

Сцикит-ЛЛМ је Питхон пакет који помаже у интеграцији великих језичких модела (ЛЛМ) у оквир сцикит-леарн. Помаже у извршавању задатака анализе текста. Ако сте упознати са сцикит-леарн, биће вам лакше да радите са Сцикит-ЛЛМ.
Важно је напоменути да Сцикит-ЛЛМ не замењује сцикит-леарн. сцикит-леарн је библиотека за машинско учење опште намене, али је Сцикит-ЛЛМ посебно дизајниран за задатке анализе текста.
Преглед садржаја
Почетак рада са Сцикит-ЛЛМ
За почетак са Сцикит-ЛЛМ, мораћете да инсталирате библиотеку и конфигуришете свој АПИ кључ. Да бисте инсталирали библиотеку, отворите свој ИДЕ и креирајте ново виртуелно окружење. Ово ће помоћи у спречавању потенцијалних сукоба верзија библиотеке. Затим покрените следећу команду у терминалу.
pip install scikit-llm
Ова команда ће инсталирати Сцикит-ЛЛМ и његове потребне зависности.
Да бисте конфигурисали свој АПИ кључ, морате га набавити од свог ЛЛМ провајдера. Да бисте добили ОпенАИ АПИ кључ, следите ове кораке:
Наставите до ОпенАИ АПИ страница. Затим кликните на свој профил који се налази у горњем десном углу прозора. Изаберите Прикажи АПИ кључеве. Ово ће вас одвести на страницу АПИ кључева.
На страници АПИ кључеви кликните на дугме Креирај нови тајни кључ.
Именујте свој АПИ кључ и кликните на дугме Креирај тајни кључ да бисте генерисали кључ. Након генерисања, потребно је да копирате кључ и сачувате га на безбедном месту јер ОпенАИ неће поново приказати кључ. Ако га изгубите, мораћете да генеришете нову.
Сада када имате свој АПИ кључ, отворите свој ИДЕ и увезите класу СКЛЛМЦонфиг из библиотеке Сцикит-ЛЛМ. Ова класа вам омогућава да поставите опције конфигурације које се односе на употребу великих језичких модела.
from skllm.config import SKLLMConfig
Ова класа очекује да подесите свој ОпенАИ АПИ кључ и детаље организације.
SKLLMConfig.set_openai_key("Your API key")
SKLLMConfig.set_openai_org("Your organization ID")
ИД организације и назив нису исти. ИД организације је јединствени идентификатор ваше организације. Да бисте добили ИД своје организације, идите на ОпенАИ организација страницу подешавања и копирајте је. Сада сте успоставили везу између Сцикит-ЛЛМ и великог језичког модела.
Сцикит-ЛЛМ захтева од вас да имате план који се плаћа. То је зато што бесплатни пробни ОпенАИ налог има ограничење брзине од три захтева у минути што није довољно за Сцикит-ЛЛМ.
Покушај коришћења бесплатног пробног налога ће довести до грешке сличне оној испод током анализе текста.

Да бисте сазнали више о ограничењима стопе. Наставите до Страница ограничења брзине ОпенАИ.
ЛЛМ добављач није ограничен само на ОпенАИ. Можете користити и друге ЛЛМ провајдере.
Увоз потребних библиотека и учитавање скупа података
Увезите панде које ћете користити за учитавање скупа података. Такође, из Сцикит-ЛЛМ и сцикит-леарн, увезите потребне класе.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Затим учитајте скуп података на којем желите да извршите анализу текста. Овај код користи скуп података ИМДБ филмова. Међутим, можете га подесити да бисте користили сопствени скуп података.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Коришћење само првих 100 редова скупа података није обавезно. Можете користити цео скуп података.
Затим издвојите карактеристике и колоне са ознакама. Затим поделите свој скуп података на скупове за обуку и тестове.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Колона Жанр садржи ознаке које желите да предвидите.
Класификација нултог текста са Сцикит-ЛЛМ
Класификација текста на нултом нивоу је карактеристика коју нуде велики језички модели. Он класификује текст у унапред дефинисане категорије без потребе за експлицитном обуком о означеним подацима. Ова могућност је веома корисна када се бавите задацима где треба да класификујете текст у категорије које нисте предвидели током обуке модела.
Да бисте извршили класификацију текста нулте слике користећи Сцикит-ЛЛМ, користите класу ЗероСхотГПТЦлассифиер.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
Излаз је следећи:
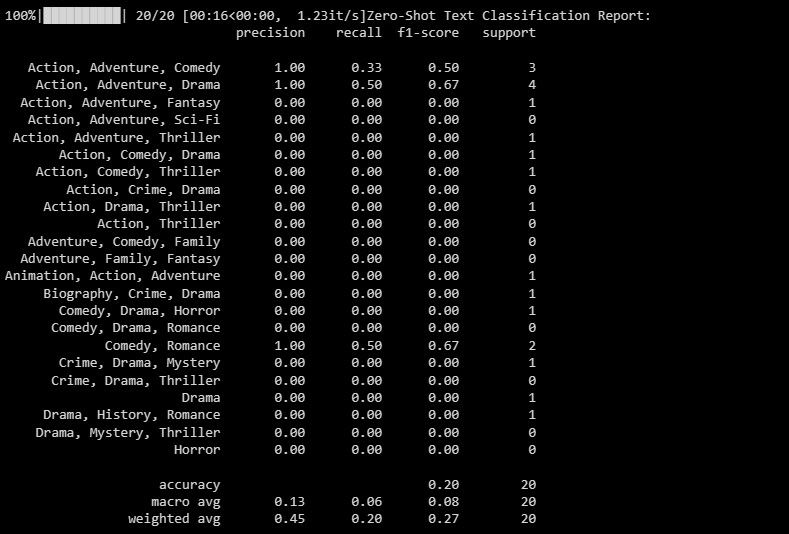
Извештај о класификацији пружа метрику за сваку ознаку коју модел покушава да предвиди.
Мулти-Лабел Зеро-Схот класификација текста са Сцикит-ЛЛМ
У неким сценаријима, један текст може истовремено припадати више категорија. Традиционални модели класификације се боре са овим. Сцикит-ЛЛМ са друге стране чини ову класификацију могућом. Класификација текста са више ознака је кључна за додељивање више описних ознака једном текстуалном узорку.
Користите МултиЛабелЗероСхотГПТЦлассифиер да предвидите које су ознаке прикладне за сваки узорак текста.
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
У коду изнад дефинишете ознаке кандидата којима ваш текст може припадати.
Излаз је као што је приказано у наставку:
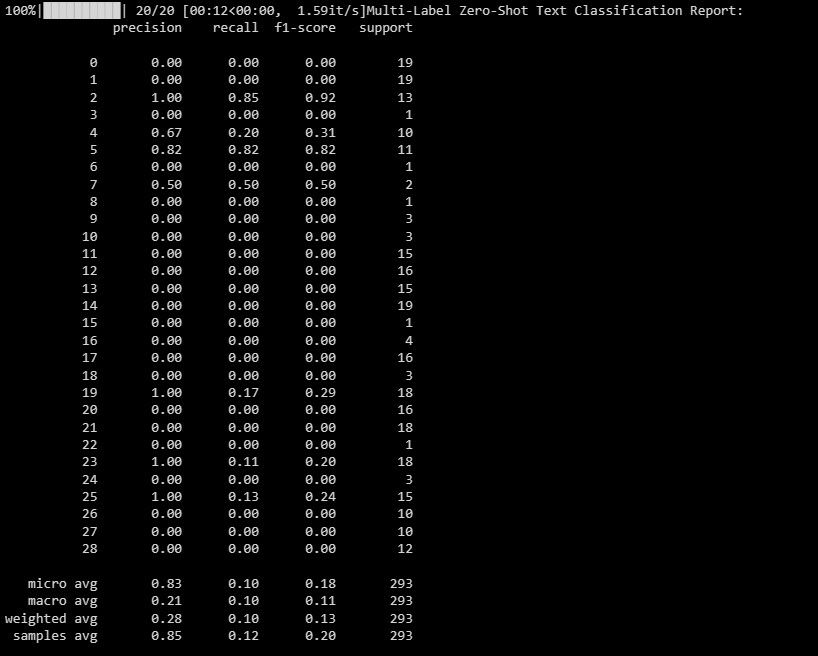
Овај извештај вам помаже да разумете колико добро функционише ваш модел за сваку ознаку у класификацији са више ознака.
Векторизација текста са Сцикит-ЛЛМ
У векторизацији текста текстуални подаци се конвертују у нумерички формат који модели машинског учења могу да разумеју. Сцикит-ЛЛМ нуди ГПТВеторизер за ово. Омогућава вам да трансформишете текст у векторе фиксне димензије користећи ГПТ моделе.
Ово можете постићи коришћењем терминске фреквенције-инверзне фреквенције документа.
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5])
Ево излаза:
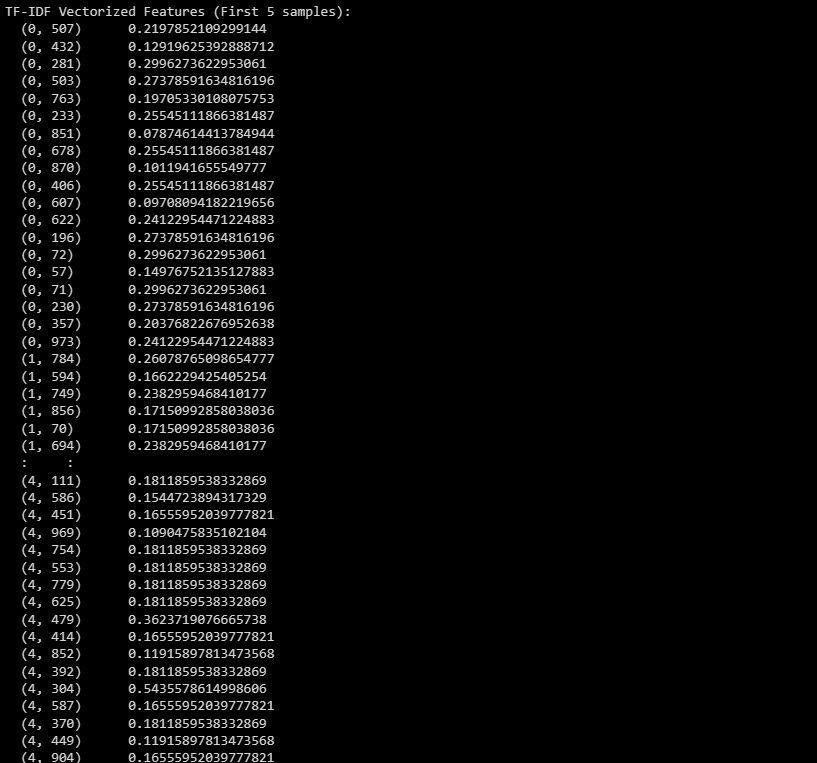
Излаз представља векторизоване карактеристике ТФ-ИДФ за првих 5 узорака у скупу података.
Резиме текста са Сцикит-ЛЛМ
Сажимање текста помаже у сажимању дела текста уз очување његових најкритичнијих информација. Сцикит-ЛЛМ нуди ГПТСуммаризер, који користи ГПТ моделе за генерисање сажетих сажетака текста.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Излаз је следећи:
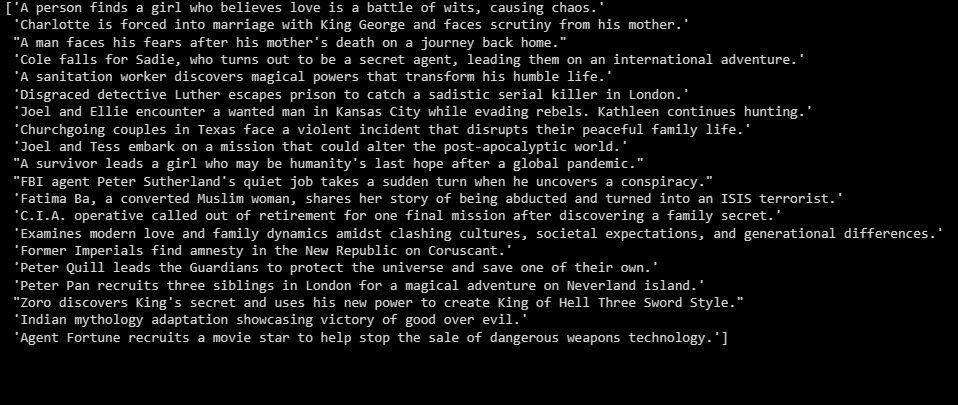
Горе наведено је резиме података теста.
Направите апликације на врху ЛЛМ-а
Сцикит-ЛЛМ отвара свет могућности за анализу текста са великим језичким моделима. Разумевање технологије која стоји иза великих језичких модела је кључно. То ће вам помоћи да разумете њихове предности и слабости које вам могу помоћи у изградњи ефикасних апликација на врху ове најсавременије технологије.