

Веб сцрапинг вам омогућава да ефикасно прикупите велике количине података са интернета на веома брз начин и посебно је корисно у случајевима када веб локације не излажу своје податке на структурисан начин коришћењем интерфејса за програмирање апликација (АПИ).
На пример, замислите да креирате апликацију која упоређује цене артикала на сајтовима за е-трговину. Како бисте се позабавили овим? Један од начина је да сами ручно проверите цену артикала на свим сајтовима и забележите своје налазе. Међутим, ово није паметан начин јер постоје хиљаде производа на платформама за е-трговину и требало би вам заувек да извучете релевантне податке.
Бољи начин да се то уради је путем веб-отписивања. Веб сцрапинг је процес аутоматског издвајања података са веб страница и веб локација помоћу софтвера.
Софтверске скрипте, које се називају веб стругачи, користе се за приступ веб локацијама и преузимање података са веб локација. Подаци који се преузимају, обично у неструктурираном облику, могу се затим анализирати и ускладиштити на структуриран начин који је значајан за кориснике.
Веб сцрапинг је веома драгоцен у екстракцији података јер обезбеђује приступ великом броју података и омогућава аутоматизацију, тако да можете да закажете да се ваша скрипта за стругање веба покрене у одређено време или као одговор на одређене окидаче. Веб сцрапинг вам такође омогућава да добијате ажурирања у реалном времену и олакшава спровођење истраживања тржишта.

Многа предузећа и компаније се ослањају на веб стругање да би извукли податке за анализу. Компаније специјализоване за људске ресурсе, е-трговину, финансије, некретнине, путовања, друштвене медије и истраживања користе веб скрапинг да би извукли релевантне податке са веб локација.
Сам Гоогле користи веб скрапинг за индексирање веб локација на интернету како би корисницима могао да пружи релевантне резултате претраге.
Међутим, важно је да будете опрезни приликом уклањања веба. Иако укидање јавно доступних података није противзаконито, неке веб локације не дозвољавају сцрапинг. То може бити зато што имају осетљиве корисничке информације, њихови услови коришћења услуге изричито забрањују уклањање веба или штите интелектуалну својину.
Поред тога, неке веб локације не дозвољавају веб скрајпинг јер то може преоптеретити сервер веб локације и довести до повећања трошкова пропусног опсега, посебно када се веб скрајпинг врши у великом обиму.
Да бисте проверили да ли се веб локација може укинути, додајте роботс.ткт УРЛ адреси веб локације. роботс.ткт се користи да укаже ботовима који делови веб-сајта могу да се скражу. На пример, да бисте проверили да ли можете да скидате Гоогле, идите на гоогле.цом/роботс.ткт
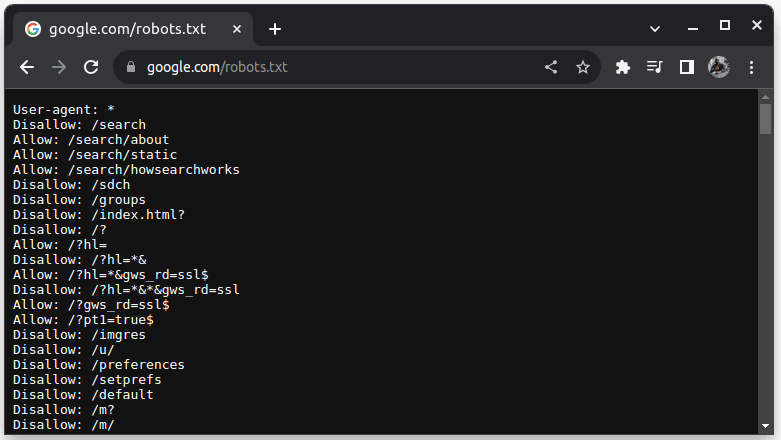
Кориснички агент: * се односи на све ботове или софтверске скрипте и пописиваче. Дисаллов се користи да каже ботовима да не могу приступити ниједном УРЛ-у у директоријуму, на пример /сеарцх. Дозволи означава директоријуме одакле могу да приступе УРЛ адресама.
Пример сајта који не дозвољава сцрапинг је ЛинкедИн. Да бисте проверили да ли можете да скренете ЛинкедИн, идите на линкедин.цом/роботс.ткт
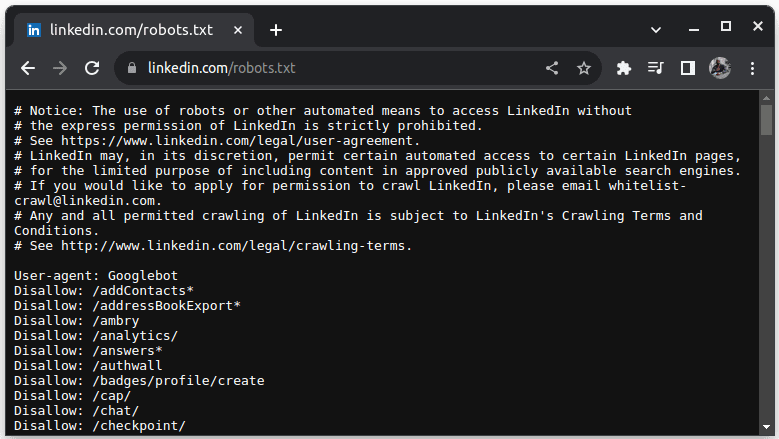
Као што видите, није вам дозвољено да скидате ЛинкедИн без њихове дозволе. Увек проверите да ли веб локација дозвољава сцрапинг да бисте избегли било какве правне проблеме.
Преглед садржаја
Зашто је Јава погодан језик за Веб Сцрапинг
Док можете да креирате веб стругач са различитим програмским језицима, Јава је посебно идеална за посао из више разлога. Прво, Јава има богат екосистем и велику заједницу и пружа разне библиотеке за веб скрапинг као што су ЈСоуп, ВебМагиц и ХТМЛУнит, које олакшавају писање веб скрепера.

Такође обезбеђује библиотеке за рашчлањивање ХТМЛ-а како би се поједноставио процес издвајања података из ХТМЛ докумената и мрежних библиотека као што је ХттпУРЛЦоннецтион за прављење захтева ка различитим УРЛ адресама веб локација.
Јава јака подршка за истовременост и вишенитност је такође корисна у веб скрапингу јер омогућава паралелну обраду и руковање задацима гребања веба са више захтева, омогућавајући вам да сцрапинг више страница истовремено. С обзиром на то да је скалабилност кључна снага Јаве, можете удобно да скупљате веб локације у великом обиму користећи веб стругач написан на Јави.
Јава-ина подршка за више платформи такође је згодна јер вам омогућава да напишете веб стругач и покренете га у било ком систему који има компатибилну Јава виртуелну машину. Стога можете написати веб стругач у једном оперативном систему или уређају и покренути га у другом оперативном систему без потребе да мењате веб стругач.
Јава се такође може користити са претраживачима без главе као што су Хеадлесс Цхроме, ХТМЛ Унит, Хеадлесс Фирефок и ПхантомЈс, између осталих. Безглави претраживач је претраживач без графичког корисничког интерфејса. Безглави претраживачи могу да симулирају интеракције корисника и веома су корисни када скражују веб локације које захтевају интеракцију корисника.
За крај, Јава је веома популаран и широко коришћен језик који је подржан и који се лако може интегрисати са разним алатима као што су базе података и оквири за обраду података. Ово је корисно јер осигурава да док скрапате податке, сви алати који ће вам бити потребни за сцрапинг, обраду и складиштење података вероватно подржавају Јаву.
Хајде да видимо како можемо да користимо Јаву за веб скрапинг.
Јава за Веб Сцрапинг: Предуслови
Да бисте користили Јава у веб скрапингу, треба да буду испуњени следећи предуслови:
1. Јава – требало би да имате инсталирану Јаву, по могућности најновију верзију за дугорочну подршку. У случају да немате инсталирану Јаву, идите на инсталирање Јава да бисте сазнали како да инсталирате Јаву на своју машину
2. Интегрисано развојно окружење (ИДЕ) – Требало би да имате инсталиран ИДЕ на вашој машини. У овом водичу ћемо користити ИнтеллиЈ ИДЕА, али можете користити било који ИДЕ који вам је познат.
3. Мавен – ово ће се користити за управљање зависношћу и за инсталирање библиотеке за гребање веба.
У случају да немате инсталиран Мавен, можете га инсталирати тако што ћете отворити терминал и извршити:
sudo apt install maven
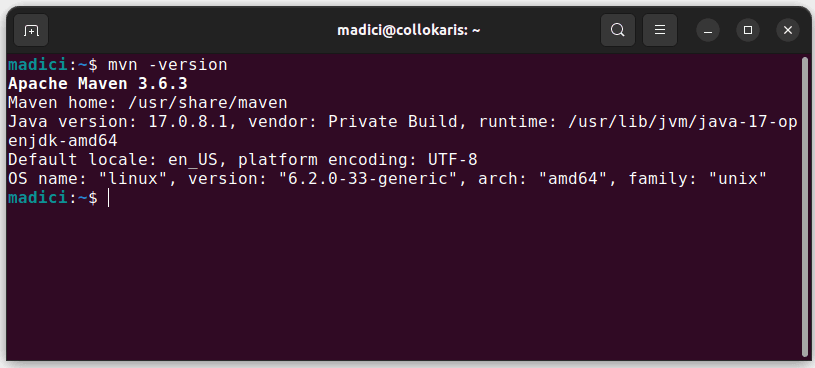
Ово инсталира Мавен из званичног спремишта. Можете потврдити да је Мавен успешно инсталиран тако што ћете извршити:
mvn -version
У случају да је инсталација била успешна, требало би да добијете такав излаз:
Постављање окружења
Да бисте подесили своје окружење:
1. Отворите ИнтеллиЈ ИДЕА. На левој траци менија кликните на Пројекти, а затим изаберите Нови пројекат.
2. У прозору Нови пројекат који се отвори, попуните га као што је приказано испод. Уверите се да је језик подешен на Јава, а систем изградње на Мавен. Пројекту можете дати било које име које желите, а затим употребите Лоцатион да бисте одредили фасциклу у којој желите да се пројекат креира. Када завршите, кликните на Креирај.
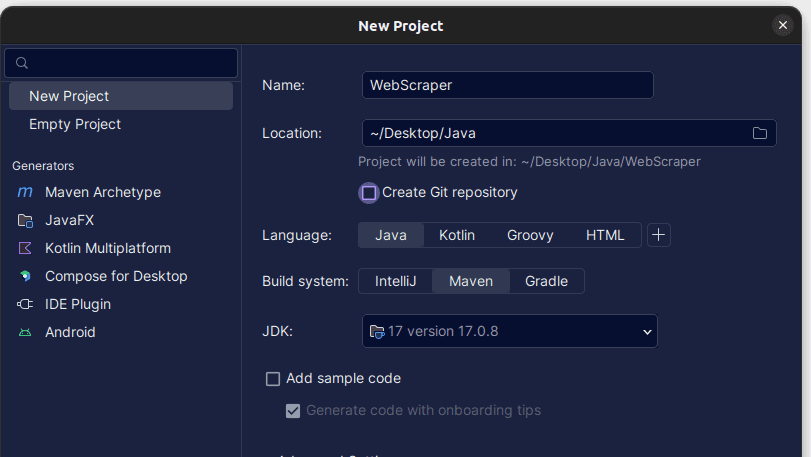
3. Када је ваш пројекат креиран, требало би да имате пом.кмл у свом пројекту као што је приказано испод.
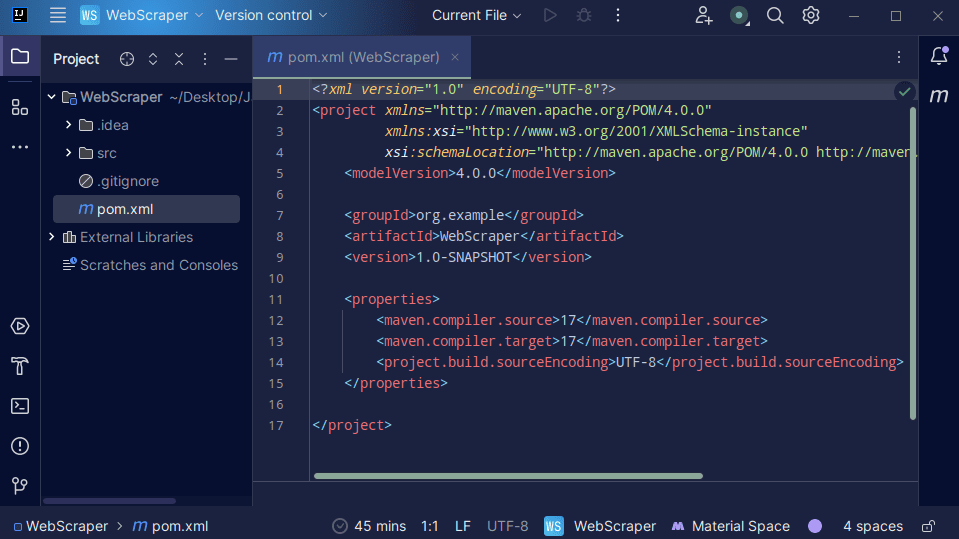
Датотеку пом.кмл креира Мавен и она садржи информације о пројекту и детаље о конфигурацији које Мавен користи за израду пројекта. То је овај фајл који такође користимо да означимо да ћемо користити спољне библиотеке.
У изградњи веб стругача користићемо библиотеку јсоуп. Стога, морамо да га додамо као зависност у пом.кмл датотеци како би Мавен могао да је учини доступним у нашем пројекту.
4. Додајте зависност јсоуп у датотеку пом.кмл копирањем кода испод и додавањем у своју датотеку пом.кмл
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Резултат би требао бити као што је приказано у наставку:
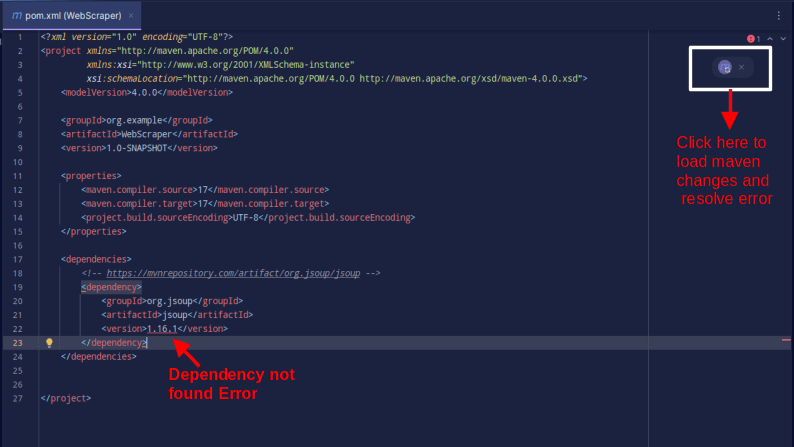
У случају да наиђете на грешку која каже да се зависност не може пронаћи, кликните на назначену икону да би Мавен учитао направљене измене, учитао зависност и уклонио грешку.
Тиме је ваше окружење у потпуности подешено.
Веб Сцрапинг са Јавом
За веб сцрапинг, ми ћемо сцрапинг податке из СцрапеТхисСитекоји обезбеђује сандбок где програмери могу да вежбају веб скрапинг без наиласка на правне проблеме.
За гребање веб странице користећи Јава
1. На левој траци менија на ИнтеллиЈ-у отворите срц директоријум, а затим главни директоријум, који се налази унутар срц директоријума. Главни директоријум садржи директоријум који се зове јава; кликните десним тастером миша на њега и изаберите Ново, а затим Јава класа
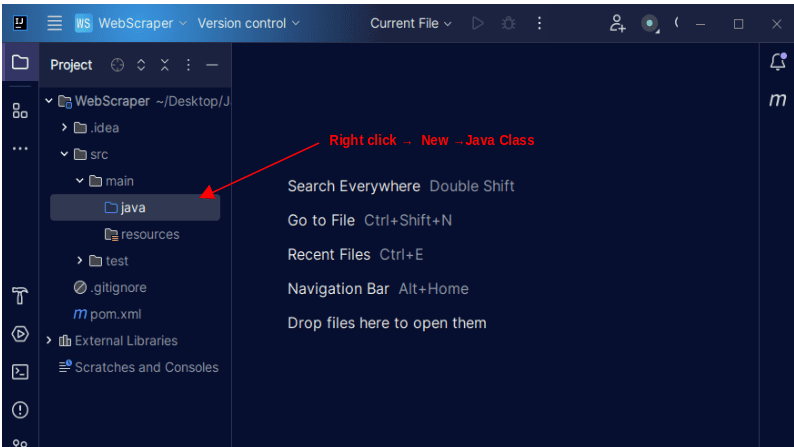
Дајте класи било које име које желите, као што је ВебСцрапер, а затим притисните Ентер да бисте креирали нову Јава класу.
Отворите новокреирану датотеку која садржи Јава класе које сте управо креирали.
2. Веб сцрапинг подразумева добијање података са веб локација. Због тога морамо да наведемо УРЛ са којег желимо да извучемо податке. Када одредимо УРЛ, морамо се повезати са УРЛ-ом и направити ГЕТ захтев за преузимање ХТМЛ садржаја странице.
Код који то ради је приказан испод:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Излаз:
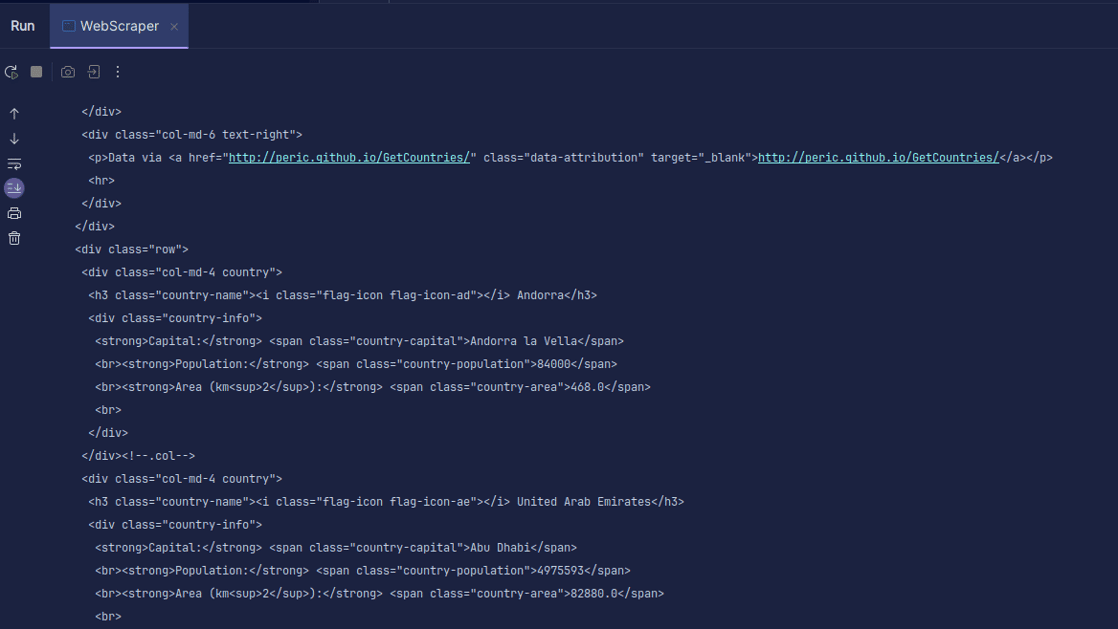
Као што видите, ХТМЛ странице се враћа и то је оно што штампамо. Приликом сцрапинга, УРЛ који наведете може имати грешку, а ресурс који покушавате да скрежете можда уопште не постоји. Зато је важно да наш код умотамо у наредбу три-цатцх.
Линија:
Document doc = Jsoup.connect(url).get();
Користи се за повезивање за повезивање са УРЛ-ом који желите да скрежете. Гет() метода се користи за прављење ГЕТ захтева и преузимање ХТМЛ-а на страници. Враћени резултат се затим чува у објекту ЈСОУП документа, под називом доц. Чување резултата у ЈСОУП документу омогућава вам да користите ЈСОУП АПИ за манипулацију враћеним ХТМЛ-ом.
3. Иди на СцрапеТхисСите и прегледајте страницу. У ХТМЛ-у би требало да видите структуру приказану испод:
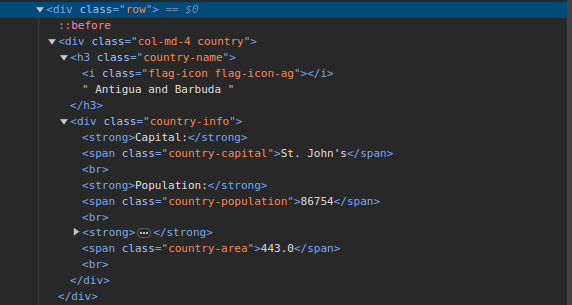
Имајте на уму да се све земље на страници чувају у сличној структури. Постоји див са класом која се зове земља са елементом х3 са класом назива земље која садржи назив сваке земље на страници.
Унутар главног дива налази се још један див са класом информација о земљи и садржи информације као што су главни град, становништво и област земље. Можемо користити ове називе класа за одабир ХТМЛ елемената и издвајање информација из њих.
4. Извуците одређени садржај из ХТМЛ-а на страници користећи следеће редове:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Користимо метод селецт() да изаберемо елементе из ХТМЛ-а странице који одговарају специфичном ЦСС селектору који прослеђујемо. У нашем случају, ми прослеђујемо имена класа. Прегледајући страницу, видели смо да се све информације о земљи на страници чувају под див са класом земље.
Свака земља има свој див са класом земље и див садржи информације као што су назив земље, главни град и становништво.
Због тога прво бирамо све земље на страници користећи класу .цоунтри. Затим чувамо ово у променљивој која се зове земље типа Елементс, која функционише баш као листа. Затим користимо фор-петљу да прођемо кроз земље и извучемо назив земље, главни град и становништво и одштампамо оно што смо пронашли.
Цела наша кодна база је приказана испод:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Излаз:
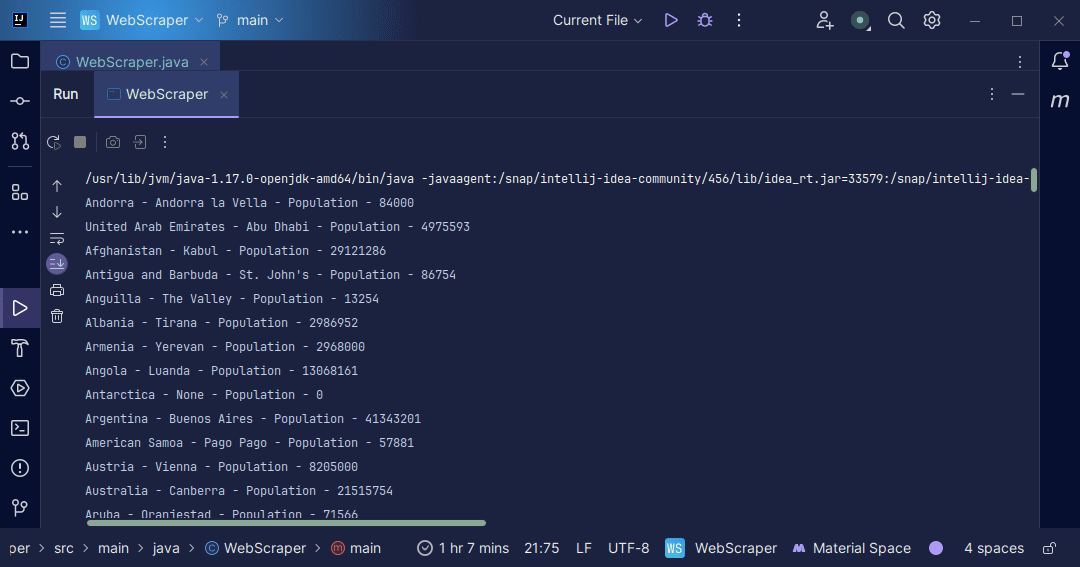
Са информацијама које добијемо са странице, можемо да урадимо разне ствари, као што је да их одштампамо као што смо управо урадили или да их сачувамо у датотеци у случају да желимо да извршимо даљу обраду података.
Закључак
Веб сцрапинг је одличан начин за издвајање неструктурираних података са веб локација, складиштење података на структуиран начин и обраду података за издвајање значајних информација. Међутим, важно је да будете опрезни приликом веб-стругања, јер одређене веб-странице не дозвољавају веб-сцрапинг.
Да бисте били сигурни, користите веб локације које пружају сандбокове за вежбање растављања. У супротном, увек прегледајте датотеку роботс.ткт сваке веб локације коју желите да сцрапингујете да бисте сазнали да ли веб локација дозвољава уклањање.
када пишете веб сцраппер, Јава је одличан језик јер пружа библиотеке које чине брисање веба лакшим и ефикаснијим. Као Јава програмер, прављење веб стругача ће вам помоћи да још више развијете своје вештине програмирања. Зато само напред и напишите свој сопствени веб скрапер или модификујте онај који се користи у чланку да бисте извукли различите врсте информација. Срећно кодирање!
Такође можете истражити нека популарна решења за веб сцрапинг заснована на облаку.