
Подаци су неизоставан део предузећа и организација и вредни су само када су правилно структурисани и када се њима ефикасно управља.
Према статистичким подацима, 95% предузећа данас сматра да је управљање и структурирање неструктурираних података проблем.
Овде на сцену ступа рударење података. То је процес откривања, анализе и издвајања смислених образаца и вредних информација из великих скупова неструктурираних података.
Компаније користе софтвер да идентификују обрасце у великим серијама података како би сазнале више о својим клијентима и циљној публици и развиле пословне и маркетиншке стратегије за побољшање продаје и смањење трошкова.
Поред ове предности, откривање превара и аномалија су најважније апликације рударења података.
Овај чланак објашњава откривање аномалија и даље истражује како може помоћи у спречавању кршења података и упада у мрежу како би се осигурала сигурност података.
Преглед садржаја
Шта је детекција аномалија и њени типови?
Док рударење података укључује проналажење образаца, корелација и трендова који се међусобно повезују, то је одличан начин за проналажење аномалија или ванредних тачака података унутар мреже.
Аномалије у рударењу података су тачке података које се разликују од других тачака података у скупу података и одступају од нормалног обрасца понашања скупа података.
Аномалије се могу класификовати у различите типове и категорије, укључујући:
- Промене у догађајима: Односи се на изненадне или систематске промене у односу на претходно нормално понашање.
- Оутлиерс: Мали аномални обрасци који се појављују на несистематски начин у прикупљању података. Они се даље могу класификовати у глобалне, контекстуалне и колективне одлике.
- Помаци: Постепена, неусмерена и дугорочна промена у скупу података.
Дакле, откривање аномалија је техника обраде података која је веома корисна за откривање лажних трансакција, руковање студијама случаја са висококласном неравнотежом и откривање болести за изградњу робусних модела науке о подацима.
На пример, компанија ће можда желети да анализира свој новчани ток како би пронашла ненормалне или понављајуће трансакције на непознатом банковном рачуну како би открила превару и спровела даљу истрагу.
Предности откривања аномалија
Откривање аномалија понашања корисника помаже у јачању безбедносних система и чини их прецизнијим и прецизнијим.
Он анализира и даје смисао разним информацијама које безбедносни системи обезбеђују да би се идентификовале претње и потенцијални ризици унутар мреже.
Ево предности откривања аномалија за компаније:
- Откривање претњи сајбер безбедности и кршења података у реалном времену док његови алгоритми вештачке интелигенције (АИ) непрестано скенирају ваше податке да би пронашли необично понашање.
- То чини праћење аномалних активности и образаца бржим и лакшим од ручног откривања аномалија, смањујући рад и време потребно за решавање претњи.
- Минимизира оперативне ризике тако што идентификује оперативне грешке, као што су изненадни падови перформанси, пре него што се појаве.
- Помаже у отклањању великих пословних штета брзим откривањем аномалија, јер без система за откривање аномалија, компанијама могу бити потребне недеље и месеци да идентификују потенцијалне претње.
Дакле, откривање аномалија је огромна предност за предузећа која чувају обимне скупове података о клијентима и пословним подацима како би пронашла прилике за раст и елиминисала безбедносне претње и оперативна уска грла.
Технике детекције аномалија
Откривање аномалија користи неколико процедура и алгоритама машинског учења (МЛ) за надгледање података и откривање претњи.
Ево главних техника откривања аномалија:
#1. Технике машинског учења

Технике машинског учења користе МЛ алгоритме за анализу података и откривање аномалија. Различити типови алгоритама машинског учења за откривање аномалија укључују:
- Алгоритми груписања
- Алгоритми класификације
- Алгоритми дубоког учења
А најчешће коришћене МЛ технике за откривање аномалија и претњи укључују машине за подршку векторима (СВМ), к-меанс кластерисање и аутоенкодере.
#2. Статистичке технике
Статистичке технике користе статистичке моделе за откривање необичних образаца (као што су необичне флуктуације у перформансама одређене машине) у подацима да би се откриле вредности које су изван опсега очекиваних вредности.
Уобичајене технике за откривање статистичких аномалија укључују тестирање хипотезе, ИКР, З-сцоре, модификовани З-скор, процену густине, бокплот, анализу екстремних вредности и хистограм.
#3. Дата Мининг Тецхникуес

Технике рударења података користе технике класификације података и груписања за проналажење аномалија унутар скупа података. Неке уобичајене технике аномалија рударења података укључују спектрално груписање, кластерисање засновано на густини и анализу главних компоненти.
Алгоритми за прикупљање података кластером се користе за груписање различитих тачака података у кластере на основу њихове сличности за проналажење тачака података и аномалија које спадају ван ових кластера.
С друге стране, класификациони алгоритми додељују тачке података одређеним унапред дефинисаним класама и откривају тачке података које не припадају овим класама.
#4. Технике засноване на правилима
Као што име сугерише, технике детекције аномалија засноване на правилима користе скуп унапред одређених правила за проналажење аномалија унутар података.
Ове технике су релативно лакше и једноставније за постављање, али могу бити нефлексибилне и можда неће бити ефикасне у прилагођавању променљивом понашању података и обрасцима.
На пример, можете лако програмирати систем заснован на правилима да означи трансакције које премашују одређени износ у доларима као лажне.
#5. Технике специфичне за домен
Можете користити технике специфичне за домен да бисте открили аномалије у одређеним системима података. Међутим, иако могу бити високо ефикасни у откривању аномалија у одређеним доменима, могу бити мање ефикасни у другим доменима изван наведеног.
На пример, користећи технике специфичне за домен, можете дизајнирати технике посебно за проналажење аномалија у финансијским трансакцијама. Али, можда неће радити за проналажење аномалија или падова перформанси у машини.
Потреба за машинским учењем за откривање аномалија
Машинско учење је веома важно и веома корисно у откривању аномалија.
Данас, већина компанија и организација које захтевају откривање изванредних вредности баве се огромним количинама података, од текста, информација о клијентима и трансакција до медијских датотека попут слика и видео садржаја.
Пролазак кроз све банковне трансакције и податке који се генеришу сваке секунде ручно како би се добио смислен увид је скоро немогуће. Штавише, већина компанија се суочава са изазовима и великим потешкоћама у структурирању неструктурираних података и уређењу података на смислен начин за анализу података.
Овде алати и технике попут машинског учења (МЛ) играју огромну улогу у прикупљању, чишћењу, структурирању, уређењу, анализи и складиштењу огромних количина неструктурираних података.
Технике и алгоритми машинског учења обрађују велике скупове података и пружају флексибилност за коришћење и комбиновање различитих техника и алгоритама како би се обезбедили најбољи резултати.
Осим тога, машинско учење такође помаже да се поједноставе процеси откривања аномалија за апликације у стварном свету и штеди вредне ресурсе.
Ево још неких предности и важности машинског учења у откривању аномалија:
- Олакшава откривање аномалија у скалирању тако што аутоматизује идентификацију образаца и аномалија без потребе за експлицитним програмирањем.
- Алгоритми машинског учења су веома прилагодљиви променама образаца скупова података, што их чини веома ефикасним и робусним током времена.
- Лако рукује великим и сложеним скуповима података, чинећи откривање аномалија ефикасним упркос сложености скупа података.
- Осигурава рану идентификацију и откривање аномалија тако што идентификује аномалије како се дешавају, штедећи време и ресурсе.
- Системи за откривање аномалија засновани на машинском учењу помажу у постизању виших нивоа тачности у откривању аномалија у поређењу са традиционалним методама.
Дакле, откривање аномалија упарено са машинским учењем помаже бржем и ранијем откривању аномалија како би се спречиле безбедносне претње и злонамерна кршења.
Алгоритми машинског учења за откривање аномалија
Можете открити аномалије и одступања у подацима уз помоћ различитих алгоритама рударења података за класификацију, груписање или учење правила асоцијације.
Обично су ови алгоритми за рударење података класификовани у две различите категорије — алгоритми учења под надзором и алгоритми учења без надзора.
Учење под надзором
Надзирано учење је уобичајен тип алгоритма учења који се састоји од алгоритама као што су машине за подршку векторима, логистичка и линеарна регресија и класификација у више класа. Овај тип алгоритма се обучава на означеним подацима, што значи да његов скуп података за обуку укључује и нормалне улазне податке и одговарајуће исправне излазне или аномалне примере за конструисање предиктивног модела.
Дакле, његов циљ је да направи предвиђања излаза за невидљиве и нове податке на основу образаца скупа података за обуку. Примене алгоритама за учење под надзором укључују препознавање слике и говора, предиктивно моделирање и обраду природног језика (НЛП).
Учење без надзора
Учење без надзора се не обучава ни на једном означеном податку. Уместо тога, открива компликоване процесе и основне структуре података без пружања упутства за алгоритам обуке и уместо да прави одређена предвиђања.
Примене алгоритама учења без надзора укључују откривање аномалија, процену густине и компресију података.
Сада, хајде да истражимо неке популарне алгоритме за откривање аномалија заснованих на машинском учењу.
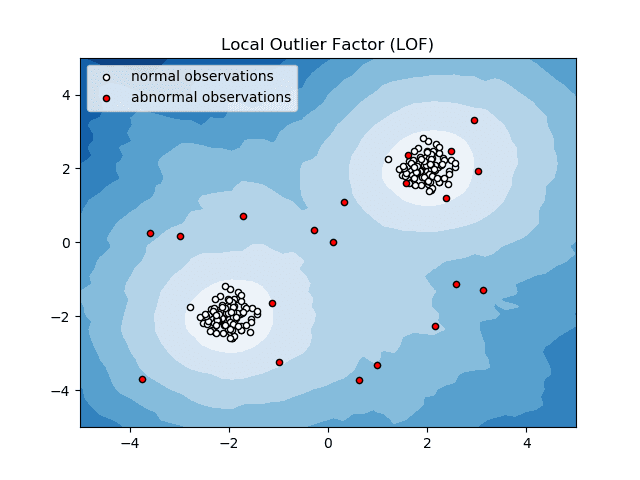
Локални фактор одступања (ЛОФ)
Фактор локалног одступања или ЛОФ је алгоритам за откривање аномалија који узима у обзир густину локалних података да би утврдио да ли је тачка података аномалија.
 Извор: сцикит-леарн.орг
Извор: сцикит-леарн.орг
Он упоређује локалну густину предмета са локалним густинама његових суседа да би анализирао области сличне густине и ставке са релативно нижим густинама од њихових суседа — које нису ништа друго до аномалије или одступања.
Дакле, једноставним речима, густина која окружује изванредну или аномалну ставку разликује се од густине око њених суседа. Стога се овај алгоритам назива и алгоритам за детекцију оутлиер-а заснован на густини.
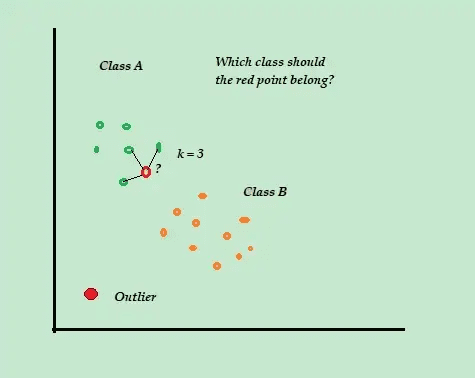
К-најближи сусед (К-НН)
К-НН је најједноставнији алгоритам за класификацију и надгледано откривање аномалија који је једноставан за имплементацију, чува све доступне примере и податке и класификује нове примере на основу сличности у метрици удаљености.
 Извор: тодатасциенце.цом
Извор: тодатасциенце.цом
Овај класификациони алгоритам се такође назива лењи ученик јер чува само означене податке о обуци — не ради ништа друго током процеса обуке.
Када стигне нова неозначена тачка података за обуку, алгоритам гледа у К-најближе или најближе тачке података за обуку да би их користио за класификацију и одређивање класе нове необележене тачке података.
К-НН алгоритам користи следеће методе детекције да одреди најближе тачке података:
- Еуклидско растојање за мерење удаљености за континуиране податке.
- Хемингова удаљеност за мерење близине или „близине“ два текстуална низа за дискретне податке.
На пример, узмите у обзир да се ваши скупови података за обуку састоје од две ознаке класе, А и Б. Ако стигне нова тачка података, алгоритам ће израчунати растојање између нове тачке података и сваке од тачака података у скупу података и изабрати тачке који су максималног броја најближи новој тачки података.
Дакле, претпоставимо да је К=3 и 2 од 3 тачке података су означене као А, онда је нова тачка података означена као класа А.
Стога, К-НН алгоритам најбоље функционише у динамичким окружењима са честим захтевима за ажурирање података.
То је популаран алгоритам за откривање аномалија и рударење текста са апликацијама у финансијама и предузећима за откривање лажних трансакција и повећање стопе откривања превара.
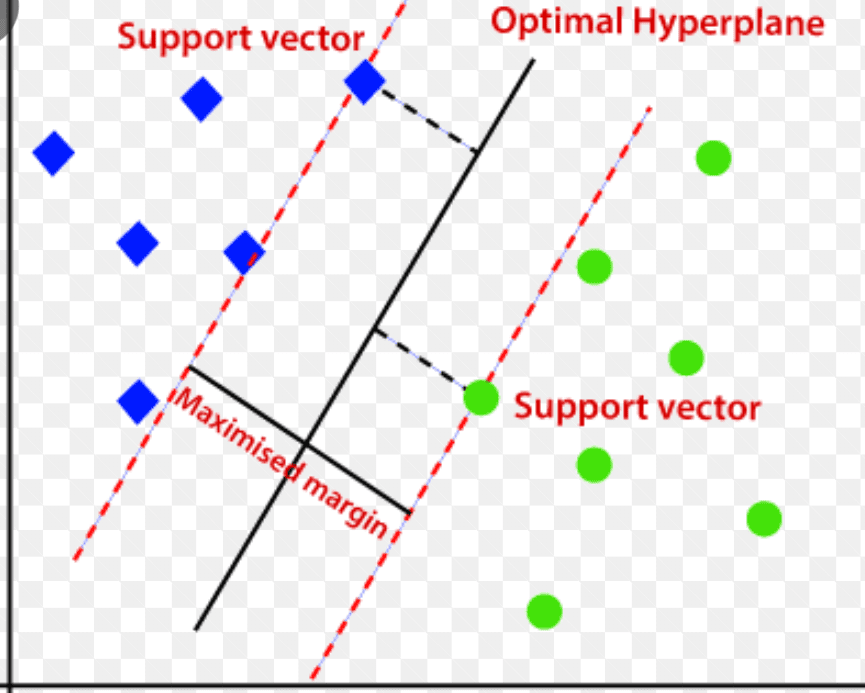
Машина за векторску подршку (СВМ)
Машина вектора подршке је надзирани алгоритам за откривање аномалија заснован на машинском учењу који се углавном користи у проблемима регресије и класификације.
Користи вишедимензионалну хиперравнину за раздвајање података у две групе (нове и нормалне). Дакле, хиперраван делује као граница одлуке која раздваја нормална посматрања података и нове податке.
 Извор: ввв.аналитицсвидхиа.цом
Извор: ввв.аналитицсвидхиа.цом
Удаљеност између ове две тачке података се назива маргинама.
Пошто је циљ да се повећа растојање између две тачке, СВМ одређује најбољу или оптималну хиперравнину са максималном маргином како би се обезбедило што веће растојање између две класе.
Што се тиче откривања аномалија, СВМ израчунава маргину посматрања нове тачке података са хиперравне да би је класификовао.
Ако маргина премашује постављени праг, она класификује ново запажање као аномалију. Истовремено, ако је маргина мања од прага, посматрање се класификује као нормално.
Дакле, СВМ алгоритми су веома ефикасни у руковању високодимензионалним и сложеним скуповима података.
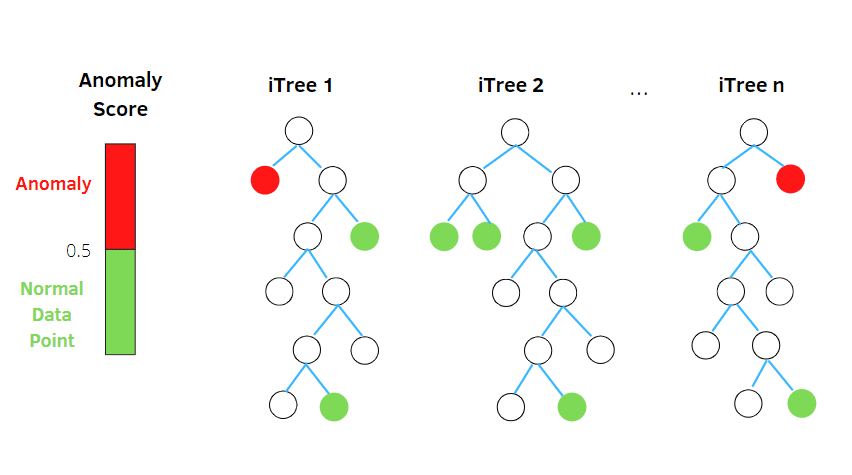
Исолатион Форест
Исолатион Форест је алгоритам за откривање аномалија без надзора машинског учења заснован на концепту класификатора случајних шума.
 Извор: беттерпрограмминг.пуб
Извор: беттерпрограмминг.пуб
Овај алгоритам обрађује насумично подузорковане податке у скупу података у структури стабла на основу случајних атрибута. Конструише неколико стабала одлучивања да изолује посматрања. И сматра одређено запажање аномалијом ако је изоловано у мањем броју стабала на основу стопе контаминације.
Дакле, једноставним речима, алгоритам изолационе шуме дели тачке података у различита стабла одлучивања – обезбеђујући да свако посматрање буде изоловано од другог.
Аномалије обично леже даље од кластера тачака података – што олакшава идентификацију аномалија у поређењу са нормалним тачкама података.
Алгоритми изолационе шуме могу лако да рукују категоричким и нумеричким подацима. Као резултат тога, они су бржи за обуку и веома ефикасни у откривању аномалија у високодимензионалним и великим скуповима података.
Интеркуартиле опсег
Интерквартилни опсег или ИКР се користи за мерење статистичке варијабилности или статистичке дисперзије да би се пронашле аномалне тачке у скуповима података тако што ће се поделити на квартиле.
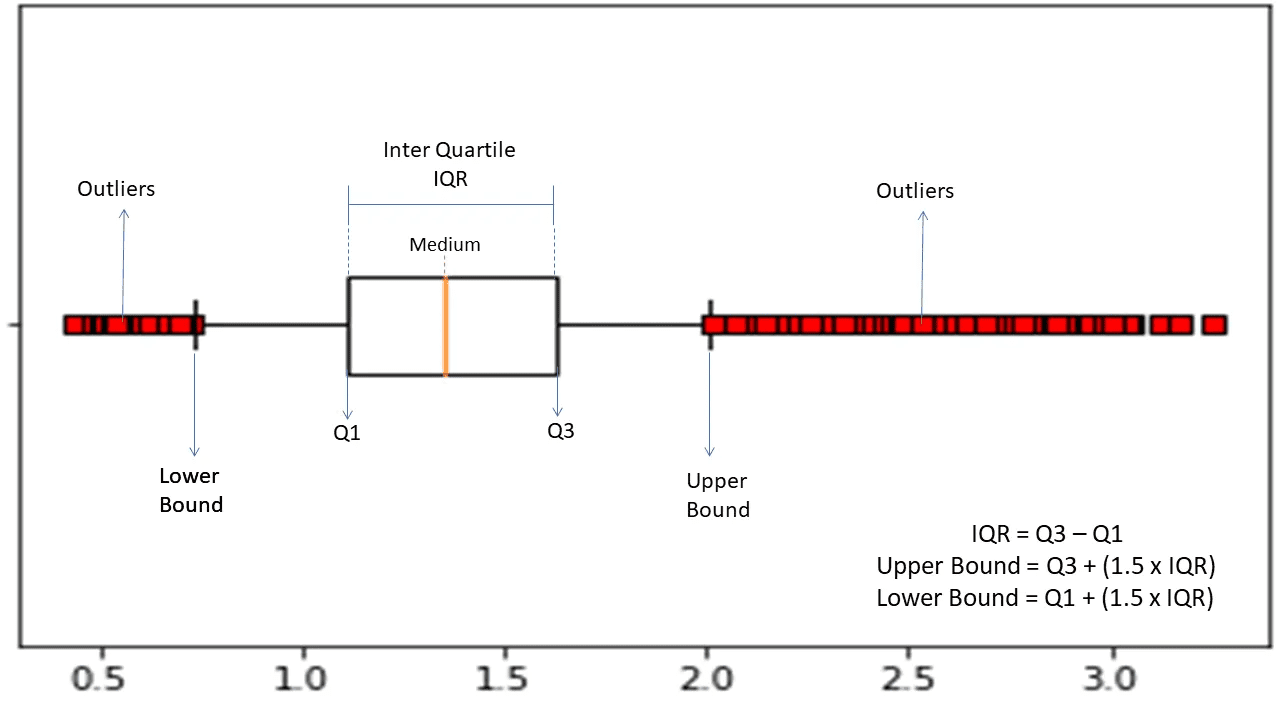 Извор: мориох.цом
Извор: мориох.цом
Алгоритам сортира податке у растућем редоследу и дели скуп на четири једнака дела. Вредности које раздвајају ове делове су К1, К2 и К3—први, други и трећи квартил.
Ево процентуалне дистрибуције ових квартила:
- К1 означава 25. перцентил података.
- К2 означава 50. перцентил података.
- К3 означава 75. перцентил података.
ИКР је разлика између трећег (75.) и првог (25.) скупова података перцентила, која представља 50% података.
Коришћење ИКР-а за откривање аномалија захтева од вас да израчунате ИКР вашег скупа података и дефинишете доњу и горњу границу података да бисте пронашли аномалије.
- Доња граница: К1 – 1,5 * ИКР
- Горња граница: К3 + 1,5 * ИКР
Обично се посматрања која су изван ових граница сматрају аномалијама.
ИКР алгоритам је ефикасан за скупове података са неравномерно распоређеним подацима и где дистрибуција није добро схваћена.
Завршне речи
Чини се да се ризици за сајбер безбедност и кршење података неће смањити у наредним годинама — а очекује се да ће ова ризична индустрија даље расти у 2023. години, а очекује се да ће се сами ИоТ сајбер напади удвостручити до 2025.
Штавише, сајбер криминал ће коштати глобалне компаније и организације процењених 10,3 билиона долара годишње до 2025.
Због тога потреба за техникама откривања аномалија данас постаје све присутнија и неопходна за откривање превара и спречавање упада у мрежу.
Овај чланак ће вам помоћи да разумете шта су аномалије у рударењу података, различите врсте аномалија и начине за спречавање упада у мрежу коришћењем техника детекције аномалија заснованих на МЛ-у.
Затим можете истражити све о матрици конфузије у машинском учењу.