

Кључне Такеаваис
- Платформе друштвених медија продају корисничке податке компанијама са вештачком интелигенцијом за обуку генеративних АИ модела, упркос забринутости за приватност.
- Платформе као што су Мета, Реддит, Тумблр и ВордПресс.цом активно су укључене у ове уговоре о лиценцирању података за обуку вештачке интелигенције.
- Корисници могу да предузму неке мале кораке да заштите своје податке, као што је прилагођавање поставки приватности, одустајање од дељења и опрез у погледу онога што објављују на мрежи.
Један од најновијих начина на који компаније друштвених медија уновчавају корисничке податке је преко послова са компанијама са вештачком интелигенцијом. Али да ли постоји нешто што обични корисници могу да ураде да заштите своје податке и садржај?
Коришћење података друштвених медија за обуку генеративних модела вештачке интелигенције био је контроверзан потез — али изгледа да то не спречава компаније друштвених медија да деле корисничке податке.
Мета већ користи податке друштвених медија за обуку генеративних АИ функција најављених на Мета Цоннецт-у 2023. Ово укључује Мета АИ и функције као што је прављење налепница генерисаних АИ на ВхатсАпп-у.
Као што је Мајк Кларк, директор за управљање производима у компанији Мета, изјавио у а Пост Мета Невсроом:
„Јавно дељене објаве са Инстаграма и Фацебоока — укључујући фотографије и текст — биле су део података који се користе за обуку генеративних АИ модела који су у основи функција које смо најавили на Цоннецт.“
Чини се да овај тренд не успорава 2024. Према РеутерсРеддит је постигао договор са Гуглом да садржај платформе друштвених медија учини доступним за обуку АИ модела.
Реддитова С-1 пријава за своју ИПО, поднету 22. фебруара 2024, потврђује да компанија истражује уговоре о лиценцирању. У поднеску се наводи:
„Реддит подаци су темељни део за изградњу тренутне АИ технологије и многих ЛЛМ-ова. Верујемо да ће Реддитов масивни корпус конверзацијских података и знања наставити да игра улогу у обуци и побољшању ЛЛМ-а.”
У њему се наводи да је Реддит „у раној фази омогућавања трећим странама да лиценцирају приступ претраживању, анализи и приказу историјских података и података у реалном времену са наше платформе“ како би обучавали ЛЛМ.
И док су Мета и Реддит нека од највећих имена у друштвеним медијима, они нису једине платформе укључене у коришћење података друштвених медија за обуку АИ. Према а извештај 404 МедиаТумблр и ВордПресс.цом се припремају за продају корисничких података Мидјоурнеи и ОпенАИ.
Шансе су да ако користите Фацебоок, Инстаграм, Реддит, Тумблр или ВордПресс.цом, ваш јавно доступан садржај је већ коришћен у обуци ЛЛМ.
На пример, ако користите Алат за претрагу Вашингтон поста да бисте видели које су локације укључене у Гооглеов скуп података Ц4, који је коришћен као део Бардове обуке, видећете да Реддит.цом чини 7,9 милиона токена.

Тумблр.цом има 1,6 милиона токена. Моја мала веб локација, која користи ВордПресс.цом, чинила је 14.000 токена – тако да су мали лични блогови можда били укључени у скуп података.
Са текућим уговорима између компанија са вештачком интелигенцијом и компанија за друштвене медије, уговори о лиценцирању ће значити да ће се ови подаци активно продавати, а не само састругати са веба.
Али када је у питању будућа обрада, шта можете учинити поводом тога? Мета је увео а образац за генеративна АИ права субјекта података који вам омогућава да уложите приговор или ограничите обраду ваших личних података од трећих страна за обуку Мета генеративних АИ модела.
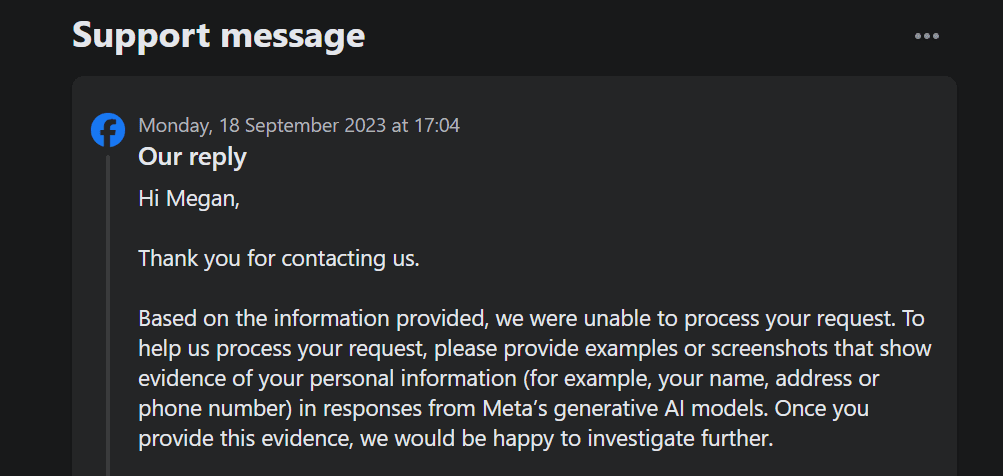
Посебно, ова опција вам не дозвољава да приговорите Мета-овој сопственој обради ваших података за обуку генеративне вештачке интелигенције. Штавише, када сам поднео пријаву за приговор на коришћење мојих личних података користећи формулар, тикет за подршку је захтевао од мене да докажем да се моји лични подаци већ појављују у Мета-иним генеративним АИ резултатима.
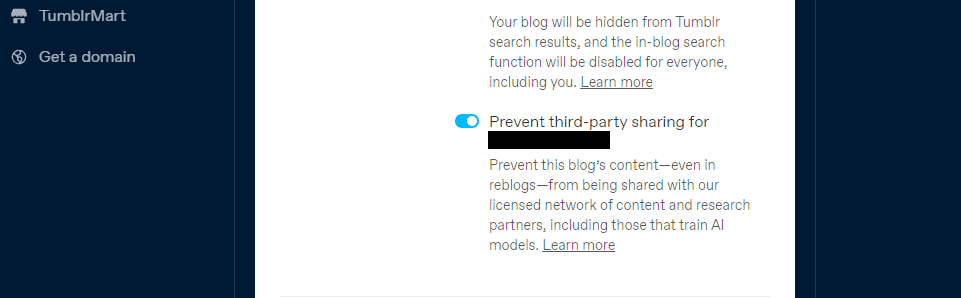
Тумблр је такође увео опцију да онемогућите дељење садржаја ваших јавних блогова са трећим лицима користећи подешавања вашег блога. Можете га пронаћи у подешавањима тако што ћете кликнути на свој блог и померити се надоле до подешавања видљивости. Затим изаберите да спречите дељење треће стране за свој блог.
Када је реч о платформи као што је Инстаграм, можете покушати да промените свој Инстаграм налог на приватни да бисте спречили употребу ваших података. Ово не гарантује да се ваши подаци неће користити, али пошто се чини да се прикупљање података за ЛЛМ фокусира на јавне податке, то би могла бити потенцијална заштита.
Такође можете учинити свој Кс (Твиттер) налог приватним, али ово је још једном само потенцијална заштита и не гарантује да ће ваши подаци остати приватни.
А заједничка изјава од стране разних националних комесара за информације и стручњака широм света, такође је предложио неке акције за појединце који желе да минимизирају ризик приватности од гребања података од стране АИ компанија. Савет укључује:
- Прочитајте услове и политику приватности веб локације да бисте видели како дели ваше личне податке.
- Ограничите информације које објављујете на мрежи, посебно осетљиве информације.
- Управљајте подешавањима приватности.
- Размишљајте дугорочно о информацијама које делите на мрежи.
- Контактирајте компанију за друштвене медије или веб локацију ако мислите да су ваши подаци непрописно избрисани. Ако нисте задовољни њиховим одговором, поднесите жалбу надлежном органу за заштиту података.
Такође можете да избришете одређене информације на мрежи ако вам не одговара да им трећа лица имају приступ, иако су јавно доступне информације на вашим профилима можда већ избрисане.
Нажалост, ми као редовни корисници можемо да урадимо само толико да заштитимо своје податке од компанија са вештачком интелигенцијом. Права контрола над овим информацијама вероватно ће доћи само уз помоћ регулатора.