотеке нашег ПДФ-а је „туринг.пдф“. Наше датотеке слика ћемо звати „туринг-01.пнг“, „туринг-02.пнг“ и тако даље:
pdftoppm -png turing.pdf turing

Да бисмо покренули тесерацт на свакој датотеци слике помоћу једне команде, морамо да користимо а за петљу. За сваку нашу датотеку „туринг-нн.пнг“ покрећемо тесерацт и креирамо текстуалну датотеку под називом „тект-“ плус „туринг-нн“ као део назива датотеке слике:
for i in turing-??.png; do tesseract "$i" "text-$i" -l eng; done;

Да комбинујемо све текстуалне датотеке у једну, можемо користити цат:
cat text-turing* > complete.txt

Вертикални водени жиг је транскрибован као ред бесмислица на дну странице. Текст је био сувише мали да би га тесерак тачно прочитао, али би га било довољно лако пронаћи и избрисати. Најгори резултат би били залутали знакови на крају сваког реда.
Занимљиво је да су појединачна слова на почетку листе питања и одговора на другој страни занемарена. Одељак из ПДФ-а је приказан испод.

Као што можете видети у наставку, питања остају, али „К“ и „А“ на почетку сваког реда су изгубљени.

Дијаграми такође неће бити исправно транскрибовани. Хајде да погледамо шта се дешава када покушамо да издвојимо доле приказану из Туринг ПДФ-а.

Као што можете видети у нашем резултату испод, знакови су прочитани, али је формат дијаграма изгубљен.

Опет, тесеракт се борио са малом величином индекса, и они су погрешно приказани.
Искрено речено, то је ипак био добар резултат. Нисмо били у могућности да издвојимо једноставан текст, али је овај пример намерно изабран јер је представљао изазов.
Добро решење када вам затреба
ОЦР није нешто што ћете морати да користите свакодневно. Међутим, када се укаже потреба, добро је знати да имате један од најбољих ОЦР мотора на располагању.