

Веб сцрапинг је идеја издвајања информација са веб локације и њиховог коришћења за одређени случај употребе.
Рецимо да покушавате да издвојите табелу са веб странице, конвертујете је у ЈСОН датотеку и користите ЈСОН датотеку за прављење неких интерних алата. Уз помоћ веб скрапинга, можете издвојити податке које желите циљањем одређених елемената на веб страници. Веб стругање помоћу Питхон-а је веома популаран избор јер Питхон нуди више библиотека као што су БеаутифулСоуп или Сцрапи за ефикасно издвајање података.
Поседовање вештине ефикасног издвајања података је такође веома важно као програмер или научник података. Овај чланак ће вам помоћи да разумете како да ефикасно састружете веб локацију и добијете неопходан садржај да бисте њиме манипулисали у складу са вашим потребама. За овај водич користићемо пакет БеаутифулСоуп. То је модеран пакет за сцрапинг података у Питхон-у.
Преглед садржаја
Зашто користити Питхон за Веб Сцрапинг?
Питхон је први избор за многе програмере када праве веб стругаче. Постоји много разлога зашто је Питхон први избор, али у овом чланку размотрићемо три главна разлога зашто се Питхон користи за сцрапинг података.
Подршка за библиотеку и заједницу: Постоји неколико сјајних библиотека, као што су БеаутифулСоуп, Сцрапи, Селениум, итд., које пружају сјајне функције за ефикасно гребање веб страница. Изградио је одличан екосистем за веб сцрапинг, а такође и зато што многи програмери широм света већ користе Питхон, можете брзо добити помоћ када заглавите.
Аутоматизација: Питхон је познат по својим могућностима аутоматизације. Више од веб стругања је потребно ако покушавате да направите сложен алат који се ослања на стругање. На пример, ако желите да направите алатку која прати цене артикала у продавници на мрежи, мораћете да додате неке могућности аутоматизације тако да може свакодневно да прати цене и додаје их у вашу базу података. Питхон вам даје могућност да аутоматизујете такве процесе са лакоћом.
Визуелизација података: Научници података увелико користе веб стругање. Научници података често морају да извлаче податке са веб страница. Са библиотекама као што је Пандас, Питхон чини визуализацију података једноставнијом из сирових података.
Библиотеке за Веб Сцрапинг у Питхон-у
Постоји неколико библиотека доступних у Питхон-у за поједностављивање веб-стругања. Хајде да разговарамо о три најпопуларније библиотеке овде.
#1. БеаутифулСоуп
Једна од најпопуларнијих библиотека за веб сцрапинг. БеаутифулСоуп помаже програмерима да скрежу веб странице од 2004. Пружа једноставне методе за навигацију, претрагу и модификовање стабла рашчлањивања. Сам Беаутифулсоуп такође ради кодирање за долазне и одлазне податке. Добро је одржаван и има сјајну заједницу.
#2. Сцрапи
Још један популаран оквир за екстракцију података. Сцрапи има више од 43000 звездица на ГитХубу. Такође се може користити за гребање података из АПИ-ја. Такође има неколико занимљивих уграђених подршке, попут слања е-поште.
#3. Селен
Селен није углавном библиотека за стругање веба. Уместо тога, то је пакет за аутоматизацију претраживача. Али можемо лако да проширимо његове функционалности за гребање веб страница. Користи протокол ВебДривер за контролу различитих претраживача. Селен је на тржишту већ скоро 20 година. Али користећи Селениум, можете лако да аутоматизујете и скидате податке са веб страница.
Изазови са Питхон Веб Сцрапинг-ом
Човек се може суочити са многим изазовима када покушава да извуче податке са веб локација. Постоје проблеми као што су споре мреже, алати за спречавање гребања, блокирање засновано на ИП-у, блокирање цаптцха итд. Ови проблеми могу да изазову огромне проблеме када покушавате да скрежете веб локацију.
Али можете ефикасно заобићи изазове тако што ћете пратити неке начине. На пример, у већини случајева, веб адреса је блокирана од стране веб локације када постоји више од одређеног броја захтева послатих у одређеном временском интервалу. Да бисте избегли блокирање ИП адресе, мораћете да кодирате свој стругач тако да се охлади након слања захтева.

Програмери такође имају тенденцију да постављају замке за лонце за стругање. Ове замке су обично невидљиве голим људским очима, али их може пузати стругач. Ако стружете веб локацију која поставља такву замку, мораћете да кодирате свој стругач у складу са тим.
Цаптцха је још један озбиљан проблем са стругачима. Већина веб-сајтова данас користи цаптцха да заштити приступ ботова својим страницама. У том случају, можда ћете морати да користите цаптцха решавач.
Крегање веб странице помоћу Питхон-а
Као што смо разговарали, користићемо БеаутифулСоуп да уклонимо веб локацију. У овом водичу ћемо састругати историјске податке Етхереума из Цоингецко-а и сачувати податке табеле као ЈСОН датотеку. Пређимо на изградњу стругача.
Први корак је да инсталирате БеаутифулСоуп и Рекуестс. За овај водич, користићу Пипенв. Пипенв је виртуелни менаџер окружења за Питхон. Такође можете користити Венв ако желите, али ја више волим Пипенв. Дискусија о Пипенв-у је ван оквира овог упутства. Али ако желите да научите како се Пипенв може користити, пратите овај водич. Или, ако желите да разумете Питхон виртуелна окружења, пратите овај водич.
Покрените Пипенв схелл у свом пројектном директорију тако што ћете покренути команду пипенв схелл. Покренуће подљуску у вашем виртуелном окружењу. Сада, да бисте инсталирали БеаутифулСоуп, покрените следећу команду:
pipenv install beautifulsoup4
И, за инсталирање захтева, покрените команду сличну горњој:
pipenv install requests
Када се инсталација заврши, увезите потребне пакете у главну датотеку. Направите датотеку под називом маин.пи и увезите пакете као што је доле:
from bs4 import BeautifulSoup import requests import json
Следећи корак је да добијете садржај странице са историјским подацима и рашчланите га помоћу ХТМЛ парсера доступног у БеаутифулСоуп-у.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
У горњем коду, страници се приступа помоћу методе гет доступног у библиотеци захтева. Парсирани садржај се затим чува у променљивој која се зове супа.
Оригинални део за стругање почиње сада. Прво, мораћете да тачно идентификујете табелу у ДОМ-у. Ако отворите ову страницу и проверите је користећи алатке за програмере доступне у претраживачу, видећете да табела има ове табеле класа табле-стрипед тект-см тект-лг-нормал.
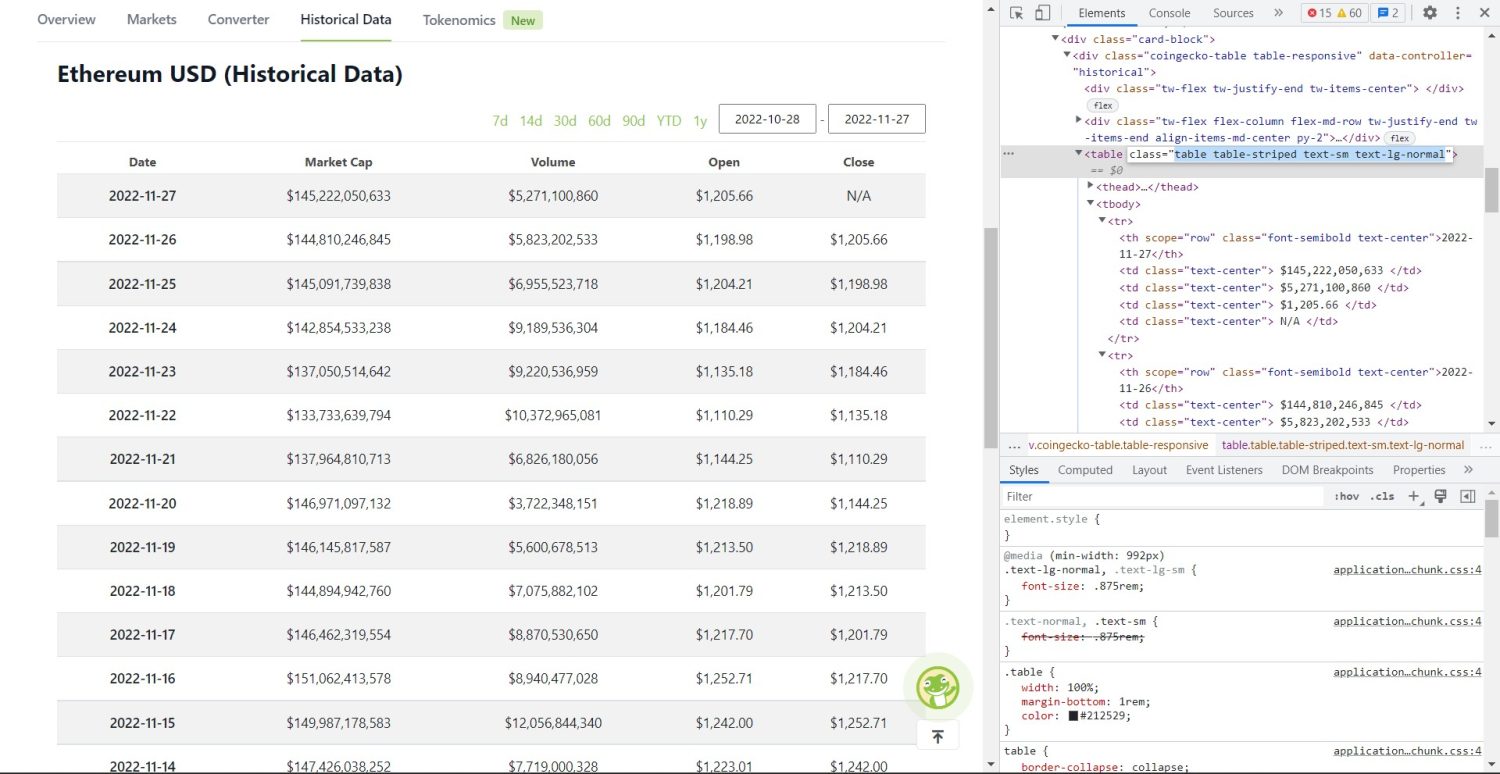 Табела историјских података Цоингецко Етхереум
Табела историјских података Цоингецко Етхереум
Да бисте правилно циљали ову табелу, можете користити метод проналажења.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
У горњем коду, прво се табела налази помоћу методе соуп.финд, а затим помоћу методе финд_алл, претражују се сви тр елементи унутар табеле. Ови тр елементи се чувају у променљивој која се зове табле_дата. Табела има неколико елемената за наслов. Нова променљива под називом табле_хеадингс је иницијализована за држање наслова на листи.
Затим се покреће фор петља за први ред табеле. У овом реду се траже сви елементи са тх, а њихова текстуална вредност се додаје на листу табле_хеадингс. Текст се екстрахује методом текста. Ако сада одштампате променљиву табле_хеадингс, моћи ћете да видите следећи излаз:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Следећи корак је да извучете остатак елемената, генеришете речник за сваки ред, а затим додате редове у листу.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Ово је суштински део кода. За сваки тр у променљивој табле_дата, прво се претражују елементи тх. тх елементи су датум приказан у табели. Ови елементи се чувају унутар променљиве тх. Слично, сви тд елементи се чувају у променљивој тд.
Иницијализују се празни подаци из речника. Након иницијализације, пролазимо кроз опсег тд елемената. За сваки ред, прво ажурирамо прво поље речника са првом ставком тх. Код табле_хеадингс[0]: тх[0].тект додељује пар кључ-вредност датума и првог елемента.
Након иницијализације првог елемента, остали елементи се додељују помоћу дата.упдате({табле_хеадингс[i+1]: тд[i].тект.реплаце(‘н’, ”)}). Овде се текст тд елемената прво екстрахује методом текста, а затим се све н замењује методом замене. Вредност се затим додељује и+1. елементу листе табле_хеадингс јер је и-ти елемент већ додељен.
Затим, ако дужина речника података прелази нулу, речник додајемо на листу табле_детаилс. Можете да одштампате листу табле_детаилс да бисте проверили. Али вредности ћемо писати у ЈСОН датотеку. Хајде да погледамо код за ово,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Овде користимо метод јсон.думп да запишемо вредности у ЈСОН датотеку под називом табле.јсон. Када се писање заврши, штампамо податке сачуване у јсон датотеци… у конзолу.
Сада покрените датотеку користећи следећу команду,
python run main.py
После неког времена, моћи ћете да видите податке сачуване у ЈСОН датотеци… текст у конзоли. Такође ћете видети нову датотеку под називом табле.јсон у радном директоријуму датотека. Датотека ће изгледати слично следећој ЈСОН датотеци:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Успешно сте имплементирали веб стругач користећи Питхон. Да бисте видели комплетан код, можете посетити овај ГитХуб репо.
Закључак
У овом чланку се говорило о томе како можете да имплементирате једноставно Питхон сцрапе. Разговарали смо о томе како се БеаутифулСоуп може користити за брзо скидање података са веб странице. Такође смо разговарали о другим доступним библиотекама и зашто је Питхон први избор за многе програмере за сцрапинг веб локација.
Такође можете погледати ове оквире за стругање веба.